KubeCon + CloudNativeCon Europe 2022 Recap - Batch/HPCの潮流とScheduler拡張事例 / Kubernetes Meetup Tokyo #51 / #k8sjp
0 likes1,463 views

KubeCon + CloudNativeCon Europe 2022 で発表された最新のHPC/Batchの潮流、及び、Scheduler拡張事例を共有します。



































![39
@everpeace
● Batch/HPC基盤系
○ [Keynote] High Performance Computing on Google Kubernetes Engine(Google)
○ Kueue: A Kubernetes-native Job Queueing (Google)
○ Volcano – Cloud Native Batch System for AI, BigData and HPC (Huawei)
○ Fast Data on-Ramp with Apache Pulsar on K8 (StreamNative)
○ Efficient Deep Learning Training with Ludwig AutoML, Ray, and Nodeless Kubernetes
(Elotl, Predibase)
● HPC系事例
○ [LT] How to Handle Fair Scheduling in a Private Academic K8s infrastructure (Masaryk
University, CESNET)
● Scheduler系
○ Resource Orchestration of HPC on Kubernetes: Where We Are Now and the Journey
Ahead! (RedHat)
○ Get More Computing Power by Helping the OS Scheduler (Intel)
○ Apache YuniKorn A Kubernetes Scheduler Plugin for Batch Workloads(Cloudera)
[参考] Kubernetes Batch + HPC Day](https://image.slidesharecdn.com/kubernetesmeetuptokyo51-batchhpcscheduler-220526063829-92a2dfeb/85/KubeCon-CloudNativeCon-Europe-2022-Recap-Batch-HPC-Scheduler-Kubernetes-Meetup-Tokyo-51-k8sjp-39-320.jpg)
![40
@everpeace
● Batch/HPC基盤系
○ Volcano: Intro & Deep Dive (Huawei)
○ Introduction to the Kubernetes WG Batch (Google, Alibaba)
○ Unlimited Data Science Libraries, One Container Image, No Installation! (Red Hat, Ghent Univ.)
○ [LT]Secure Multi User HPC Jobs in Kubernetes with Kyverno (Ohio Supercomputer Center)
● Batch系事例
○ Spark on Kubernetes: The Elastic Story (Apple)
○ Supporting Long-Lived Pods Using a Simple Kubernetes Webhook (Slack)
● HPC系事例
○ Kubernetes as a Substrate for ATLAS Compute (CERN)
○ KubeFlux: An HPC Scheduler Plugin for Kubernetes (IBM, LLNL)
● Scheduler系
○ Working your Cluster: Smarter Scheduling Decisions for Your Workloads (Intel)
○ KubeFlux: An HPC Scheduler Plugin for Kubernetes (IBM, LLNL)
[参考]KubeCon + CloudNativeCon (Batch/HPC系)](https://image.slidesharecdn.com/kubernetesmeetuptokyo51-batchhpcscheduler-220526063829-92a2dfeb/85/KubeCon-CloudNativeCon-Europe-2022-Recap-Batch-HPC-Scheduler-Kubernetes-Meetup-Tokyo-51-k8sjp-40-320.jpg)





























Ad
More Related Content
What's hot (20)
Similar to KubeCon + CloudNativeCon Europe 2022 Recap - Batch/HPCの潮流とScheduler拡張事例 / Kubernetes Meetup Tokyo #51 / #k8sjp (20)



![[GKE & Spanner 勉強会] GKE 入門](https://cdn.slidesharecdn.com/ss_thumbnails/gke01-200121090059-thumbnail.jpg?width=560&fit=bounds)








![[External] 2021.12.15 コンテナ移行の前に知っておきたいこと @ gcpug 湘南](https://cdn.slidesharecdn.com/ss_thumbnails/external2021-211216025522-thumbnail.jpg?width=560&fit=bounds)



