





























































Ad
More Related Content
Similar to Linear regression: introduction and method (20)
More from ThomasWong104635 (6)




Ad
Recently uploaded (20)










![Adamson, Walter L. - Avant-Garde Florence. From Modernism to Fascism [ocr] [...](https://cdn.slidesharecdn.com/ss_thumbnails/adamsonwalterl-250506185430-7d64f4bb-thumbnail.jpg?width=560&fit=bounds)









Ad
Linear regression: introduction and method
- 1. 7/17/2017 http://numericalmethods.eng.usf.edu 1 Linear Regression Major: All Engineering Majors Authors: Autar Kaw, Luke Snyder http://numericalmethods.eng.usf.edu Transforming Numerical Methods Education for STEM Undergraduates
- 3. http://numericalmethods.eng.usf.edu 3 What is Regression? What is regression? Given n data points best fit ) (x f y = to the data. Residual at each point is ) (x f y = Figure. Basic model for regression ) , ( ),......, , ( ), , ( 2 2 1 1 n n y x y x y x ) ( i i i x f y E − = y x ) , ( 1 1 y x ) , ( n n y x ) , ( i i y x ) ( i i i x f y E − =
- 4. http://numericalmethods.eng.usf.edu 4 Linear Regression-Criterion#1 Given n data points best fit x a a y 1 0 + = to the data. Does minimizing∑ = n i i E 1 work as a criterion? x x a a y 1 0 + = ) , ( 1 1 y x ) , ( 2 2 y x ) , ( 3 3 y x ) , ( n n y x ) , ( i i y x i i i x a a y E 1 0 − − = y Figure. Linear regression of y vs x data showing residuals at a typical point, xi . ) , ( ),......, , ( ), , ( 2 2 1 1 n n y x y x y x
- 5. http://numericalmethods.eng.usf.edu 5 Example for Criterion#1 x y 2.0 4.0 3.0 6.0 2.0 6.0 3.0 8.0 Example: Given the data points (2,4), (3,6), (2,6) and (3,8), best fit the data to a straight line using Criterion#1 Figure. Data points for y vs x data. Table. Data Points 0 2 4 6 8 10 0 1 2 3 4 y x Minimize∑ = n i i E 1
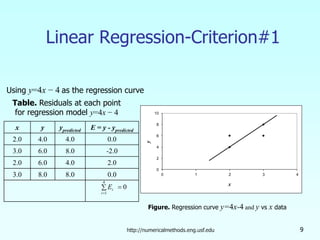
- 6. http://numericalmethods.eng.usf.edu 6 Linear Regression-Criteria#1 0 4 1 = ∑ = i i E x y ypredicted E = y - ypredicted 2.0 4.0 4.0 0.0 3.0 6.0 8.0 -2.0 2.0 6.0 4.0 2.0 3.0 8.0 8.0 0.0 Table. Residuals at each point for regression model y=4x − 4 Figure. Regression curve y=4x − 4 and y vs x data 0 2 4 6 8 10 0 1 2 3 4 y x Using y=4x − 4 as the regression curve
- 7. http://numericalmethods.eng.usf.edu 7 Linear Regression-Criterion#1 x y ypredicted E = y - ypredicted 2.0 4.0 6.0 -2.0 3.0 6.0 6.0 0.0 2.0 6.0 6.0 0.0 3.0 8.0 6.0 2.0 0 4 1 = ∑ = i i E 0 2 4 6 8 10 0 1 2 3 4 y x Table. Residuals at each point for regression model y=6 Figure. Regression curve y=6 and y vs x data Using y=6 as a regression curve
- 8. http://numericalmethods.eng.usf.edu 8 Linear Regression – Criterion #1 0 4 1 = ∑ = i i E for both regression models of y=4x-4 and y=6 The sum of the residuals is minimized, in this case it is zero, but the regression model is not unique. Hence the criterion of minimizing the sum of the residuals is a bad criterion. 0 2 4 6 8 10 0 1 2 3 4 y x
- 9. http://numericalmethods.eng.usf.edu 9 Linear Regression-Criterion#1 0 4 1 = ∑ = i i E x y ypredicted E = y - ypredicted 2.0 4.0 4.0 0.0 3.0 6.0 8.0 -2.0 2.0 6.0 4.0 2.0 3.0 8.0 8.0 0.0 Table. Residuals at each point for regression model y=4x − 4 Figure. Regression curve y=4x-4 and y vs x data 0 2 4 6 8 10 0 1 2 3 4 y x Using y=4x − 4 as the regression curve
- 10. http://numericalmethods.eng.usf.edu 10 Linear Regression-Criterion#2 x ) , ( 1 1 y x ) , ( 2 2 y x ) , ( 3 3 y x ) , ( n n y x ) , ( i i y x i i i x a a y E 1 0 − − = y Figure. Linear regression of y vs. x data showing residuals at a typical point, xi . Will minimizing | | 1 ∑ = n i i E work any better? x a a y 1 0 + =
- 11. http://numericalmethods.eng.usf.edu 11 Example for Criterion#2 x y 2.0 4.0 3.0 6.0 2.0 6.0 3.0 8.0 Example: Given the data points (2,4), (3,6), (2,6) and (3,8), best fit the data to a straight line using Criterion#2 Figure. Data points for y vs. x data. Table. Data Points 0 2 4 6 8 10 0 1 2 3 4 y x Minimize ∑ = n i i E 1 | |
