
















![Offloading Computation
// DAXPY in CUDA
__global__
void daxpy(int n, double a, double *x, double *y) {
int i = blockIdx.x*blockDim.x + threadIdx.x;
if (i < n) y[i] = a*x[i] + y[i];
}
int main(void) {
int n = 1024;
double a;
double *x, *y; /* host copy of x and y */
double *x_d; *y_d; /* device copy of x and y */
int size = n * sizeof(double)
// Alloc space for host copies and setup values
x = (double *)malloc(size); fill_doubles(x, n);
y = (double *)malloc(size); fill_doubles(y, n);
// Alloc space for device copies
cudaMalloc((void **)&d_x, size);
cudaMalloc((void **)&d_y, size);
// Copy to device
cudaMemcpy(d_x, x, size, cudaMemcpyHostToDevice);
cudaMemcpy(d_y, y, size, cudaMemcpyHostToDevice);
// Invoke DAXPY with 256 threads per Block
int nblocks = (n+ 255) / 256;
daxpy<<<nblocks, 256>>>(n, 2.0, x_d, y_d);
// Copy result back to host
cudaMemcpy(y, d_y, size, cudaMemcpyDeviceToHost);
// Cleanup
free(x); free(y);
cudaFree(d_x); cudaFree(d_y);
return 0;
}
serial code
parallel exe on GPU
serial code
CUDA kernel
21](https://image.slidesharecdn.com/lecture11gpuarchcuda01-230302204713-cb58b1fb/85/lecture11_GPUArchCUDA01-pptx-21-320.jpg)




![DAXPY
// DAXPY in CUDA
__global__
void daxpy(int n, double a, double *x, double *y) {
int i = blockIdx.x*blockDim.x + threadIdx.x;
if (i < n) y[i] = a*x[i] + y[i];
}
// Invoke DAXPY with 256 threads per Thread Block
int nblocks = (n + 255) / 256;
daxpy<<<nblocks, 256>>>(n, 2.0, x, y);
26
Creating a number of threads which is (or slightly greater) the number of
elements to be processed, and each thread launch the same daxpy function.
Each thread finds it element to compute and do the work.](https://image.slidesharecdn.com/lecture11gpuarchcuda01-230302204713-cb58b1fb/85/lecture11_GPUArchCUDA01-pptx-26-320.jpg)






![Hello World! with Device Code
__device__ const char *STR = "Hello World!";
const char STR_LENGTH = 12;
__global__ void hellokernel(){
printf("%c", STR[threadIdx.x % STR_LENGTH]);
}
int main(void){
int num_threads = STR_LENGTH;
int num_blocks = 1;
hellokernel<<<num_blocks,num_threads>>>();
cudaDeviceSynchronize();
return 0;
}
Output:
$ nvcc
hello.cu
$ ./a.out
Hello World!
