Lambda Architectures in Practice
10 likes1,915 views

The document discusses the implementation of lambda architectures using technologies like Kafka, Hadoop, Storm, and Druid. It highlights the challenges of streaming data pipelines and emphasizes the necessity of achieving low-latency data processing while ensuring data consistency. The document concludes that while lambda architectures may evolve, they effectively address the need for reliable data pipelines through various open-source tools.





































































Lambda Architectures in Practice
- 1. LAMBDA ARCHITECTURES IN PRACTICE KAFKA · HADOOP · STORM · DRUID GIAN MERLINO DRUID COMMITTER · SOFTWARE ENGINEER @ METAMARKETS
- 2. InfoQ.com: News & Community Site • 750,000 unique visitors/month • Published in 4 languages (English, Chinese, Japanese and Brazilian Portuguese) • Post content from our QCon conferences • News 15-20 / week • Articles 3-4 / week • Presentations (videos) 12-15 / week • Interviews 2-3 / week • Books 1 / month Watch the video with slide synchronization on InfoQ.com! http://www.infoq.com/presentations /lambda-arch-case-study
- 3. Purpose of QCon - to empower software development by facilitating the spread of knowledge and innovation Strategy - practitioner-driven conference designed for YOU: influencers of change and innovation in your teams - speakers and topics driving the evolution and innovation - connecting and catalyzing the influencers and innovators Highlights - attended by more than 12,000 delegates since 2007 - held in 9 cities worldwide Presented at QCon San Francisco www.qconsf.com
- 4. PROBLEM STREAMING DATA PIPELINES CHALLENGES NO DATA LEFT BEHIND INFRASTRUCTURE THE “RAD”-STACK PLATFORM DEVELOPMENT AND OPERATIONS TOOLS OVERVIEW
- 5. THE PROBLEM
- 6. THE PROBLEM
- 7. THE PROBLEM
- 8. THE PROBLEM ‣ Business intelligence for ad-tech ‣ Arbitrary and interactive exploration ‣ Multi-tenancy: thousands of concurrent users ‣ Recency: explore current data, alert on major changes ‣ Efficiency: each event is individually very low-value ‣ Data model: must join impressions with clicks
- 9. 2013 FINDING A SOLUTION ‣ Load all your data into Hadoop. Query it. Done! ‣ Good job guys, let’s go home
- 10. 2013 HADOOP BENEFITS AND DRAWBACKS ‣ HDFS is a scalable, reliable storage technology ‣ MapReduce is great for data-parallel computation at scale ‣ But Hadoop MapReduce is not optimized for low latency ‣ To optimize queries, we need a query layer ‣ To load data quickly, we need streaming ingestion
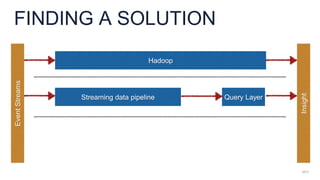
- 11. 2013 FINDING A SOLUTION Query Layer Hadoop EventStreams Insight Streaming data pipeline
- 12. 2013 FINDING A SOLUTION Streaming data pipeline RDBMS Hadoop EventStreams Insight
- 13. 2013 FINDING A SOLUTION Streaming data pipeline NoSQL K/V Stores Hadoop EventStreams Insight
- 14. 2013 FINDING A SOLUTION Streaming data pipeline Commercial Databases Hadoop EventStreams Insight
- 15. 2013 FINDING A SOLUTION Streaming data pipeline Hadoop EventStreams Insight
- 16. DRUID ‣ Druid project started in 2011, open sourced in Oct. 2012 ‣ Designed for low latency ingestion and slice-and-dice aggregation ‣ Growing Community • ~45 contributors • Used in production at numerous large and small organizations ‣ Cluster vitals ‣ 10+ trillion events, 200TB of compressed queryable data ‣ Ingesting over 450,000 events/sec on average ‣ 90th/95th/99th percentile queries within 1s/2s/10s
- 18. TIME SERIES DATA ‣ Unifying feature: some notion of “event timestamp” ‣ Questions are typically also time-oriented ‣ Monitoring: Plot CPU usage over the past 3 days, in 5-min buckets ‣ BI: Which accounts brought in the most revenue this week? ‣ Web analytics: How many unique users today? By OS? By page?
