Leveraging HPC Resources to Improve the Experimental Design of Software Analytics

Software analytics (for software quality purpose) is a statistical or machine learning classifier that is trained to identify defect-prone software modules. The goal of software analytics is to help software engineers prioritize their software testing effort on the most-risky modules and understand past pitfalls that lead to defective code. While the adoption of software analytics enables software organizations to distil actionable insights, there are still many barriers to broad and successful adoption of such analytics systems. Indeed, even if software organizations can access such invaluable software artifacts and toolkits for data analytics, researchers and practitioners often have little knowledge to properly develop analytics systems. Thus, the accuracy of the predictions and the insights that are derived from analytics systems is one of the most important challenges of data science in software engineering. In this work, we conduct a series of empirical investigation to better understand the impact of experimental components (i.e., class mislabelling, parameter optimization of classification techniques, and model validation techniques) on the performance and interpretation of software analytics. To accelerate a large amount of compute-intensive experiment, we leverage the High-Performance-Computing (HPC) resources of Centre for Advanced Computing (CAC) from Queen’s University, Canada. Through case studies of systems that span both proprietary and open- source domains, we demonstrate that (1) realistic noise does not impact the precision of software analytics; (2) automated parameter optimization for classification techniques substantially improve the performance and stability of software analytics; and (3) the out-of- sample bootstrap validation technique produces a good balance between bias and variance of performance estimates. Our results lead us to conclude that the experimental components of analytics modelling impact the predictions and associated insights that are derived from software analytics. Empirical investigations on the impact of overlooked experimental components are needed to derive practical guidelines for analytics modelling.













































































































More Related Content
What's hot (20)
Similar to Leveraging HPC Resources to Improve the Experimental Design of Software Analytics (20)


















Recently uploaded (20)




















Leveraging HPC Resources to Improve the Experimental Design of Software Analytics
- 1. 1 Leveraging HPC Resources to Improve the Experimental Design of Software Analytics Chakkrit (Kla) Tantithamthavorn http://chakkrit.com [email protected] @klainfo
- 3. 2 My academic career Master 2014 PhD 2016
- 4. 2 My academic career Master 2014 PhD 2016 PostDoc 2017
- 5. 2 My academic career Master 2014 PhD 2016 PostDoc 2017 Faculty Member Dec 2017
- 6. Software defects are prevalent in today software development life cycle 3 Deliver software product to customers Software Team
- 7. Software defects are prevalent in today software development life cycle 4 Deliver software product to customers Customers Software Team
- 8. Software defects are prevalent in today software development life cycle 5 Software Team Deliver software product to customers Customers
- 9. Software defects are prevalent in today software development life cycle 5 Software Team Deliver software product to customers Customers Crash Error Stop working Freeze
- 10. Software defects are prevalent in today software development life cycle 5 Software Team Deliver software product to customers Customers Crash Error Stop working Freeze
- 11. 6 Questions arise during a team meeting Tester Where are the top- ten risky software modules?
- 12. 6 Questions arise during a team meeting Tester Where are the top- ten risky software modules? Developer Why defects happen?
- 13. 6 Questions arise during a team meeting Tester Where are the top- ten risky software modules? Developer Why defects happen? Manager When we are ready to ship the next release?