$
33](https://image.slidesharecdn.com/lecture11gpuarchcuda01-230302204713-cb58b1fb/85/lecture11_GPUArchCUDA01-pptx-33-320.jpg)
![Hello World! with Device Code
__device__ const char *STR = "Hello World!";
const char STR_LENGTH = 12;
__global__ void hellokernel(){
printf("%c", STR[threadIdx.x % STR_LENGTH]);
}
int main(void){
int num_threads = STR_LENGTH;
int num_blocks = 2;
hellokernel<<<num_blocks,num_threads>>>();
cudaDeviceSynchronize();
return 0;
}
__device__: Identify device-only data
threadIdx.x: the thread ID
Each thread only prints one character
34](https://image.slidesharecdn.com/lecture11gpuarchcuda01-230302204713-cb58b1fb/85/lecture11_GPUArchCUDA01-pptx-34-320.jpg)





























lecture11_GPUArchCUDA01.pptx
- 1. Manycore GPU Architectures and Programming: Outline • Introduction – GPU architectures, GPGPUs, and CUDA • GPU Execution model • CUDA Programming model • Working with Memory in CUDA – Global memory, shared and constant memory • Streams and concurrency • CUDA instruction intrinsic and library • Performance, profiling, debugging, and error handling • Directive-based high-level programming model – OpenACC and OpenMP 1
- 2. Computer Graphics GPU: Graphics Processing Unit 2
- 3. Graphics Processing Unit (GPU) 3 Image: http://www.ntu.edu.sg/home/ehchua/programming/opengl/CG_BasicsTheory.html
- 4. Graphics Processing Unit (GPU) 4 • Enriching user visual experience • Delivering energy-efficient computing • Unlocking potentials of complex apps • Enabling Deeper scientific discovery
- 5. 55 GPU Computing – General Purpose GPUs (GPGPUs) • Use GPU for more than just generating graphics – The computational resources are there, they are most of the time underutilized
- 6. GPU Performance Gains Over CPU 6 http://docs.nvidia.com/cuda/cuda-c-programming-guide
- 7. GPU Performance Gains Over CPU 7
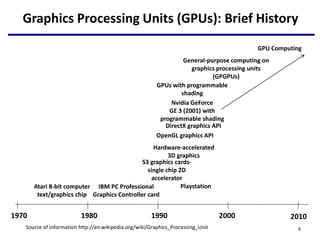
- 8. Graphics Processing Units (GPUs): Brief History 8 1970 2010 2000 1990 1980 Atari 8-bit computer text/graphics chip Source of information http://en.wikipedia.org/wiki/Graphics_Processing_Unit IBM PC Professional Graphics Controller card S3 graphics cards- single chip 2D accelerator OpenGL graphics API Hardware-accelerated 3D graphics DirectX graphics API Playstation GPUs with programmable shading Nvidia GeForce GE 3 (2001) with programmable shading General-purpose computing on graphics processing units (GPGPUs) GPU Computing
- 9. NVIDIA Products • NVIDIA Corp. is the leader in GPUs for HPC • We will concentrate on NVIDIA GPU – Others AMD, ARM, etc 9 1993 2010 1999 1995 http://en.wikipedia.org/wiki/GeForce 2009 2007 2008 2000 2001 2002 2003 2004 2005 2006 Established by Jen- Hsun Huang, Chris Malachowsky, Curtis Priem NV1 GeForce 1 GeForce 2 seriesGeForce FX series GeForce 8 series GeForce 200 series GeForce 400 series GTX460/465/470/475/ 480/485 GTX260/275/280/285/295 GeForce 8800 GT 80 Tesla Quadr o NVIDIA's first GPU with general purpose processors C870, S870, C1060, S1070, C2050, … Tesla 2050 GPU has 448 thread processors Fermi Kepler (2011) Maxwe (2013)
- 10. Unified Shader Architecture 10 FIGURE A.2.5 Basic unified GPU architecture. Example GPU with 112 streaming processor (SP) cores organized in 14 streaming multiprocessors (SMs); the cores are highly multithreaded. It has the basic Tesla architecture of an NVIDIA GeForce 8800. The processors connect with four 64-bit-wide DRAM partitions via an interconnection network. Each SM has eight SP cores, two special function units (SFUs), instruction and constant caches, a multithreaded instruction unit, and a shared memory. Copyright © 2009 Elsevier, Inc. All rights reserved.
