Lessons learnt on a 2000-core cluster
Download as pptx, pdf3 likes1,143 views

The document summarizes lessons learned from running software on a 2000-core cluster. Key issues included: - RabbitMQ started refusing connections when there were too many, requiring establishing a RabbitMQ cluster. - Third-party libraries like Enyim for memcached access failed under high load and were replaced with custom code. - Tasks were split too finely, overwhelming RabbitMQ; larger-grained tasks improved performance. - A global event logging system ("Greg") contained bugs that slowed debugging, showing the importance of tools. Fixing issues like unbounded buffers and clock synchronization bugs improved its usefulness.




























































































Lessons learnt on a 2000-core cluster
- 1. Running our software on a 2000-core clusterLessons learnt
- 2. StructureFor each problemSymptomsMethod of investigationCauseAction takenMorale
- 3. BackgroundPretty simple: Distributing embarassingly parallel computations on a clusterDistribution fabric is RabbitMQPublish tasks to queuePull results from queueComputational listeners on cluster nodesTasks are “fast” (~1s cpu time) or “slow” (~15min cpu time)Tasks are split into parts (usually 160)Also parts share the same data chunk – it’s stored in memcached and task input contains the “shared data id”Requirements: 95% utilization for slow tasks, “as much as we can” for fast ones.
- 4. RabbitMQ starts refusing connectionsto some clients when there are too many of them.
- 5. InvestigationEventually turned out RabbitMQ supports max ~400 connections per process on Windows.
- 6. SolutionIn RabbitMQ:Establish a cluster of RabbitMQs2 “eternal” connections per client, 512 connections per instance, 1600 clients ~16 instances suffice.Instances start on same IP, on subsequent ports (5672,5673..)In code:Make both submitter and consumer scan ports until success
- 7. MoraleCapacity planning!If there’s a resource, plan how much of it you’ll need and with what pattern of usage. Otherwise you’ll exhaust it sooner or later.Network bandwidthNetwork latencyConnectionsThreadsMemoryWhatever
- 8. RabbitMQConsumer uses a legacy componentwhich can’t run concurrent instancesin the same directory
- 9. SolutionCreate temporary directory.Directory.SetCurrentDirectory() at startup.The temp directories pile up.
- 10. SolutionAt startup, clean up unused temp directories.How to know if it is unused?Create a lock file in the directoryAt startup, try removing lock files and dirsProblemRaces: several instances want to delete the same fileAll but one crash!Several solutions with various kinds of races, “fixed” by try/ignore band-aid…Just wrap the whole “clean-up” block in a try/ignore!That’s it.
- 11. MoraleIf it’s non-critical, wrap the whole thing with try/ignoreEven if you think it will never failIt will(maybe in the future, after someone changes the code…)Thinking “it won’t” is unneeded complexityLow-probable errors will happenThe chance is small but frequent0.001 probability of error, 2000 occasions = 87% that at least 1 failure occurs
- 12. Then the thing started working.Kind of.We asked for 1000 tasks “in flight”, and got only about 125.
- 13. Gateway is highly CPU loaded(perhaps that’s the bottleneck?)
- 14. SolutionEliminate data compressionIt was unneeded – 160 compressions of <1kb-sized data per task (1 per subtask)!Eliminate unneeded deserializationEliminate Guid.NewGuid() per subtaskIt’s not nearly as cheap as one might thinkEspecially if there’s 160 of them per taskTurn on server GC
- 15. Solution (ctd.)There was support for our own throttling and round-robining in codeWe didn’t actually need it! (needed before, but not now)Eliminated bothResultOops, RabbitMQ crashed!
