



































![Deploying a pipeline
● Command line interface for all operations
usage: dataduct pipeline activate [-h] [-m MODE] [-f] [-t TIME_DELTA] [-b]
pipeline_definitions
[pipeline_definitions ...]](https://image.slidesharecdn.com/2015-10-10dataductreinvent-160716202550/85/Large-Scale-ETL-Data-Flows-With-Data-Pipeline-and-Dataduct-38-320.jpg)



























































Ad
More Related Content
What's hot (20)
Viewers also liked (20)


















Ad
Similar to Large-Scale ETL Data Flows With Data Pipeline and Dataduct (15)















Ad
Recently uploaded (20)
![Get & Download Wondershare Filmora Crack Latest [2025]](https://cdn.slidesharecdn.com/ss_thumbnails/revolutionizingresidentialwi-fi-250422112639-60fb726f-250429170801-59e1b240-thumbnail.jpg?width=560&fit=bounds)



















Large-Scale ETL Data Flows With Data Pipeline and Dataduct
- 1. © 2015, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Sourabh Bajaj, Software Engineer, Coursera October 2015 BDT404 Large-Scale ETL Data Flows With Data Pipeline and Dataduct
- 2. What to Expect from the Session ● Learn about: • How we use AWS Data Pipeline to manage ETL at Coursera • Why we built Dataduct, an open source framework from Coursera for running pipelines • How Dataduct enables developers to write their own ETL pipelines for their services • Best practices for managing pipelines • How to start using Dataduct for your own pipelines
- 3. Coursera
- 4. Coursera
- 5. Coursera
- 6. 120 partners 2.5 million course completions Education at Scale 15 million learners worldwide 1300 courses
- 7. Data Warehousing at Coursera Amazon Redshift 167 Amazon Redshift users 1200 EDW tables 22 source systems 6 dc1.8xlarge instances 30,000,000 queries run
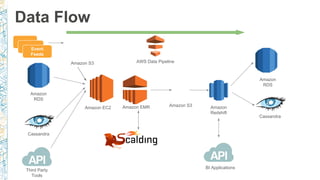
- 8. Data Flow Amazon Redshift Amazon RDS Amazon EMR Amazon S3 Event Feeds Amazon EC2 Amazon RDS Amazon S3 BI Applications Third Party Tools Cassandra Cassandra AWS Data Pipeline
- 9. Data Flow Amazon Redshift Amazon RDS Amazon EMR Amazon S3 Event Feeds Amazon EC2 Amazon RDS Amazon S3 BI Applications Third Party Tools Cassandra Cassandra AWS Data Pipeline
- 10. Data Flow Amazon Redshift Amazon RDS Amazon EMR Amazon S3 Event Feeds Amazon EC2 Amazon RDS Amazon S3 BI Applications Third Party Tools Cassandra Cassandra AWS Data Pipeline
- 11. Data Flow Amazon Redshift Amazon RDS Amazon EMR Amazon S3 Event Feeds Amazon EC2 Amazon RDS Amazon S3 BI Applications Third Party Tools Cassandra Cassandra AWS Data Pipeline
- 12. Data Flow Amazon Redshift Amazon RDS Amazon EMR Amazon S3 Event Feeds Amazon EC2 Amazon RDS Amazon S3 BI Applications Third Party Tools Cassandra Cassandra AWS Data Pipeline
- 13. ETL at Coursera 150 Active pipelines 44 Dataduct developers
- 14. Requirements for an ETL system Fault Tolerance Scheduling Dependency Management Resource Management Monitoring Easy Development
- 15. Requirements for an ETL system Fault Tolerance Scheduling Dependency Management Resource Management Monitoring Easy Development
- 16. Requirements for an ETL system Fault Tolerance Scheduling Dependency Management Resource Management Monitoring Easy Development
- 17. Requirements for an ETL system Fault Tolerance Scheduling Dependency Management Resource Management Monitoring Easy Development
- 18. Requirements for an ETL system Fault Tolerance Scheduling Dependency Management Resource Management Monitoring Easy Development
- 19. Requirements for an ETL system Fault Tolerance Scheduling Dependency Management Resource Management Monitoring Easy Development