- 11. Latest NVIDIA Volta GV100 GPU • Released May 2017 – Total 80 SM (Stream Multiprocessors) • Cores – 5120 FP32 cores • Can do FP16 also – 2560 FP64 cores – 640 Tensor cores • Memory – 16G HBM2 – L2: 6144 KB – Shared memory: 96KB * 80 (SM) – Register File: 20,480 KB (Huge) 11 https://devblogs.nvidia.com/parallelforall/inside-volta/
- 12. SM of Volta GPU 12 • Released May 2017 – Total 80 SM • Cores – 5120 FP32 cores • Can do FP16 also – 2560 FP64 cores – 640 Tensor cores • Memory – 16G HBM2 – L2: 6144 KB – Shared memory: 96KB * 80 (SM) – Register File: 20,480 KB (Huge)
- 13. What is GPU Today? • It is a processor optimized for 2D/3D graphics, video, visual computing, and display. • It is highly parallel, highly multithreaded multiprocessor optimized for visual computing. • It provide real-time visual interaction with computed objects via graphics images, and video. • It serves as both a programmable graphics processor and a scalable parallel computing platform. – Heterogeneous systems: combine a GPU with a CPU • It is called as Many-core 13
- 14. Programming for NVIDIA GPUs 14 http://docs.nvidia.com/cuda/cuda-c- programming-guide/
- 15. CUDA(Compute Unified Device Architecture) Both an architecture and programming model • Architecture and execution model – Introduced in NVIDIA in 2007 – Get highest possible execution performance requires understanding of hardware architecture • Programming model – Small set of extensions to C – Enables GPUs to execute programs written in C – Within C programs, call SIMT “kernel” routines that are executed on GPU. 15
- 16. GPU CUDA Programming Four important things • Offloading computation • Single Instruction Multiple Threads (SIMT): – Streaming and massively-parallel multithreading • Work well with the memory – Both between host memory and GPU memory • Make use of CUDA library 16
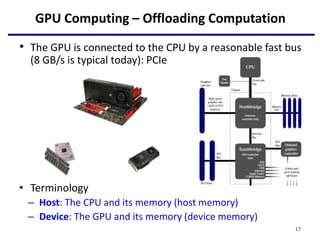
- 17. GPU Computing – Offloading Computation • The GPU is connected to the CPU by a reasonable fast bus (8 GB/s is typical today): PCIe • Terminology – Host: The CPU and its memory (host memory) – Device: The GPU and its memory (device memory) 17
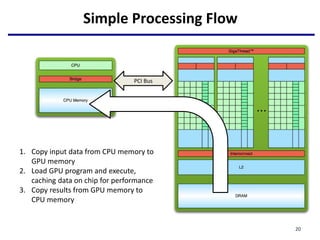
- 18. Simple Processing Flow 1. Copy input data from CPU memory to GPU memory PCI Bus 18
- 19. Simple Processing Flow 1. Copy input data from CPU memory to GPU memory 2. Load GPU program and execute, caching data on chip for performance PCI Bus 19
- 20. Simple Processing Flow 1. Copy input data from CPU memory to GPU memory 2. Load GPU program and execute, caching data on chip for performance 3. Copy results from GPU memory to CPU memory PCI Bus 20
- 21. Offloading Computation // DAXPY in CUDA __global__ void daxpy(int n, double a, double *x, double *y) { int i = blockIdx.x*blockDim.x + threadIdx.x; if (i < n) y[i] = a*x[i] + y[i]; } int main(void) { int n = 1024; double a; double *x, *y; /* host copy of x and y */ double *x_d; *y_d; /* device copy of x and y */ int size = n * sizeof(double) // Alloc space for host copies and setup values x = (double *)malloc(size); fill_doubles(x, n); y = (double *)malloc(size); fill_doubles(y, n); // Alloc space for device copies cudaMalloc((void **)&d_x, size); cudaMalloc((void **)&d_y, size); // Copy to device cudaMemcpy(d_x, x, size, cudaMemcpyHostToDevice); cudaMemcpy(d_y, y, size, cudaMemcpyHostToDevice); // Invoke DAXPY with 256 threads per Block int nblocks = (n+ 255) / 256; daxpy<<<nblocks, 256>>>(n, 2.0, x_d, y_d); // Copy result back to host cudaMemcpy(y, d_y, size, cudaMemcpyDeviceToHost); // Cleanup free(x); free(y); cudaFree(d_x); cudaFree(d_y); return 0; } serial code parallel exe on GPU serial code CUDA kernel 21
