Jump Start with Apache Spark 2.0 on Databricks
Download as PPTX, PDF9 likes2,811 views

The document provides an overview of Apache Spark 2.0 on Databricks, detailing its architecture, major new features, and improvements such as unified APIs and structured streaming capabilities. It emphasizes the role of Databricks in simplifying big data processing and introduces participants to various functionalities and workshops focused on Spark's dataframes, datasets, and performance optimizations through Project Tungsten. The presentation includes practical sessions to familiarize users with structured streaming and batch processing using Spark SQL.

































![Background: What is in an RDD?
•Dependencies
• Partitions (with optional locality info)
• Compute function: Partition =>
Iterator[T]
Opaque
Computation
& Opaque Data](https://image.slidesharecdn.com/jumpstartwithspark2-161013175546/85/Jump-Start-with-Apache-Spark-2-0-on-Databricks-35-320.jpg)

![Dataset API in Spark 2.0
• Typed interface over DataFrames / Tungsten
• case class Person(name: String, age: Int)
• val dataframe = spark.read.json(“people.json”)
• val ds: Dataset[Person] = dataframe.as[Person]
• ds.filter(p => p.name.startsWith(“M”))
.groupBy(“name”)
.avg(“age”)](https://image.slidesharecdn.com/jumpstartwithspark2-161013175546/85/Jump-Start-with-Apache-Spark-2-0-on-Databricks-37-320.jpg)
![Type-safe:
operate on
domain objects
with compiled
lambda functions
8
Datasets API
val df = spark.read.json("people.json")
/ / Convert data to domain objects.
case class Person(name: S tri ng , age: I n t )
val ds: Dataset[Person] = df.as[Person]
d s . f i l t e r ( _ . a g e > 30)
/ / Compute histogram of age by name.
val h i s t = ds.groupBy(_.name).mapGroups {
case (name, people: Iter[Person]) =>
val buckets = newArray[Int](10)
people.map(_.age).foreach { a =>
buckets(a / 10) += 1
}
(name, buckets)
}](https://image.slidesharecdn.com/jumpstartwithspark2-161013175546/85/Jump-Start-with-Apache-Spark-2-0-on-Databricks-38-320.jpg)


























![Streaming ETL with DataFrame
input = spark.read
.format("json")
.stream("source-path")
result = input
.select("device", "signal")
.where("signal > 15")
result.write
.format("parquet")
.outputMode("append")
.startStream("dest-path")
1 2 3
Result
[append-only table]
Input
Output
[append mode]
new
rows in
result of
2
new
rows in
result of
3](https://image.slidesharecdn.com/jumpstartwithspark2-161013175546/85/Jump-Start-with-Apache-Spark-2-0-on-Databricks-66-320.jpg)











Jump Start with Apache Spark 2.0 on Databricks
- 1. Jump Start with Apache® Spark™ 2.0 on Databricks Jules S. Damji Spark Community Evangelist Fremont Big Data & Cloud Meetup @2twitme
- 2. $ whoami • Spark Community Evangelist @ Databricks • Previously Developer Advocate @ Hortonworks • In the past engineering roles at: • Sun Microsystems, Netscape, @Home,VeriSign, Scalix, Centrify, LoudCloud/Opsware, ProQuest • [email protected] • https://www.linkedin.com/in/dmatrix
- 3. Agenda for the next 2+ hours • Get to know Databricks • Overview Spark Architecture • What’s New in Spark 2.0 • Unified APIs: SparkSessions, SQL, DataFrames, Datasets… • Workshop Notebook 1 • Break… Hour 1 • Introduction to DataFrames, DataSets and Spark SQL • Workshop Notebook 2 • Introduction to Structured Streaming Concepts • Workshop 3/Demo • Go Home… Hour 2+
- 4. Get to know Databricks • Get Databricks community edition http://databricks.com/try- databricks
- 5. We are Databricks, the company behind Apache Spark Founded by the creators of Apache Spark in 2013 Share of Spark code contributed by Databricks in 2014 75% 5 Data Value Created Databricks on top of Spark to make big data simple.