- 16. Cause3 queues per clientRemember “Capacity planning”?A RabbitMQ queue is an exhaustable resourceDidn’t even remove unneeded queuesLong to explain, butDidn’t actually need them in this scenarioRabbitMQ is not ok with several thousand queuesrabbimqctl list_queues took an eternity
- 17. SolutionHave 2 queues per JOB and no cancellation queuesJust purge request queueOK unless several jobs share their request queueWe don’t use this option.
- 18. And then it workedCompute nodes at 100% cpuCluster quickly and sustainedly saturatedCluster fully loaded
- 19. MoraleEliminate bloat – Complexity killsEven if “We’ve got feature X” sounds coolRound-robining and throttlingCancellation queuesCompression
- 20. MoraleRethink what is CPU-cheapO(1) is not enoughYou’re going to compete with 2000 coresYou’re going to do this “cheap” stuff a zillion times
- 21. MoraleRethink what is CPU-cheap1 task = avg. 600ms of computation for 2000 coresSplit into 160 parts160 Guid.NewGuid()160 gzip compressions of 1kb data160 publishes to RabbitMQ160*N serializations/deserializationsIt’s not cheap at all, compared to 600msEsp. compared to 30ms, if you’re aiming at 95% scalability
- 22. And then we tried short tasks~1000x shorter
- 23. Oh well.The tasks are really short, after all…
- 24. And we started getting really a lot of memcached misses.
- 25. InvestigationHave we put so much into memcached that it evicted the tasks?Log:Key XXX not found> echo “GET XXX” | telnet 123.45.76.89 11211YYYYYYYYNope, it’s still there.
- 26. SolutionRetry until ok (with exponential back-off)
- 27. Desperately retryingBlue: Fetching from memcachedOrange: ComputingOh.
- 28. InvestigationMemcached can’t be down for that long, right?Right.Look into code…We cached the MemcachedClient objectsto avoid creating them per each requestbecause this is oh so slow
- 29. InvestigationThere was a bug in the memcached client library (Enyim)It took too long to discover that a server is back onlineOur “retries” were not actually retryingThey were stumbling on Enyim’s cached “server is down”.
- 30. SolutionDo not cache the MemcachedClient objectsResult:That helped. No more misses.
- 31. MoraleEliminate bloat – Complexity killsI think we’ve already talked of this one.Smart code is bad because you don’t know what it’s actually doing
- 32. Then we saw that memcached gets take 200ms each
- 33. InvestigationMemcached can’t be that slow, right?Right.Then who is slow?Who is between us and memcached?Right, Enyim.Creating those non-cached Client objects
- 34. SolutionWrite own fat-free “memcached client”Just a dozen lines of codeThe protocol is very simple.Nothing stands between us and memcached(well, except for the OS TCP stack)Result:That helped. Now gets took ~2ms.
- 35. MoraleEliminate bloat – Complexity killsShould I say more?
- 36. And this is how well we scaled these short tasks.About 5 1-second tasks/s. Terrific for a 2000-core cluster.
- 37. InvestigationThese stripes are almost parallel!Because tasks are round-robined to nodes in the same order.And this round-robiner’s not keeping up.Who’s that?RabbitMQ.We must have hit RabbitMQ limitsORLY?We push 160 messages per 1 task that takes 0.25ms on 2000 cores.Capacity planning?
- 38. InvestigationAnd we also have 16 RabbitMQs.And there’s just 1 queue.Every queue lives on 1 node.15/16 = 93.75% of pushes and pulls are indirect.
- 39. SolutionDon’t split these short tasks into parts.Result:That helped.~76 tasks/s submitted to RabbitMQ.
- 40. And then thisAn operation on a socket could not be performed because the system lacked sufficient buffer space or because a queue was full.(during connection to the Gateway)Spurious program crashes in Enyim code under load
- 41. SolutionUpdate Enyim to latest version.Result:Didn’t help.
- 42. SolutionGet rid of Enyim completely.(also implement put() – another 10 LOC)Result:That helpedNo more crashesPostfactum:Actually I forgot to destroy the Enyim client objects
- 43. MoraleThird-party libraries can failThey’re written by humansMaybe by humans who didn’t test them under these conditions (i.e. a large number of connections occupied by the rest of the program)YOU can fail (for example, misuse a library)You’re a humanDo not fear replacing a library with an easy piece of codeOf course if it is easy (for memcached it, luckily, was)“Why did they write a complex library?” Because it does more, but maybe not what you need.
