

![Introduction
• 言語モデルの教師有り学習では対数尤度を最大化する
– 対数尤度最大化 と 人から見た良い文の生成 の間にはズレが存在
• 本論文の目標
– 我々が気にしている行動をより密接に捉えた目標に基づいて
言語モデルを学習させる方法を発展させる
• 英文の要約タスクを対象
– 文書要約においては強化学習は一般的
– ROUGEのような要約品質を評価する自動メトリクスは
人間の判断との相関性が低いという批判を受けている[1,2,3,4]
3
[1] N. Schluter. The limits of automatic summarisation according to rouge. In Proceedings of the 15th Conference of the
European Chapter of the Association for Computational Linguistics: Volume 2, Short Papers, pages 41–45, 2017.
[2] R. Paulus, C. Xiong, and R. Socher. A deep reinforced model for abstractive summarization. arXiv preprint arXiv:1705.04304,
2017.
[3] A. T. Chaganty, S. Mussman, and P. Liang. The price of debiasing automatic metrics in natural language evaluation. arXiv
preprint arXiv:1807.02202, 2018.
[4] W. Kryscinski, N. S. Keskar, B. McCann, C. Xiong, and R. Socher. Neural text summarization: A critical evaluation. In
Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint
Conference on Natural Language Processing (EMNLP-IJCNLP), pages 540–551, 2019.](https://image.slidesharecdn.com/presentation-201020090205/85/Learning-to-summarize-from-human-feedback-4-320.jpg)
![Related Work
• 強化学習(RL)を用いた要約モデルの学習に
人間のフィードバックを使用した研究[1,2]
– 人間評価のデータセットから報酬関数を学習[1]
– 人間のフィードバックを用いたオンライン学習[2]
• OpenAI(本論文と同じ著者含む)
• 変更点
– より大きなモデルを使用
» GPT-2(774M) -> GPT-3(1.3B, 6.7B)
– フィードバック収集をバッチ設定に移行
– ラベラーと研究者の高い一致率を確保
– policy network と value network を分離
– 参照要約上でfine-tuneしたモデルでその他モデルを初期化
– etc
4
[1] F. Böhm, Y. Gao, C. M. Meyer, O. Shapira, I. Dagan, and I. Gurevych. Better rewards yield better summaries: Learning to
summarise without references. arXiv preprint arXiv:1909.01214, 2019.
[2] D. M. Ziegler, N. Stiennon, J. Wu, T. B. Brown, A. Radford, D. Amodei, P. Christiano, and G. Irving. Fine-tuning language
models from human preferences. arXiv preprint arXiv:1909.08593, 2019.](https://image.slidesharecdn.com/presentation-201020090205/85/Learning-to-summarize-from-human-feedback-5-320.jpg)



![Datasets and task
• TL;DR summarization dataset[1]
– reddit.com の約300万の投稿
– 投稿者の書いた投稿の要約
– 品質を確保するためにデータセットをフィルタリング
• 要約が24~48トークンの投稿を選択
(要約の長さが品質に与える影響を抑える)
• その他にも色々フィルタリング
• フィルタリング後:123,169件(内5%をvalidation set)
– TL;DRを選んだ理由(要約ではCNN/DMがよく使用される)
• CNN/DMは単純な抽出ベースラインの性能が非常に高いため
– 従来研究で痛い目にあった
• Groud-truth task
– 48token以下の長さで可能な限り良い要約を生成するモデルを学習
– 要約の品質
• 要約がどれだけ忠実に元の投稿を伝えているか によって判断
8
[1] M. Völske, M. Potthast, S. Syed, and B. Stein. Tl; dr: Mining reddit to learn automatic summarization. In Proceedings of the
Workshop on New Frontiers in Summarization, pages 59–63, 2017.](https://image.slidesharecdn.com/presentation-201020090205/85/Learning-to-summarize-from-human-feedback-9-320.jpg)



![Collecting human feedback
• 従来研究[1]での失敗
– モデルに学習させたい品質とラベラーの実際の評価にミスマッチ
• 従来研究からの変更
1. オフライン設定
• 以下を交互に繰り返す
– ラベラーに大量の比較データを送る
– 累積的に収集されたデータに基づいてモデルを再学習
2. ラベラーとのハンズオン関係を維持
• ラベラーと研究者の判断が一致するようにラベラーをトレーニング
• データ収集期間中にラベラーと研究者の判断の一致を監視
– 一部では一致度は約77±2%(研究者同士は73±4%)
• パフォーマンスの悪いラベラーは途中でクビにする
• etc
12
[1] D. M. Ziegler, N. Stiennon, J. Wu, T. B. Brown, A. Radford, D. Amodei, P. Christiano, and G. Irving. Fine-tuning language
models from human preferences. arXiv preprint arXiv:1909.08593, 2019.](https://image.slidesharecdn.com/presentation-201020090205/85/Learning-to-summarize-from-human-feedback-13-320.jpg)