- 14. 7 Software analytics enables software practitioners to make informed and empirically-supported decisions Goals of software analytics: • Improve software quality • Better developer productivity • Improve user experience
- 15. 8 Two major innovations of software analytics for software quality purpose
- 16. 8 Predict what are risky modules Two major innovations of software analytics for software quality purpose
- 17. 8 Predict what are risky modules Understand what makes software fail Quality improvement plan Two major innovations of software analytics for software quality purpose
- 18. Pre-release period Release Software quality analytics Software analytics is used to predict software modules that are likely to be defective in the future Post-release period 9
- 19. Pre-release period Release Software quality analytics Module A Module C Module B Module D Software analytics is used to predict software modules that are likely to be defective in the future Post-release period Clean Defect-prone Clean Defect-prone Module A Module C Module B Module D 9
- 20. Pre-release period Release Software quality analytics Module A Module C Module B Module D Software analytics is used to predict software modules that are likely to be defective in the future Post-release period Clean Defect-prone Clean Defect-prone Module A Module C Module B Module D Lewis et al., ICSE’13 Mockus et al., BLTJ’00 Ostrand et al., TSE’05 Kim et al., FSE’15 Naggappan et al., ICSE’06 Zimmermann et al., FSE’09 Caglayan et al., ICSE’15 Tan et al., ICSE’15 Shimagaki et al., ICSE’16 9
- 21. 10 Code Properties lines of code, complexity Large and more complex files m ore defect-prone Files that are written by experienced developers Developer author experience less defect-prone Dev. Process #prior defects, #commits, #churn Files that were changed many times m ore defect-prone Organization #authors, #major authors Files that are changed by many authors m ore defect-prone Software analytics is used to understand software defect characteristics
- 22. A big picture of software analytics modelling 11 Data Preparation Model Construction Model Validation Software repositories Dataset Analytics model Accuracy
- 23. Statistical Model Training Corpus Classifier Parameters (7) Model Construction Performance Measures Data Sampling (2) Data Cleaning and Filtration (3) Metrics Extraction and Normalization (4) Descriptive Analytics (+/-) Relationship to the Outcome Y X x Software Repository Software Dataset Clean Dataset Studied Dataset Outcome Studied Metrics Control Metrics +~ (1) Data Collection Predictive Analytics Prescriptive Analytics (8) Model Validation (9) Model Analysis and Interpretation Importance Score Testing Corpus PredictionsPerformance Estimates Patterns 12 In reality, software analytics modelling is detailed and complex
- 24. 13 While today research toolkits (e.g., R, Weka) are easily accessible, they come at risks https://en.wikipedia.org/wiki/All_models_are_wrong
- 25. 14 Practitioners often borrow techniques from other domains that may not work best in SE domain
- 26. 15 Such challenge has an ultimate negative impact on developers, managers, and software company Misleading insights Developers initiate wrong plan for quality improvement Testers waste time and resources Wrong predictions + The operating cost of software company is expensive
- 27. 16 (1) What is the best pattern for software analytics modelling? (2) What is the impact of experimental factors on its accuracy?
- 28. There are various experimental factors involved in software analytics modelling Model Validation Performance Measures Model Construction Classification Technique Data Preparation Metrics Collection Defect Labelling Classifier Parameters Validation Techniques 17
- 29. 18 Leveraging HPC Resources to Improve the Experimental Design of Software Analytics Noise in Defect Datasets (ICSE’15) Parameters Optimization (ICSE’16) Model Validation Techniques (TSE’17) Defect Labelling Classifier Parameters Validation Techniques 2 3 4 Experimental Factors Analysis (TSE’16) Experimental Factors 1
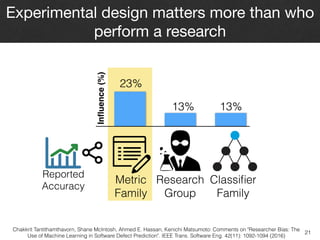
- 30. 19 Which factors (i.e., researchers or experimental components) have the largest impact on the accuracy of software analytics? Dataset Family Metric Family Classifier Family Research Group Reported AccuracyExtract experimental factors from 42 defect prediction studies Chakkrit Tantithamthavorn, Shane McIntosh, Ahmed E. Hassan, Kenichi Matsumoto: Comments on "Researcher Bias: The Use of Machine Learning in Software Defect Prediction". IEEE Trans. Software Eng. 42(11): 1092-1094 (2016)