- 12. http://numericalmethods.eng.usf.edu 12 Linear Regression-Criterion#2 4 | | 4 1 = ∑ = i i E x y ypredicted E = y - ypredicted 2.0 4.0 4.0 0.0 3.0 6.0 8.0 -2.0 2.0 6.0 4.0 2.0 3.0 8.0 8.0 0.0 Table. Residuals at each point for regression model y=4x − 4 Figure. Regression curve y= y=4x − 4 and y vs. x data 0 2 4 6 8 10 0 1 2 3 4 y x Using y=4x − 4 as the regression curve
- 13. http://numericalmethods.eng.usf.edu 13 Linear Regression-Criterion#2 x y ypredicted E = y - ypredicted 2.0 4.0 6.0 -2.0 3.0 6.0 6.0 0.0 2.0 6.0 6.0 0.0 3.0 8.0 6.0 2.0 4 | | 4 1 = ∑ = i i E 0 2 4 6 8 10 0 1 2 3 4 y x Table. Residuals at each point for regression model y=6 Figure. Regression curve y=6 and y vs x data Using y=6 as a regression curve
- 14. http://numericalmethods.eng.usf.edu 14 Linear Regression-Criterion#2 for both regression models of y=4x − 4 and y=6. The sum of the absolute residuals has been made as small as possible, that is 4, but the regression model is not unique. Hence the criterion of minimizing the sum of the absolute value of the residuals is also a bad criterion. 4 4 1 = ∑ = i i E
- 15. http://numericalmethods.eng.usf.edu 15 Least Squares Criterion The least squares criterion minimizes the sum of the square of the residuals in the model, and also produces a unique line. ( ) 2 1 1 0 1 2 ∑ − − = ∑ = = = n i i i n i i r x a a y E S x 1 1 , y x 2 2 , y x 3 3 , y x n n y x , i i y x , y Figure. Linear regression of y vs x data showing residuals at a typical point, xi . x a a y 1 0 + = i i i x a a y E 1 0 − − =
- 16. http://numericalmethods.eng.usf.edu 16 Finding Constants of Linear Model ( ) 2 1 1 0 1 2 ∑ − − = ∑ = = = n i i i n i i r x a a y E S Minimize the sum of the square of the residuals: To find ( )( ) 0 1 2 1 1 0 0 = − − − − = ∂ ∂ ∑ = n i i i r x a a y a S ( )( ) 0 2 1 1 0 1 = − − − − = ∂ ∂ ∑ = n i i i i r x x a a y a S giving i n i i i n i i n i x y x a x a ∑ ∑ ∑ = = = = + 1 2 1 1 1 0 0 a and 1 a we minimize with respect to 1 a 0 a and r S . ∑ ∑ ∑ = = = = + n i i i n i n i y x a a 1 1 1 1 0
- 17. http://numericalmethods.eng.usf.edu 17 Finding Constants of Linear Model 0 a Solving for 2 1 1 2 1 1 1 1 − − = ∑ ∑ ∑ ∑ ∑ = = = = = n i i n i i n i i n i i n i i i x x n y x y x n a and 2 1 1 2 1 1 1 1 2 0 − − = ∑ ∑ ∑ ∑ ∑ ∑ = = = = = = n i i n i i n i i i n i i n i i n i i x x n y x x y x a 1 a and directly yields, x a y a 1 0 − =
- 18. http://numericalmethods.eng.usf.edu 18 Example 1 The torque, T needed to turn the torsion spring of a mousetrap through an angle, is given below. Angle, θ Torque, T Radians N-m 0.698132 0.188224 0.959931 0.209138 1.134464 0.230052 1.570796 0.250965 1.919862 0.313707 Table: Torque vs Angle for a torsional spring Find the constants for the model given by θ 2 1 k k T + = Figure. Data points for Torque vs Angle data 0.1 0.2 0.3 0.4 0.5 1 1.5 2 θ (radians) Torque (N-m)
- 19. http://numericalmethods.eng.usf.edu 19 Example 1 cont. 1 a The following table shows the summations needed for the calculations of the constants in the regression model. θ 2 θ θ T Radians N-m Radians2 N-m-Radians 0.698132 0.188224 0.487388 0.131405 0.959931 0.209138 0.921468 0.200758 1.134464 0.230052 1.2870 0.260986 1.570796 0.250965 2.4674 0.394215 1.919862 0.313707 3.6859 0.602274 6.2831 1.1921 8.8491 1.5896 Table. Tabulation of data for calculation of important ∑ = = 5 1 i 5 = n Using equations described for 2 5 1 5 1 2 5 1 5 1 5 1 2 − − = ∑ ∑ ∑ ∑ ∑ = = = = = i i i i i i i i i i i n T T n k θ θ θ θ ( ) ( )( ) ( ) ( )2 2831 6 8491 8 5 1921 1 2831 6 5896 1 5 . . . . . − − = 2 10 6091 9 − × = . N-m/rad summations 0 a T and with
- 20. http://numericalmethods.eng.usf.edu 20 Example 1 cont. n T T i i ∑ = = 5 1 _ Use the average torque and average angle to calculate 1 k _ 2 _ 1 θ k T k − = n i i ∑ = = 5 1 _ θ θ 5 1921 . 1 = 1 10 3842 . 2 − × = 5 2831 . 6 = 2566 . 1 = Using, ) 2566 . 1 )( 10 6091 . 9 ( 10 3842 . 2 2 1 − − × − × = 1 10 1767 . 1 − × = N-m
- 21. http://numericalmethods.eng.usf.edu 21 Example 1 Results Figure. Linear regression of Torque versus Angle data Using linear regression, a trend line is found from the data Can you find the energy in the spring if it is twisted from 0 to 180 degrees?
