Lecture 06 - CS-5040 - modern database systems
1 like604 views

The document provides an overview of MapReduce, a programming model and system developed by Google for processing large datasets in a distributed environment. It describes how MapReduce allows users to specify map and reduce functions to parallelize computations across large clusters. The system handles parallelization, fault tolerance, data distribution and load balancing transparently. MapReduce was motivated by the need to perform many data-intensive computations on the large amounts of data Google was processing, while hiding the complexity of distributed and parallel processing.















![reduce
func6on
michael
mathioudakis
16
key,
value
key,
value
key,
value
key,
value
key,
value
key,
value
key,
value
reduce
key,
[value1,
value2,
...]
reduce
key,
[value1,
value2,
...]
same
key
same
key](https://image.slidesharecdn.com/lecture06-cs-e5040-moderndatabasesystems-160311123854/85/Lecture-06-CS-5040-modern-database-systems-16-320.jpg)


![example
-‐
solu6on
michael
mathioudakis
19
doc1,
value
doc2,
value
doc3,
value
map
word1,
1
word2,
1
word3,
1
word4,
1
word4,
1
word2,
1
word2,
1
word1,
1
word4,
1
word1,
1
word1,
1
word1,
1
word1,
1
word1,
[4]
reduce
word2,
1
word2,
1
word2,
1
word2,
[3]](https://image.slidesharecdn.com/lecture06-cs-e5040-moderndatabasesystems-160311123854/85/Lecture-06-CS-5040-modern-database-systems-19-320.jpg)






![more
examples
reverse
web-‐link
graph
process
a
set
of
webpages
for
each
link
to
target
webpage,
find
a
list
[source]
of
all
webpages
source
that
contain
a
link
to
target
input
a
set
of
(key,value)
pairs
key:
webpage
URL
value:
webpage
contents
(html)
michael
mathioudakis
26](https://image.slidesharecdn.com/lecture06-cs-e5040-moderndatabasesystems-160311123854/85/Lecture-06-CS-5040-modern-database-systems-26-320.jpg)

![more
examples
term
vector
per
host
process
logs
of
webpages
each
webpage
has
a
URL
of
the
form
[host]/[page
address]
hgp://www.aalto.fi/en/current/news/2016-‐03-‐02/
find
a
term
vector
per
host
input
a
set
of
(key,value)
pairs
key:
webpage
URL
value:
webpage
contents
(html-‐stripped
text)
michael
mathioudakis
28](https://image.slidesharecdn.com/lecture06-cs-e5040-moderndatabasesystems-160311123854/85/Lecture-06-CS-5040-modern-database-systems-28-320.jpg)































![michael
mathioudakis
61
Spark: Cluster Computing with Working Sets
Matei Zaharia, Mosharaf Chowdhury, Michael J. Franklin, Scott Shenker, Ion Stoica
University of California, Berkeley
Abstract
MapReduce and its variants have been highly successful
in implementing large-scale data-intensive applications
on commodity clusters. However, most of these systems
are built around an acyclic data flow model that is not
suitable for other popular applications. This paper fo-
cuses on one such class of applications: those that reuse
a working set of data across multiple parallel operations.
This includes many iterative machine learning algorithms,
as well as interactive data analysis tools. We propose a
new framework called Spark that supports these applica-
tions while retaining the scalability and fault tolerance of
MapReduce. To achieve these goals, Spark introduces an
abstraction called resilient distributed datasets (RDDs).
An RDD is a read-only collection of objects partitioned
across a set of machines that can be rebuilt if a partition
is lost. Spark can outperform Hadoop by 10x in iterative
machine learning jobs, and can be used to interactively
query a 39 GB dataset with sub-second response time.
1 Introduction
A new model of cluster computing has become widely
popular, in which data-parallel computations are executed
on clusters of unreliable machines by systems that auto-
matically provide locality-aware scheduling, fault toler-
ance, and load balancing. MapReduce [11] pioneered this
model, while systems like Dryad [17] and Map-Reduce-
Merge [24] generalized the types of data flows supported.
MapReduce/Dryad job, each job must reload the data
from disk, incurring a significant performance penalty.
• Interactive analytics: Hadoop is often used to run
ad-hoc exploratory queries on large datasets, through
SQL interfaces such as Pig [21] and Hive [1]. Ideally,
a user would be able to load a dataset of interest into
memory across a number of machines and query it re-
peatedly. However, with Hadoop, each query incurs
significant latency (tens of seconds) because it runs as
a separate MapReduce job and reads data from disk.
This paper presents a new cluster computing frame-
work called Spark, which supports applications with
working sets while providing similar scalability and fault
tolerance properties to MapReduce.
The main abstraction in Spark is that of a resilient dis-
tributed dataset (RDD), which represents a read-only col-
lection of objects partitioned across a set of machines that
can be rebuilt if a partition is lost. Users can explicitly
cache an RDD in memory across machines and reuse it
in multiple MapReduce-like parallel operations. RDDs
achieve fault tolerance through a notion of lineage: if a
partition of an RDD is lost, the RDD has enough infor-
mation about how it was derived from other RDDs to be
able to rebuild just that partition. Although RDDs are
not a general shared memory abstraction, they represent
a sweet-spot between expressivity on the one hand and
scalability and reliability on the other hand, and we have
found them well-suited for a variety of applications.
appeared
at
HotCloud,
2010](https://image.slidesharecdn.com/lecture06-cs-e5040-moderndatabasesystems-160311123854/85/Lecture-06-CS-5040-modern-database-systems-61-320.jpg)
![michael
mathioudakis
62
appeared
at
the
USENIX
conference
on
networked
systems
design
and
implementa6on,
2010
Resilient Distributed Datasets: A Fault-Tolerant Abstraction for
In-Memory Cluster Computing
Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma,
Murphy McCauley, Michael J. Franklin, Scott Shenker, Ion Stoica
University of California, Berkeley
Abstract
We present Resilient Distributed Datasets (RDDs), a dis-
tributed memory abstraction that lets programmers per-
form in-memory computations on large clusters in a
fault-tolerant manner. RDDs are motivated by two types
of applications that current computing frameworks han-
dle inefficiently: iterative algorithms and interactive data
mining tools. In both cases, keeping data in memory
can improve performance by an order of magnitude.
To achieve fault tolerance efficiently, RDDs provide a
restricted form of shared memory, based on coarse-
grained transformations rather than fine-grained updates
to shared state. However, we show that RDDs are expres-
sive enough to capture a wide class of computations, in-
cluding recent specialized programming models for iter-
ative jobs, such as Pregel, and new applications that these
models do not capture. We have implemented RDDs in a
system called Spark, which we evaluate through a variety
of user applications and benchmarks.
