Learning Deep Architectures for AI (第 3 回 Deep Learning 勉強会資料; 松尾)
81 likes62,934 views


![松尾まとめ:広義のDeep Learning
もしくはDeep Architecture
• [勝ち組1] DBN: Deep Belief Network
– Restricted Boltzman Machine(RBM)で層ごとに訓練
• その方法 CD: Contrastive Divergence
– Deep Boltzman Machine (DBM)に変換できる
– Hintonさんら(トロント大) 狭義のDeep Learning
• [勝ち組2] Stacked Auto-Encoders
– Auto-Encoders
– Bengioさんら(モントリオール大) たぶんこれがいい
• [惜しい]
– Convolutional Network:特に視覚。2次元の制約を使う。LeCunさんたちのグ
ループ(ニューヨーク大)
– Self-taught Learning:1段でunsupervised + supervised。Ngさんたちのグループ
(スタンフォード大)
– Multi-task learning, transfer learning:目の付けどころはいいが、ちょっと違う概
念
• [負け組]
– Deep Neural Network, Multi-layer Neural Network(昔からある)
– Deep Graphical Model(昔からある)](https://image.slidesharecdn.com/deepv2matsuo-121229003803-phpapp01/85/Learning-Deep-Architectures-for-AI-3-Deep-Learning-2-320.jpg)












![[Loosli, Canu, & Bottou, 2007]
Denoising auto encodersを使っている](https://image.slidesharecdn.com/deepv2matsuo-121229003803-phpapp01/85/Learning-Deep-Architectures-for-AI-3-Deep-Learning-15-320.jpg)

![主役のAuto-Encoder
• Auto-encoder framework [Lecaum 1987][Bourland 1988][Hinton 1994] : unsupervised feature construction
method の一つ。
• auto-: 「自己の」 auto-encoder を直訳すると自己符号器
• encoder, decoder, reconstruction error の 3 つの要素から構成。
• encoder と decoder の合成写像が入力値を再現するような学習を行う。
• 学習は入力値と出力値の誤差(reconstruction error)を最小化することで行われる。
• この操作によって、入力値をより適切な表現に写像する auto-encoder が得られる。
𝑇
𝑡 𝑡
𝜃 = argmin 𝒥DAE (𝜃) = argmin 𝐿 𝑥 , 𝑔 𝜃 𝑓𝜃 𝑥
𝜃 𝜃
𝑡=1
t-th Input Reconstruction Output
Vector (Auto-)encoder Representation VectorDecoder Vector
𝑥 (𝑡) 𝑓𝜃 (𝑡) 𝑔𝜃 𝑟 (𝑡)
Reconstruction Error
𝐿
17 前回の大澤君資料より](https://image.slidesharecdn.com/deepv2matsuo-121229003803-phpapp01/85/Learning-Deep-Architectures-for-AI-3-Deep-Learning-17-320.jpg)















Learning Deep Architectures for AI (第 3 回 Deep Learning 勉強会資料; 松尾)
- 1. Learning Deep Architectures for AI Journal of Foundations and Trends in Machine Learning, 2009 Yoshua Bengio (U. Montreal, Canada)