- 22. Streaming Processing To be efficient, GPUs must have high throughput, i.e. processing millions of pixels in a single frame, but may be high latency • “Latency is a time delay between the moment something is initiated, and the moment one of its effects begins or becomes detectable” • For example, the time delay between a request for texture reading and texture data returns • Throughput is the amount of work done in a given amount of time – CPUs are low latency low throughput processors – GPUs are high latency high throughput processors 22
- 23. Parallelism in CPUs v. GPUs • CPUs use task parallelism – Multiple tasks map to multiple threads – Tasks run different instructions – 10s of relatively heavyweight threads run on 10s of cores – Each thread managed and scheduled explicitly – Each thread has to be individually programmed (MPMD) 23 • GPUs use data parallelism – SIMD model (Single Instruction Multiple Data) SIMT – Same instruction on different data – 10,000s of lightweight threads on 100s of cores – Threads are managed and scheduled by hardware – Programming done for batches of threads (e.g. one pixel shader per group of pixels, or draw call)
- 24. Streaming Processing to Enable Massive Parallelism • Given a (typically large) set of data(“stream”) • Run the same series of operations (“kernel” or “shader”) on all of the data (SIMD) • GPUs use various optimizations to improve throughput: • Some on chip memory and local caches to reduce bandwidth to external memory • Batch groups of threads to minimize incoherent memory access – Bad access patterns will lead to higher latency and/or thread stalls. • Eliminate unnecessary operations by exiting or killing threads 24
- 25. CUDA Thread Hierarchy • Allows flexibility and efficiency in processing 1D, 2-D, and 3-D data on GPU. • Linked to internal organization • Threads in one block execute together. 25 Can be 1, 2 or 3 dimensions
- 26. DAXPY // DAXPY in CUDA __global__ void daxpy(int n, double a, double *x, double *y) { int i = blockIdx.x*blockDim.x + threadIdx.x; if (i < n) y[i] = a*x[i] + y[i]; } // Invoke DAXPY with 256 threads per Thread Block int nblocks = (n + 255) / 256; daxpy<<<nblocks, 256>>>(n, 2.0, x, y); 26 Creating a number of threads which is (or slightly greater) the number of elements to be processed, and each thread launch the same daxpy function. Each thread finds it element to compute and do the work.
- 27. Hello World! int main(void) { printf("Hello World!n"); return 0; } • Standard C that runs on the host • NVIDIA compiler (nvcc) can be used to compile programs with no device code • fornax.cse.sc.edu • Using nvcc compiler 27 Output: $ nvcc hello.cu $ ./a.out Hello World! $
- 28. Hello World! with Device Code __global__ void hellokernel() { printf(”Hello World!n”); } int main(void){ int num_threads = 1; int num_blocks = 1; hellokernel<<<num_blocks,num_threads>>>(); cudaDeviceSynchronize(); return 0; } Two new syntactic elements… Output: $ nvcc hello.cu $ ./a.out Hello World! $ 28
- 29. Access to fornax • ssh fornax.cse.sc.edu -l<username> • Or ssh <username>@fornax.cse.sc.edu • You need college VPN to access, go to vpn.cse.sc.edu to download and install on your computer 29
- 30. GPU code examples https://passlab.github.io/CSCE790/resources/gpu_code_examples/ • Use wget to download each file when you login: • E.g. wget https://passlab.github.io/CSCE790/resources/gpu_code_example s/hello-1.cu • nvcc hello-1.cu –o hello-1 • ./hello-1 • nvcc hello-2.cu –o hello-2 • ./hello-2 30