- 44. But we’re still there at 76 tasks/s.
- 45. SolutionA thourough and blind CPU hunt in Client and Gateway.Didn’t want to launch a profiler on the cluster nodesbecause RDP was laggy and I was lazy(Most probably this was a mistake)
- 46. SolutionFix #1Special-case optimization for TO-0 tasks: Unneeded deserialization and splitting in Gateway (don’t split them at all)ResultGateway CPU load drops 2xScalability doesn’t improve
- 47. SolutionFix #2Eliminate task GUID generation in ClientParallelize submission of requestsTo spread WCF serialization CPU overhead over coresTurn on Server GCResultNow it takes 14 instead of 20s to push 1900 tasks to Gateway (130/s). Still not quite there.
- 48. Look at the cluster load againWhere do these pauses come from?They appear consistently on every run.
- 49. Where do these pauses come from?What can pause a .NET application?The Garbage CollectorThe OS (swap in/out)What’s common between these runs?~Number of tasks in memory at pauses
- 50. Where did the memory go?Node with Client had 98-99% physical memory occupied.By whom?SQL Server: >4GbMS HPC Server: Another few GbNo wonder.
- 51. SolutionTurn off HPC Server on this node.Result:These pauses got much milder
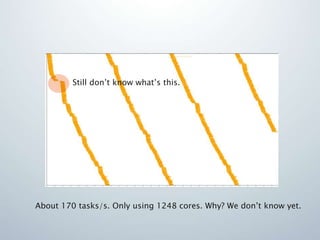
- 52. Still don’t know what’s this.About 170 tasks/s. Only using 1248 cores. Why? We don’t know yet.
- 53. MoraleMeasure your application.Eliminate interference from others. The interference can be drastic.Do not place a latency-sensitive component together with anything heavy (throughput-sensitive) like SQL Server.
- 54. But scalability didn’t improve much.
- 55. How do we understand why it’s so bad?Eliminate interference.
- 56. What interference is there?“Normalizing” tasksDeserializeExtract data to memcachedSerializeLet us remove it (prepare tasks, then shoot like a machinegun).Result: almost same – 172 tasks/s(Unrealistic but easier for further investigation)
- 57. So how long does it take to submit a task?(now that it’s the only thing we’re doing)Client: “Oh, quite a lot!”Gateway: “Not much.”1 track = 1 thread. Before BeginExecute: start orange bar, after BeginExecute: end bar.
- 58. Duration of these barsClient:“Usually and consistentlyabout 50ms.”Gateway: “Usually a couple ms.”
- 59. Very suspiciousWhat are those 50ms? Too round of a number.Perhaps some protocol is enforcing it?What’s our protocol?
- 60. What’s our protocol?tcp, right?var client = new CloudGatewayClient( "BasicHttpBinding_ICloudGateway");Oops.
- 61. SolutionChange to NetTcpBindingDon’t remember which is which :(Still looks strange, but much better.
- 62. About 340 tasks/s. Only using 1083 of >1800 cores! Why? We don’t know yet.
- 63. MoraleDouble-check your configuration.Measure the “same” thing in several ways.Time to submit a task, from POV of client and gateway
- 64. Here comes the dessert.“Tools matter”Already shown how pictures (and drawing tools) matter.We have a logger. “Greg” = “Global Registrator”.Most of the pictures wouldn’t be possible without it.Distributed (client/server)Accounts for machine clock offsetOutput is sorted on “global time axis”Lots of smart “scalability” tricks inside
- 65. Tools matterAnd it didn’t work quite well, for quite a long time. Here’s how it failed:Ate 1-2Gb RAMOutput was not sortedLogged events with a 4-5min lag
- 66. Tools matterHere’s how its failures mattered:Had to wait several minutes to gather all the events from a run.Sometimes not all of them were even gatheredAfter the problems were fixed, “experiment roundtrip” (change, run, collect data, analyze) skyrocketed at least 2x-3x.