- 31. 20 Using ANOVA analysis to investigate the relationship between reported accuracy and experimental factors Dataset Family Metric Family Classifier Family Research Group Reported Accuracy Studied factors Analyze the impact of factors ANOVA Analysis Outcome Chakkrit Tantithamthavorn, Shane McIntosh, Ahmed E. Hassan, Kenichi Matsumoto: Comments on "Researcher Bias: The Use of Machine Learning in Software Defect Prediction". IEEE Trans. Software Eng. 42(11): 1092-1094 (2016)
- 32. Experimental design matters more than who perform a research Reported Accuracy Influence(%) Metric Family 23% Research Group 13% 13% Classifier Family 21 Chakkrit Tantithamthavorn, Shane McIntosh, Ahmed E. Hassan, Kenichi Matsumoto: Comments on "Researcher Bias: The Use of Machine Learning in Software Defect Prediction". IEEE Trans. Software Eng. 42(11): 1092-1094 (2016)
- 33. 22 Leveraging HPC Resources to Improve the Experimental Design of Software Analytics Noise in Defect Datasets (ICSE’15) Parameters Optimization (ICSE’16) Model Validation Techniques (TSE’17) Defect Labelling Classifier Parameters Validation Techniques 2 3 4 Experimental Factors Analysis (TSE’16) Experimental Factors 1 Experimental design matters more than who perform a research
- 34. 23 Leveraging HPC Resources to Improve the Experimental Design of Software Analytics Noise in Defect Datasets (ICSE’15) Parameters Optimization (ICSE’16) Model Validation Techniques (TSE’17) Defect Labelling Classifier Parameters Validation Techniques 2 3 4 Experimental Factors Analysis (TSE’16) Experimental Factors 1 Experimental design matters more than who perform a research
- 35. The accuracy of software analytics depends on the quality of the data from which it was trained Inaccurate Insights Inaccurate Predictions Noisy Dataset 24 Analytics model
- 36. The accuracy of software analytics depends on the quality of the data from which it was trained Such inaccurate predictions and insights could lead to missteps in practice. Inaccurate Insights Inaccurate Predictions Noisy Dataset 24 Analytics model
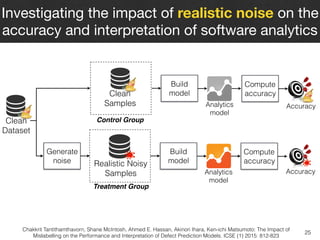
- 37. 25 Investigating the impact of realistic noise on the accuracy and interpretation of software analytics Clean Samples Realistic Noisy Samples Clean Dataset Generate noise Control Group Treatment Group Build model Build model Analytics model Analytics model Accuracy Accuracy Compute accuracy Compute accuracy Chakkrit Tantithamthavorn, Shane McIntosh, Ahmed E. Hassan, Akinori Ihara, Ken-ichi Matsumoto: The Impact of Mislabelling on the Performance and Interpretation of Defect Prediction Models. ICSE (1) 2015: 812-823
- 38. 26 Leveraging HPC resources to improve experimental design for software analytics 18 datasets 26 classification techniques x 1 million analytics model 1,000 validation samples x =x 2 settings of control and treatment
- 39. 26 Leveraging HPC resources to improve experimental design for software analytics 18 datasets 26 classification techniques x 1 million analytics model 1,000 validation samples x =x 2 settings of control and treatment If one model requires 1 min computation time, then an experiment needs 2 years to be finished
- 40. 26 Leveraging HPC resources to improve experimental design for software analytics 18 datasets 26 classification techniques x 1 million analytics model 1,000 validation samples x =x 2 settings of control and treatment If one model requires 1 min computation time, then an experiment needs 2 years to be finished A HPC cluster of 40 CPUs could significantly accelerate our experiment from 2 years to 17 days
- 41. 27 While the recall is often impacted, the precision is rarely impacted = Realistic Noisy Clean Interpretation: Ratio = 1 means there is no impact. Precision Recall 1.00.50.02.01.5 Ratio
- 42. 27 While the recall is often impacted, the precision is rarely impacted = Realistic Noisy Clean Interpretation: Ratio = 1 means there is no impact. Precision is rarely impacted by realistic noise Precision Recall 1.00.50.02.01.5 Ratio
- 43. 27 While the recall is often impacted, the precision is rarely impacted = Realistic Noisy Clean Interpretation: Ratio = 1 means there is no impact. Models trained on noisy data achieve 56% of the recall of models trained on clean data Precision is rarely impacted by realistic noise Precision Recall 1.00.50.02.01.5 Ratio