- 6. Unified engine across diverse workloads & environments
- 7. Apache Spark Architecture Deployments Modes • Local • Standalone • YARN • Mesos
- 8. Apache Spark Architecture An Anatomy of an Application Spark Application • Jobs • Stages • Tasks
- 9. How did we Get Here..? Where we Going..?
- 10. A Brief History 10 2012 Started @ UC Berkeley 2010 research paper 2013 Databricks started & donated to ASF 2014 Spark 1.0 & libraries (SQL, ML, GraphX) 2015 DataFrames/Datasets Tungsten ML Pipelines 2016 Apache Spark 2.0 Easier Smart er Faster
- 11. Apache Spark 2.0 • Steps to Bigger & Better Things…. Builds on all we learned in past 2 years
- 14. Major Features in Apache Spark 2.0 Tungsten Phase 2 speedups of 5-10x & Catalyst Optimizer Faster Structured Streaming real-time engine on SQL / DataFrames Smarter Unifying Datasets and DataFrames & SparkSessions Easier
- 15. Unified API Foundation for the Future: Spark Sessions, Dataset, DataFrame, MLlib, Structured Streaming…
- 16. Towards SQL 2003 • Today, Spark can run all 99 TPC-DS queries! - New standard compliant parser (with good error messages!) - Subqueries (correlated & uncorrelated) - Approximate aggregate stats - https://databricks.com/blog/2016/07/26/introducing- apache-spark-2-0.html - https://databricks.com/blog/2016/06/17/sql-subqueries-in- apache-spark-2-0.html
- 17. 0 100 200 300 400 500 600 Runtime(seconds) Preliminary TPC-DS Spark 2.0 vs 1.6 – Lower is Better Time (1.6) Time (2.0)
- 18. SparkSession – A Unified entry point to Spark • SparkSession is the “SparkContext” for Dataset/DataFrame - Entry point for reading data and writing data - Working with metadata - Setting Spark Configuration - Driver uses for Cluster resource management
- 19. SparkSession vs SparkContext SparkSessions Subsumes • SparkContext • SQLContext • HiveContext • StreamingContext • SparkConf
- 21. Long Term • RDD will remain the low-level API in Spark • For control and certain type-safety in Java/Scala • Datasets & DataFrames give richer semantics and optimizations • For semi-structured data and DSL like operations • New libraries will increasingly use these as interchange format • Examples: Structured Streaming, MLlib, GraphFrames – A Tale of Three APIs: RDDs, DataFrames and Datasets
- 22. Other notable API improvements • DataFrame-based ML pipeline API becoming the main MLlib API • ML model & pipeline persistence with almost complete coverage • In all programming languages: Scala, Java, Python, R • Improved R support • (Parallelizable) User-defined functions in R • Generalized Linear Models (GLMs), Naïve Bayes, Survival Regression, K-Means
- 23. Workshop: Notebook on SparkSession • Import Notebook into your Spark 2.0 Cluster – http://dbricks.co/sswksh1 – http://docs.databricks.com – http://spark.apache.org/docs/latest/api/scala/index.html#or g.apache.spark.sql.SparkSession • Familiarize your self with Databricks Notebook environment • Work through each cell • CNTR + <return> / Shift + Return • Try challenges • Break…
- 24. DataFrames/Datasets & Spark SQL & Catalyst Optimizer
- 25. The not so secret truth… SQL is not about SQL is about more than SQL
- 26. Spark SQL: The whole story 1 0 Is About Creating and Running Spark Programs Faster: • Write less code • Read less data • Let the optimizer do the hard work
- 27. Spark SQL Architecture Logical Plan Physica l Plan Catalog Optimizer RDDs … Data Source API SQL DataFrame s Code Generator Datasets
- 28. 28 Using Catalyst in Spark SQL Unresolved Logical Plan Logical Plan Optimized Logical Plan RDDs Selected Physical Plan Analysis Logical Optimization Physical Planning CostModel Physical Plans Code Generation Catalog Analysis: analyzing a logical plan to resolve references Logical Optimization: logical plan optimization Physical Planning: Physical planning Code Generation: Compile parts of the query to Java bytecode SQL AST DataFrame Datasets