- 67. Tools matterToo bad it was on the last day of cluster availability.
- 68. Why was it so buggy?The problem ain’t that easy (as it seemed).Lots of clients (~2000)Lots of messages1 RPC request per message = unacceptableDon’t log a message until clock synced with the client machineResync clock periodicallyLog messages in order of global time, not order of arrivalAnyone might (and does) fail or come back online at any momentMust not crashMust not overflow RAMMust be fast
- 69. How does it work?Client buffers messages and sends them to server in batches (client initiates). Messages marked with client’s local timestamp.Server buffers messages from each client.Periodically client and server calibrate clocks (server initiates).Once a client machine is calibrated its messages go to global buffer with transformed timestamp.Messages stay in global buffer for 10s (“if a message is earliest for 10s, it will remain earliest”)Global buffer(windowSize): Add(time, event)PopEarliest() : (time,event)
- 70. So, the tricks were:Limit the global buffer (drop messages if it’s full)“Dropping message”…“Dropped 10000,20000… messages”…”Accepting again after dropping N”Limit the send buffer on clientSameUse compression for batches(unused actually)Ignore (but log) errors like failed calibration, failed send, failed receive, failed connect etcRetry after a whileSend records to server in bounded batchesIf I’ve got 1mln records to say, I shouldn’t keep the connection busy for a long time (num.concurrent connections is a resource!). Cut into batches of 10000.Prefer polling to blocking because it’s simpler
- 71. So, the tricks were:Prefer “negative feedback” styleWake up, see what’s wrong, fixNot: “react to every event with preserving invariants”Much harder, sometimes impossible.Network performance tricks:TCP NO_DELAY whenever possibleWarm up the connection before calibratingCalibrate N times, average until confidence interval reached(actually precise calibration is theoretically impossible, only if network latencies are symmetric, which they aren’t…)
- 72. And the bugs were:Client called server even if it had nothing to say.Impact: *lots* of unneeded connections.Fix: Check, poll.
- 73. And the bugs were:“Pending records” per-client buffer was unbounded.Impact: Server ate memory if it couldn’t sync clockReason: Code duplication. Should have abstracted away “Bounded buffer”.Fix: Bound.
- 74. And the bugs were:If couldn’t calibrate with client at 1st attempt, never calibrated.Impact: Well… Esp. given the previous bug.Reason: try{loop}/ignore instead of loop{try/ignore}Meta reason: too complex code, mixed levels of abstractionMixed what’s being “tried” with how it’s being managed (failures handled)Fix: change to loop{try/ignore}.Meta fix: Go through all code, classify methods into “spaghetti” and “flat logic”. Extract logic from spaghetti.
- 75. And the bugs were:No calibration with a machine in scenario “Start client A, start client B, kill client A”Impact: Very bad.Reason: If client couldn’t establish a calibration TCP listener, it wouldn’t try again (“someone else’s listening, not my job”).Then that guy dies and whose job is it now?Meta reason: One-time global initialization for a globally periodic process (init; loop{action}).Global conditions change and initialization is needed again.Fix: Transform to loop{init; action} – periodically establish listener (ignore failure).
- 76. And the bugs were:Events were not coming out in order.Impact: Not critical by itself, but casts doubt on the correctness of everything.If this doesn’t work, how can we be sure that we even get all messages?All in all, very bad.Reason: ???And they were also coming out with a huge lag.Impact: Dramatic (as already said).
- 77. The case of the lagging events There were many places where they could lag.That’s already very bad by itself…On client? (repeatedly failing to connect to server)On server? (repeatedly failing to read from client)In per-client buffer? (failing to calibrate / to notice that calibration is done)In global buffer?(failing to notice that this event has “expired” its 10s)
- 78. The case of the lagging eventsMeta fix:More internal loggingDidn’t help.This logging was invisible because done with Trace.WriteLine and viewed with DbgView, which doesn’t work between sessionsMy fault – didn’t cope with this.Only failed under large load from many machines (the worst kind of error…)But could have helped.Log/assert everythingIf things were fine where you expect them to be, there’d be no bugs.But there are.