- 2. 松尾まとめ:広義のDeep Learning もしくはDeep Architecture • [勝ち組1] DBN: Deep Belief Network – Restricted Boltzman Machine(RBM)で層ごとに訓練 • その方法 CD: Contrastive Divergence – Deep Boltzman Machine (DBM)に変換できる – Hintonさんら(トロント大) 狭義のDeep Learning • [勝ち組2] Stacked Auto-Encoders – Auto-Encoders – Bengioさんら(モントリオール大) たぶんこれがいい • [惜しい] – Convolutional Network:特に視覚。2次元の制約を使う。LeCunさんたちのグ ループ(ニューヨーク大) – Self-taught Learning:1段でunsupervised + supervised。Ngさんたちのグループ (スタンフォード大) – Multi-task learning, transfer learning:目の付けどころはいいが、ちょっと違う概 念 • [負け組] – Deep Neural Network, Multi-layer Neural Network(昔からある) – Deep Graphical Model(昔からある)
- 3. 東西横綱 決め技: 寄り切り 決め技: 上手投げ Auto-Encoder Deep Belief Network Stacked Auto-Encoder (Deep Boltzman Machine)
- 4. RBM Auto-Encoder Min Energy(x,h) = -b’x – c’x – h’Wx – x’Ux – h’Vh Min RE = -log(x|c(x)) c(x): coding
- 5. 周辺の概念 • (1) 帰納転移学習 (inductive transfer learning) • (2) トランスダクティブ転移学習 (transductive transfer learning) • (3) 自己教示学習 (self-taught learning) • (4) 教師なし転移学習 (unsupervised transfer learning) 神嶌 敏弘 “転移学習” 人工知能学会誌, vol.25, no.4, pp.572-580 (2010) より
- 6. はじめに (1. Introduction) • AIを作るには、世界の知識を入れないといけない。画像や文 章を理解できるコンピュータは作れるのか? • 難しい。 • 現状では小さい問題にわけて 低いレベルから作っていくしかない – たとえばエッジを検出するとか、 輪郭を検出するとか、 目を検知するとか。
- 7. 学習するとは何か? • 機械(machine)が理解するとは? – 3Dの物体では、位置、向き、光など:factor of variationとよぶ – もし機械がこれらのfactorを見つけて、データの統計的な変種やその相 互作用を説明できれば、機械はその世界を「理解した」と言えるであろう。 • 抽象化とは? – カテゴリ(例えばMANカテゴリ)、もしくは – 素性(センサーデータの関数。実数でも離散でも構わない) を作ることである • 抽象化された概念である「MAN」を検知する「MAN検知器」を作る には、たくさんの中間レベルの概念が必要 • 深いアーキテクチャ(deep architecture)の学習の焦点は、そういっ た抽象化を、いかに自動的に行うかである。
- 8. 脳と深いアーキテクチャ (1.1 How do We Train Deep Architecture?) • ここでいうアーキテクチャの深さとは、非線形な関数のレベルの数である。 • 現在の学習アルゴリズムのほとんどは、浅いアーキテクチャ(1, 2もしくは3)である。 • 哺乳類の脳は、深いアーキテクチャで、入力が複数の抽象化のレベルで表現される。 • 研究者達は、長年、深い多層のニューラルネットワークを訓練しようとして来たが、 2006年までは成功しなかった。2、3層でよい結果はでても、それ以上になると結果は 悪くなった。 • 2006年にHintonらは、Deep Belief Network (DBN)を提案した。 • 2006年以来、多くの学習問題、回帰問題、次元削減、textureやmotionのモデル化、 情報検索やロボット、自然言語処理、協調フィルタリング等でよい結果を示した。 • 脳の各レベルでの抽象化は、たくさんの数の素性の小さい集合の活性化で起こる。 – その素性は互いに排他的でなく、素性は分散的な表現となる。 – つまり、どれかひとつのニューロンに情報が局在化するのではない。 – さらに、脳はsparseな表現を使う。同時に1-4%のニューロンしか活性化しない。 • したがって、疎な表現というのが大事そうだ。