![Discussion (Limitations)
• 最終的なモデルを作成するのに必要な時間とコスト
– 6.7BモデルのRL fine-tuneに約320[GPU-days]が必要だった
• 厳密にはRL fine-tuneに使用したデータより
baselineの学習に使用する人間のデータは少ない
24](https://image.slidesharecdn.com/presentation-201020090205/85/Learning-to-summarize-from-human-feedback-25-320.jpg)
![Discussion (Future directions)
• 本論文の手法は人間がサンプルを比較可能なタスクに適用可能
– 対話、機械翻訳、質問応答、音声合成、音楽生成、etc
• この方法は最尤サンプルの分布シフトや縮退が問題になるよう
な長いサンプルを生成する場合に特に重要になると期待される
• サンプル効率の向上
– マルチタスク学習
• 人間がモデル出力の品質を簡単に評価できない
– 人間が評価タスクを迅速かつ正確に実行できるように
MLシステムを訓練[1]
• 二値比較以外のフィードバック方法
– ラベラーに出力を編集してもらう
– ラベラーに理由を説明してもらう
– etc
25
[1] P. Christiano, B. Shlegeris, and D. Amodei. Supervising strong learners by amplifying weak experts. arXiv preprint
arXiv:1810.08575, 2018.](https://image.slidesharecdn.com/presentation-201020090205/85/Learning-to-summarize-from-human-feedback-26-320.jpg)






![[DL輪読会]Autonomous Reinforcement Learning: Formalism and Benchmarking](https://cdn.slidesharecdn.com/ss_thumbnails/20220311arlfinal-220314025127-thumbnail.jpg?width=560&fit=bounds)




![[DL輪読会]Reward Augmented Maximum Likelihood for Neural Structured Prediction](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks0804-170803075139-thumbnail.jpg?width=560&fit=bounds)

![[DL輪読会]Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets](https://cdn.slidesharecdn.com/ss_thumbnails/20220325okimura-220405024717-thumbnail.jpg?width=560&fit=bounds)
![[DL輪読会]SOM-VAE: Interpretable Discrete Representation Learning on Time Series](https://cdn.slidesharecdn.com/ss_thumbnails/190118nonakadlhacks-190118005053-thumbnail.jpg?width=560&fit=bounds)
![[DL輪読会]NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis](https://cdn.slidesharecdn.com/ss_thumbnails/nerfdlseminar1-200327021512-thumbnail.jpg?width=560&fit=bounds)

![[DL輪読会]Convolutional Conditional Neural Processesと Neural Processes Familyの紹介](https://cdn.slidesharecdn.com/ss_thumbnails/20191220readingpaperconvcnp-191220034420-thumbnail.jpg?width=560&fit=bounds)

![SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法](https://cdn.slidesharecdn.com/ss_thumbnails/os2-02final-210610091211-thumbnail.jpg?width=560&fit=bounds)






![SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss2ssii2022-220607054716-2760bd30-thumbnail.jpg?width=560&fit=bounds)



![[DL輪読会]"Dynamical Isometry and a Mean Field Theory of CNNs: How to Train 10,0...](https://cdn.slidesharecdn.com/ss_thumbnails/wakasugi-180824003300-thumbnail.jpg?width=560&fit=bounds)



![[DL輪読会] Towards an Automatic Turing Test: Learning to Evaluate Dialogue Respo...](https://cdn.slidesharecdn.com/ss_thumbnails/170925dlhackstowardsanautomaticturingtest-170925104902-thumbnail.jpg?width=560&fit=bounds)

Ad
More Related Content
What's hot (20)
Similar to Learning to summarize from human feedback (20)


![[DL輪読会]ODT: Online Decision Transformer](https://cdn.slidesharecdn.com/ss_thumbnails/20220318-220322065805-thumbnail.jpg?width=560&fit=bounds)