1 Introduction
Cluster computing frameworks like MapReduce [10] and
Dryad [19] have been widely adopted for large-scale data
analytics. These systems let users write parallel compu-
tations using a set of high-level operators, without having
to worry about work distribution and fault tolerance.
Although current frameworks provide numerous ab-
tion, which can dominate application execution times.
Recognizing this problem, researchers have developed
specialized frameworks for some applications that re-
quire data reuse. For example, Pregel [22] is a system for
iterative graph computations that keeps intermediate data
in memory, while HaLoop [7] offers an iterative MapRe-
duce interface. However, these frameworks only support
specific computation patterns (e.g., looping a series of
MapReduce steps), and perform data sharing implicitly
for these patterns. They do not provide abstractions for
more general reuse, e.g., to let a user load several datasets
into memory and run ad-hoc queries across them.
In this paper, we propose a new abstraction called re-
silient distributed datasets (RDDs) that enables efficient
data reuse in a broad range of applications. RDDs are
fault-tolerant, parallel data structures that let users ex-
plicitly persist intermediate results in memory, control
their partitioning to optimize data placement, and ma-
nipulate them using a rich set of operators.
The main challenge in designing RDDs is defining a
programming interface that can provide fault tolerance
efficiently. Existing abstractions for in-memory storage
on clusters, such as distributed shared memory [24], key-
value stores [25], databases, and Piccolo [27], offer an
interface based on fine-grained updates to mutable state
(e.g., cells in a table). With this interface, the only ways
to provide fault tolerance are to replicate the data across
machines or to log updates across machines. Both ap-](https://image.slidesharecdn.com/lecture06-cs-e5040-moderndatabasesystems-160311123854/85/Lecture-06-CS-5040-modern-database-systems-62-320.jpg)




















![transforma6ons
and
ac6ons
Transformations
map( f : T ) U) : RDD[T] ) RDD[U]
filter( f : T ) Bool) : RDD[T] ) RDD[T]
flatMap( f : T ) Seq[U]) : RDD[T] ) RDD[U]
sample(fraction : Float) : RDD[T] ) RDD[T] (Deterministic sampling)
groupByKey() : RDD[(K, V)] ) RDD[(K, Seq[V])]
reduceByKey( f : (V,V) ) V) : RDD[(K, V)] ) RDD[(K, V)]
union() : (RDD[T],RDD[T]) ) RDD[T]
join() : (RDD[(K, V)],RDD[(K, W)]) ) RDD[(K, (V, W))]
cogroup() : (RDD[(K, V)],RDD[(K, W)]) ) RDD[(K, (Seq[V], Seq[W]))]
crossProduct() : (RDD[T],RDD[U]) ) RDD[(T, U)]
mapValues( f : V ) W) : RDD[(K, V)] ) RDD[(K, W)] (Preserves partitioning)
sort(c : Comparator[K]) : RDD[(K, V)] ) RDD[(K, V)]
partitionBy(p : Partitioner[K]) : RDD[(K, V)] ) RDD[(K, V)]
Actions
count() : RDD[T] ) Long
collect() : RDD[T] ) Seq[T]
reduce( f : (T,T) ) T) : RDD[T] ) T
lookup(k : K) : RDD[(K, V)] ) Seq[V] (On hash/range partitioned RDDs)
save(path : String) : Outputs RDD to a storage system, e.g., HDFS
Table 2: Transformations and actions available on RDDs in Spark. Seq[T] denotes a sequence of elements of type T.
that searches for a hyperplane w that best separates two
sets of points (e.g., spam and non-spam emails). The al-
gorithm uses gradient descent: it starts w at a random
ranks0input file
map
contribs0
links
join
reduce + map
michael
mathioudakis
84](https://image.slidesharecdn.com/lecture06-cs-e5040-moderndatabasesystems-160311123854/85/Lecture-06-CS-5040-modern-database-systems-84-320.jpg)


![example:
pagerank
-‐
lineage
s in Spark. Seq[T] denotes a sequence of elements of type T.
ranks0input file
map
contribs0
ranks1
contribs1
ranks2
contribs2
links
join
reduce + map
. . .
Figure 3: Lineage graph for datasets in PageRank.michael
mathioudakis
87](https://image.slidesharecdn.com/lecture06-cs-e5040-moderndatabasesystems-160311123854/85/Lecture-06-CS-5040-modern-database-systems-87-320.jpg)











































More Related Content
What's hot (20)
Similar to Lecture 06 - CS-5040 - modern database systems (20)


















More from Michael Mathioudakis (8)








Recently uploaded (20)




















Lecture 06 - CS-5040 - modern database systems
- 1. Modern Database Systems Lecture 6 Aris6des Gionis Michael Mathioudakis Spring 2016
- 2. logis6cs • tutorial on monday, TU6@2:15pm • assignment 2 is out -‐ due by march 14th • for programming part, check updated tutorial • total of 5 late days are allowed michael mathioudakis 2
- 3. today mapreduce & spark as they were introduced emphasis on high level concepts michael mathioudakis 3
- 5. intro recap structured data, semi-‐structured data, text query op6miza6on vs flexibility of data model disk access a central issue indexing now: big data scale so big, that new issues take front seat: distributed, parallel computa6on fault tolerance how to accommodate those within a simple computa6onal model? michael mathioudakis 5
- 6. remember this task from lecture 0... data records that contain information about products viewed or purchased from an online store task for each pair of Games products, count the number of customers that have purchased both 6 Product Category Customer Date Price Ac8on other... Portal 2 Games Michael M. 12/01/2015 10€ Purchase ... FLWR Plant Food Garden Aris G. 19/02/2015 32€ View Chase the Rabbit Games Michael M. 23/04/2015 1€ View Portal 2 Games Ores6s K. 13/05/2015 10€ Purchase ... > what challenges does case B pose compared to case A? hint limited main memory, disk access, distributed setting case A 10,000 records (0.5MB per record, 5GB total disk space) 10GB of main memory case B 10,000,000 records (~5TB total disk space) stored across 100 nodes (50GB per node), 10GB of main memory per node
- 8. michael mathioudakis 8 MapReduce: Simplified Data Processing on Large Clusters Jeffrey Dean and Sanjay Ghemawat [email protected], [email protected] Google, Inc. Abstract MapReduce is a programming model and an associ- ated implementation for processing and generating large data sets. Users specify a map function that processes a key/value pair to generate a set of intermediate key/value pairs, and a reduce function that merges all intermediate values associated with the same intermediate key. Many real world tasks are expressible in this model, as shown in the paper. Programs written in this functional style are automati- cally parallelized and executed on a large cluster of com- modity machines. The run-time system takes care of the details of partitioning the input data, scheduling the pro- gram’s execution across a set of machines, handling ma- chine failures, and managing the required inter-machine communication. This allows programmers without any experience with parallel and distributed systems to eas- ily utilize the resources of a large distributed system. Our implementation of MapReduce runs on a large cluster of commodity machines and is highly scalable: a typical MapReduce computation processes many ter- abytes of data on thousands of machines. Programmers find the system easy to use: hundreds of MapReduce pro- grams have been implemented and upwards of one thou- given