- 9. 重要そうなもの (1.3 Desiderata for Learning AI) • AIの学習のために欲しいものリスト – 複雑で変化する関数を学習する能力 – 人間の入力がほとんどなくとも、AIタスクに必要な低次、 中間、高次の抽象化を学習する – 大量の例から学習する:学習の計算時間が線形に近い – ほとんどラベルのないデータから学習する – たくさんのタスクにあるシナジーを活用する(マルチタスク 学習) – 強力な教師なし学習をもつ
- 10. 深いアーキテクチャが重要な理由 (2. Theoretical Advantages of Deep Architecture) • 浅すぎる階層では表現できない関数もある。 • 線形回帰は1レベル • カーネルマシンや決定木は2レベル:カーネルマシンの場合、K(x,x’)を計算するのが第一レ ベル、b+ΣαK(x,xi)を計算するのが第二レベル • BoostingやStackingは1レベル加えるもの
- 11. AIの古典的な論理で言うと (2.1 Computational Complexity) • 理論的には、kの深さで表される関数は、k-1の深さで表そう とすると、指数的な数の要素が必要になることもある。 • 論理回路 – すべてのBoolean Functionは、2階層で表現できる。ANDのORか、OR のANDか。 – disjunctive normal form, conjunctive normal form – (x1∧x2∧¬x3)∨(¬x1∧x2∧x3)∨(x1∧¬x2∧x3) – (¬x1∨¬x2∨¬x3)∧ (¬x1∨x2∨x3)∧ (x1∨¬x2∨x3)∧…
- 12. (深いアーキテクチャでない) ローカルな推定器の限界 (3. Local vs Non-local Generalization) • ローカルなestimatorは、入力空間上で、入力xに近い訓練データをさがす。 • ローカルなestimatorは、入力空間を領域に分割する。たくさんの領域が 必要な場合には、パラメータが多くなり、たくさんの訓練データが必要で ある。←→次元の呪い • 違う表現をすると、学習したい関数の”variations”の数が問題である。 • Gaussian Kernel (RBF Kernel)のカーネルマシンの場合、”bump”の数と比 例するだけの数の訓練データが必要
- 13. 同じものの違う表現 • 高次元の複雑なタスクの場合、decision surface(決定表面)の複雑さは、 ローカルな方法の限界をすぐに越えてしまう。 • 言い方を変えれば、決定表面のカーブがたくさんの亜種をもち、かつ、背 後にある規則で関係づけることができないのであれば、ローカルな方法 を越えることはできない。 • いろいろなアルゴリズムに使われるneighborhood graph
- 14. 歴史的には (4. Neural Networks for Deep Architectures) • 多層ニューラルネットワーク – 普通のニューラルネットワーク。多層。(Rumelhart 1986) – 訓練ができない。精度が悪い。 – ランダムな初期値からの勾配法は、局所解に陥る。1, 2階層のほうが いい。 • 2007年にLeCunらのConvolutional Neural Network • 2006年にHintonは、1階層ずつ教師なし学習で事前訓練をし ておけばよい結果が得られることを示した • 重要なのは、layer-local unsupervised criteria
- 15. [Loosli, Canu, & Bottou, 2007] Denoising auto encodersを使っている
- 16. 参考:Convolutional Neural Networks (4.5 Convolutional Neural Networks) • LeCun 1989- • 畳み込みレイヤーとサブサンプルレイヤー • それぞれのレイヤーは2次元の位置があり、下のレ イヤーのパッチから重みつきで足し合わされる。 • 仮説:視覚の場合には、領域の制限が非常に強い から、階層的に局所的につながることが、よいprior になっている?
- 17. 主役のAuto-Encoder • Auto-encoder framework [Lecaum 1987][Bourland 1988][Hinton 1994] : unsupervised feature construction method の一つ。 • auto-: 「自己の」 auto-encoder を直訳すると自己符号器 • encoder, decoder, reconstruction error の 3 つの要素から構成。 • encoder と decoder の合成写像が入力値を再現するような学習を行う。 • 学習は入力値と出力値の誤差(reconstruction error)を最小化することで行われる。 • この操作によって、入力値をより適切な表現に写像する auto-encoder が得られる。 𝑇 𝑡 𝑡 𝜃 = argmin 𝒥DAE (𝜃) = argmin 𝐿 𝑥 , 𝑔 𝜃 𝑓𝜃 𝑥 𝜃 𝜃 𝑡=1 t-th Input Reconstruction Output Vector (Auto-)encoder Representation VectorDecoder Vector 𝑥 (𝑡) 𝑓𝜃 (𝑡) 𝑔𝜃 𝑟 (𝑡) Reconstruction Error 𝐿 17 前回の大澤君資料より