![[DL輪読会]Learning to Adapt: Meta-Learning for Model-Based Control](https://cdn.slidesharecdn.com/ss_thumbnails/20180511dl-180511004107-thumbnail.jpg?width=560&fit=bounds)

![[Paper Reading] The price of debasing automatic metrics in natural language e...](https://cdn.slidesharecdn.com/ss_thumbnails/paperreading-20181012-shinoda-181013064855-thumbnail.jpg?width=560&fit=bounds)



![[DL輪読会]Decision Transformer: Reinforcement Learning via Sequence Modeling](https://cdn.slidesharecdn.com/ss_thumbnails/decisiontransformer20210709zhangxin-210709021501-thumbnail.jpg?width=560&fit=bounds)

Ad
More from harmonylab (20)




















Ad
Learning to summarize from human feedback
- 1. 論文紹介ゼミ Learning to summarize from human feedback 北海道大学大学院情報科学院 調和系工学研究室 博士1年 吉田拓海
- 2. 論文情報 • 著者 – Nisan Stiennon, Long Ouyang, Jeff Wu, Daniel M. Ziegler, Ryan Lowe, Chelsea Voss, Alec Radford, Dario Amodei, Paul Christiano • OpenAI • 概要 – 人間のフィードバックを用いて強化学習 – Pretrained Model を Fine Tune -> Human Feedback で強化学習 – 要約タスクでFine Tuneのみや人間の要約を上回る • 論文URL – https://arxiv.org/abs/2009.01325 • GitHub – https://github.com/openai/summarize-from-feedback • OpenAI Blog – https://openai.com/blog/learning-to-summarize-with-human- feedback/ 1
- 3. 概要 2
- 4. Introduction • 言語モデルの教師有り学習では対数尤度を最大化する – 対数尤度最大化 と 人から見た良い文の生成 の間にはズレが存在 • 本論文の目標 – 我々が気にしている行動をより密接に捉えた目標に基づいて 言語モデルを学習させる方法を発展させる • 英文の要約タスクを対象 – 文書要約においては強化学習は一般的 – ROUGEのような要約品質を評価する自動メトリクスは 人間の判断との相関性が低いという批判を受けている[1,2,3,4] 3 [1] N. Schluter. The limits of automatic summarisation according to rouge. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 2, Short Papers, pages 41–45, 2017. [2] R. Paulus, C. Xiong, and R. Socher. A deep reinforced model for abstractive summarization. arXiv preprint arXiv:1705.04304, 2017. [3] A. T. Chaganty, S. Mussman, and P. Liang. The price of debiasing automatic metrics in natural language evaluation. arXiv preprint arXiv:1807.02202, 2018. [4] W. Kryscinski, N. S. Keskar, B. McCann, C. Xiong, and R. Socher. Neural text summarization: A critical evaluation. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 540–551, 2019.
- 5. Related Work • 強化学習(RL)を用いた要約モデルの学習に 人間のフィードバックを使用した研究[1,2] – 人間評価のデータセットから報酬関数を学習[1] – 人間のフィードバックを用いたオンライン学習[2] • OpenAI(本論文と同じ著者含む) • 変更点 – より大きなモデルを使用 » GPT-2(774M) -> GPT-3(1.3B, 6.7B) – フィードバック収集をバッチ設定に移行 – ラベラーと研究者の高い一致率を確保 – policy network と value network を分離 – 参照要約上でfine-tuneしたモデルでその他モデルを初期化 – etc 4 [1] F. Böhm, Y. Gao, C. M. Meyer, O. Shapira, I. Dagan, and I. Gurevych. Better rewards yield better summaries: Learning to summarise without references. arXiv preprint arXiv:1909.01214, 2019. [2] D. M. Ziegler, N. Stiennon, J. Wu, T. B. Brown, A. Radford, D. Amodei, P. Christiano, and G. Irving. Fine-tuning language models from human preferences. arXiv preprint arXiv:1909.08593, 2019.