- 29. Catalyst Optimizations Logical Optimizations Create Physical Plan & generate JVM bytecode • Push filter predicates down to data source, so irrelevant data can be skipped • Parquet: skip entire blocks, turn comparisons on strings into cheaper integer comparisons via dictionary encoding • RDBMS: reduce amount of data traffic by pushing predicates down • Catalyst compiles operations into physical plans for execution and generates JVM bytecode • Intelligently choose between broadcast joins and shuffle joins to reduce network traffic • Lower level optimizations: eliminate expensive object allocations and reduce virtual function calls
- 30. # Load partitioned Hive table def add_demographics(events): u = sqlCtx.table("users") events . j o i n ( u , events.user_id == u.user_id) .withColumn("city", zipToCity(df.zip)) # Join on user_id # Run udf to add c i t y column Physical Plan with Predicate Pushdown and Column Pruning join optimize d scan (events) optimize d scan (users) events = add_demographics(sqlCtx.load("/data/events", "parquet")) training_data = events.where(events.city == "New York").select(events.timestamp).collect() Logical Plan filter join Physical Plan join scan (users ) events file users table 30 scan (event s) filter
- 31. Columns: Predicate pushdown spark.read .format("jdbc") .option("url", "jdbc:postgresql:dbserver") .option("dbtable", "people") .load() .where($"name" === "michael") 31 You Write Spark Translates For Postgres SELECT * FROM people WHERE name = 'michael'
- 32. 4 3 Spark Core (RDD) Catalyst DataFrame/DatasetSQL ML Pipelines Structure d Streamin g { JSON } JDBC and more… Foundational Spark 2.0 Components Spark SQL GraphFrame s
- 34. Dataset Spark 2.0 APIs
- 35. Background: What is in an RDD? •Dependencies • Partitions (with optional locality info) • Compute function: Partition => Iterator[T] Opaque Computation & Opaque Data
- 36. Structured APIs In Spark 36 SQL DataFrames Datasets Syntax Errors Analysis Errors Runtime Compile Time Runtime Compile Time Compile Time Runtime Analysis errors are reported before a distributed job starts
- 37. Dataset API in Spark 2.0 • Typed interface over DataFrames / Tungsten • case class Person(name: String, age: Int) • val dataframe = spark.read.json(“people.json”) • val ds: Dataset[Person] = dataframe.as[Person] • ds.filter(p => p.name.startsWith(“M”)) .groupBy(“name”) .avg(“age”)
- 38. Type-safe: operate on domain objects with compiled lambda functions 8 Datasets API val df = spark.read.json("people.json") / / Convert data to domain objects. case class Person(name: S tri ng , age: I n t ) val ds: Dataset[Person] = df.as[Person] d s . f i l t e r ( _ . a g e > 30) / / Compute histogram of age by name. val h i s t = ds.groupBy(_.name).mapGroups { case (name, people: Iter[Person]) => val buckets = newArray[Int](10) people.map(_.age).foreach { a => buckets(a / 10) += 1 } (name, buckets) }
- 41. Project Tungsten • Substantially speed up execution by optimizing CPU efficiency, via: SPARK-12795 (1) Runtime code generation (2) Exploiting cache locality (3) Off-heap memory management
- 42. 6 “bricks ” Tungsten’s Compact Row Format 0x 0 12 3 32 L 48 L 4 “data” (123, “data”, “bricks”) Null bitmap Offset to data Offset to data Field lengths 2
- 43. Encoders 6 “bricks ” 0x0 123 32L 48L 4 “data” JVM Object Internal Representation MyClass(123, “data”, “bricks”) Encoders translate between domain objects and Spark's internal format
- 44. Datasets: Lightning-fast Serialization with Encoders
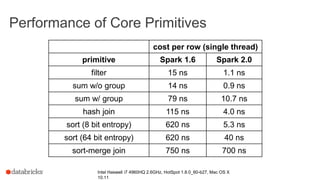
- 45. Performance of Core Primitives cost per row (single thread) primitive Spark 1.6 Spark 2.0 filter 15 ns 1.1 ns sum w/o group 14 ns 0.9 ns sum w/ group 79 ns 10.7 ns hash join 115 ns 4.0 ns sort (8 bit entropy) 620 ns 5.3 ns sort (64 bit entropy) 620 ns 40 ns sort-merge join 750 ns 700 ns Intel Haswell i7 4960HQ 2.6GHz, HotSpot 1.8.0_60-b27, Mac OS X 10.11
- 47. Workshop: Notebook on DataFrames/Datasets & Spark SQL • Import Notebook into your Spark 2.0 Cluster – http://dbricks.co/sswksh2 – https://spark.apache.org/docs/latest/api/scala/index.ht ml#org.apache.spark.sql.Dataset – Work through each cell • Try challenges • Break..
