Leveraging Open Source Automated Data Science Tools

The data science process seeks to transform and empower organizations by finding and exploiting market inefficiencies and potentially hidden opportunities, but this is often an expensive, tedious process. However, many steps can be automated to provide a streamlined experience for data scientists. Eduardo Arino de la Rubia explores the tools being created by the open source community to free data scientists from tedium, enabling them to work on the high-value aspects of insight creation and impact validation. The promise of the automated statistician is almost as old as statistics itself. From the creations of vast tables, which saved the labor of calculation, to modern tools which automatically mine datasets for correlations, there has been a considerable amount of advancement in this field. Eduardo compares and contrasts a number of open source tools, including TPOT and auto-sklearn for automated model generation and scikit-feature for feature generation and other aspects of the data science workflow, evaluates their results, and discusses their place in the modern data science workflow. Along the way, Eduardo outlines the pitfalls of automated data science and applications of the “no free lunch” theorem and dives into alternate approaches, such as end-to-end deep learning, which seek to leverage massive-scale computing and architectures to handle automatic generation of features and advanced models.






































































More Related Content
What's hot (20)
Similar to Leveraging Open Source Automated Data Science Tools (20)


















More from Domino Data Lab (20)




















Recently uploaded (20)




















Leveraging Open Source Automated Data Science Tools
- 1. LEVERAGING OPEN SOURCE E D U A R D O A R I Ñ O D E L A R U B I A C H I E F D A T A S C I E N T I S T , D O M I N O D A T A L A B E D U A R D O @ D O M I N O D A T A L A B . C O M T W I T T E R : @ E A R I N O A U T O M A T E D D A T A S C I E N C E T O O L S
- 2. CONTENTS Introduction 1 WELCOME TO MY DATA POPUP TALK Some background 2 Tools Available 3
- 3. A nice self-serving way to eat up at least a few minutes of this talk. INTRODUCTION
- 4. PICTURE SLIDE DATA SCIENTIST A BIT ABOUT ME
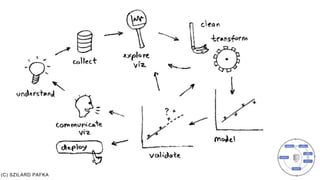
- 5. A QUICK TIMELINE Manufacturing & Logistics
- 8. Let’s discuss what is ML, what is data science, and make sure we’re all using the same words to mean the same things. SOME BACKGROUND
- 9. FIND A CATEGORY Detect defective, classify workloads, categorize vendors WHAT IS MACHINE LEARNING? FIND A NUMBER Predict yields, decide optimal run rates, predict tolerances FIND STRUCTURE Competitive intelligence, understand vendor processes, market segments KMEANS, KOHONEN SOM Field of study that gives computers the ability to learn without being explicitly programmed" GLM, RIDGE, ETC… KNN, NEURAL NET, ETC.
- 10. Biology is not the study of microscopes. Though they sure make biology a whole lot easier, they are a tool. ML plays a part in the data science process, but data science is not just applied ML. They make it a whole lot easier, it is a tool. ML IS NOT DATA SCIENCE SO WHAT CAN WE AUTOMATE?
- 16. So now that we’ve spent some time together, what are some good open source tools we can use? TOOLS AVAILABLE
- 17. ANGRY OLD MAN RANT Data Science tools are incredibly automated! We’re in a golden age of data science automation. It’s really not very long ago that in order to train a model you had to go out into some professor’s FTP server and figure out how to get some library to even compile. Here are some things we just take for granted that are now automated…
- 18. The original sample is randomly partitioned into k equal sized subsamples CROSS VALIDATION 1 Hyperparameter sweeps are something that you just simply had to code by hand GRID SEARCH 3 Scaling? Centering? Box cox? These were things that you had to do by hand, and doing them wrong was bad. PRE PROCESSING 2
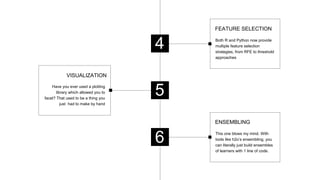
- 19. Have you ever used a plotting library which allowed you to facet? That used to be a thing you just had to make by hand VISUALIZATION 4 6 Both R and Python now provide multiple feature selection strategies, from RFE to threshold approaches FEATURE SELECTION 5 This one blows my mind. With tools like h2o’s ensembling, you can literally just build ensembles of learners with 1 line of code. ENSEMBLING
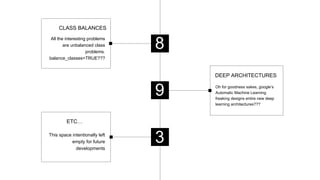
- 20. All the interesting problems are unbalanced class problems. balance_classes=TRUE??? CLASS BALANCES 8 This space intentionally left empty for future developments ETC… 3 Oh for goodness sakes, google’s Automatic Machine Learning freaking designs entire new deep learning architectures??? DEEP ARCHITECTURES 9
- 21. BUT DON’T FORGET HOW LUCKY WE ARE Between the massive hardware that is available to us, and the incredible libraries that have been created by the community, we’re infinitely more productive than we were just a few years ago. But we want even more automation… so let’s talk about some cool tools :) WE’RE SPOILED