![[OracleCodeTokyo2019] Kubernetesで実現する運用自動化の新しいアプローチとは](https://cdn.slidesharecdn.com/ss_thumbnails/oraclecodetokyo19b-2-2k8soperatorkshigeruv1-190522024836-thumbnail.jpg?width=560&fit=bounds)

Ad
More from Preferred Networks (20)




















Ad
KubeCon + CloudNativeCon Europe 2022 Recap - Batch/HPCの潮流とScheduler拡張事例 / Kubernetes Meetup Tokyo #51 / #k8sjp
- 1. Batch/HPCの潮流と Scheduler拡張事例 Kubernetes Meetup Tokyo #51, 2022/05/26(Thu) Shingo Omura, Preferred Networks, Inc. @everpeace KubeCon + CloudNativeCon Europe 2022 Recap
- 2. 2 @everpeace ▶ Preferred Networks, Inc. / エンジニア ▶ 社内向けGPUクラスタの開発運用 ▶ 社内クラスタ向けにkube-schedulerを拡張 ▶ 主にkubernetes sig-scheduling で活動中 Shingo OMURA / @everpeace
- 3. 3 @everpeace PFN のオンプレML基盤の取り組み オンプレML基盤 on Kubernetes 〜PFN、ヤフー〜 PFNにおける取り組み We're Hiring!! 機械学習Platform エンジニア
- 5. 5 KubeCon + CloudNativeCon Europe 2022 Batch/HPC on Kubernetes 最新潮流
- 6. 6 @everpeace ● KeynoteにHPCというキーワードが登場。多分初めて。 ○ Keynote: Building Bridges: Cloud Native and High Performance Computing - Ricardo Rocha, Computing Engineer, CERN ● Kubernetes Batch + HPC Dayが初開催(コロケイベント) ○ 5 sessions + 3 LTs ● KubeCon + CloudNativeConのセッションは ○ 9 session + 1 LT ("Batch", "HPC") Batch/HPC on Kubernetes 最新潮流
- 7. 7 @everpeace High Perfomance Computingの特徴 Keynote: Building Bridges: Cloud Native and High Performance Computing 大量のJobが 大量に通信し合う (x00Gbps) 超低レイテンシ InfiniBand等 ナノ〜マイクロ秒 高速に計算したいの でCPUとメモリは 近いほうがいい 多種多様な ソフトウェア が必要 (次のスライド)
- 8. 8 @everpeace HPCにおける高度なスケジューリング要求 Keynote: Building Bridges: Cloud Native and High Performance Computing Workload単位(種類の異なるPod群) Queueingしたい異なるWorkload間 に優先度つけたい リソースは公平に使いたい (寡占、独占は避けたい) 通信し合うので一気にスケジュールしたい 入力だけ違うジョブを大量に投げたい
- 9. 9 @everpeace ● 基盤系キーワード ○ Volcano(旧 kube-batch) ○ Kubernetes Batch Working Group ■ Kueue ● 事例はあまり多くない ○ HPC ■ Kubernetes as a Substrate for ATLAS Compute (Univ. of Texas, TU München) ■ KubeFlux: An HPC Scheduler Plugin for Kubernetes (IBM, LLNL) ○ Batch ■ Spark on Kubernetes: The Elastic Story (Apple) ■ Supporting Long-Lived Pods Using a Simple Kubernetes Webhook (Slack) ● Scheduler拡張系結構多い→このあと特集します Batch/HPC on Kubernetes 最新潮流
- 10. 10 @everpeace ● 基盤系 ○ Volcano: Intro & Deep Dive (Huawei) ○ Introduction to the Kubernetes WG Batch (Google, Alibaba) ○ Kueue: A Kubernetes-native Job Queueing (Google) ● 事例系 ○ Kubernetes as a Substrate for ATLAS Compute (CERN) ○ KubeFlux: An HPC Scheduler Plugin for Kubernetes (IBM, Lawrence Livermore National Laboratory) Selected Sessions: Batch/HPC on k8s 最新潮流
- 11. 11 KubeCon + CloudNativeCon Europe 2022 Batch/HPC on k8s 最新潮流 <基盤系>
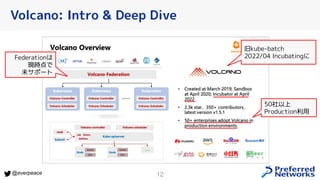
- 12. 12 @everpeace Volcano: Intro & Deep Dive 旧kube-batch 2022/04 Incubatingに 50社以上 Production利用 Federationは 現時点で 未サポート