day, etc. Most such computations are conceptu- ally straightforward. However, the input data is usually large and the computations have to be distributed across hundreds or thousands of machines in order to finish in a reasonable amount of time. The issues of how to par- allelize the computation, distribute the data, and handle failures conspire to obscure the original simple compu- tation with large amounts of complex code to deal with these issues. As a reaction to this complexity, we designed a new abstraction that allows us to express the simple computa- tions we were trying to perform but hides the messy de- tails of parallelization, fault-tolerance, data distribution and load balancing in a library. Our abstraction is in- spired by the map and reduce primitives present in Lisp and many other functional languages. We realized that most of our computations involved applying a map op- eration to each logical “record” in our input in order to compute a set of intermediate key/value pairs, and then applying a reduce operation to all the values that shared the same key, in order to combine the derived data ap- propriately. Our use of a functional model with user- specified map and reduce operations allows us to paral- lelize large computations easily and to use re-execution as the primary mechanism for fault tolerance. appeared at the Symposium on Opera6ng Systems Design & Implementa6on, 2004
- 9. some context in early 2000s, google was developing systems to accommodate storage and processing of big data volumes michael mathioudakis 9 google file system (gfs) “a scalable distributed file system for large distributed data-‐intensive applica6ons” “provides fault tolerance while running on inexpensive commodity hardware” bigtable “distributed storage system for managing structured data that is designed to scale to a very large size: petabytes of data across thousands of commodity servers” mapreduce “programming model and implementa6on for processing and genera6ng large data sets”
- 10. mo6va6on hundreds of special-‐purpose computa6ons over raw data crawled webpages & documents, search & web request logs inverted indexes, web graphs, document summaries, frequent queries conceptually straighforward computa6on however... a lot of data, distributed over many machines hundreds or thousands of machines... a lot of prac6cal issues arise, that obscure the simplicity of computa6on michael mathioudakis 10 at google in early 2000s...
- 11. developed solu6on programming model simple based on the map and reduce primi6ves found in func6onal languages (e.g., Lisp) system hides the messy details in a library paralleliza6on, fault-‐tolerance, data distribu6on, load balancing michael mathioudakis 11 mapreduce programming model system
- 12. programming model input a set of (key,value) pairs computa8on two func6ons: map and reduce wrigen by the user output a set of (key,value) pairs michael mathioudakis 12
- 13. map func6on input one (key,value) pair output set of intermediate (key,value) pairs mapreduce groups together pairs with same key and passes them to reduce func6on michael mathioudakis 13
- 14. michael mathioudakis 14 map func6on key, value key, value key, value ... key, value key, value map key, value key, value key, value key, value key, value key, value key, value key, value key, value key, value key, value key, value key, value key, value typeof(key/value) generally ≠ typeof(key/value) key, value key, value key, value key, value legend different key value
- 15. reduce func6on input (key, list(values)) intermediate key and set of values for that key list(values) supplied as iterator, convenient when not enough memory output list(values) typically only 0 or 1 values are output per invoca6on michael mathioudakis 15
- 16. reduce func6on michael mathioudakis 16 key, value key, value key, value key, value key, value key, value key, value reduce key, [value1, value2, ...] reduce key, [value1, value2, ...] same key same key
- 17. programming model input a set of (key,value) pairs map (key,value) è list( (key,value) ) reduce (key, list(values)) è (key, list(values)) output list( (key, list(values)) ) michael mathioudakis 17
- 18. example task count the number of occurrences of each word in a collec6on of documents input a set of (key,value) pairs key: document file loca6on (id) value: document contents (list of words) how would you approach this? michael mathioudakis 18 map (key,value) è list( (key,value) ) reduce (key, list(values)) è (key, list(values))
- 19. example -‐ solu6on michael mathioudakis 19 doc1, value doc2, value doc3, value map word1, 1 word2, 1 word3, 1 word4, 1 word4, 1 word2, 1 word2, 1 word1, 1 word4, 1 word1, 1 word1, 1 word1, 1 word1, 1 word1, [4] reduce word2, 1 word2, 1 word2, 1 word2, [3]
- 20. example -‐ solu6on michael mathioudakis 20 Consider the problem of counting the number of oc- currences of each word in a large collection of docu- ments. The user would write code similar to the follow- ing pseudo-code: map(String key, String value): // key: document name // value: document contents for each word w in value: EmitIntermediate(w, "1"); reduce(String key, Iterator values): // key: a word // values: a list of counts int result = 0; for each v in values: result += ParseInt(v); Emit(AsString(result)); The map function emits each word plus an associated count of occurrences (just ‘1’ in this simple example). identi ate da Coun tion p ⟨URL for th pair. Rever ⟨tar URL functi sociat ⟨tar Term
- 21. programming model -‐ types michael mathioudakis 21 map (key,value) è list( (key,value) ) reduce (key, list(values)) è (key, list(values)) intermediate (key, value) pairs input (key, value) pairs output (key, value) pairs type of type of ≠
- 22. more examples michael mathioudakis 22 grep search a set of documents for a string pagern in a line input a set of (key,value) pairs key: document file loca6on (id) value: document contents (lines of characters)
- 23. more examples michael mathioudakis 23 map emits a line if it matches the pagern (document file loca6on, line) reduce iden6ty func6on
- 24. more examples count of URL access frequency process logs of web page requests logs are stored in documents, one line per request, each line contains URL of requested page input a set of (key,value) pairs key: log file loca6on value: log contents (lines of requests) michael mathioudakis 24
- 25. more examples map process logs of web page requests output (URL, 1) pairs reduce add together counts for same URL michael mathioudakis 25
- 26. more examples reverse web-‐link graph process a set of webpages for each link to target webpage, find a list [source] of all webpages source that contain a link to target input a set of (key,value) pairs key: webpage URL value: webpage contents (html) michael mathioudakis 26
- 27. more examples map output (target, source) pairs for each link to a target URL found in a page named source reduce concatenate list of sources per target output (target, list(source)) pairs michael mathioudakis 27