- 44. 28 Leveraging HPC Resources to Improve the Experimental Design of Software Analytics Noise in Defect Datasets (ICSE’15) Parameters Optimization (ICSE’16) Model Validation Techniques (TSE’17) Defect Labelling Classifier Parameters Validation Techniques 2 3 4 Experimental Factors Analysis (TSE’16) Experimental Factors 1 Experimental design matters more than who perform a research Researchers can rely on the accuracy of modules labelled as defective by analytics models that are trained using such noisy data
- 45. 29 Leveraging HPC Resources to Improve the Experimental Design of Software Analytics Noise in Defect Datasets (ICSE’15) Parameters Optimization (ICSE’16) Model Validation Techniques (TSE’17) Defect Labelling Classifier Parameters Validation Techniques 2 3 4 Experimental Factors Analysis (TSE’16) Experimental Factors 1 Experimental design matters more than who perform a research Researchers can rely on the accuracy of modules labelled as defective by analytics models that are trained using such noisy data
- 46. Software analytics is trained using classification techniques Defect Dataset Classification Technique Model Construction 30 Analytics model
- 47. Such classification techniques often require parameter settings Defect Dataset Classification Technique Model Construction 31 Analytics model
- 48. Such classification techniques often require parameter settings Defect Dataset Classification Technique Model Construction Classifier Parameters 31 Analytics model
- 49. Such classification techniques often require parameter settings 26 of the 30 most commonly used classification techniques require at least one parameter setting Defect Dataset Classification Technique Model Construction Classifier Parameters 31 Analytics model
- 50. randomForest package Default setting of the number of trees in a random forest 10 50 100 500 bigrf package Different toolkits have different default settings for the same classification technique 32
- 51. 33 Investigating the impact of automated parameter optimization on the accuracy of software analytics Defect dataset Apply automated parameter optimization Control Group Treatment Group Build model Build model Analytics model Analytics model Accuracy Accuracy Compute accuracy Compute accuracy Chakkrit Tantithamthavorn, Shane McIntosh, Ahmed E. Hassan, Kenichi Matsumoto: Automated parameter optimization of classification techniques for defect prediction models. ICSE 2016: 321-332 default setting optimal setting
- 52. Large Medium Small ● ● ● ● ● ● ● ● 0.0 0.1 0.2 0.3 0.4 C 5.0 AdaBoost AVN N etC ART PC AN N etN N etFDA M LPW eightD ecayM LP LM TG PLS LogitBoostKN N xG BTreeG BM N B R BF SVM R adia G AM AUCPerformanceImprovement 34 Each boxplot presents the performance improvement for all the 18 studied datasets Automated parameter optimization can substantially improve the accuracy of software analytics
- 53. Large Medium Small ● ● ● ● ● ● ● ● 0.0 0.1 0.2 0.3 0.4 C 5.0 AdaBoost AVN N etC ART PC AN N etN N etFDA M LPW eightD ecayM LP LM TG PLS LogitBoostKN N xG BTreeG BM N B R BF SVM R adia G AM AUCPerformanceImprovement 35 9 of the 26 studied classification techniques have a large performance improvement Automated parameter optimization can substantially improve the accuracy of software analytics
- 54. 36 Leveraging HPC Resources to Improve the Experimental Design of Software Analytics Noise in Defect Datasets (ICSE’15) Parameters Optimization (ICSE’16) Model Validation Techniques (TSE’17) Defect Labelling Classifier Parameters Validation Techniques 2 3 4 Experimental Factors Analysis (TSE’16) Experimental Factors 1 Experimental design matters more than who perform a research Researchers can rely on the accuracy of modules labelled as defective by analytics models that are trained using such noisy data Researchers should apply automated parameter optimization in order to improve the performance and reliability of software analytics
