











































































Lesson 1 introduction to_big_data_and_hadoop.pptx
- 1. Big Data Hadoop and Spark Developer
- 2. Introduction to Big Data and Hadoop
- 3. Describe the concepts of Big Data Explain Hadoop and how it addresses Big Data challenges Describe the components of Hadoop Ecosystem Learning Objectives By the end of this lesson, you will be able to:
- 4. Introduction to Big Data
- 5. Big Data Overview Big Data is the data that has high volume, variety, velocity, veracity, and value. 6 5 1 3 4 Manufacturing Consumer Energy Technology 2 Healthcare Banking According to US Bureau of Labour Statistics, Big Data alone will fetch 11.5 million jobs by 2026.
- 6. Traditional Decision-Making Experience and Intuition What We Think Rule of Thumb
- 7. Challenges of Traditional Decision-Making Takes a long time to arrive at a decision, therefore losing the competitive advantage Requires human intervention at various stages Lacks systematic linkage among strategy, planning, execution, and reporting Provides limited scope of data analytics, that is, it provides only a bird's eye view Obstructs company’s ability to make fully informed decisions
- 9. The Solution: Big Data Analytics Solution The decision-making is based on what you know which in turn is based on data analytics. It provides a comprehensive view of the overall picture which is a result of analyzing data from various sources. It provides streamlined decision-making from top to bottom. Big data analytics helps in analyzing unstructured data. It helps in faster decision-making thus improving the competitive advantage and saving time and energy.
- 10. Case Study: Google’s Self-Driving Car Technical Data Community Data Personal Data
- 11. Big Data Analytics Pipeline
- 12. What Is Big Data?
- 13. What Is Big Data? Big data refers to extremely large data sets that may be analyzed computationally to reveal patterns, trends, and associations, especially relating to human behavior and interactions.
- 14. Big Data at a Glance
- 15. Different Types of Data
- 16. Growth in Data By 2020, data will show an exponential rise!
- 17. Four Vs of Big Data
- 18. Four Vs of Big Data Volume Variety Velocity Veracity • Overall amount of information produced every day is rising exponentially • 2.3 trillion gigabytes of data is generated every day on the internet • Social media, CRM systems, e-mails, audio and video forms produce varied data • Analytics tools are used to segregate groups based on the type of data generated • More than 50,000 Google searches are completed • More than 125,000 YouTube videos are viewed • 7,000 tweets are sent out • More than 2 million e-mails are sent Inherent discrepancies in the data collected results in inaccurate predictions
- 19. Unstructured Data Conundrum Unstructured Data Semi-structured Data Web Logs Multimedia Social Media
- 20. Case Study: Royal Bank of Scotland
- 21. Case Study: Royal Bank of Scotland 100% of this data could be processed whereas only 3% could be processed earlier with traditional systems.
- 22. Case Study: Royal Bank of Scotland Sentiment analysis Improved customer satisfaction Reduced processing time The case study of Royal Bank of Scotland gave the following three things:
- 23. Challenges of Traditional System
- 24. Challenges of Traditional Systems (RDBMS and DWH) UNSTRUCTURED DATA Relational databases can’t categorize unstructured data. GROWTH RATE RDBMS systems are designed for steady data retention rather than rapid growth. DATA SIZE Data ranges from terabytes (10^12 bytes) to exabytes (10^18 bytes).
- 25. Advantages of Big Data 1 Processes all types of data at scale Processes huge data quickly in real-time 3 Can run anywhere and additional hardware can be added 4 Better decision-making, thanks to Hadoop 2 2
- 26. Companies Using Big Data
- 27. Big Data: Case Study 1 When do users watch a show? Where do they watch it? 3 On which device do they watch the show? 4 How often do they pause a program? 2 2 5 How often do they re-watch a program? 6 Do they skip the credits? 7 What are the keywords searched?
- 28. Big Data: Case Study Solution • Traditionally, the analysis of such data was done using a computer algorithm that was designed to produce a correct solution for any given instance. • As the data started to grow, a series of computers were employed to do the analysis. • They were also known as distributed systems. Multiple systems
- 29. Features of Big Data Analytics
- 30. Scalability in Big Data ● A scalable data platform accommodates rapid changes in the growth of data, either in traffic or volume. ● It utilizes and adds hardware or software to increase the output and storage of data. ● When a company has a scalable data platform, it is prepared for the potential of growth in its data needs.