- 49. Streaming in Apache Spark Streaming demands new types of streaming requirements… 3 SQL Streamin g MLlib Spark Core GraphX Functional, concise and expressive Fault-tolerant state management Unified stack with batch processing More than 51% users say most important part of Apache Spark Spark Streaming in production jumped to 22% from 14%
- 50. Streaming apps are growing more complex 4
- 51. Streaming computations don’t run in isolation • Need to interact with batch data, interactive analysis, machine learning, etc.
- 52. Use case: IoT Device Monitoring IoT events from Kafka ETL into long term storage - Prevent data loss - Prevent duplicates Status monitoring - Handle late data - Aggregate on windows on even-t time Interactivel y debug issues - consistency event stream Anomaly detection - Learn modelsoffline - Use online + continuous learning
- 53. Use case: IoT Device Monitoring Anomaly detection - Learn modelsoffline - Use online + continuous learning IoT events event stream from Kafka ETL into long term storage - Prevent data loss Status monitoring - Prevent duplicates Interactively - Handle late data debug issues - Aggregate on windows - consistency on event time Continuous Applications Not just streaming any more
- 55. The simplest way to perform streaming analytics is not having to reason about streaming at all
- 56. Static, bounded table Stream as a unbound DataFrame Streaming, unbounded table Single API !
- 57. Stream as unbounded DataFrame
- 58. Gist of Structured Streaming High-level streaming API built on Spark SQL engine Runs the same computation as batch queries in Datasets / DataFrames Event time, windowing, sessions, sources & sinks Guarantees an end-to-end exactly once semantics Unifies streaming, interactive and batch queries Aggregate data in a stream, then serve using JDBC Add, remove, change queries at runtime Build and apply ML models to your Stream
- 59. Advantages over DStreams 1. Processing with event-time, dealing with late data 2. Exactly same API for batch, streaming, and interactive 3. End-to-end exactly-once guarantees from the system 4. Performance through SQL optimizations - Logical plan optimizations, Tungsten, Codegen, etc. - Faster state management for stateful stream processing 59
- 60. Structured Streaming ModelTrigger: every 1 sec 1 2 3 Time data up to 1 Input data up to 2 data up to 3 Quer y Input: data from source as an append-only table Trigger: how frequently to check input for new data Query: operations on input usual map/filter/reduce new window, session ops
- 61. Model Trigger: every 1 sec 1 2 3 output for data up to 1 Result Quer y Time data up to 1 Input data up to 2 output for data up to 2 data up to 3 output for data up to 3 Result: final operated table updated every trigger interval Output: what part of result to write to data sink after every trigger Complete output: Write full result table every time Output complet e output
- 62. Model Trigger: every 1 sec 1 2 3 output for data up to 1 Result Quer y Time data up to 1 Input data up to 2 output for data up to 2 data up to 3 output for data up to 3 Output delta output Result: final operated table updated every trigger interval Output: what part of result to write to data sink after every trigger Complete output: Write full result table every time Delta output: Write only the rows that changed in result from previous batch
- 64. Batch ETL with DataFrame inputDF = spark.read .format("json") .load("source-path") resultDF = input .select("device", "signal") .where("signal > 15") resultDF.write .format("parquet") .save("dest-path") Read from JSON file Select some devices Write to parquet file
- 65. Streaming ETL with DataFrame input = ctxt.read .format("json") .stream("source-path") result = input .select("device", "signal") .where("signal > 15") result.write .format("parquet") .outputMode("append") .startStream("dest-path") read…stream() creates a streaming DataFrame, does not start any of the computation write…startStream() defines where & how to output the data and starts the processing