- 55. 37 Leveraging HPC Resources to Improve the Experimental Design of Software Analytics Noise in Defect Datasets (ICSE’15) Parameters Optimization (ICSE’16) Model Validation Techniques (TSE’17) Defect Labelling Classifier Parameters Validation Techniques 2 3 4 Experimental Factors Analysis (TSE’16) Experimental Factors 1 Experimental design matters more than who perform a research Researchers can rely on the accuracy of modules labelled as defective by analytics models that are trained using such noisy data Researchers should apply automated parameter optimization in order to improve the performance and reliability of software analytics
- 56. Estimating model accuracy requires the use of Model Validation Techniques (MVTs) Defect Dataset Training Corpus Testing Corpus Model Validation 38 Chakkrit Tantithamthavorn, Shane McIntosh, Ahmed E. Hassan, Kenichi Matsumoto: An Empirical Comparison of Model Validation Techniques for Defect Prediction Models. IEEE Trans. Software Eng. 43(1): 1-18 (2017)
- 57. Estimating model accuracy requires the use of Model Validation Techniques (MVTs) Defect Dataset Training Corpus Testing Corpus Analytics model Model Validation 38 Chakkrit Tantithamthavorn, Shane McIntosh, Ahmed E. Hassan, Kenichi Matsumoto: An Empirical Comparison of Model Validation Techniques for Defect Prediction Models. IEEE Trans. Software Eng. 43(1): 1-18 (2017)
- 58. Estimating model accuracy requires the use of Model Validation Techniques (MVTs) Defect Dataset Training Corpus Testing Corpus Analytics model Model Validation Performance Estimates Compute accuracy 38 Chakkrit Tantithamthavorn, Shane McIntosh, Ahmed E. Hassan, Kenichi Matsumoto: An Empirical Comparison of Model Validation Techniques for Defect Prediction Models. IEEE Trans. Software Eng. 43(1): 1-18 (2017)
- 59. Training Prior studies apply 3 families of 12 most commonly- used model validation techniques Testing 70% 30% Training Holdout Validation Testing k-1 folds k-Fold Cross Validation Repeat k times 1 fold Bootstrap Validation Training Testing bootstrap Repeat N times out-of-sample • 50% Holdout • 70% Holdout • Repeated 50% Holdout • Repeated 70% Holdout • Leave-one-out CV • 2 Fold CV • 10 Fold CV • Repeated 10 fold CV • Ordinary bootstrap • Optimism-reduced bootstrap • Out-of-sample bootstrap • .632 Bootstrap 39
- 60. Model validation techniques may produce different performance estimates AUC=0.73 Construct and evaluate the model using ordinary bootstrap Construct and evaluate the model using 50% holdout validation Defect Dataset AUC=0.58 40
- 61. Model validation techniques may produce different performance estimates It’s not clear which model validation techniques provide the most accurate performance estimates AUC=0.73 Construct and evaluate the model using ordinary bootstrap Construct and evaluate the model using 50% holdout validation Defect Dataset AUC=0.58 40
- 62. Examining the bias and variance of performance estimates that are produced by model validation techniques (MVTs) 41
- 63. Bias measures the difference between performance estimates and the ground-truth Examining the bias and variance of performance estimates that are produced by model validation techniques (MVTs) 41
- 64. Bias measures the difference between performance estimates and the ground-truth Variance measures the variation of performance estimates when an experiment is repeated Examining the bias and variance of performance estimates that are produced by model validation techniques (MVTs) 41
- 65. Bias measures the difference between performance estimates and the ground-truth Variance measures the variation of performance estimates when an experiment is repeated Examining the bias and variance of performance estimates that are produced by model validation techniques (MVTs) 42
- 66. Bias measures the difference between performance estimates and the ground-truth Variance measures the variation of performance estimates when an experiment is repeated Examining the bias and variance of performance estimates that are produced by model validation techniques (MVTs) 42 Defect Dataset Sample Dataset Unseen Dataset
- 67. V.S. Bias and variance calculation Bias Variance Bias measures the difference between performance estimates and the ground-truth Variance measures the variation of performance estimates when an experiment is repeated Examining the bias and variance of performance estimates that are produced by model validation techniques (MVTs) 43 Model Validation Techniques Defect Dataset Sample Dataset Unseen Dataset Training Testing Performance on unseen data (ground-truth) Analytics model Training Testing Analytics model Performance Estimates