- 28. more examples term vector per host process logs of webpages each webpage has a URL of the form [host]/[page address] hgp://www.aalto.fi/en/current/news/2016-‐03-‐02/ find a term vector per host input a set of (key,value) pairs key: webpage URL value: webpage contents (html-‐stripped text) michael mathioudakis 28
- 29. more examples map emit a (hostname, term vector) pair for each webpage, hostname is extracted from document URL reduce adds (hostname, frequency vector) pair per hostname michael mathioudakis 29
- 30. more examples simple inverted index (no counts) process a collec6on of documents to construct an inverted index for each word, have a list of documents in which it occurs input a set of (key,value) pairs key: document file loca6on (id) value: document contents (list of words) michael mathioudakis 30
- 31. more examples map parse each document, emit a sequence (word, document ID) reduce output (word, list(document ID)) pair for each word michael mathioudakis 31
- 32. system at google (back in 2004) large clusters of commodity PCs, connected with ethernet dual-‐processor x86, linux, 2-‐4gb of memory per machine 100 Mbit/s or 1Gbit/s network 100’s or 1000’s pf machines per cluster storage inexpensive IDE disks agached to the machines google file system (GFS) -‐ uses replica6on users submit jobs to scheduling system michael mathioudakis 32
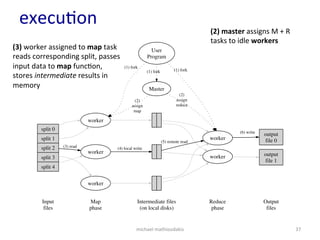
- 33. execu6on a job is submiged, then what? map and reduce invoca6ons are distributed over machines input data is automa6cally par66oned into a set of M splits the M splits are fed each into a map instance intermediate results are par66oned into R par66ons according to hash func6on -‐-‐ provided by user michael mathioudakis 33
- 34. execu6on michael mathioudakis 34 User Program Master (1) fork worker (1) fork worker (1) fork (2) assign map (2) assign reduce split 0 split 1 split 2 split 3 split 4 output file 0 (6) write worker (3) read worker (4) local write Map phase Intermediate files (on local disks) worker output file 1 Input files (5) remote read Reduce phase Output files Figure 1: Execution overview
- 35. execu6on michael mathioudakis 35 User Program Master (1) fork worker (1) fork worker (1) fork (2) assign map (2) assign reduce split 0 split 1 split 2 split 3 split 4 output file 0 (6) write worker (3) read worker (4) local write Map phase Intermediate files (on local disks) worker output file 1 Input files (5) remote read Reduce phase Output files Figure 1: Execution overview (1) split input files into M pieces (16-‐64MB each) and fork many copies of the user program
- 36. execu6on michael mathioudakis 36 User Program Master (1) fork worker (1) fork worker (1) fork (2) assign map (2) assign reduce split 0 split 1 split 2 split 3 split 4 output file 0 (6) write worker (3) read worker (4) local write Map phase Intermediate files (on local disks) worker output file 1 Input files (5) remote read Reduce phase Output files Figure 1: Execution overview (1) split input files into M pieces (16-‐64MB each) and fork many copies of the user program (2) master assigns M + R tasks to idle workers
- 37. execu6on michael mathioudakis 37 User Program Master (1) fork worker (1) fork worker (1) fork (2) assign map (2) assign reduce split 0 split 1 split 2 split 3 split 4 output file 0 (6) write worker (3) read worker (4) local write Map phase Intermediate files (on local disks) worker output file 1 Input files (5) remote read Reduce phase Output files Figure 1: Execution overview (3) worker assigned to map task reads corresponding split, passes input data to map func6on, stores intermediate results in memory (2) master assigns M + R tasks to idle workers
- 38. execu6on michael mathioudakis 38 User Program Master (1) fork worker (1) fork worker (1) fork (2) assign map (2) assign reduce split 0 split 1 split 2 split 3 split 4 output file 0 (6) write worker (3) read worker (4) local write Map phase Intermediate files (on local disks) worker output file 1 Input files (5) remote read Reduce phase Output files Figure 1: Execution overview (4) periodically, buffered intermediate results are wrigen to local disk, into R par66ons, according to hash func6on; their loca6ons are passed to master (2) master assigns M + R tasks to idle workers
- 39. execu6on michael mathioudakis 39 User Program Master (1) fork worker (1) fork worker (1) fork (2) assign map (2) assign reduce split 0 split 1 split 2 split 3 split 4 output file 0 (6) write worker (3) read worker (4) local write Map phase Intermediate files (on local disks) worker output file 1 Input files (5) remote read Reduce phase Output files Figure 1: Execution overview (4) periodically, buffered intermediate results are wrigen to local disk, into R par66ons, according to hash func6on; their loca6ons are passed to master (5) master no6fies reduce workers; reduce worker collects intermediate data for one par66on from local disks of map workers; sorts by intermediate key;
- 40. execu6on michael mathioudakis 40 User Program Master (1) fork worker (1) fork worker (1) fork (2) assign map (2) assign reduce split 0 split 1 split 2 split 3 split 4 output file 0 (6) write worker (3) read worker (4) local write Map phase Intermediate files (on local disks) worker output file 1 Input files (5) remote read Reduce phase Output files Figure 1: Execution overview (6) reduce worker passes each intermediate key and corresponding values to reduce func6on; output appended to file for this reduce par66on (5) master no6fies reduce workers; reduce worker collects intermediate data for one par66on from local disks of map workers; sorts by intermediate key;
- 41. execu6on michael mathioudakis 41 User Program Master (1) fork worker (1) fork worker (1) fork (2) assign map (2) assign reduce split 0 split 1 split 2 split 3 split 4 output file 0 (6) write worker (3) read worker (4) local write Map phase Intermediate files (on local disks) worker output file 1 Input files (5) remote read Reduce phase Output files Figure 1: Execution overview (6) reduce worker passes each intermediate key and corresponding values to reduce func6on; output appended to file for this reduce par66on (7) arer all tasks are completed, the master wakes up the user program final output: R files
- 42. master data structures state for each map & reduce task idle, in-‐progress, completed + iden6ty of assigned worker for each completed map task loca6on and sizes of R intermediate file regions received as map tasks are completed pushed incrementally to reduce workers with in-‐progress tasks michael mathioudakis 42
- 43. fault tolerance worker failure master pings worker periodically if no response, then worker has failed completed map tasks reset to idle (why?) in-‐progress tasks set to idle idle tasks: up for grabs by other workers michael mathioudakis 43
- 44. fault tolerance master failure master writes periodic checkpoints with master data structures (state) new master re-‐starts from last check-‐point michael mathioudakis 44
- 45. “stragglers” tasks that take too long to complete solu6on when a mapreduce opera6on is close to comple6on, schedule backup tasks for remaining tasks michael mathioudakis 45 fault tolerance
- 46. locality master tries to assign tasks to nodes that contain a replica of the input data michael mathioudakis 46