- 66. Streaming ETL with DataFrame input = spark.read .format("json") .stream("source-path") result = input .select("device", "signal") .where("signal > 15") result.write .format("parquet") .outputMode("append") .startStream("dest-path") 1 2 3 Result [append-only table] Input Output [append mode] new rows in result of 2 new rows in result of 3
- 67. Continuous Aggregations Continuously compute average signal of each type of device 67 input.groupBy("device-type") .avg("signal") input.groupBy( window("event-time", "10min"), "device type") .avg("signal") Continuously compute average signal of each type of device in last 10 minutes of event time - Windowing is just a type of aggregation - Simple API for event time based windowing
- 68. Joining streams with static data kafkaDataset = spark.read .kafka("iot-updates") .stream() staticDataset = ctxt .read . j d b c ( " j d b c : / / " , " i o t - d evi c e - i nfo ") joinedDataset = kafkaDataset.join( staticDataset, "device-type") 2 Join streaming data from Kafka with static data via JDBC to enrich the streaming data … … without having to think that you are joining streaming data
- 69. Output Modes Defines what is outputted every time there is a trigger Different output modes make sense for different queries 2 input.select("device", " s i g n a l " ) . w r i t e .outputMode("append") .format("parquet") .startStream("dest-path") Append modewith non-aggregation queries input.agg(count("*")) . w r i t e .outputMode("complete") .format("parquet") .startStream("dest-path") Complete mode with aggregation queries
- 70. Query Management query = result.write .format("parquet") .outputMode("append") .startStream("dest-path") query.stop() query.awaitTermination() query.exception() query.sourceStatuses() query.sinkStatus() 70 query: a handle to the running streaming computation for managing it - Stop it, wait for it to terminate - Get status - Get error, if terminated Multiple queries can be active at the same time Each query has unique name for keeping track
- 71. Logically: Dataset operations on table (i.e. as easy to understand as batch) Physically: Spark automatically runs the query in streaming fashion (i.e. incrementally and continuously) DataFrame Logical Plan Catalyst optimizer Continuous, incremental execution Query Execution
- 72. Batch/Streaming Execution on Spark SQL 72 DataFrame / Dataset Logical Plan Planne r SQL AST DataFram e Unresolve d Logical Plan Logical Plan Optimized Logical Plan RDDs Selected Physical Plan Analysis Logical Optimization Physical Planning CostModel Physical Plans Code Generation CatalogDataset Helluvalot of magic!
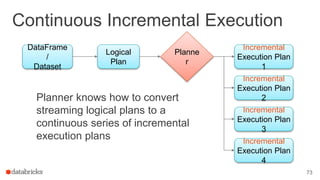
- 73. Continuous Incremental Execution Planner knows how to convert streaming logical plans to a continuous series of incremental execution plans 73 DataFrame / Dataset Logical Plan Incremental Execution Plan 1 Incremental Execution Plan 2 Incremental Execution Plan 3 Planne r Incremental Execution Plan 4
- 74. Structured Streaming: Recap • High-level streaming API built on Datasets/DataFrames • Event time, windowing, sessions, sources & sinks End-to-end exactly once semantics • Unifies streaming, interactive and batch queries • Aggregate data in a stream, then serve using JDBC Add, remove, change queries at runtime • Build and apply ML models
- 76. Demo & Workshop: Structured Streaming • Import Notebook into your Spark 2.0 Cluster • http://dbricks.co/sswksh3 (Demo) • http://dbricks.co/sswksh4 (Workshop) • Done!
- 77. Resources • docs.databricks.com • Spark Programming Guide • Structured Streaming Programming Guide • Databricks Engineering Blogs • sparkhub.databricks.com • https://spark-packages.org/
- 78. Q & A ?