- 31. Hello World! with Device Code __global__ void hellokernel(void) • CUDA C/C++ keyword __global__ indicates a function that: – Runs on the device – Is called from host code • nvcc separates source code into host and device components – Device functions (e.g. hellokernel()) processed by NVIDIA compiler – Host functions (e.g. main()) processed by standard host compiler • gcc, cl.exe 31
- 32. Hello World! with Device COde hellokernel<<<num_blocks,num_threads>>>(); • Triple angle brackets mark a call from host code to device code – Also called a “kernel launch” – <<< ... >>> parameters are for thread dimensionality • That’s all that is required to execute a function on the GPU! 32
- 33. Hello World! with Device Code __device__ const char *STR = "Hello World!"; const char STR_LENGTH = 12; __global__ void hellokernel(){ printf("%c", STR[threadIdx.x % STR_LENGTH]); } int main(void){ int num_threads = STR_LENGTH; int num_blocks = 1; hellokernel<<<num_blocks,num_threads>>>(); cudaDeviceSynchronize(); return 0; } Output: $ nvcc hello.cu $ ./a.out Hello World! $ 33
- 34. Hello World! with Device Code __device__ const char *STR = "Hello World!"; const char STR_LENGTH = 12; __global__ void hellokernel(){ printf("%c", STR[threadIdx.x % STR_LENGTH]); } int main(void){ int num_threads = STR_LENGTH; int num_blocks = 2; hellokernel<<<num_blocks,num_threads>>>(); cudaDeviceSynchronize(); return 0; } __device__: Identify device-only data threadIdx.x: the thread ID Each thread only prints one character 34
- 35. Manycore GPU Architectures and Programming • GPU architectures, graphics and GPGPUs • GPU Execution model • CUDA Programming model • Working with Memory in CUDA – Global memory, shared and constant memory • Streams and concurrency • CUDA instruction intrinsic and library • Performance, profiling, debugging, and error handling • Directive-based high-level programming model – OpenACC and OpenMP 35
- 36. PCI Bus GPU Execution Model • The GPU is a physically separate processor from the CPU – Discrete vs. Integrated • The GPU Execution Model offers different abstractions from the CPU to match the change in architecture 36
- 37. PCI Bus GPU Execution Model • The GPU is a physically separate processor from the CPU – Discrete vs. Integrated • The GPU Execution Model offers different abstractions from the CPU to match the change in architecture 37
- 38. The Simplest Model: Single-Threaded • Single-threaded Execution Model – Exclusive access to all variables – Guaranteed in-order execution of loads and stores – Guaranteed in-order execution of arithmetic instructions • Also the most common execution model, and simplest for programmers to conceptualize and optimize Single-Threaded 38
- 39. CPU SPMD Multi-Threading • Single-Program, Multiple-Data (SPMD) model – Makes the same in-order guarantees within each thread – Says little or nothing about inter-thread behaviour or exclusive variable access without explicit inter-thread synchronization SPMD Synchronize 39
- 40. GPU Multi-Threading • Uses the Single-Instruction, Multiple-Thread model – Many threads execute the same instructions in lock-step – Implicit synchronization after every instruction (think vector parallelism) SIMT 40
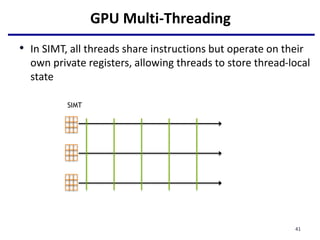
- 41. GPU Multi-Threading • In SIMT, all threads share instructions but operate on their own private registers, allowing threads to store thread-local state SIMT 41
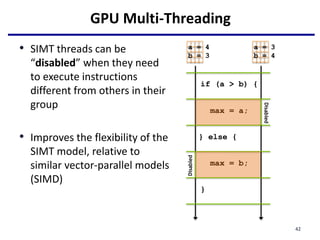
- 42. GPU Multi-Threading if (a > b) { max = a; } else { max = b; } a = 4 b = 3 a = 3 b = 4 Disabled Disabled • SIMT threads can be “disabled” when they need to execute instructions different from others in their group • Improves the flexibility of the SIMT model, relative to similar vector-parallel models (SIMD) 42