- 18. Auto-Encoders 4.6 Auto-encoders • 出力は入力と同じ。 • 2乗平均誤差を使って、k個の線形な隠れ層を作ると、主成 分分析の最初のk個の主成分と同じ。 • 隠れ層が多い場合には、identity functionになりそうだが、実 際にはよい表現を作る。早期停止つき確率的勾配法は、l2 正則化と同じ効果だから。
- 19. RBM 前々回の大知君資料より
- 20. RBM (5.3 Restricted Boltzmann Machines) • 以下を最小化 • RBMの場合、U=0, V=0 • いくつかの分布はコンパクトに表現できないこともあるが、十分な数の隠 れユニットがあればどんな離散分布も表現できる
- 21. RBMの訓練方法 (5.4 Contrastive Divergence) • RBMを訓練する際に、反復的に対数尤度勾配を求める近 似法 x1 ↓ h1 ↓ x2 ↓ h2 • k-step CD: MCMCのステップをk回に限る
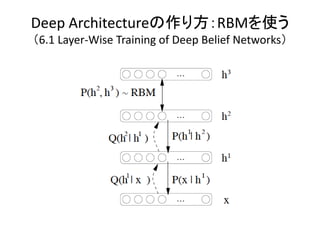
- 22. Deep Architectureの作り方:RBMを使う (6.1 Layer-Wise Training of Deep Belief Networks)
- 23. サンプル 割り当て RBM
- 24. Deep Architectureの作り方:Auto-Encoderを使う (6.2 Training Stacked Auto-Encoders) • DBNと同じ。 • しかし、RBMやDBNのような生成モデルではないので、何を 学んだかを出力してみることができない
- 25. Auto-Encoderの疎なもの (7.1 Sparse Representations in Auto-Encoders and RBMs) • 疎な表現は、情報理論的な意味においてより効率的であ る。 • Sparse Auto-Encoders • L1ノルムはl0ノルムのよいproxyで、疎な結果をもたらす • Explaining away: 複数あるうちのひとつのコード化を選ぶ • 良い点:最も重要なのだけ選ぶ。悪い点:結果が安定しな い(RBMには関係ない)
- 26. Auto-Encoderのロバストなもの (7.2 Denoising Auto-Encoders) • ノイズを加えても、それを除去するようなエン コードを見つける • 例えば、半分の値をゼロにするとか。見えな いものから見えるものを観測する • Vincent 2008。昔からあったが、deep architectureの前訓練としてよいことが分かっ た。
- 27. 時系列 (7.4 Conditional RBMs and Temporal RBMs) • Conditional RBM – いくつかのパラメータが自由ではなく、条件付き 確率変数によってパラメタライズされているもの。 – 例えば、隠れユニットのオフセットが、文脈変数z の線形関数になっているとか。 • Temporal RBM – P(x_t | x_t-1, x_t-2, …)を考えると、時系列のモデ ル化になる。
- 28. 今後の課題 (9.1 Global Optimization Strategies) • 層ごとのローカルな教師なし学習が、よりよい汎化性能につながる理由のひとつ は、入力に近い、低レベルの層を最適化するから。 • 既存の研究と、continuation modelに基づく難しい最適化の方法をつなげる。 – 簡単な問題から難しい問題に連続的に変化させる方法。Greedyな層ごとの学習も、 continuation methodの近似と考えられる。 • これによって、グローバルな最適化も可能かもしれない。 – 教師なしから教師ありにスムーズに変化させる – 温度を導入する – カリキュラムに沿った学習 • カリキュラムに沿った学習 – 人間は20年も学習が必要。その学習は構造化されており、教育システムによって異な る概念を異なる時期に学ぶように、特に前に学習した概念を使って新しい抽象化を学 ぶようにできている。 – Elman(1993)にもある概念だが、コンピュータの学習にもカリキュラムがあると学習を効 率的に導けるのではないか。(動物の訓練ではShapingと呼ばれる)