- 13. 13 @everpeace ● CRDベー ス:Queue/PodGroup/ Job ● 独自scheduler ● Scheduling Policy がかなり多彩 Volcano: Intro & Deep Dive DRFベースのFair Share (Job単位, NS単位) Parameter Serverと Workerを近くに配置 NUMA的に空いているとこ ろにスケジュール Time Division Multiplex 一定期間以上走っている Podをpreemptionできる (zoneごとに期間等設定可) スケジュールされるまでの 時間を保証 独自Device Pluginで メモリ単位でGPU要求可 (Isolation無し) Queue単位で 最低リソース量保証
- 14. 14 @everpeace Introduction to the Kubernetes WG Batch Mission: Kubernetes coreとしてBatchをどのようにサポートするかを議論&実装 ※WG組成にあたっては結構議論があった模様(kubernetes/community#6263) ● 同日にCNCF TAG-RuntimeにBatch System Initiative(BSI) WGの提案があったり(cncf/tag-runtime#38)、 ● Kubernetes WGじゃなくてCNCF側だけで十分じゃないか(Volcano, Apache Yunikornとかあるよ)?とか、 ● Kubernetes WGとCNCF BSI WGとどういうふうに役割を分担する?とか、 ● Gang-SchedulingもQueue/Hierarchical Queueの概念もVolcanoですでに実装されているよ、とか ● Kubernetes WGはKubernetesとしてどうBatchをサポートするかにフォーカスしてCNCFのBSIとは協調関係とか。
- 15. 15 @everpeace Introduction to the Kubernetes WG Batch SIG-Appsでのコレまでの活動 ● Indexed Jobs, Suspended jobs, TTL after Finish, Accurate job tracking, Number of ready pods (Job系) ● CronJob ● Pod deletion cost SIG-Nodeでのコレまでの活動 ● Topology manager ● Topology-aware scheduling plugin (via NodeResourceTopology CRD) SIG-Schedulingでのコレまでの活動 ● Co-Scheduling ● CapacityScheduling (via ElasticResourceQuota CRD) ● Binpack (via RequestedToCapacityRatioResourceAllocation plugin)
- 16. 16 @everpeace Introduction to the Kubernetes WG Batch bit.ly/k8s-reservations まだGoogle Docsで議論中 KEP-3063: dynamic resource allocation 多分このKEPの事だと思われます
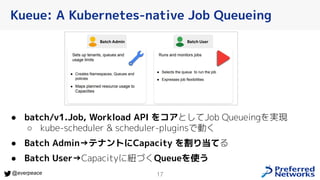
- 17. 17 @everpeace ● batch/v1.Job, Workload API をコアとしてJob Queueingを実現 ○ kube-scheduler & scheduler-pluginsで動く ● Batch Admin→テナントにCapacity を割り当てる ● Batch User→Capacityに紐づくQueueを使う Kueue: A Kubernetes-native Job Queueing
- 18. 18 @everpeace ● ClusterQueue ○ Capacity, Cohort(capacityを融 通し合うグループ)を定義 ● Queue ○ ClusterQueueを参照して属す Capacityを指定する ● Job ○ annotationでQueueを指定する ○ spec.queueNameを提案中 (k/k#106886) ● Workload API ○ 複数種Pod群によるジョブ Kueue: A Kubernetes-native Job Queueing Kueue入門 が詳しいです!
- 19. 19 @everpeace Kueue: A Kubernetes-native Job Queueing ※ Keynote: Building Bridges: Cloud Native and High Performance Computing より引用 Cohortによるリソース融 通のデモもありました!
- 20. 20 KubeCon + CloudNativeCon Europe 2022 Batch/HPC on k8s 最新潮流 <事例系>
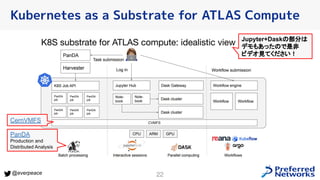
- 21. 21 @everpeace Kubernetes as a Substrate for ATLAS Compute ATLASはCERNの大型ハドロン衝突型加速器にある素粒子物理実験装置 全体で600PBytesのデータ 700K+ vCPUs(一部クラウド有) 2020年に始めたMiniK8s Gridは現在は Googleでバーストさせてトータル 100k vCPU
- 22. 22 @everpeace Kubernetes as a Substrate for ATLAS Compute CernVMFS PanDA Production and Distributed Analysis Jupyter+Daskの部分は デモもあったので是非 ビデオ見てください!