- 20. Requirements for an ETL system Fault Tolerance Scheduling Dependency Management Resource Management Monitoring Easy Development
- 21. Dataduct
- 22. ● Open source wrapper around AWS Data Pipeline Dataduct
- 23. Dataduct ● Open source wrapper around AWS Data Pipeline ● It provides: • Code reuse • Extensibility • Command line interface • Staging environment support • Dynamic updates
- 24. Dataduct ● Repository • https://github.com/coursera/dataduct ● Documentation • http://dataduct.readthedocs.org/en/latest/ ● Installation • pip install dataduct
- 25. Let’s build some pipelines
- 26. Pipeline 1: Amazon RDS → Amazon Redshift ● Let’s start with a simple pipeline of pulling data from a relational store to Amazon Redshift Amazon Redshift Amazon RDS Amazon S3 Amazon EC2 AWS Data Pipeline
- 27. Pipeline 1: Amazon RDS → Amazon Redshift
- 28. ● Definition in YAML ● Steps ● Shared Config ● Visualization ● Overrides ● Reusable code Pipeline 1: Amazon RDS → Amazon Redshift
- 29. Pipeline 1: Amazon RDS → Amazon Redshift (Steps) ● Extract RDS • Fetch data from Amazon RDS and output to Amazon S3
- 30. Pipeline 1: Amazon RDS → Amazon Redshift (Steps) ● Create-Load-Redshift • Create table if it doesn’t exist and load data using COPY.
- 31. Pipeline 1: Amazon RDS → Amazon Redshift ● Upsert • Update and insert into the production table from staging.
- 32. Pipeline 1: Amazon RDS → Amazon Redshift (Tasks) ● Bootstrap • Fully automated • Fetch latest binaries from Amazon S3 for Amazon EC2 / Amazon EMR • Install any updated dependencies on the resource • Make sure that the pipeline would run the latest version of code
- 33. Pipeline 1: Amazon RDS → Amazon Redshift ● Quality assurance • Primary key violations in the warehouse. • Dropped rows: By comparing the number of rows. • Corrupted rows: By comparing a sample set of rows. • Automatically done within UPSERT
- 34. Pipeline 1: Amazon RDS → Amazon Redshift ● Teardown • Amazon SNS alerting for failed tasks • Logging of task failures • Monitoring • Run times • Retries • Machine health
- 35. Pipeline 1: Amazon RDS → Amazon Redshift (Config) ● Visualization • Automatically generated by Dataduct • Allows easy debugging
- 36. Pipeline 1: Amazon RDS → Amazon Redshift ● Shared Config • IAM roles • AMI • Security group • Retries • Custom steps • Resource paths
- 37. Pipeline 1: Amazon RDS → Amazon Redshift ● Custom steps • Open-sourced steps can easily be shared across multiple pipelines • You can also create new steps and add them using the config
- 38. Deploying a pipeline ● Command line interface for all operations usage: dataduct pipeline activate [-h] [-m MODE] [-f] [-t TIME_DELTA] [-b] pipeline_definitions [pipeline_definitions ...]
- 39. Pipeline 2: Cassandra → Amazon Redshift Amazon Redshift Amazon EMR (Scalding) Amazon S3 Amazon S3 Amazon EMR (Aegisthus) Cassandra AWS Data Pipeline
- 40. ● Shell command activity to rescue Pipeline 2: Cassandra → Amazon Redshift
- 41. ● Shell command activity to rescue ● Priam backups of Cassandra to Amazon S3 Pipeline 2: Cassandra → Amazon Redshift
- 42. ● Shell command activity to rescue ● Priam backups of Cassandra to S3 ● Aegisthus to parse SSTables into Avro dumps Pipeline 2: Cassandra → Amazon Redshift
- 43. ● Shell command activity to rescue ● Priam backups of Cassandra to Amazon S3 ● Aegisthus to parse SSTables into Avro dumps ● Scalding to process Aegisthus output • Extend the base steps to create more patterns Pipeline 2: Cassandra → Amazon Redshift
- 44. Pipeline 2: Cassandra → Amazon Redshift