- 43. GPU Multi-Threading • GPUs execute many groups of SIMT threads in parallel – Each executes instructions independent of the others SIMT Group 0 SIMT Group 1 43
- 44. • How does this execution model map down to actual GPU hardware? • NVIDIA GPUs consist of many streaming multiprocessors (SM) Execution Model to Hardware 44
- 45. Execution Model to Hardware • NVIDIAGPU Streaming Multiprocessors (SM) are analogous to CPU cores – Single computational unit – Think of an SM as a single vector processor – Composed of multiple CUDA “cores”, load/store units, special function units (sin, cosine, etc.) – Each CUDA core contains integer and floating-point arithmetic logic units 45
- 46. Execution Model to Hardware • GPUs can execute multiple SIMT groups on each SM – For example: on NVIDIA GPUs a SIMT group is 32 threads, each Kepler SM has 192 CUDA cores simultaneous execution of 6 SIMT groups on an SM • SMs can support more concurrent SIMT groups than core count would suggest – Each thread persistently stores its own state in a private register set – Many SIMT groups will spend time blocked on I/O, not actively computing – Keeping blocked SIMT groups scheduled on an SM would waste cores – Groups can be swapped in and out without worrying about losing state 46
- 47. Execution Model to Hardware • This leads to a nested thread hierarchy on GPUs A single thread SIMT Group SIMT Groups that concurrently run on the same SM SIMT Groups that execute together on the same GPU 47
- 48. References 1. The sections on Introducing the CUDA Execution Model, Understanding the Nature of Warp Execution, and Exposing Parallelism in Chapter 3 of Professional CUDA C Programming 2. Michael Wolfe. Understanding the CUDA Data Parallel Threading Model. https://www.pgroup.com/lit/articles/insider/v2n1a5.htm 3. Will Ramey. Introduction to CUDA Platform. http://developer.download.nvidia .com/compute/developertrainingmaterials/presentations/general/W hy_GPU_ Computing.pptx 4. Timo Stich. Fermi Hardware & Performance Tips. http://theinf2.informatik.uni-jena.de/ theinf2_multimedia/Website_downloads/NVIDIA_Fermi_Perf_Jena_ 2011.pdf 48
- 49. More information about GPUs 49
- 50. GPU Architecture Revolution • Unified Scalar Shader Architecture • Highly Data Parallel Stream Processing 50 An Introduction to Modern GPU Architecture, Ashu Rege, NVIDIA Director of Developer Technology ftp://download.nvidia.com/developer/cuda/seminar/TDCI_Arch.pdf Image: http://www.ntu.edu.sg/home/ehchua/programming/opengl/CG_BasicsTheory.html
- 51. GPUs with Dedicated Pipelines -- late 1990s-early 2000s • Graphics chips generally had a pipeline structure with individual stages performing specialized operations, finally leading to loading frame buffer for display. • Individual stages may have access to graphics memory for storing intermediate computed data. 51 Input stage Vertex shader stage Geometry shader stage Rasterizer stage Frame buffer Pixel shading stage Graphics memory
- 52. Graphics Logical Pipeline Processor Per Function, each could be vector 52 Graphics logical pipeline. Programmable graphics shader stages are blue, and fixed-function blocks are white. Copyright © 2009 Elsevier, Inc. All rights reserved. Unbalanced and inefficient utilization
- 53. Unified Shader • Optimal utilization in unified architecture 53 FIGURE A.2.4 Logical pipeline mapped to physical processors. The programmable shader stages execute on the array of unified processors, and the logical graphics pipeline dataflow recirculates through the processors. Copyright © 2009 Elsevier, Inc. All rights reserved.