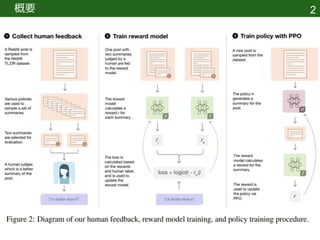
- 6. Method and experiment details 5 複数のソースから要約をサンプリング (現在のポリシー、初期ポリシー、参照要約、 その他ベースラインなど) どのポリシーからサンプリングするかについて 体系的に計画は立ててない 要約のペアを人間の評価者に送る 評価者は良い要約を選択 最終的なデータセットは64,832件
- 7. Method and experiment details 6 報酬モデル𝒓を学習 学習にはこれまでに収 集した全ラベルを使用
- 8. Method and experiment details 7 報酬モデル𝒓に対してポリシー𝝅を学習 報酬モデルの出力を報酬として強化学習
- 9. Datasets and task • TL;DR summarization dataset[1] – reddit.com の約300万の投稿 – 投稿者の書いた投稿の要約 – 品質を確保するためにデータセットをフィルタリング • 要約が24~48トークンの投稿を選択 (要約の長さが品質に与える影響を抑える) • その他にも色々フィルタリング • フィルタリング後:123,169件(内5%をvalidation set) – TL;DRを選んだ理由(要約ではCNN/DMがよく使用される) • CNN/DMは単純な抽出ベースラインの性能が非常に高いため – 従来研究で痛い目にあった • Groud-truth task – 48token以下の長さで可能な限り良い要約を生成するモデルを学習 – 要約の品質 • 要約がどれだけ忠実に元の投稿を伝えているか によって判断 8 [1] M. Völske, M. Potthast, S. Syed, and B. Stein. Tl; dr: Mining reddit to learn automatic summarization. In Proceedings of the Workshop on New Frontiers in Summarization, pages 59–63, 2017.
- 10. TL;DR summarization dataset 例 9 投稿
- 11. TL;DR summarization dataset 例 10 投稿 親愛なるReddit、私のボーイフレンドと私は異なる大陸に住んでいます。 いくつかの背景があります。 私は大学生です。私の彼氏(同い年)はオーストラリアに住んでいて、これまでのところ、私たちの関係は 純粋にオンライン上のものでした。彼は今年の終わりにアメリカに引っ越して一緒にいたいと思っています が、住居と仕事を探す必要があります。私たちには資金がありますし、私のボーイフレンドはアルバイトで 年収約13000ドルを稼いでいて、もうすぐ別の仕事に就く予定なので、お金を転がしているわけではありま せんが、お金は本当の問題ではありません。私たちは彼がビザを取得することの方が心配です。 国務省のウェブサイトによると、移民ビザには、1)家族がスポンサーとなるビザ、2)雇用主がスポンサーと なるビザ、3)特別な移民ビザの3種類があります。 1) 彼は家族ではありませんが、私たちが婚約して結婚すればビザを取得することができます。この選択肢 しかなさそうですが、二人とも直接会うことなく結婚したいとは思っていません。 2) 私たちの理解では、就労ビザは熟練した労働者にのみ与えられるものであり、私の彼氏が雇用主のスポ ンサーになることができるとは思えません。 3) 該当しません。 さらに、私たちには授業料や追加費用を支払う資金がなく、彼の家族(そして私の家族も)は彼をサポート する気がないので、彼は大学の学生ビザを申請することができません。 www.DeepL.com/Translator(無料版)で翻訳しました。
- 12. TL;DR summarization dataset 例 11 要約 アメリカ在住と仕事を両立できるビザを取得するには? オーストラリア出身の彼氏が私と一緒になるためにアメリカに移住したいと言って いますが、ビザが必要です。私たちは、私たちのどちらも最初にお互いに会わずに 結婚することを望んでいないので、彼に家族スポンサーのビザを取得することがで きません。 彼氏がアメリカに移住したいと言っていますが、ビザがありません。どうすれば取 得できるのでしょうか? 彼氏と私は違う大陸に住んでいて、アメリカに引っ越すためにはビザが必要です。 直接会わずに結婚するのは嫌だし、大学に通うための資金もない。 Human-written reference summary Human feedback 6B model Supervised 6B model Pre-trained 6B model
