























































Ad
More Related Content
What's hot (20)
Similar to Kubernetes環境に対する性能試験(Kubernetes Novice Tokyo #2 発表資料) (20)

![[4.20版] UE4におけるLoadingとGCのProfilingと最適化手法](https://cdn.slidesharecdn.com/ss_thumbnails/ue4loadgcprofilingoptimization420-180802153630-thumbnail.jpg?width=560&fit=bounds)











![[GTCJ2018] Optimizing Deep Learning with Chainer PFN得居誠也](https://cdn.slidesharecdn.com/ss_thumbnails/gtcj2018optimizingdeeplearningwithpfnseiyatokui-181009073509-thumbnail.jpg?width=560&fit=bounds)




Ad
More from NTT DATA Technology & Innovation (20)




















Ad
Kubernetes環境に対する性能試験(Kubernetes Novice Tokyo #2 発表資料)
- 1. マスター タイトルの書式設定 1 Kubernetes環境に対す る性能試験 2020/06/30 Kubernetes Novice Tokyo #2 @kashinoki38 Yasuhiro Horiuchi
- 2. マスター タイトルの書式設定 2 Agenda • 自己紹介 • 概要 • デモアプリと実施していること • 性能試験のための基盤 • 性能改善の営み@K8s の準備 • 性能評価の理解 • Prometheusで最低限監視しておきたい項目 • 監視以外に必要なモノ • 負荷がけ準備 • 試験実施 2
- 3. マスター タイトルの書式設定 3 自己紹介 3 • 某SIer勤務 • 業務:性能全般幅広く (プリセールス / インフラコンサル / サイジング / 性能試験 / 性能問題解決) • Kubernetes歴4ヶ月 • あんまり周りにK8sの監視ちゃんとやりながら試験してるところないなあ • ▷K8s上のアプリケーションに対する性能試験についてベストラプラクティスを 調査中 https://kashionki38.hatenablog.com/ (Hatena) @ka_shino_ki (Twitter)
- 4. マスター タイトルの書式設定 4 概要 デモアプリと実施していること 4 • Sock Shop • https://microservices-demo.github.io/ • Weaveworksのマイクロサービスデモアプリ • 靴下のECサイト • 公式GitHubは古いので、K8s v1.16への対応が必 要 ↓ https://github.com/kashinoki38/microservices- demo • 実施していること • GKE上にSock Shopをデプロイし、性能試験っぽい ことをして実施→評価→解析を回す =性能改善の営み @ K8s
- 6. マスター タイトルの書式設定 6 性能改善の営み @K8s の準備 性能評価の理解 6 • サービス監視(RED) • Rate : =Throughput, 秒間リクエスト数, 秒間PV数 • Error Rate : エラー率, 5xxとか • Duration : =ResponseTime, %ile評価が一般的 • リソース監視(USE)http://www.brendangregg.com/usemethod.html • Utilization: 使用率 E.g. CPU使用率 • Saturation : 飽和度, どれくらいキューに詰まっているか E.g. ロードアベレージ • Errors : エラーイベントの数
- 7. マスター タイトルの書式設定 7 性能改善の営み @K8s の準備 性能評価の理解 7 • サービス監視(RED) • Rate : =Throughput, 秒間リクエスト数, 秒間PV数 • Error Rate : エラー率, 5xxとか • Duration : =ResponseTime, %ile評価が一般的 • リソース監視(USE)http://www.brendangregg.com/usemethod.html • Utilization: 使用率 E.g. CPU使用率 • Saturation : 飽和度, どれくらいキューに詰まっているか E.g. ロードアベレージ • Errors : エラーイベントの数 後から情報取るのは困難、、 コマンドだけだと対象が多すぎて全部見れない、、
- 8. マスター タイトルの書式設定 8 性能改善の営み @K8s の準備 性能評価の理解 8 • サービス監視(RED) • Rate : =Throughput, 秒間リクエスト数, 秒間PV数 • Error Rate : エラー率, 5xxとか • Duration : =ResponseTime, %ile評価が一般的 • リソース監視(USE)http://www.brendangregg.com/usemethod.html • Utilization: 使用率 E.g. CPU使用率 • Saturation : 飽和度, どれくらいキューに詰まっているか E.g. ロードアベレージ • Errors : エラーイベントの数 メトリクス監視はPrometheusででき る 後から情報取るのは困難、、 コマンドだけだと対象が多すぎて全部見れない、、