- 23. 23 @everpeace KubeFlux: An HPC Scheduler Plugin for Kubernetes Lawrence Livermore National Laboratoryの ElCapitan (2023予定) は >2 exaFLOPS!! (富岳は442 PFLOPS) ※現行設備は言及なし 紹介されたユースケースは生物系が多い 10%くらいしかcloud利用していないが 今後増えていく予定
- 24. 24 @everpeace KubeFlux: An HPC Scheduler Plugin for Kubernetes ● HPC ClusterとKubernetes Clusterが別 ● HPC ClusterからKubernetes Clusterにあるデータベースに アクセスする ● KubernetesではJupyterLabで 色々実験できるらしい ※アップロードされたスライドから引用 (実際のセッションでは使用されていなかった )
- 25. 25 KubeCon + CloudNativeCon Europe 2022 Scheduler最新拡張事例
- 26. 26 @everpeace ● Batch/HPCで登場したセッション ○ Working your Cluster: Smarter Scheduling Decisions for Your Workloads (Intel) → Telemetry Aware Scheduling (Custom Metrics API連携) ○ Resource Orchestration of HPC on Kubernetes: Where We Are Now and the Journey Ahead! (RedHat) → NUMA Aware Scheduling ○ KubeFlux: An HPC Scheduler Plugin for Kubernetes (IBM, LLNL) → HPC Scheduler & kube-scheduler連携 ● 純粋にScheduler拡張系のセッション ○ Network-aware Scheduling in Kubernetes (Ghent University) →Infrastructure Topology & Network Aware Scheduling Selected Sessions: Scheduler最新拡張事例
- 27. 27 @everpeace Telemetry Aware Scheduling Working your Cluster: Smarter Scheduling Decisions for Your Workloads Nodeメトリクスを カスタムメトリクス APIでexposeする Scheduler Extender として動作してPodの TAS Policyをenforce TAS Policy CR (Telemetry Aware Scheduling Policy)
- 28. 28 @everpeace Telemetry Aware Scheduling Working your Cluster: Smarter Scheduling Decisions for Your Workloads dontschedule strategy: health_metric メトリクスが1なNodeにはscheduleしない scheduleonmetric strategy: temperature メトリクスが少ないNodeにスケジュールされる labeling strategy: memory_used_card0メトリクスが100を超えたら card0=trueって いうnode labelを付与 deschedule stragety: tempertureメトリクスが80を超えたらdeschedule freeRAMメトリクスが200を切ったらdeschedule
- 29. 29 @everpeace NUMA Aware Scheduling Resource Orchestration of HPC on Kubernetes: Where We Are Now and the Journey Ahead! kube-schedulerはNodeのNUMA利用状況を 知らない → Topology Manager Policyがきついと PodがScheduleされてもErrorで全然 上がらない
- 30. 30 @everpeace NUMA Aware Scheduling Resource Orchestration of HPC on Kubernetes: Where We Are Now and the Journey Ahead! KubeletのPodResource APIを使って resourceのassign状況を NodeResourceTopology CRにexpose Scheduler Pluginで NodeResourceTopology CR を見てschedule判断 Node毎に生成される zone: NUMA, socket, die, etc. cost: zone間の距離を表す指標
- 31. 31 @everpeace HPC Scheduler & kube-scheduler連携 KubeFlux: An HPC Scheduler Plugin for Kubernetes コレまでのnode-centricなmodelは ● monogenousな環境向け ● Heterogeneousな環境だと効率悪い ● リソースの包含関係をグラフとして表現 ● リッチなグラフtraversal/allocaiton API ● 複雑なスケジューリングをcodeを 変更せずに実現可能 ※SIG-Schedulingのsubprojectだった Poseidonと少し違う感じがするが 詳細不明
- 32. 32 @everpeace HPC Scheduler & kube-scheduler連携 KubeFlux: An HPC Scheduler Plugin for Kubernetes ● Fluxionをsidecarで実行 ● Scheduler PluginはgRPCで連携 ● Plugin的にはPreFilter/Filterだけを実装 ● Scheudling判断はすべてFluxionに移譲