- 47. task granularity M map tasks and R reduce tasks ideally, M and R should be much larger than number of workers why? load-‐balancing & speedy recovery michael mathioudakis 47
- 48. ordering guarantees intermediate key/value pairs are processed in increasing key order makes it easy to generate a sorted output file per par66on (why?) michael mathioudakis 48
- 49. combiner func6ons op6onal user-‐defined func6on executed on machines that perform map tasks “combines” results before passed to the reducer what would the combiner be for the word-‐count example? typically the combiner is the same as the reducer only difference: output reducer writes to final output combiner writes to intermediate output michael mathioudakis 49
- 50. counters objects updated within map and reduce func6ons periodically propagated to master useful for debugging michael mathioudakis 50
- 51. counters -‐ example Counter* uppercase; uppercase = GetCounter("uppercase"); map(String name, String contents): for each word w in contents: if (IsCapitalized(w)): uppercase->Increment(); EmitIntermediate(w, "1"); The counter values from individual worker machines are periodically propagated to the master (piggybacked on the ping response). The master aggregates the counter values from successful map and reduce tasks and returnsmichael mathioudakis 51
- 52. performance 1800 machines each machine had two 2GHz Xeon processors 4GB of memory (2.5-‐3GB available) two 160GB disks gigabit Ethernet michael mathioudakis 52
- 53. performance grep 1010 100-‐byte records search for a pagern found in <105 records M = 15000, R = 1 150 seconds from start to finish exercise: today, how big a file would you grep on one machine in 150 seconds? michael mathioudakis 53
- 54. performance sort 1010 100-‐byte records extract 10 byte sor6ng-‐key from each record (line) M = 15000, R = 4000 850 seconds from start to finish exercise: how would you implement sort? michael mathioudakis 54
- 55. summary original mapreduce paper simple programming model based on func6onal language primi6ves system takes care of scheduling and fault-‐tolerance great impact for cluster compu6ng michael mathioudakis 55
- 56. hadoop michael mathioudakis 56
- 57. map reduce and hadoop michael mathioudakis 57 mapreduce implemented into apache hadoop sorware ecosystem for distributed data storage and processing open source
- 58. hadoop michael mathioudakis 58 common hdfs mapreduce yarn scheduling & resource management hadoop distributed filesystem
- 59. hadoop michael mathioudakis 59 common hdfs mapreduce yarn scheduling & resource management hadoop distributed filesystem mahout machine learning library hive data warehouse, sql-‐ like querying pig data-‐flow language and system for parallel computa6on spark and a lot of other projects!! cluster-‐compu6ng engine
- 60. spark michael mathioudakis 60
- 61. michael mathioudakis 61 Spark: Cluster Computing with Working Sets Matei Zaharia, Mosharaf Chowdhury, Michael J. Franklin, Scott Shenker, Ion Stoica University of California, Berkeley Abstract MapReduce and its variants have been highly successful in implementing large-scale data-intensive applications on commodity clusters. However, most of these systems are built around an acyclic data flow model that is not suitable for other popular applications. This paper fo- cuses on one such class of applications: those that reuse a working set of data across multiple parallel operations. This includes many iterative machine learning algorithms, as well as interactive data analysis tools. We propose a new framework called Spark that supports these applica- tions while retaining the scalability and fault tolerance of MapReduce. To achieve these goals, Spark introduces an abstraction called resilient distributed datasets (RDDs). An RDD is a read-only collection of objects partitioned across a set of machines that can be rebuilt if a partition is lost. Spark can outperform Hadoop by 10x in iterative machine learning jobs, and can be used to interactively query a 39 GB dataset with sub-second response time. 1 Introduction A new model of cluster computing has become widely popular, in which data-parallel computations are executed on clusters of unreliable machines by systems that auto- matically provide locality-aware scheduling, fault toler- ance, and load balancing. MapReduce [11] pioneered this model, while systems like Dryad [17] and Map-Reduce- Merge [24] generalized the types of data flows supported. MapReduce/Dryad job, each job must reload the data from disk, incurring a significant performance penalty. • Interactive analytics: Hadoop is often used to run ad-hoc exploratory queries on large datasets, through SQL interfaces such as Pig [21] and Hive [1]. Ideally, a user would be able to load a dataset of interest into memory across a number of machines and query it re- peatedly. However, with Hadoop, each query incurs significant latency (tens of seconds) because it runs as a separate MapReduce job and reads data from disk. This paper presents a new cluster computing frame- work called Spark, which supports applications with working sets while providing similar scalability and fault tolerance properties to MapReduce. The main abstraction in Spark is that of a resilient dis- tributed dataset (RDD), which represents a read-only col- lection of objects partitioned across a set of machines that can be rebuilt if a partition is lost. Users can explicitly cache an RDD in memory across machines and reuse it in multiple MapReduce-like parallel operations. RDDs achieve fault tolerance through a notion of lineage: if a partition of an RDD is lost, the RDD has enough infor- mation about how it was derived from other RDDs to be able to rebuild just that partition. Although RDDs are not a general shared memory abstraction, they represent a sweet-spot between expressivity on the one hand and scalability and reliability on the other hand, and we have found them well-suited for a variety of applications. appeared at HotCloud, 2010
- 62. michael mathioudakis 62 appeared at the USENIX conference on networked systems design and implementa6on, 2010 Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael J. Franklin, Scott Shenker, Ion Stoica University of California, Berkeley Abstract We present Resilient Distributed Datasets (RDDs), a dis- tributed memory abstraction that lets programmers per- form in-memory computations on large clusters in a fault-tolerant manner. RDDs are motivated by two types of applications that current computing frameworks han- dle inefficiently: iterative algorithms and interactive data mining tools. In both cases, keeping data in memory can improve performance by an order of magnitude. To achieve fault tolerance efficiently, RDDs provide a restricted form of shared memory, based on coarse- grained transformations rather than fine-grained updates to shared state. However, we show that RDDs are expres- sive enough to capture a wide class of computations, in- cluding recent specialized programming models for iter- ative jobs, such as Pregel, and new applications that these models do not capture. We have implemented RDDs in a system called Spark, which we evaluate through a variety of user applications and benchmarks. 