- 45. ● Custom steps • Aegisthus • Scalding Pipeline 2: Cassandra → Amazon Redshift
- 46. ● EMR-Config overrides the defaults Pipeline 2: Cassandra → Amazon Redshift
- 47. ● Multiple output nodes from transform step Pipeline 2: Cassandra → Amazon Redshift
- 48. ● Bootstrap • Save every pipeline definition • Fetching new jar for the Amazon EMR jobs • Specify the same Hadoop / Hive metastore installation Pipeline 2: Cassandra → Amazon Redshift
- 49. Data products ● We’ve talked about data into the warehouse ● Common pattern: • Wait for dependencies • Computation inside redshift to create derived tables • Amazon EMR activities for more complex process • Load back into MySQL / Cassandra • Product feature queries MySQL / Cassandra ● Used in recommendations, dashboards, and search
- 50. Recommendations ● Objective • Connecting the learner to right content ● Use cases: • Recommendations email • Course discovery • Reactivation of the users
- 51. Recommendations ● Computation inside Amazon Redshift to create derived tables for co-enrollments ● Amazon EMR job for model training ● Model file pushed to Amazon S3 ● Prediction API uses the updated model file ● Contract between the prediction and the training layer is via model definition.
- 52. Internal Dashboard ● Objective • Serve internal dashboards to create a data driven culture ● Use Cases • Key performance indicators for the company • Track results for different A/B experiments
- 54. ● Do: • Monitoring (run times, retries, deploys, query times) Learnings
- 55. ● Do: • Monitoring (run times, retries, deploys, query times) • Code should live in library instead of scripts being passed to every pipeline Learnings
- 56. ● Do: • Monitoring (run times, retries, deploys, query times) • Code should live in library instead of scripts being passed to every pipeline • Test environment in staging should mimic prod Learnings
- 57. ● Do: • Monitoring (run times, retries, deploys, query times) • Code should live in library instead of scripts being passed to every pipeline • Test environment in staging should mimic prod • Shared library to democratize writing of ETL Learnings
- 58. ● Do: • Monitoring (run times, retries, deploys, query times) • Code should live in library instead of scripts being passed to every pipeline • Test environment in staging should mimic prod • Shared library to democratize writing of ETL • Using read-replicas and backups Learnings
- 59. ● Don’t: • Same code passed to multiple pipelines as a script Learnings
- 60. ● Don’t: • Same code passed to multiple pipelines as a script • Non version controlled pipelines Learnings
- 61. ● Don’t: • Same code passed to multiple pipelines as a script • Non version controlled pipelines • Really huge pipelines instead of modular small pipelines with dependencies Learnings
- 62. ● Don’t: • Same code passed to multiple pipelines as a script • Non version controlled pipelines • Really huge pipelines instead of modular small pipelines with dependencies • Not catching resource timeouts or load delays Learnings
- 63. Dataduct ● Code reuse ● Extensibility ● Command line interface ● Staging environment support ● Dynamic updates
- 64. Dataduct ● Repository • https://github.com/coursera/dataduct ● Documentation • http://dataduct.readthedocs.org/en/latest/ ● Installation • pip install dataduct
- 65. Questions? Also, we are hiring! https://www.coursera.org/jobs
- 66. Remember to complete your evaluations!
- 67. Thank you! Also, we are hiring! https://www.coursera.org/jobs Sourabh Bajaj sb2nov @sb2nov