





























































Ad
More Related Content
Similar to Lecture03 - K-Nearest-Neighbor Machine learning (20)
Recently uploaded (20)





![Get & Download Wondershare Filmora Crack Latest [2025]](https://cdn.slidesharecdn.com/ss_thumbnails/revolutionizingresidentialwi-fi-250422112639-60fb726f-250429170801-59e1b240-thumbnail.jpg?width=560&fit=bounds)












Ad
Lecture03 - K-Nearest-Neighbor Machine learning
- 1. K-Nearest Neighbour Tushar B. Kute, http://tusharkute.com
- 2. What sort of Machine Learning? • An idea that can be used for machine learning— as does another maxim involving poultry: "birds of a feather flock together." • In other words, things that are alike are likely to have properties that are alike. • We can use this principle to classify data by placing it in the category with the most similar, or "nearest" neighbors.
- 3. Nearest Neighbor Classification • In a single sentence, nearest neighbor classifiers are defined by their characteristic of classifying unlabeled examples by assigning them the class of the most similar labeled examples. Despite the simplicity of this idea, nearest neighbor methods are extremely powerful. They have been used successfully for: – Computer vision applications, including optical character recognition and facial recognition in both still images and video – Predicting whether a person enjoys a movie which he/she has been recommended (as in the Netflix challenge) – Identifying patterns in genetic data, for use in detecting specific protein or diseases
- 4. The kNN Algorithm • The kNN algorithm begins with a training dataset made up of examples that are classified into several categories, as labeled by a nominal variable. • Assume that we have a test dataset containing unlabeled examples that otherwise have the same features as the training data. • For each record in the test dataset, kNN identifies k records in the training data that are the "nearest" in similarity, where k is an integer specified in advance. • The unlabeled test instance is assigned the class of the majority of the k nearest neighbors
- 5. Example: Reference: Machine Learning with R, Brett Lantz, Packt Publishing
- 6. Example:
- 7. Example:
- 9. Example:
- 10. Calculating Distance • Locating the tomato's nearest neighbors requires a distance function, or a formula that measures the similarity between two instances. • There are many different ways to calculate distance. • Traditionally, the kNN algorithm uses Euclidean distance, which is the distance one would measure if you could use a ruler to connect two points, illustrated in the previous figure by the dotted lines connecting the tomato to its neighbors.
- 11. Calculating Distance Reference: Super Data Science
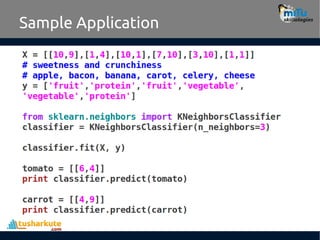
- 12. Distance • Euclidean distance is specified by the following formula, where p and q are th examples to be compared, each having n features. The term p1 refers to the value of the first feature of example p, while q1 refers to the value of the first feature of example q: • The distance formula involves comparing the values of each feature. For example, to calculate the distance between the tomato (sweetness = 6, crunchiness = 4), and the green bean (sweetness = 3, crunchiness = 7), we can use the formula as follows:
- 13. Distance
- 16. Choosing appropriate k • Deciding how many neighbors to use for kNN determines how well the mode will generalize to future data. • The balance between overfitting and underfitting the training data is a problem known as the bias- variance tradeoff. • Choosing a large k reduces the impact or variance caused by noisy data, but can bias the learner such that it runs the risk of ignoring small, but important patterns.
- 18. Choosing appropriate k • In practice, choosing k depends on the difficulty of the concept to be learned and the number of records in the training data. • Typically, k is set somewhere between 3 and 10. One common practice is to set k equal to the square root of the number of training examples. • In the classifier, we might set k = 4, because there were 15 example ingredients in the training data and the square root of 15 is 3.87.
- 19. Min-Max normalization • The traditional method of rescaling features for kNN is min- max normalization. • This process transforms a feature such that all of its values fall in a range between 0 and 1. The formula for normalizing a feature is as follows. Essentially, the formula subtracts the minimum of feature X from each value and divides by the range of X: • Normalized feature values can be interpreted as indicating how far, from 0 percent to 100 percent, the original value fell along the range between the original minimum and maximum.
- 20. The Lazy Learning • Using the strict definition of learning, a lazy learner is not really learning anything. • Instead, it merely stores the training data in it. This allows the training phase to occur very rapidly, with a potential downside being that the process of making predictions tends to be relatively slow. • Due to the heavy reliance on the training instances, lazy learning is also known as instance-based learning or rote learning.
- 21. Few Lazy Learning Algorithms • K Nearest Neighbors • Local Regression • Lazy Naive Bayes
- 23. Python Packages needed • pandas – Data Analytics • numpy – Numerical Computing • matplotlib.pyplot – Plotting graphs • sklearn – Classification and Regression Classes
- 25. KNN – Classification : Dataset • The best small project to start with on a new tool is the classification of iris flowers (e.g. the iris dataset). • This is a good project because it is so well understood. – Attributes are numeric so you have to figure out how to load and handle data. – It is a classification problem, allowing you to practice with perhaps an easier type of supervised learning algorithm. – It is a multi-class classification problem (multi-nominal) that may require some specialized handling. – It only has 4 attributes and 150 rows, meaning it is small and easily fits into memory (and a screen or A4 page). – All of the numeric attributes are in the same units and the same scale, not requiring any special scaling or transforms to get started.
- 26. Dataset
- 27. KNN – Classification : Dataset
- 28. Pre-processing
- 29. Characterize
- 30. Finding error with changed k
- 31. Error rate
- 32. Useful resources • www.mitu.co.in • www.pythonprogramminglanguage.com • www.scikit-learn.org • www.towardsdatascience.com • www.medium.com • www.analyticsvidhya.com • www.kaggle.com • www.stephacking.com • www.github.com
- 33. [email protected] Thank you This presentation is created using LibreOffice Impress 5.1.6.2, can be used freely as per GNU General Public License Web Resources https://mitu.co.in http://tusharkute.com /mITuSkillologies @mitu_group [email protected] /company/mitu- skillologies MITUSkillologies