- 68. ● ● ● ● Holdout 0.5 Holdout 0.7 2−Fold, 10−Fold CV Rep. 10−Fold CV Ordinary Optimism Outsample .632 Bootstrap Rep. Holdout 0.5, 0.7 1 1.5 2 2.5 3 11.522.53 Mean Ranks of Bias MeanRanksofVariance Family ● Bootstrap Cross Validation Holdout Bias and variance of performance estimates that are produced by MVTS are statistically different 44
- 69. ● ● ● ● Holdout 0.5 Holdout 0.7 2−Fold, 10−Fold CV Rep. 10−Fold CV Ordinary Optimism Outsample .632 Bootstrap Rep. Holdout 0.5, 0.7 1 1.5 2 2.5 3 11.522.53 Mean Ranks of Bias MeanRanksofVariance Family ● Bootstrap Cross Validation Holdout Single-repetition holdout family produces the least accurate and stable performance estimates 45
- 70. ● ● ● ● Holdout 0.5 Holdout 0.7 2−Fold, 10−Fold CV Rep. 10−Fold CV Ordinary Optimism Outsample .632 Bootstrap Rep. Holdout 0.5, 0.7 1 1.5 2 2.5 3 11.522.53 Mean Ranks of Bias MeanRanksofVariance Family ● Bootstrap Cross Validation Holdout Single-repetition holdout family produces the least accurate and stable performance estimates 45 produces the least accurate and stable performance estimates Single-repetition holdout validation
- 71. ● ● ● ● Holdout 0.5 Holdout 0.7 2−Fold, 10−Fold CV Rep. 10−Fold CV Ordinary Optimism Outsample .632 Bootstrap Rep. Holdout 0.5, 0.7 1 1.5 2 2.5 3 11.522.53 Mean Ranks of Bias MeanRanksofVariance Family ● Bootstrap Cross Validation Holdout Single-repetition holdout family produces the least accurate and stable performance estimates 45 produces the least accurate and stable performance estimates Single-repetition holdout validation produces the most accurate and stable performance estimates Out-of-sample bootstrap validation
- 72. ● ● ● ● Holdout 0.5 Holdout 0.7 2−Fold, 10−Fold CV Rep. 10−Fold CV Ordinary Optimism Outsample .632 Bootstrap Rep. Holdout 0.5, 0.7 1 1.5 2 2.5 3 11.522.53 Mean Ranks of Bias MeanRanksofVariance Family ● Bootstrap Cross Validation Holdout Single-repetition holdout family produces the least accurate and stable performance estimates 45 produces the least accurate and stable performance estimates Single-repetition holdout validation produces the most accurate and stable performance estimates Out-of-sample bootstrap validation Out-of-sample bootstrap should be used in future defect prediction studies
- 73. 46 Leveraging HPC Resources to Improve the Experimental Design of Software Analytics Noise in Defect Datasets (ICSE’15) Parameters Optimization (ICSE’16) Model Validation Techniques (TSE’17) Defect Labelling Classifier Parameters Validation Techniques 2 3 4 Experimental Factors Analysis (TSE’16) Experimental Factors 1 Experimental design matters more than who perform a research Researchers can rely on the accuracy of modules labelled as defective by analytics models that are trained using such noisy data Researchers should apply automated parameter optimization in order to improve the performance and reliability of software analytics Researchers should avoid using the single-repetition holdout validation and instead opt to use the out-of-sample bootstrap model validation technique
- 74. 47 Experimental design matters more than who perform a research!!!
- 75. Future Research Agenda of Software Analytics Research 48 (1:Education) Lack of modelling skills Practitioners often treat research toolkits as a blackboxIntegrate data science courses into computer science curriculum
- 76. Future Research Agenda of Software Analytics Research 48 (1:Education) Lack of modelling skills Practitioners often treat research toolkits as a blackboxIntegrate data science courses into computer science curriculum (2:Management) Using inappropriate techniques Practitioners often borrow techniques from other domains that may not work best with our domain Use experimental science to select the most appropriate technique
- 77. Future Research Agenda of Software Analytics Research 48 (1:Education) Lack of modelling skills Practitioners often treat research toolkits as a blackboxIntegrate data science courses into computer science curriculum (2:Management) Using inappropriate techniques Practitioners often borrow techniques from other domains that may not work best with our domain Use experimental science to select the most appropriate technique (3:Monitoring) Outdated training data and statistical models Practitioners rarely check if their training data and the model are up-to-date Leveraging HPC resources to develop real-time software analytics
- 78. 49
- 79. 49
- 80. 49
- 81. 49