- 29. 要するに何が良いかの振り返り (9.2 Why Unsupervised Learning is Important) • 本稿では、強力な教師なし学習は、深いアーキテクチャーに 必須の要素であるということを言ってきた。その理由を簡単 にまとめる。 – ラベルデータはそもそも尐ない。ラベルなしのデータは多い。 – 未来のタスクは分からない。とすると、いまの世界の学習をできるだ け保存する学習をしておくほうがいい。 – いったん、高レベルの表現が得られると、他の学習タスクはずっと簡 単になる。 – 層ごとの教師なし学習。ローカルな情報だけで可能である。 – つまり教師なし学習は、教師あり学習のパラメータを、よりよい解のあ る方向に動かす。 – 入力と出力の関係だけでなく、入力の分布の統計的な規則を使うこと で局所解に陥るのをさける。
- 30. 研究課題リスト(1/4) 9.3 Open Questions 1. 回路における深さの役割は、論理回路と線形な素子を越えて一般化で きるか 2. AIのタスクを人間のパフォーマンスのレベルに近づけるのに十分な深さ があるのか? 3. 再帰的な計算を含む動的な回路に拡張できるのか 4. なぜランダムな初期値からのDeep Neural Networkの勾配法はうまくい かないのか 5. CDによって訓練されたRBMは、入力の情報を保存するのに役に立つか、 そうでないならどう改善できるか – Auto-encoderは明示的に保存するので。 6. 深いアーキテクチャのための教師あり学習は、悪い局所最適のために 難しいのか、それとも最適化問題が複雑すぎるのか。 7. RBMを訓練する際に局所解の存在は重要な問題なのか
- 31. 研究課題リスト(2/4) 8. RBMやauto-encoderを、よい表現を取り出すことができてより簡単な最適 化問題(おそらく凸の問題)で置き換えることができるか? 9. 現在の深いアーキテクチャの訓練アルゴリズムは、多くのフェーズがある が、これはオンラインの設定では現実的ではない。(局所解に陥るか ら)。深いアーキテクチャを訓練するオンラインの方法があるか? 10. CDのGibbsステップの回数は訓練時に適応的にできるか 11. 計算時間を考慮に入れてCDを大きく改善することができるか? 12. 再構成エラーのほかに、RBMやDBNの訓練をモニターする適切な方法が あるか? 13. RBMとauto-encoderは、学習する表現に、何らかの疎な制約をかけるこ とで改善するか。どういった方法がベストか。 14. 隠れ層の数が増えるに従って、エネルギー関数のノンパラメトリックな形 を使って、RBMのキャパシティは増えるか???
- 32. 研究課題リスト(3/4) • 15. 生成モデルは、単一のDenoising auto-encoderに関してしかないが、Stacked auto-encoderやStacked Denoising Auto-encoderで学習されたモデルの確率的な 解釈はあるか • 16. DBNの訓練の際には、層ごとの貪欲なアルゴリズムは効率的か?貪欲すぎ ないか? • 17. DBNと関連する生成モデルの対数尤度勾配の低いvarianceとbiasの推定器は ないか?? • 18. 教師なしの層ごとの訓練の手続きは深いアーキテクチャを作るが、局所解に 陥って、大規模なデータの全部の情報を使えない。より強力な最適化アルゴリズ ムはないか • 19. continuation法による最適化の戦略は、深いアーキテクチャの学習に大きな 改善をもたらすか?? • 20. DBNやStacked Auto-encoders、DBM以外に、訓練可能な深い構造があるか • 21. 人間が何年も何十年も学習するのにかかるような、高いレベルの抽象化を学 習するには、カリキュラムが必要か
- 33. 研究課題リスト(3/4) • 22. 深いアーキテクチャを学習するのに発見された方法は、リカレントネッ トワークやdynamical belief networkを学習するのにも使えるか?? • 23. 深いアーキテクチャは、例えばベクトルで表せないような情報を表現 するのにどこまで一般化できるか? • 24. DBNは半教師あり学習やself-taught learningでは適しているが、現在 のdeep learningのアルゴリズムをこれらの設定に用いる最もよい方法 は? • 25. ラベル付き例があるとき、どのように教師ありと教師なしの基準をあ わせて、入力の表現を学習すればよいか。 • 26. CDやDBNと同じような計算を脳に見つけることができるか。 • 27. 大脳は、フィードフォワードではなく、フィードバックのループがたくさん ある。学習だけでなく、視覚証拠からの状況的なpriorを統合するのにも 使われる。どのようなモデルが、深いアーキテクチャでのこのようなインタ ラクションにつながるのか?