1 Introduction Cluster computing frameworks like MapReduce [10] and Dryad [19] have been widely adopted for large-scale data analytics. These systems let users write parallel compu- tations using a set of high-level operators, without having to worry about work distribution and fault tolerance. Although current frameworks provide numerous ab- tion, which can dominate application execution times. Recognizing this problem, researchers have developed specialized frameworks for some applications that re- quire data reuse. For example, Pregel [22] is a system for iterative graph computations that keeps intermediate data in memory, while HaLoop [7] offers an iterative MapRe- duce interface. However, these frameworks only support specific computation patterns (e.g., looping a series of MapReduce steps), and perform data sharing implicitly for these patterns. They do not provide abstractions for more general reuse, e.g., to let a user load several datasets into memory and run ad-hoc queries across them. In this paper, we propose a new abstraction called re- silient distributed datasets (RDDs) that enables efficient data reuse in a broad range of applications. RDDs are fault-tolerant, parallel data structures that let users ex- plicitly persist intermediate results in memory, control their partitioning to optimize data placement, and ma- nipulate them using a rich set of operators. The main challenge in designing RDDs is defining a programming interface that can provide fault tolerance efficiently. Existing abstractions for in-memory storage on clusters, such as distributed shared memory [24], key- value stores [25], databases, and Piccolo [27], offer an interface based on fine-grained updates to mutable state (e.g., cells in a table). With this interface, the only ways to provide fault tolerance are to replicate the data across machines or to log updates across machines. Both ap-
- 63. why not mapreduce? mapreduce flows are acyclic not efficient for some applica6ons michael mathioudakis 63
- 64. why not mapreduce? itera8ve jobs many common machine learning algorithms repeatedly apply the same func6on on the same dataset (e.g., gradient descent) mapreduce repeatedly reloads (reads & writes) data michael mathioudakis 64
- 65. why not mapreduce? interac8ve analy8cs load data in memory and query repeatedly mapreduce would re-‐read data michael mathioudakis 65
- 66. spark’s proposal generalize mapreduce model to accommodate such applica6ons allow us treat data as available across repeated queries and updates resilient distributed datasets (rdds) michael mathioudakis 66
- 67. resilient distributed datasets (rdd) read-‐only collec6on of objects par66oned across machines users can explicitly cache rdds in memory re-‐use across mapreduce-‐like parallel opera6ons michael mathioudakis 67
- 68. main challenge efficient fault-‐tolerance to treat data as available in-‐memory should be easy to re-‐build if part of data (e.g., a par66on) is lost achieved through course-‐grained transforma3ons and lineage michael mathioudakis 68
- 69. fault-‐tolerance coarse transforma8ons e.g., map opera6ons applied to many (even all) data items lineage the series of transforma6ons that led to a dataset if a par66on is lost, there is enough informa6on to re-‐ apply the transforma6ons and re-‐compute it michael mathioudakis 69
- 70. programming model developers write a drive program high-‐level control flow think of rdds as ‘variables’ that represent datasets on which you apply parallel opera3ons can also use restricted types of shared variables michael mathioudakis 70
- 71. spark run6me Worker tasks results RAM Input Data Worker RAM Input Data Worker RAM Input Data Driver michael mathioudakis 71
- 72. rdd read-‐only collec6on of objects par66oned across a set of machines, that can be re-‐built if a par66on is lost constructed in the following ways: from a file in a shared file system (e.g., hdfs) parallelizing a collec8on (e.g., an array) divide into par66ons and send to mul6ple nodes transforming an exis8ng rdd e.g., applying a map opera6on changing the persistence of an exis6ng rdd hint to cache rdd or save to filesystem michael mathioudakis 72
- 73. rdd need not exist physically at all 6mes instead, there is enough informa6on to compute the rdd rdds are lazily-‐created and ephemeral lazy materialized only when informa6on is extracted from them (through ac3ons!) ephemeral discarded arer use michael mathioudakis 73
- 74. transforma6ons and ac6ons transforma6ons lazy opera6ons that define a new rdd ac6ons launch computa6on on rdd to return a value to the program or write data to external storage michael mathioudakis 74
- 75. shared variables broadcast variables read-‐only variables, sent to all workers typical use-‐case large read-‐only piece of data (e.g., lookup table) that is used across mul6ple parallel opera6ons michael mathioudakis 75
- 76. shared variables accumulators write-‐only variables, that workers can update using an opera6on that is commuta6ve and associa6ve only the driver can read typical use-‐case counters michael mathioudakis 76
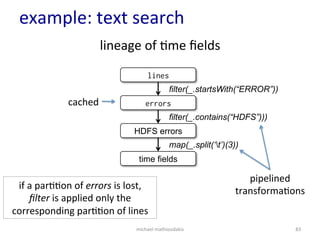
- 77. example: text search suppose that a web service is experiencing errors and you want to search over terabytes of logs to find the cause the logs are stored in Hadoop Filesystem (HDFS) errors are wrigen in the logs as lines that start with the keyword “ERROR” michael mathioudakis 77
- 78. example: text search michael mathioudakis 78 HDFS errors time fields map(_.split(‘t’)(3)) Figure 1: Lineage graph for the third query in our example. Boxes represent RDDs and arrows represent transformations. lines = spark.textFile("hdfs://...") errors = lines.filter(_.startsWith("ERROR")) errors.persist() Line 1 defines an RDD backed by an HDFS file (as a collection of lines of text), while line 2 derives a filtered RDD from it. Line 3 then asks for errors to persist in memory so that it can be shared across queries. Note that the argument to filter is Scala syntax for a closure. At this point, no work has been performed on the clus- ter. However, the user can now use the RDD in actions, e.g., to count the number of messages: F S m W p B e Ta 2. T m tr te a in lines = spark.textFile("hdfs://...") errors = lines.filter(_.startsWith("ERROR")) errors.persist() Line 1 defines an RDD backed by an HDFS file (as a collection of lines of text), while line 2 derives a filtered RDD from it. Line 3 then asks for errors to persist in memory so that it can be shared across queries. Note that the argument to filter is Scala syntax for a closure. At this point, no work has been performed on the clus- ter. However, the user can now use the RDD in actions, e.g., to count the number of messages: errors.count() The user can also perform further transformations on the RDD and use their results, as in the following lines: // Count errors mentioning MySQL: errors.filter(_.contains("MySQL")).count() e Ta 2. To m tri te a in bu gr w D m to in Scala... rdd rdd from a file transforma6on hint: keep in memory! no work on the cluster so far ac6on! lines is not loaded to ram!