- 13. Collecting human feedback • 従来研究[1]での失敗 – モデルに学習させたい品質とラベラーの実際の評価にミスマッチ • 従来研究からの変更 1. オフライン設定 • 以下を交互に繰り返す – ラベラーに大量の比較データを送る – 累積的に収集されたデータに基づいてモデルを再学習 2. ラベラーとのハンズオン関係を維持 • ラベラーと研究者の判断が一致するようにラベラーをトレーニング • データ収集期間中にラベラーと研究者の判断の一致を監視 – 一部では一致度は約77±2%(研究者同士は73±4%) • パフォーマンスの悪いラベラーは途中でクビにする • etc 12 [1] D. M. Ziegler, N. Stiennon, J. Wu, T. B. Brown, A. Radford, D. Amodei, P. Christiano, and G. Irving. Fine-tuning language models from human preferences. arXiv preprint arXiv:1909.08593, 2019.
- 14. Models • どのモデルもGPT-3スタイルのTransformer Decoder – 13億(1.3B)と67億(6.7B)のパラメータ数を持つモデルで実験 13 Pretrained Model (GPT-3) Supervised Model 𝝅 𝑺𝑭𝑻 Reward Model 𝒓 Human Feedback Policy 𝝅 𝑹𝑳 TL;DR dataset でfine-tune Reward Modelを報酬とした 強化学習(PPO)でfine-tune Human Feedbackデータによって Reward Modelを学習
- 15. Models • Reward models – Supervised baseline で初期化 – 投稿𝑥が与えられたときに、人間が判断してどの要約が良いか予測 – 損失関数 loss(𝑟𝜃) • 𝑟𝜃(𝑥, 𝑦):投稿𝑥と要約𝑦に対する報酬モデルのスカラー出力 • 出力はデータセットの参照要約の平均スコアが0になるように正規化 • Human feedback policies – Supervised baseline で初期化 – Rewards modelの出力を報酬としてPPOで最適化 – 強化学習の報酬 𝑅(𝑥, 𝑦) • 𝜋 𝜙 𝑅𝐿 :学習済みRLポリシー • 𝜋 𝑆𝐹𝑇:元の教師ありモデル • 𝛽 = 0.05 14
- 16. Results (Summarizing Reddit posts from human feedback) • 人間が 参照要約 よりも モデルが生成した要約 を好む割合 15 Human feedback は Supervised を大幅に上回る 6.7B model は1.3B modelより有意に優れている 人間が作成した参照要約(Reference summary)より優れている
- 17. Results (Summarizing Reddit posts from human feedback) • リッカート尺度(7 point)で評価 16 評価軸 Overall 全体的な品質 Coverage どれだけ重要な情報がカバーされているか Coherence 要約がそれ自体でどれだけ読みやすいか Accuracy 要約の記述が投稿内でどの程度記述されているか Human feedbackは全軸で優れている(特にCoverage) 6.7B PPO modelは45%が7/7の評価(Overall) Supervised: 20%, Reference summary: 23%
- 18. Results (Transfer to summarizing news articles) • TL;DRで学習したモデルをCNN/DMニュース記事要約に転移 – 前ページと同様にリッカート尺度で評価(図は4軸の平均) 17 生成要約の文章長が短いのにも関わらずHuman feedback transfer はCNN/DMでfine-tuneしたモデルとほぼ同等の性能 同じような長さではCNN/DMで学習したT5と同等の性能
- 19. Results (Understanding the Reward model) • What happens as we optimize the reward model ? – 初期バージョンの報酬モデルに対して 異なるKLペナルティ係数𝛽で学習したポリシーを評価 • 人間が 参照要約 よりも モデルが生成した要約 を好む割合 18 (small 𝜷)の下ではラベラーによるとモデルは改善する (large 𝜷)と真の嗜好は予測と比較して低下する これは望ましくない、この過剰適合はROUGEでも起こる
- 20. Results (Understanding the Reward model) • How does reward modeling scale with increasing model and data size? – モデルサイズと学習データ量が報酬モデルの性能に与える影響 19 データ量を2倍にするとvalidation accuracyが1.1%増加 モデルサイズを2倍にすると1.8%増加
- 21. Results (Understanding the Reward model) • What has the reward model learned? – 報酬モデル(RM)とラベラーの評価、ROUGE等の一致率を計算 • 1.3B supervised model (T=0.7)の要約を使用 20 RMはlabelerと一致度が高い