- 31. Fault Tolerance in Big Data ● Fault tolerance in Big data or Hadoop HDFS refers to the working strength of a system in unfavorable conditions and how that system can handle such a situation. ● HDFS also maintains the replication factor by creating a replica of data on other available machines in the cluster if one machine fails unexpectedly.
- 32. Data Inconsistency in Big Data ● Once data is captured in big data, inconsistent or conflicting phenomena can occur at various granularities. ● It occurs from knowledge content, data, information, knowledge, meta-knowledge, to expertise, and can adversely affect the quality of the outcomes in Big data analysis process.
- 34. Distributed Systems A distributed system is a model in which components located on networked computers communicate and coordinate their actions by passing messages.
- 35. How Does a Distributed System Work? Data =1 Terabyte Data =1 Terabyte In recent times, distributed systems have been replaced by Hadoop.
- 36. Challenges of Distributed Systems System failure 1 2 Limited bandwidth 3 High programming complexity Any solution? Hadoop Since, multiple computers are used in a distributed system, there are high chances of:
- 38. What Is Hadoop? Hadoop is a framework that allows distributed processing of large datasets across clusters of commodity computers using simple programming models. Doug Cutting discovered Hadoop and named it after his son’s yellow toy elephant. It is inspired by the technical document published by Google.
- 39. Characteristics of Hadoop Can follow both horizontal and vertical scaling Can store huge data and decide to use it later Stores copies of the data on different machines and is resistant to hardware failure Can use ordinary computers for data processing Economical Reliable Scalable Flexible The four key characteristics of Hadoop are:
- 40. Traditional Database Systems vs. Hadoop Data sent to the program Program sent to the data Traditional System Hadoop VS.
- 41. Analogy of Traditional System and Hadoop
- 42. Standards and Structured Traditional Database Systems vs. Hadoop
- 43. Hadoop Core Components YARN Resource Management Data Processing Hadoop Core Storage
- 44. Components of Hadoop Ecosystem
- 45. Components of Hadoop Ecosystem Data Processing YARN Cluster Resource Management Data Visualization Data Analysis Data Exploration Data Ingestion Sqoop Flume Data Storage
- 46. Components of Hadoop Ecosystem HDFS (HADOOP DISTRIBUTED FILE SYSTEM) A storage layer for Hadoop Suitable for the distributed storage and processing Hadoop provides a command line interface to interact with HDFS Streaming access to file system data Provides file permissions and authentication
- 47. Components of Hadoop Ecosystem HBase Mainly used when you need random, real-time, read/write access to your Big Data Provides support to high volume of data and high throughput A NoSQL database or non-relational database Stores data in HDFS Table can have thousands of columns
- 48. Components of Hadoop Ecosystem SQOOP • Sqoop is a tool designed to transfer data between Hadoop and relational database servers. • It is used to import data from relational databases such as Oracle and MySQL to HDFS and export data from HDFS to relational databases.
- 49. Components of Hadoop Ecosystem FLUME Ideally suited for event data from multiple systems A distributed service for ingesting streaming data If you want to ingest event data such as, streaming data, sensor data, or log files, then you can use Flume.
- 50. Components of Hadoop Ecosystem SPARK An open source cluster computing framework Provides 100 times faster performance than Map-Reduce Supports machine learning, business intelligence, streaming, and batch processing
- 51. Components of Hadoop Ecosystem SPARK: COMPONENTS Apache Spark Spark Core and Resilient Distributed Datasets (RDDs) Spark SQL Spark Streaming Machine Learning Library (MLlib) GraphX
- 52. Components of Hadoop Ecosystem HADOOP MAP-REDUCE The original Hadoop processing engine which is primarily Java based An extensive and mature fault tolerance framework Based on the map and reduce programming model Commonly used
- 53. Components of Hadoop Ecosystem PIG Best for ad-hoc queries such as join and filter An open source dataflow system An alternative to writing Map-Reduce code Converts pig script to Map-Reduce code
- 54. Components of Hadoop Ecosystem IMPALA Very low latency – measured in milliseconds High performance SQL engine which runs on Hadoop cluster Ideal for interactive analysis Supports a dialect of SQL (Impala SQL)
- 55. Components of Hadoop Ecosystem HIVE Executes queries using Map-Reduce Similar to Impala Best for data processing and ETL
- 56. Components of Hadoop Ecosystem CLOUDERA SEARCH One of Cloudera's near-real-time access products Enables nontechnical users to search and explore data stored in or ingested into Hadoop and HBase Eliminates the need to move large datasets across infrastructures to address business tasks A fully integrated data processing platform
- 57. Components of Hadoop Ecosystem OOZIE Start End Action A B C Oozie Coordinator Engine Oozie Workflow Engine Action1 Action2 Action3 Oozie is a workflow or coordination system used to manage the Hadoop jobs
- 58. Components of Hadoop Ecosystem HUE (HADOOP USER EXPERIENCE) Hue is an acronym for Hadoop User Experience Hue is an open source Web interface for analyzing data with Hadoop It provides SQL editors for Hive, Impala, MySQL, Oracle, PostgreSQL, Spark SQL, and Solr SQL
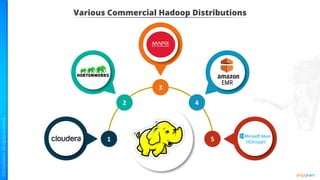
- 60. Various Commercial Hadoop Distributions HDInsight
- 61. Big Data Processing Components of Hadoop ecosystem work together to process big data. There are four stages of big data processing:
- 62. Walk-Through of the Simplilearn Cloud Lab Duration: 10 mins Problem Statement: In this demonstration, we will walk you through the Simplilearn cloud lab. Access: Click on the Practice Labs tab on the left side panel of the LMS. Copy or note the username and password that is generated. Click on the Launch Lab button. On the page that appears, enter the username and password in the respective fields, and click Login.