- 79. example -‐ text search ctd. let us find errors related to “MySQL” michael mathioudakis 79
- 80. example -‐ text search ctd. michael mathioudakis 80 Figure 1: Lineage graph for the third query in our example. Boxes represent RDDs and arrows represent transformations. lines = spark.textFile("hdfs://...") errors = lines.filter(_.startsWith("ERROR")) errors.persist() Line 1 defines an RDD backed by an HDFS file (as a collection of lines of text), while line 2 derives a filtered RDD from it. Line 3 then asks for errors to persist in memory so that it can be shared across queries. Note that the argument to filter is Scala syntax for a closure. At this point, no work has been performed on the clus- ter. However, the user can now use the RDD in actions, e.g., to count the number of messages: errors.count() m W p B e Ta 2. T m tr te a in bu gr w collection of lines of text), while line 2 derives a filtered RDD from it. Line 3 then asks for errors to persist in memory so that it can be shared across queries. Note that the argument to filter is Scala syntax for a closure. At this point, no work has been performed on the clus- ter. However, the user can now use the RDD in actions, e.g., to count the number of messages: errors.count() The user can also perform further transformations on the RDD and use their results, as in the following lines: // Count errors mentioning MySQL: errors.filter(_.contains("MySQL")).count() // Return the time fields of errors mentioning // HDFS as an array (assuming time is field // number 3 in a tab-separated format): errors.filter(_.contains("HDFS")) 2. To m tri te a in bu gr w D m to R gr w to m memory so that it can be shared across queries. Note that the argument to filter is Scala syntax for a closure. At this point, no work has been performed on the clus- ter. However, the user can now use the RDD in actions, e.g., to count the number of messages: errors.count() The user can also perform further transformations on the RDD and use their results, as in the following lines: // Count errors mentioning MySQL: errors.filter(_.contains("MySQL")).count() // Return the time fields of errors mentioning // HDFS as an array (assuming time is field // number 3 in a tab-separated format): errors.filter(_.contains("HDFS")) .map(_.split(’t’)(3)) .collect() After the first action involving errors runs, Spark will memo tribut tems, a glob includ but a graine which DSM make tolera Th RDD graine writes to app more need be rec partit ure, a transforma6on ac6on
- 81. example -‐ text search ctd. again let us find errors related to “HDFS” and extract their 6me field assuming 6me is field no. 3 in tab-‐separated format michael mathioudakis 81
- 82. example -‐ text search ctd. again michael mathioudakis 82 Figure 1: Lineage graph for the third query in our example. Boxes represent RDDs and arrows represent transformations. lines = spark.textFile("hdfs://...") errors = lines.filter(_.startsWith("ERROR")) errors.persist() Line 1 defines an RDD backed by an HDFS file (as a collection of lines of text), while line 2 derives a filtered RDD from it. Line 3 then asks for errors to persist in memory so that it can be shared across queries. Note that the argument to filter is Scala syntax for a closure. At this point, no work has been performed on the clus- ter. However, the user can now use the RDD in actions, e.g., to count the number of messages: errors.count() The user can also perform further transformations on W p B e Ta 2. T m tr te a in bu gr w D RDD from it. Line 3 then asks for errors to persist in memory so that it can be shared across queries. Note that the argument to filter is Scala syntax for a closure. At this point, no work has been performed on the clus- ter. However, the user can now use the RDD in actions, e.g., to count the number of messages: errors.count() The user can also perform further transformations on the RDD and use their results, as in the following lines: // Count errors mentioning MySQL: errors.filter(_.contains("MySQL")).count() // Return the time fields of errors mentioning // HDFS as an array (assuming time is field // number 3 in a tab-separated format): errors.filter(_.contains("HDFS")) .map(_.split(’t’)(3)) .collect() To m tri te a in bu gr w D m to R gr w to m ne be At this point, no work has been performed on the clus- ter. However, the user can now use the RDD in actions, e.g., to count the number of messages: errors.count() The user can also perform further transformations on the RDD and use their results, as in the following lines: // Count errors mentioning MySQL: errors.filter(_.contains("MySQL")).count() // Return the time fields of errors mentioning // HDFS as an array (assuming time is field // number 3 in a tab-separated format): errors.filter(_.contains("HDFS")) .map(_.split(’t’)(3)) .collect() After the first action involving errors runs, Spark will store the partitions of errors in memory, greatly speed- ing up subsequent computations on it. Note that the base tems, a glob includ but a graine which DSM make tolera Th RDD graine writes to app more need be rec partit ure, a nodes At this point, no work has been performed on the clus- ter. However, the user can now use the RDD in actions, e.g., to count the number of messages: errors.count() The user can also perform further transformations on the RDD and use their results, as in the following lines: // Count errors mentioning MySQL: errors.filter(_.contains("MySQL")).count() // Return the time fields of errors mentioning // HDFS as an array (assuming time is field // number 3 in a tab-separated format): errors.filter(_.contains("HDFS")) .map(_.split(’t’)(3)) .collect() After the first action involving errors runs, Spark will store the partitions of errors in memory, greatly speed- a g inc bu gra wh DS ma tol RD gra wr to mo ne be pa ure no transforma6ons ac6on
- 83. example: text search lineage of 6me fields michael mathioudakis 83 lines errors filter(_.startsWith(“ERROR”)) HDFS errors time fields filter(_.contains(“HDFS”))) map(_.split(‘t’)(3)) Figure 1: Lineage graph for the third query in our example. Boxes represent RDDs and arrows represent transformations. lines = spark.textFile("hdfs://...") errors = lines.filter(_.startsWith("ERROR")) cached pipelined transforma6ons if a par66on of errors is lost, filter is applied only the corresponding par66on of lines