- 54. Specialized Pipeline Architecture 54 GeForce 6 Series Architecture (2004-5) From GPU Gems 2
- 55. GPU Memory Model SIMT Thread Groups on a GPU SIMT Thread Groups on an SM SIMT Thread Group Registers Local Memory On-Chip Shared Memory Global Memory Constant Memory Texture Memory • Now that we understand how abstract threads of execution are mapped to the GPU: – How do those threads store and retrieve data? – What rules are there about memory consistency? – How can we efficiently use GPU memory? 55
- 56. GPU Memory Model • There are many levels and types of GPU memory, each of which has special characteristics that make it useful – Size – Latency – Bandwidth – Readable and/or Writable – Optimal Access Patterns – Accessibility by threads in the same SIMT group, SM, GPU • Later lectures will go into detail on each type of GPU memory 56
- 57. GPU Memory Model • For now, we focus on two memory types: on-chip shared memory and registers – These memory types affect the GPU execution model • Each SM has a limited set of registers, each thread receives its own private set of registers • Each SM has a limited amount of Shared Memory, all SIMT groups on an SM share that Shared Memory SIMT Thread Groups on a GPU SIMT Thread Groups on an SM SIMT Thread Group Registers Local Memory On-Chip Shared Memory Global Memory Constant Memory Texture Memory 57
- 58. GPU Memory Model • Shared Memory and Registers are limited – Per-SM resources which can impact how many threads can execute on an SM • For example: consider an imaginary SM that supports executing 1,024 threads concurrently (32 SIMT groups of 32 threads) – Suppose that SM has a total of 16,384 registers – Suppose each thread in an application requires 64 registers to execute – Even though we can theoretically support 1,024 threads, we can only simultaneously store state for 16,384 registers / 64 registers per thread = 256 threads 58
- 59. GPU Memory Model • Parallelism is limited by both the computational and storage resources of the GPU. – In the GPU Execution Model, they are closely tied together. 59
- 60. The Host and the GPU • Cooperative co-processors – CPU and GPU work together on the problem at hand – Keep both processors well-utilized to get to the solution – Many different work partitioning techniques across CPU and GPU 60 PCIe Bus
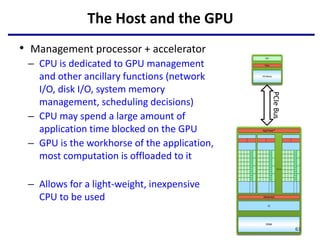
- 61. The Host and the GPU • Management processor + accelerator – CPU is dedicated to GPU management and other ancillary functions (network I/O, disk I/O, system memory management, scheduling decisions) – CPU may spend a large amount of application time blocked on the GPU – GPU is the workhorse of the application, most computation is offloaded to it – Allows for a light-weight, inexpensive CPU to be used 61 PCIe Bus
- 62. The Host and the GPU Co-processor • More computational bandwidth • Higher power consumption • Programmatically challenging • Requires knowledge of both architectures to be implemented effectively • Note useful for all applications Accelerator • Computational bandwidth of GPU only • Lower power consumption • Programming and optimizing focused on the GPU • Limited knowledge of CPU architecture required 62
- 63. GPU Communication • Communicating between the host and GPU is a piece of added complexity, relative to homogeneous programming models • Generally, CPU and GPU have physically and logically separate address spaces (though this is changing) PCIe Bus 63
- 64. GPU Communication Communication Medium Latency Bandwidth On-Chip Shared Memory A few clock cycles Thousands of GB/s GPU Memory Hundreds of clock cycles Hundreds of GB/s PCI Bus Hundreds to thousands of clock cycles Tens of GB/s • Data transfer from CPU to GPU over the PCI bus adds – Conceptual complexity – Performance overhead 64
- 65. GPU Communication GPU PCIe Bus Copy Copy Copy Copy Copy Compute Compute Compute Compute • As a result, computation-communication overlap is a common technique in GPU programming – Asynchrony is a first-class citizen of most GPU programming frameworks 65
- 66. GPU Execution Model • GPUs introduce a new conceptual model for programmers used to CPU single- and multi-threaded programming • While the concepts are different, they are no more complex than those you would need to learn to extract optimal performance from CPU architectures • GPUs offer programmers more control over how their workloads map to hardware, which makes the results of optimizing applications more predictable 66