- 22. AUTOMATED DATA SCIENCE IS HUNGRY FOR RESOURCES
- 23. FEATURE ENGINEERING Feature engineering is often considered the dark art of data science. Like when your differential equations professor told you that you should “stare at it” until it made sense.
- 24. scikit-feature is an open-source feature selection repository in Python developed by Data Mining and Machine Learning Lab at Ari zona State University. It is built upon one widely used machine learning package scikit-learn and two scientific computing packages Numpy and Scipy. scikit- feature contains around 40 popular feature selection algorithms, including traditional feature selection algorithms and some structural and streaming feature selection algorithms. SCIKIT FEATURE SO COOL RIGHT
- 25. SADLY IT SEEMS TO BE MOSTLY ABANDONED
- 26. HELPS MAKE THE SAUSAGE A 'data.frame' processor/conditioner that prepares real-world data for predictive modeling in a statistically sound manner. 'vtreat' prepares variables so that data has fewer exceptional cases, making it easier to safely use models in production. Common problems 'vtreat' defends against: 'Inf', 'NA', too many categorical levels, rare categorical levels, and new categorical levels (levels seen during application, but not during training). VTREAT
- 27. THERE’S A TON MORE SO MANY PROBLEMS… 1. Bad numerical values (NA, NaN, sentinels) 2. Categorial values (missing levels, novel levels in production) 3. Categorical values with too many levels 4. Weird skew Vtreat provides “y-aware” processing
- 28. Treatment of missing values through safe replacement plus indicator column (a simple but very powerful method when combined with downstream machine learning algorithms). 1 Explicit coding of categorical variable levels as new indicator variables (with optional suppression of non- significant indicators). 3 Treatment of novel levels (new values of categorical variable seen during test or application, but not seen during training) through sub-models (or impact/effects coding of pooled rare events). 2
- 29. User specified significance pruning on levels coded into effects/impact sub-models 4 6 Treatment of categorical variables with very large numbers of levels through sub-models 5 Collaring/Winsorizing of unexpected out of range numeric inputs (clipping)
- 31. WARNING Your data had better be pretty clean! These automated ML tools are amazing, but your data needs to be in pretty good shape. Nice, numerical, no weird missing values… So chain them together and use vtreat!
- 32. AND… auto-sklearn is an automated machine learning toolkit and a drop-in replacement for a scikit-learn estimator: auto-sklearn frees a machine learning user from algorithm selection and hyperparameter tuning. It leverages recent advantages in Bayesian optimization, meta-learning and ensemble construction. Learn more about the technology behind auto-sklearn by reading this paper published at the NIPS 2015 . AUTO-SKLEARN
- 33. AWARDS Of additional note, Auto-sklearn won both the auto and the tweakathon tracks of the ChaLearn AutoML challenge.
- 35. RANDAL OLSON TPOT will automate the most tedious part of machine learning by intelligently exploring thousands of possible pipelines to find the best one for your data. Once TPOT is finished searching (or you get tired of waiting), it provides you with the Python code for the best pipeline it found so you can tinker with the pipeline from there. TPOT CREATOR
- 36. Though both projects are open source, written in Python, and aimed at simplifying a machine learning process by way of AutoML , in contrast to Auto-sklearn using Bayesian optimization, TPOT's approach is based on genetic programming. One of the real benefits of TPOT is that it produces ready-to-run, standalone Python code for the best-performing model, in the form of a scikit- learn pipeline. This code, representing the best performing of all candidate models, can then be modified or inspected for ad ditional insight, effectively being able to serve as a starting point as opposed to solely as an end product. GENETIC PROGRAMMING - MATTHEW MAYO, KDNUGGETS.
- 39. COMING SOON? Supposedly is going to take advantage of a lot of the existing infrastructure in h2o, with ensembles in the back end, hyper parameter search, etc… VERY excited to see what happens next! AUTOML
- 40. COMING SOON? Supposedly is going to take advantage of a lot of the existing infrastructure in h2o, with ensembles in the back end, hyper parameter search, etc… VERY excited to see what happens next! AUTOML
- 42. The current version of AutoML trains and cross-validates a Random Forest, an Extremely-Randomized Forest, a random grid of Gradient Boosting Machines (GBMs), a random grid of Deep Neural Nets, and a Stacked Ensemble of all the models. http://tiny.cc/automl
- 44. THANK YOU R E A C H O U T A T E D U A R D O @ D O M I N O D A T A L A B . C O M @ E A R I N O F O R C O M I N G T O M Y T A L K W E A R E H I R I N G ! H T T P S : / / W W W . D O M I N O D A T A L A B . C O M / C A R E E R S /