- 84. transforma6ons and ac6ons Transformations map( f : T ) U) : RDD[T] ) RDD[U] filter( f : T ) Bool) : RDD[T] ) RDD[T] flatMap( f : T ) Seq[U]) : RDD[T] ) RDD[U] sample(fraction : Float) : RDD[T] ) RDD[T] (Deterministic sampling) groupByKey() : RDD[(K, V)] ) RDD[(K, Seq[V])] reduceByKey( f : (V,V) ) V) : RDD[(K, V)] ) RDD[(K, V)] union() : (RDD[T],RDD[T]) ) RDD[T] join() : (RDD[(K, V)],RDD[(K, W)]) ) RDD[(K, (V, W))] cogroup() : (RDD[(K, V)],RDD[(K, W)]) ) RDD[(K, (Seq[V], Seq[W]))] crossProduct() : (RDD[T],RDD[U]) ) RDD[(T, U)] mapValues( f : V ) W) : RDD[(K, V)] ) RDD[(K, W)] (Preserves partitioning) sort(c : Comparator[K]) : RDD[(K, V)] ) RDD[(K, V)] partitionBy(p : Partitioner[K]) : RDD[(K, V)] ) RDD[(K, V)] Actions count() : RDD[T] ) Long collect() : RDD[T] ) Seq[T] reduce( f : (T,T) ) T) : RDD[T] ) T lookup(k : K) : RDD[(K, V)] ) Seq[V] (On hash/range partitioned RDDs) save(path : String) : Outputs RDD to a storage system, e.g., HDFS Table 2: Transformations and actions available on RDDs in Spark. Seq[T] denotes a sequence of elements of type T. that searches for a hyperplane w that best separates two sets of points (e.g., spam and non-spam emails). The al- gorithm uses gradient descent: it starts w at a random ranks0input file map contribs0 links join reduce + map michael mathioudakis 84
- 85. example: pagerank se|ng N documents that contain links to other documents (e.g., webpages) pagerank itera6vely updates a rank score for each document by adding up contribu6ons from documents that link to it itera6on each document sends a contribu6on of rank/n to its neighbors rank: own document rank, n: number of neighbors updates its rank to α/Ν + (1-‐α)Σci ci: contribu6on received michael mathioudakis 85
- 86. example: pagerank michael mathioudakis 86 the contributions it received and N is the total number of documents. We can write PageRank in Spark as follows: // Load graph as an RDD of (URL, outlinks) pairs tur con ts at e- he ur- an in nk c- nt . . . Figure 3: Lineage graph for datasets in PageRank. val links = spark.textFile(...).map(...).persist() var ranks = // RDD of (URL, rank) pairs for (i <- 1 to ITERATIONS) { // Build an RDD of (targetURL, float) pairs // with the contributions sent by each page val contribs = links.join(ranks).flatMap { (url, (links, rank)) => links.map(dest => (dest, rank/links.size)) } // Sum contributions by URL and get new ranks ranks = contribs.reduceByKey((x,y) => x+y) .mapValues(sum => a/N + (1-a)*sum) } This program leads to the RDD lineage graph in Fig-
- 87. example: pagerank -‐ lineage s in Spark. Seq[T] denotes a sequence of elements of type T. ranks0input file map contribs0 ranks1 contribs1 ranks2 contribs2 links join reduce + map . . . Figure 3: Lineage graph for datasets in PageRank.michael mathioudakis 87
- 88. represen6ng rdds internal informa6on about rdds par66ons & par66oning scheme dependencies on parent RDDs func6on to compute it from parents michael mathioudakis 88
- 89. rdd dependencies narrow dependencies each par66on of the parent rdd is used by at most one par66on of the child rdd otherwise, wide dependencies michael mathioudakis 89
- 90. rdd dependencies union groupByKey join with inputs not co-partitioned join with inputs co-partitioned map, filter Narrow Dependencies: Wide Dependencies: Figure 4: Examples of narrow and wide dependencies. Eachmichael mathioudakis 90
- 91. scheduling when an ac6on is performed... (e.g., count() or save()) ... the scheduler examines the lineage graph builds a DAG of stages to execute each stage is a maximal pipeline of transforma6ons over narrow dependencies michael mathioudakis 91
- 92. scheduling join union groupBy map Stage 3 Stage 1 Stage 2 A: B: C: D: E: F: G: Figure 5: Example of how Spark computes job stages. Boxes with solid outlines are RDDs. Partitions are shaded rectangles, in black if they are already in memory. To run an action on RDDmichael mathioudakis 92 rdd par66on already in ram
- 93. memory management when not enough memory apply LRU evic6on policy at rdd level evict par66on from least recently used rdd michael mathioudakis 93
- 94. performance logis6c regression and k-‐means amazon EC2 10 itera6ons on 100GB datasets 100 node-‐clusters michael mathioudakis 94
- 95. performance - e m - r - e 80! 139! 46! 115! 182! 82! 76! 62! 3! 106! 87! 33! 0! 40! 80! 120! 160! 200! 240! Hadoop! HadoopBM! Spark! Hadoop! HadoopBM! Spark! Logistic Regression! K-Means! Iterationtime(s)! First Iteration! Later Iterations! Figure 7: Duration of the first and later iterations in Hadoop, HadoopBinMem and Spark for logistic regression and k-means using 100 GB of data on a 100-node cluster. michael mathioudakis 95
- 96. performance Example: Logistic Regression 0 500 1000 1500 2000 2500 3000 3500 4000 1 5 10 20 30 RunningTime(s) Number of Iterations Hadoop Spark 110 s / iteration first iteration 80 s further iterations 1 s michael mathioudakis 96 logis6c regression 2015
- 97. summary spark generalized map-‐reduce tailored to itera6ve computa6on and interac6ve querying simple programming model centered on rdds michael mathioudakis 97
- 98. references 1. Dean, Jeffrey, and Sanjay Ghemawat. "MapReduce: Simplified Data Processing on Large Clusters.” OSDI 2004. 2. Zaharia, Matei, et al. "Spark: Cluster Compu6ng with Working Sets." HotCloud 10 (2010): 10-‐10. 3. Zaharia, Matei, et al. "Resilient distributed datasets: A fault-‐tolerant abstrac6on for in-‐memory cluster compu6ng." Proceedings of the 9th USENIX conference on Networked Systems Design and Implementa3on. 4. Learning Spark: Lightning-‐Fast Big Data Analysis, by Holden Karau, Andy Konwinski, Patrick Wendell, Matei Zaharia 5. Chang F, Dean J, Ghemawat S, Hsieh WC, Wallach DA, Burrows M, Chandra T, Fikes A, Gruber RE. Bigtable: A distributed storage system for structured data. ACM Transac6ons on Computer Systems (TOCS). 2008 Jun 1;26(2):4. 6. Ghemawat, Sanjay, Howard Gobioff, and Shun-‐Tak Leung. "The Google file system." ACM SIGOPS opera3ng systems review. Vol. 37. No. 5. ACM, 2003. michael mathioudakis 98
- 99. next week spark programming michael mathioudakis 99
- 100. spark programming • crea6ng rdds • transforma6ons • ac6ons • lazy evalua6on • persistence • passing custom func6ons • working with key-‐value pairs – crea6on, transforma6ons, ac6ons • advanced data par66oning • global variables – accumulators (write-‐only) – broadcast (read-‐only) • reading and wri6ng data michael mathioudakis 100