以 Kubernetes 部屬 Spark 大數據計算環境
0 likes917 views

This document summarizes using Kubernetes to deploy a Spark big data computing environment. It discusses why Kubernetes is preferable to other solutions like Cloudera for managing Spark. The architecture of running Spark on Kubernetes is shown, with the Spark master and worker controllers. Performance is compared between Spark on Kubernetes and standalone Spark using the SparkPI and WordCount examples. Support for Spark 2.3.0 on Kubernetes is now official.



















以 Kubernetes 部屬 Spark 大數據計算環境
- 1. Getter May. 10 以 Kubernetes 部屬 Spark 大數據計算環境
- 2. Who am I? ● Getter (楊曜佑) ○ inwinstack RD(Ready to Die) engineer ○ OpenStack integration & Operation ○ K8S Beginner
- 3. Why use K8S?
- 4. User We need a Big Data solution!! Okay….
- 5. About Big Data Solution ● Famous management tool -- Cloudera ○ Too big ○ Too difficult ○ User does not want it (Most Important) ● Famous container management tool -- K8S ○ Small ○ Simple ○ User want it
- 7. Basic Hadoop MapReduce Compoment ● YARN ○ NodeManager ○ ResourceManager ● HDFS ○ NameNode ○ DataNode
- 8. Basic Spark Compoment ● Master ● Slave ● Storage
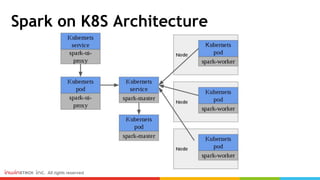
- 9. Spark on K8S Architecture
- 10. Spark on K8S Architecture ● https://github.com/kubernetes/examples/tree/m aster/staging/spark ○ spark-master-controller ○ spark-master-service ○ spark-work-controller ○ spark-ui-proxy-controller ○ spark-ui-proxy-service
- 11. Spark on K8S Architecture
- 12. Spark on K8S Architecture ● Only one master ● Using nodeAffinity to avoid Worker and Master same node ● Using podAntiAffinity to ensure each node have only one worker
- 13. About storage ● HDFS ● Persistent Volumes ○ iSCSI ○ NFS ○ CephFS ○ RBD ○ Etc...
- 14. Environment ● 3 node ● K8S version v1.9.0 ○ kubespray ○ calico ● Spark version 2.2.0
- 15. Simple performance compare ● https://codait.github.io/spark-bench/ -- SparkPI ○ slices: 10000 ■ Spark on K8S ■ Spark standalone ● Spark-example -- WordCount ○ Input file: 3G ■ Spark on K8S with NFS ■ Spark standalone with NFS
- 16. Offical support spark 2.3.0 on K8S
- 17. How it works
- 18. How it works $ bin/spark-submit --master k8s://https://<k8s-apiserver-host>:<k8s-apiserver-port> --deploy-mode cluster --name spark-pi --class org.apache.spark.examples.SparkPi --conf spark.executor.instances=5 --conf spark.kubernetes.container.image=<spark-image> local:///path/to/examples.jar
- 19. Currently experimental... ● Client mode is not currently supported. ● Future Work ○ PySpark ○ R ○ Dynamic Executor Scaling ○ Local File Dependency Management ○ Spark Application Management ○ Job Queues and Resource Management
- 20. www.inwinstack.com Thank You! 迎 棧 科 技 股 份 有 限 公 司