- 22. Results (Understanding the Reward model) • What has the reward model learned? – 人間に要約を修正させ、修正前後でどっちが良いか評価 21 報酬モデル(RM)は人間と同程度の割合で修正後を好む 著者曰く… 報酬モデル(RM)は文のシャッフルにも敏感 ROUGEとかでは文のシャッフルには鈍感 一方で、報酬モデルは投稿タイトルが2回コピーされてたり 要約の最後にアドバイスを求めるような粗悪な要約を好むことがある
- 23. Results (Understanding the Reward model) • What has the reward model learned? – 要約の修正箇所と報酬モデルの変化 • 編集距離が5未満で報酬の変化が0.5より大きい例をランダム抽出 22 報酬モデルは小さな変化(意味的には大きな変化)に敏感
- 24. Results (Analyzing automatic metrics for summarization) • 報酬モデル(RM)とラベラーの評価、ROUGE等の一致率を計算 – 1.3B supervised model (T=0.7)の要約を使用 23 対数確率やROUGEはlabelerとの一致度が低い
- 25. Discussion (Limitations) • 最終的なモデルを作成するのに必要な時間とコスト – 6.7BモデルのRL fine-tuneに約320[GPU-days]が必要だった • 厳密にはRL fine-tuneに使用したデータより baselineの学習に使用する人間のデータは少ない 24
- 26. Discussion (Future directions) • 本論文の手法は人間がサンプルを比較可能なタスクに適用可能 – 対話、機械翻訳、質問応答、音声合成、音楽生成、etc • この方法は最尤サンプルの分布シフトや縮退が問題になるよう な長いサンプルを生成する場合に特に重要になると期待される • サンプル効率の向上 – マルチタスク学習 • 人間がモデル出力の品質を簡単に評価できない – 人間が評価タスクを迅速かつ正確に実行できるように MLシステムを訓練[1] • 二値比較以外のフィードバック方法 – ラベラーに出力を編集してもらう – ラベラーに理由を説明してもらう – etc 25 [1] P. Christiano, B. Shlegeris, and D. Amodei. Supervising strong learners by amplifying weak experts. arXiv preprint arXiv:1810.08575, 2018.
- 27. Discussion (Broader impacts) • 本論文の技術は人間がモデル出力の品質を評価することが可能 なあらゆるタスクに使用できる汎用的な技術 • 本論文の技術は悪意のある行為者が社会に悪を及ぼすモデルを 訓練することを可能にする – 重要な課題であるが明白な解決策は殆ど無い • 良い行動(良い要約) をどう定義するかも重要 – 複雑なタスクで人によって意見が異なる可能性がある場合は特に • RedditのTL;DRデータセットについて – 要約タスクの難易度がCNN/DMよりかなり高いため使用した – 攻撃的な内容や有害な社会バイアスを反映した内容が含まれている • 今回のモデルも偏った要約や攻撃的な要約を生成する可能性がある 26
- 29. Human data collection details • 高品質なデータ収集の処理 – Step0:自分たちでタスクを理解 – Step1:ラベラーの研修 – Step2:データ収集 – Step3:ラベラーにフィードバックを提供 – Step4:研究者の比較校正 28参考
- 30. Human data collection details • Step0:自分たちでタスクを理解 – 自分たちで要約比較を行う – 少数のラベラーを雇い比較を行わせ、意見の相違について議論 – より多くのラベラーに向けた指示書を作成 • Step1:ラベラーの研修 • 共有のデータセットに対してラベリングさせる – いくつかは理由も言わせ、校正に役立てる – 速さと著者らとの一致に閾値を設け、閾値以下の者はクビ (研修以降の期間でもパフォーマンス低い者はクビ) 29参考
- 31. Human data collection details • Step2:データ収集 – 独自Webサイト上で大規模なバッチを評価してもらう – 2つの要約を直接比較する前に 元の投稿を見ずに要約の”素朴な解釈”を書かせる • これは要約の評価に役立つ • 要約が元の投稿の後に読まれた場合には検出されない 要約の曖昧さを表面化させる – 素朴な解釈後に要約の比較 • 要約Aが要約Bよりも優れている(またはその逆)信頼度を 9ポイントのスケールで値を割り当てる 30参考
- 32. Human data collection details • Step3:ラベラーにフィードバックを提供 – ラベラー間の一致率を提供 • 殆どの比較は1人のラベラーでのみ行う • 各ラベラーは校正目的で10%~20%同じデータにラベリング – 不一致の事例を見せることでラベルの改善に役立てる • Step4:研究者の比較校正 – 時々著者らも同じ作業をして各ラベラーと著者らの一致率を測定 (品質評価に使用) – ラベラーごとに「高い信頼度」の閾値を計算 • 平均80%で著者らと一致する値を閾値とする • 高い信頼度のラベルのみを含む検証セットをフィルタリング – データ収集プロセス全体でラベラーとコミュニケ―ションをとる • 質問や難しい比較を議論するための共有チャットルーム • オフィスアワーを開催 • ラベラーと1対1のビデオ通話で意見の相違点を議論 31参考