- 63. Describe the concepts of Big Data Explain Hadoop and how it addresses Big Data challenges Describe the components of Hadoop Ecosystem Key Takeaways You are now able to:
- 64. Knowledge Check
- 65. Knowledge Check a. b. c. d. Which of the following is a source of unstructured data? 1 Data from social media websites Transactional data in Amazon’s database Web and server logs All of the above
- 66. The correct answer is a. b. c. d. Knowledge Check Which of the following is a source of unstructured data? Unstructured data comprises of data that is usually not easily searchable, including formats like audio, video, and social media postings. a. 1 Data from social media websites Transactional data in Amazon’s database Web and server logs All of the above
- 67. Knowledge Check a. b. c. d. A bank wants to process 1000 transactions per second. Which one of the following Vs reflects this real-world use case? 2 Volume Variety Velocity Veracity
- 68. The correct answer is a. b. c. d. Knowledge Check A bank wants to process 1000 transactions per second. Which one of the following Vs reflects this real-world use case? Velocity is the frequency of incoming data that needs to be processed. Given use case is an example of an application that handles the velocity of data. c. 2 Volume Variety Velocity Veracity
- 69. Knowledge Check a. b. c. d. Why has popularity of big data increased tremendously in the recent years? 3 Due to increased volume of data Big data is an open source Abundance of unstructured data None of the above
- 70. The correct answer is a. b. c. d. Knowledge Check Why has popularity of big data increased tremendously in the recent years? Unstructured data is growing at astronomical rates, contributing to the big data deluge that's sweeping across enterprise data storage environments. a. 3 Due to increased volume of data Big data is an open source Abundance of unstructured data None of the above
- 71. Knowledge Check a. b. c. d. What is Hadoop? 4 It is an in-memory tool used in Mahout algorithm computing. It is a computing framework used for resource management. It is a framework that allows distributed processing of large datasets across clusters of commodity computers using a simple programming model. It is a search and analytics tool that provides access to analyze data.
- 72. The correct answer is a. b. c. d. Knowledge Check What is Hadoop? Hadoop is a framework that allows distributed processing of large datasets across clusters of commodity computers using a simple programming model. c. 4 It is an in-memory tool used in Mahout algorithm computing. It is a computing framework used for resource management. It is a search and analytics tool that provides access to analyze data. It is a framework that allows distributed processing of large datasets across clusters of commodity computers using a simple programming model.
- 73. Knowledge Check a. b. c. d. Which of the following is a column-oriented NoSQL database that runs on top of HDFS? 5 MongoDB Flume Ambari HBase
- 74. The correct answer is a. b. c. d. Knowledge Check Which of the following is a column-oriented NoSQL database that runs on top of HDFS? Apache HBase is a NoSQL database that runs on top of Hadoop as a distributed and scalable big data store. d. 5 MongoDB Flume Ambari HBase
- 75. Knowledge Check a. b. c. d. Scoop is used to _______. 6 Execute queries using Map-Reduce Stream event data from multiple systems Enable nontechnical users to search and explore data stored in or ingested into Hadoop and HBase Import data from relational databases to Hadoop HDFS and export from Hadoop file system to relational databases
- 76. The correct answer is a. b. c. d. Knowledge Check Scoop is used to _______. Scoop is used to import data from relational databases to Hadoop HDFS and export from Hadoop file system to relational databases. a. 6 Import data from relational databases to Hadoop HDFS and export from Hadoop file system to relational databases Execute queries using Map-Reduce Enable nontechnical users to search and explore data stored in or ingested into Hadoop and HBase Stream event data from multiple systems