- 9. マスター タイトルの書式設定 9 性能改善の営み @K8s の準備 Prometheusで最低限監視しておきたい項目 9 種別 監視対象 メトリクス How 観点 サービス監視 RED Jmeter クライアント側 Throughput ResponseTime Error% Jmeterのメトリクスを収集 BackendListner->InfluxDB- 試験の性能目標に対して達成して いるかどうか システム側 Throughput ResponseTime Error% Istioのテレメトリ機能で各serviceの リクスを収集 現状、評価よりは解析用途 (SLOを達成しているかどう か?) リソース監視 USE Node CPU/Memory/NW/D sk使用量 NodeExporterをDaemonSetとして配置 収集 各Nodeのリソース上限に抵触して いないか Pod/Containe CPU/Memory使用量 cAdvisorにて収集 (Kubeletバイナリに統合されているの scrapeの設定のみでOK) Limitsに抵触していないか 急に死んでいないか • これに加え主要なMWのメトリクスも見ておきたい • Nginx / MySQL / MongoDB • さらに管理リソースの監視も必要のはず • K8s, Istioのコントロールプレーン • kubelet, kube-proxy, envoy トラブル事例含 めて調査中
- 10. マスター タイトルの書式設定 11 • Observabilityの3柱 • Metrics→Done by Prometheus • Logging→Loki • 重要性:基本的に永続化されない。kubectl logsじゃきつ い トラシューしたいときに残っているようにしたい • Tracing→ • 重要性:MSA数珠つなぎでややこしい E2Eで遅くても原因のサービスにたどり着けない 11 https://peter.bourgon.org/blog/2017/02/21/metri -tracing-and-logging.html トラブル事例含め て調査中 トラブル事例含め て調査中 性能改善の営み @K8s の準備 監視以外に必要なモノ
- 11. マスター タイトルの書式設定 12 性能改善の営み @K8s の準備 12 Test Environment Prometheus Loggin g sock- shop istio- system monitorin g jmete r Metric s Tracin g 負荷がけ サンプルアプリ Grafana
- 12. マスター タイトルの書式設定 13 性能改善の営み @K8s の準備 負荷がけ準備 13 • 負荷がけクライアントもK8sにデプロイしたい • とりあえずJmeterで探してみる • Jmeter Operator発見 https://github.com/kubernauts/jmeter-operator • Operatorが割とCPUを食うので一旦Operatorはやめて、Deploymentだ けに PodのCPU使用率
- 13. マスター タイトルの書式設定 14 性能改善の営み @K8s の準備 14 Test Environment Prometheus Loggin g sock- shop istio- system monitorin g jmete r Metric s Tracin g 負荷がけ サンプルアプリ Grafana
- 14. マスター タイトルの書式設定 16 試験実施 16 • シナリオ • 登録済みのユーザによる、ソックス購入シナリオ • jmeterシナリオ https://github.com/kashinoki38/microservices- demo/blob/master/deploy/kubernetes/manifests-loadtest/scenario.jmx • シナリオフロー https://github.com/kashinoki38/microservices- demo/blob/master/deploy/kubernetes/loadtests/scenario-definition.xlsx
- 15. マスター タイトルの書式設定 17 試験実施 – shot1 17 • 目標負荷:100tps(Transaction = PV) • 未達 Jmeter実行結果
- 16. マスター タイトルの書式設定 18 試験実施 – shot1 Node1台のCPUがサチっている 18 • NodeのCPU使用率を確認すると1台の使用率がサチっている NodeのCPU使用率
- 17. マスター タイトルの書式設定 19 試験実施 – shot1 Node1台のCPUがサチっている 19 • NodeのCPU使用率を確認すると1台の使用率がサチっている ノードを追加 後から思えばpodの ノード偏りもあった NodeのCPU使用率
- 18. マスター タイトルの書式設定 20 試験実施 – shot2 20 • 目標負荷:100tps(Transaction = PV) • 達成 Jmeter実行結果
- 19. マスター タイトルの書式設定 21 試験実施 – shot3 21 • 目標負荷:150tps(Transaction = PV) • 未達 • Topページが大幅に遅延 Jmeter実行結果
- 20. マスター タイトルの書式設定 22 試験実施 – shot3 22 • 目標負荷:150tps(Transaction = PV) • 未達 • Topページが大幅に遅延 • 解析 • front-end podのContainerのCPU使用量がLimits付近 front-end containerのCPU使 用量 TopのJmeterレスポンスタイム