- 33. 33 @everpeace Infra Topology & Network Aware Scheduling Network-aware Scheduling in Kubernetes アプリケーション間の依存やインフラのトポロジー を考慮したスケジューリング (Contextual Awarenessと表現)が出来ていない ネットワークレイテンシや帯域を考慮した スケジューリングがしたい
- 34. 34 @everpeace Infra Topology & Network Aware Scheduling Network-aware Scheduling in Kubernetes NetworkTopology CR: region間、zone間といったネットワー クインフラのトポロジーとそれぞれの 間のネットワークコストをモデリング する
- 35. 35 @everpeace Infra Topology & Network Aware Scheduling Network-aware Scheduling in Kubernetes AppGroup CR: アプリケーション内のサービスの依存 関係、利用帯域、コストなどをモデリ ング P2はP3に依存 最低250Mi必要
- 36. 36 @everpeace Infra Topology & Network Aware Scheduling Network-aware Scheduling in Kubernetes NetworkOverhead Plugin: ● スケジュールしようとしているPodのAppGroupの通信パターンとNetworkTopology の帯域容量をみてNodeをFilter, 通信Costが低くなるようなNodeを選択 TopologicalSort Plugin: ● AppGroupの依存関係の下流から順番にスケジュール
- 37. 37 @everpeace ● HPC/Batchに特化したKeynoteやCollocated Eventが出現 ● Volcanoが機能的にはかなりリッチ ○ 独自スケジューラだったりするので採用にはなかなか勇気がいるが、Incubating Projectになったのでそろそろ検討候補か? ● Kubernetes Batch WGが出来た ○ 出来たばかりなのでまだまだこれから ○ Kueueはscheduler再開発してないのが好印象 ● HPC/Batch事例発表は多くない ○ 柔軟なスケジュールしたい場合は独自でScheduleしてたり ○ ライトにbatch/v1.Jobを使っている事例にとどまっている ○ Volcanoを使った事例発表もなかったと思われる ● kube-schedulerを拡張する事例はどんどん出てきていて面白い まとめ
- 38. Making the real world computable
- 39. 39 @everpeace ● Batch/HPC基盤系 ○ [Keynote] High Performance Computing on Google Kubernetes Engine(Google) ○ Kueue: A Kubernetes-native Job Queueing (Google) ○ Volcano – Cloud Native Batch System for AI, BigData and HPC (Huawei) ○ Fast Data on-Ramp with Apache Pulsar on K8 (StreamNative) ○ Efficient Deep Learning Training with Ludwig AutoML, Ray, and Nodeless Kubernetes (Elotl, Predibase) ● HPC系事例 ○ [LT] How to Handle Fair Scheduling in a Private Academic K8s infrastructure (Masaryk University, CESNET) ● Scheduler系 ○ Resource Orchestration of HPC on Kubernetes: Where We Are Now and the Journey Ahead! (RedHat) ○ Get More Computing Power by Helping the OS Scheduler (Intel) ○ Apache YuniKorn A Kubernetes Scheduler Plugin for Batch Workloads(Cloudera) [参考] Kubernetes Batch + HPC Day
- 40. 40 @everpeace ● Batch/HPC基盤系 ○ Volcano: Intro & Deep Dive (Huawei) ○ Introduction to the Kubernetes WG Batch (Google, Alibaba) ○ Unlimited Data Science Libraries, One Container Image, No Installation! (Red Hat, Ghent Univ.) ○ [LT]Secure Multi User HPC Jobs in Kubernetes with Kyverno (Ohio Supercomputer Center) ● Batch系事例 ○ Spark on Kubernetes: The Elastic Story (Apple) ○ Supporting Long-Lived Pods Using a Simple Kubernetes Webhook (Slack) ● HPC系事例 ○ Kubernetes as a Substrate for ATLAS Compute (CERN) ○ KubeFlux: An HPC Scheduler Plugin for Kubernetes (IBM, LLNL) ● Scheduler系 ○ Working your Cluster: Smarter Scheduling Decisions for Your Workloads (Intel) ○ KubeFlux: An HPC Scheduler Plugin for Kubernetes (IBM, LLNL) [参考]KubeCon + CloudNativeCon (Batch/HPC系)