- 79. The case of the lagging eventsInvestigation by sequential elimination of reasons.The most suspicious thing was “time-buffered queue”.A complex piece of mud.“Kind of” a priority queue with tracking times and sleeping/blocking on “pop”Looked right and passed tests, but felt uncomfortableRewritten it.
- 80. The case of the lagging eventsRewritten it.Polling instead of blocking: “What’s the earliest event? Has it been here for 10s yet?”A classic priority queue “from the book”Peek minimum, check expiry pop or not.That’s it.Now the queue definitely worked correctly.But events still lagged.
- 81. The case of the lagging eventsWhat remained? Only a walk through the code.
- 82. The case of the lagging eventsA while later…
- 83. The case of the lagging eventsA client has 3 associated threads.(1 per batch of records) Thread that reads them to per-client buffer.(1 per client) Thread that pulls from per-client bufferand writes calibrated events to global buffer(after calibration is done)(1 per machine) Calibration thread
- 84. The case of the lagging eventsA client has 3 associated threads.And they were created in ThreadPool.And ThreadPool creates no more than 2 new threads/s.
- 85. The case of the lagging eventsSo we have 2000 clients on 250 machines.A couple thousand threads.Not a big deal, OS can handle more. And they’re all doing IO. That’s what an OS is for.Created at a rate of 2 per second.4-5 minutes pass before the calibration thread is created in pool for the last machine!
- 86. The case of the lagging eventsFix: Start a new thread without ThreadPool.And suddenly everything worked.
- 87. The case of the lagging eventsWhy did it take so long to find?Unreproducible on less than a dozen machinesBad internal debugging tools (Trace.WriteLine)And lack of understanding of their importanceToo complex architectureToo many places can fail, need to debug all at once
- 88. The case of the lagging eventsMorale:Functional abstractions leak in non-functional ways.Thread pool functional abstraction = “Do something soon”Know how exactly they leak, or don’t use them.“Soon, but no sooner than 2/s”
- 89. Greg againRewritten it nearly from scratchCalibration now also initiated by clientServer only accepts client connections and moves messages around the queuesPattern “Move responsibility to client” – server now does a lot less calibration-related bookkeepingPattern “Eliminate dependency cycles / feedback loops”Now server doesn’t care at all about failure of clientPattern “Do one thing and do it well”Just serve requests.Don’t manage workflow.It’s now easier for server to throttle the number of concurrent requests of any kind
- 90. The good partsOK, lots of things were broken. Which weren’t?Asynchronous processingWe’d be screwed if not for the recent “fully asynchronous” rewrite“Concurrent synchronous calls” are a very scarce resourceReliance on a fault-tolerant abstraction: MessagingWe’d be screwed if RabbitMQ didn’t handle the failures for usGood measurement toolsWe’d be blindfolded without the global clock-synced logging and drawing toolsGood deployment scriptsWe’d be in a configuration hell if we did that manuallyReasonably low couplingWe’d have much longer experiment roundtrips if we ran tests on “the real thing” (Huge Legacy Program + HPC Server + everything)It was not hard to do independent performance optimizations of all the component layers involved (and there were not too many layers)
- 91. Morales
- 92. MoralesTools matterWould be helpless without the graphs Would have done much more if the logger was fixed earlier…Capacity planningHow much of X will you need for 2000 cores?Complexity killsProblems are everywhere, and if they’re also complex, then you can’t fix themRethink “CPU cheap”Is it cheap compared to what 2000 cores can do?Abstractions leakDo not rely on a functional abstraction when you have non-functional requirementsEverything failsEspecially youPlanning to have failures is more robust than planning how exactly to fight themThere are no “almost improbable errors”: probabilities accumulateExplicitly ignore failures in non-critical codeCode that does this is larger but simpler to understand than code that doesn’tThink where to put responsibility for whatDifference in ease of implementation may be dramatic
- 93. That’s all.