- 19. GOALS ‣ Low-latency results ‣ Strong guarantees for historical data
- 20. DATA PIPELINE
- 21. DATA PIPELINE ‣ Data bus ‣ Decouples data acquisition from processing ‣ Can buffer as many unprocessed messages as you have disk
- 22. DATA PIPELINE ‣ Stream processor ‣ Join impressions/clicks ‣ Transform data
- 23. DATA PIPELINE
- 24. DATA PIPELINE ‣ Store hour-partitioned in S3 ‣ Can run Hadoop jobs on it
- 25. DATA PIPELINE
- 26. λ
- 27. DEFINITION ‣ Hybrid batch/streaming data pipeline ‣ Batch technologies • Hadoop MapReduce • Spark ‣ Streaming technologies • Storm • Spark Streaming • Samza
- 28. WHY HYBRID? ‣ This sounds insane ‣ Need to develop for both systems ‣ Need to operate both systems ‣ Nobody really wants to do this
- 29. WHY HYBRID? ‣ We want low-latency results ‣ We also want strong guarantees for historical data ‣ Many popular streaming systems are still immature ‣ The state of things will improve in the future ‣ …but that doesn’t help you right now
- 40. COPING WITH FAULTS ‣ “Exactly once” semantics ‣ Transactions ‣ Idempotency ‣ Adding an element to a set ‣ Some kinds of sketches (HyperLogLog) ‣ Doesn’t work well for counters
- 41. LATE DATA ‣ Timeline-oriented operations are common in stream processing ‣ Windowed aggregates ‣ top pages per hour ‣ unique users per hour ‣ request counts per minute ‣ Group-by-key of related events ‣ user session analysis ‣ impression/click association
- 42. LATE DATA ‣ Similar challenges with both ‣ When can we be sure we have all the data? ‣ Normally, within a minute ‣ Or if a server is slow, a few minutes… ‣ Or if a server is down, a few hours or days… ‣ We don’t want to compromise between data quality and latency
- 43. REPROCESSING ‣ Something is broken! ‣ Your data was revised ‣ Or your code had a bug
- 44. WHY HYBRID? Late Data Reprocessin g Transactions * Streaming data store, not actually a stream processo *
- 45. WHY HYBRID? Globally ordered micro-batches Internal– yes; external– no Work in progress Late Data Reprocessin g Batch– yes; Streaming– no Transactions * Streaming data store, not actually a stream processo *
- 46. WHY HYBRID? Globally ordered micro-batches Internal– yes; external– no Work in progress Late Data Reprocessin g Depends on user code Windows based on received time, not actual time Depends on user code Batch– yes; Streaming– no Batch– unlimited; Streaming– windowPeriod Transactions * Streaming data store, not actually a stream processo *
- 47. WHY HYBRID? Globally ordered micro-batches Internal– yes; external– no Work in progress Transactions Late Data Reprocessin g Rewind with fresh state Can use non- streaming Spark Rewind with fresh state Depends on user code Windows based on received time, not actual time Depends on user code Batch– yes; Streaming– no Can use batch ingestion Batch– unlimited; Streaming– windowPeriod* Streaming data store, not actually a stream processo *
- 48. WHY NOT HYBRID? ‣ Batch-only? ‣ If ingestion latencies are good enough, that’s great! ‣ Streaming-only? ‣ OK if you have transactions and a way to deal with late data ‣ Current tools do require you to be careful
- 50. DEVELOPMENT ‣ Need code to run on two very different systems ‣ Maintaining two codebases is perilous ‣ Productivity loss ‣ Code drift ‣ Difficulty training new developers
- 51. PROGRAMMING MODEL ‣ “Query language,” if you prefer ‣ Write once, run… at least twice ‣ Open-source options ‣ Spark + Spark streaming (if you’re in the Spark ecosystem) ‣ Summingbird (key/value aggregation oriented) ‣ Or develop in-house for your use cases ‣ This investment can make sense if you have more pipeline developers than infrastructure developers
- 52. PROGRAMMING MODEL ‣ We built “Starfire,” a Scala library for stream transformation ‣ Built around operators ‣ map, flatMap, filter ‣ groupBy, join ‣ lookup ‣ sample ‣ union
- 53. PROGRAMMING MODEL ‣ Load two data streams ‣ Join streams on shared key ‣ Produce combined records ‣ Export data
- 55. EXECUTION ‣ User code generates a system-agnostic computation graph ‣ Drivers optimize and compile the graph for each system ‣ Current drivers: ‣ Local (for unit tests) ‣ Hadoop (using Cascading) ‣ Storm ‣ Samza (beta)
- 56. BENEFITS ‣ Hedge your bets around infrastructure ‣ New drivers can run all existing user code ‣ Separate system optimization from code development ‣ Improved grouping engine without any user code changes ‣ We have many more pipeline developers than infrastructure developers ‣ Developer productivity increased ‣ We use Starfire even for batch-only data pipelines
- 58. OPERATIONS ‣ Need to operate two very different systems ‣ Must maintain “no data left behind” ‣ Cornerstones of operations ‣ Tools ‣ Metrics ‣ Alerts
- 59. TOOLS ‣ Hadoop job service ‣ Watch S3 for new data from Kafka ‣ Automatically process data after a few hours ‣ Retry failed jobs, alerts on repeated failures
- 60. TOOLS ‣ Storm job service ‣ Submit jobs to Nimbus, the Storm scheduler ‣ Monitor for failed jobs ‣ Alert on deployment failures
- 61. TOOLS ‣ Backfill tool ‣ Run backfills for particular intervals ‣ Can be used for data changes or algorithm changes ‣ Ensures alignment on Druid segment granularity
- 62. TOOLS ‣ Configuration management tool ‣ Control which version of the code should be running ‣ Manage schemas for each pipeline ‣ Manage quotas for each pipeline ‣ Central audit logs for configuration changes
- 63. STREAM METRICS
- 64. STREAM METRICS
- 65. DO TRY THIS AT HOME
- 66. 2013 CORNERSTONES ‣ Druid - druid.io - @druidio ‣ Storm - storm.incubator.apache.org - @stormprocessor ‣ Hadoop - hadoop.apache.org ‣ Kafka - kafka.apache.org - @apachekafka
- 67. GLUE storm-kafka Tranquility Camus / Secor Druid Hadoop indexer
- 68. TAKE AWAYS ‣ Lambda architectures may not be with us forever ‣ But they solve a real problem: eventually consistent data pipelines using popular open-source technologies ‣ Complexity can be managed with tools and practices
- 70. Watch the video with slide synchronization on InfoQ.com! http://www.infoq.com/presentations/lambda- arch-case-study