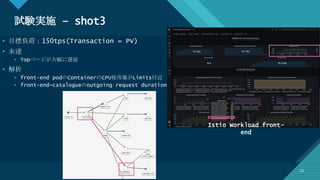
- 21. マスター タイトルの書式設定 23 試験実施 – shot3 23 • 目標負荷:150tps(Transaction = PV) • 未達 • Topページが大幅に遅延 • 解析 • front-end podのContainerのCPU使用量がLimits付近 • front-end→catalogueのoutgoing request durationが遅い Istio Workload front- end
- 22. マスター タイトルの書式設定 24 試験実施 – shot3 24 • 目標負荷:150tps(Transaction = PV) • 未達 • Topページが大幅に遅延 • 解析 • front-end podのContainerのCPU使用量がLimits付近 • front-end→catalogueのoutgoing request durationが遅い • catalogueのRequest Durationが遅い Istio Workload front- end Istio Workload catalogue
- 23. マスター タイトルの書式設定 25 試験実施 – shot3 25 • 目標負荷:150tps(Transaction = PV) • 未達 • Topページが大幅に遅延 • 解析 • front-end podのContainerのCPU使用量がLimits付近 • front-end→catalogueのoutgoing request duration が遅い • catalogueのRequest Durationが遅い • catalogue containerがrestartしている時間で Jmeterのレスポンスが遅延 not ready catalogue containerのCPU使 用率 TopのJmeterレスポンスタイム catalogue container ready 数 catalogue container restart
- 24. マスター タイトルの書式設定 26 試験実施 – shot3 26 • 目標負荷:150tps(Transaction = PV) • 未達 • Topページが大幅に遅延 • 解析 • front-end podのContainerのCPU使用量がLimits付近 • front-end→catalogueのoutgoing request duration が遅い • catalogueのRequest Durationが遅い • catalogue containerがrestartしている時間で Jmeterのレスポンスが遅延 • catalogue containerがrestartしている時間でnpm ERR!頻発 catalogue podのログ
- 25. マスター タイトルの書式設定 27 試験実施 – shot3 27 • 目標負荷:150tps(Transaction = PV) • 未達 • Topページが大幅に遅延 • 解析 • front-end podのContainerのCPU使用量がLimits付近 • front-end→catalogueのoutgoing request duration が遅い • catalogueのRequest Durationが遅い • catalogue containerがrestartしている時間で Jmeterのレスポンスが遅延 • catalogue containerがrestartしている時間でnpm ERR!頻発 • ボトルネック仮説 • front-endのCPU枯渇 → Podを増設、プロファイリング • catalogueの遅延+エラー頻発 → 詳細解析(How?)
- 26. マスター タイトルの書式設定 28 試験実施 – shot3 28 • 目標負荷:150tps(Transaction = PV) • 未達 • Topページが大幅に遅延 • 解析 • front-end podのContainerのCPU使用量がLimits付近 • front-end→catalogueのoutgoing request duration が遅い • catalogueのRequest Durationが遅い • catalogue containerがrestartしている時間で Jmeterのレスポンスが遅延 • catalogue containerがrestartしている時間でnpm ERR!頻発 • ボトルネック仮説 • front-endのCPU枯渇 → Podを増設、プロファイリング • catalogueの遅延+エラー頻発 → 詳細解析(How?) 力尽きた
- 27. マスター タイトルの書式設定 29 今後の改善事項 29 • まとめ • Sock Shopに対して最低限のリソースとサービスメトリクスを評価する基盤作っ た • 作業途中のものは随時ここに →https://github.com/kashinoki38/microservices- demo/tree/master/deploy/kubernetes • とりあえず性能改善の営みをなんとなく回せる • 改善事項 • ボトルネック情報の蓄積←ぜひ教えて下さい! • 試験実施改善 • 自動化 • シナリオのバージョン管理+試験結果との紐付け • 詳細な解析 • MWリソース、プロファイリングの差し込み方 • Jaeger, Kiali, Lokiの有効活用
Editor's Notes
- #30: ・シナリオのバージョン管理は実行時にgitにpushすればいい話 #シナリオに変更があった場合に ・githubのリンクを試験結果ダッシュボードに出せば良い