- 22. http://numericalmethods.eng.usf.edu 22 Linear Regression (special case) Given best fit to the data. ) , ( , ... ), , ( ), , ( 2 2 1 1 n n y x y x y x x a y 1 =
- 23. http://numericalmethods.eng.usf.edu 23 Linear Regression (special case cont.) Is this correct? 2 1 1 2 1 1 1 1 − − = ∑ ∑ ∑ ∑ ∑ = = = = = n i i n i i n i i n i i n i i i x x n y x y x n a x a y 1 =
- 24. http://numericalmethods.eng.usf.edu 24 x 1 1 , y x i i x a x 1 , n n y x , i i y x , i i i x a y 1 − = ε y Linear Regression (special case cont.)
- 25. http://numericalmethods.eng.usf.edu 25 Linear Regression (special case cont.) i i i x a y 1 − = ε ∑ = = n i i r S 1 2 ε ( ) 2 1 1 ∑ = − = n i i i x a y Residual at each data point Sum of square of residuals
- 26. http://numericalmethods.eng.usf.edu 26 Linear Regression (special case cont.) Differentiate with respect to gives ( )( ) ∑ = − − = n i i i i r x x a y da dS 1 1 1 2 ( ) ∑ = + − = n i i i i x a x y 1 2 1 2 2 0 1 = da dSr ∑ ∑ = = = n i i n i i i x y x a 1 2 1 1 1 a
- 27. http://numericalmethods.eng.usf.edu 27 Linear Regression (special case cont.) ∑ ∑ = = = n i i n i i i x y x a 1 2 1 1 ( ) ∑ = + − = n i i i i r x a x y da dS 1 2 1 1 2 2 0 2 1 2 2 1 2 > = ∑ = n i i r x da S d ∑ ∑ = = = n i i n i i i x y x a 1 2 1 1 Does this value of a1 correspond to a local minima or local maxima? Yes, it corresponds to a local minima.
- 28. http://numericalmethods.eng.usf.edu 28 Linear Regression (special case cont.) Is this local minima of an absolute minimum of ? r S r S 1 a r S
- 29. http://numericalmethods.eng.usf.edu 29 Example 2 Strain Stress (%) (MPa) 0 0 0.183 306 0.36 612 0.5324 917 0.702 1223 0.867 1529 1.0244 1835 1.1774 2140 1.329 2446 1.479 2752 1.5 2767 1.56 2896 To find the longitudinal modulus of composite, the following data is collected. Find the longitudinal modulus, Table. Stress vs. Strain data E using the regression model ε σ E = and the sum of the square of the 0.0E+00 1.0E+09 2.0E+09 3.0E+09 0 0.005 0.01 0.015 0.02 Strain, ε (m/m) Stress, σ (Pa) residuals. Figure. Data points for Stress vs. Strain data
- 30. http://numericalmethods.eng.usf.edu 30 Example 2 cont. i ε σ ε 2 εσ 1 0.0000 0.0000 0.0000 0.0000 2 1.8300×10−3 3.0600×108 3.3489×10−6 5.5998×105 3 3.6000×10−3 6.1200×108 1.2960×10−5 2.2032×106 4 5.3240×10−3 9.1700×108 2.8345×10−5 4.8821×106 5 7.0200×10−3 1.2230×109 4.9280×10−5 8.5855×106 6 8.6700×10−3 1.5290×109 7.5169×10−5 1.3256×107 7 1.0244×10−2 1.8350×109 1.0494×10−4 1.8798×107 8 1.1774×10−2 2.1400×109 1.3863×10−4 2.5196×107 9 1.3290×10−2 2.4460×109 1.7662×10−4 3.2507×107 10 1.4790×10−2 2.7520×109 2.1874×10−4 4.0702×107 11 1.5000×10−2 2.7670×109 2.2500×10−4 4.1505×107 12 1.5600×10−2 2.8960×109 2.4336×10−4 4.5178×107 1.2764×10−3 2.3337×108 Table. Summation data for regression model ∑ = 12 1 i ∑ = − × = 12 1 3 2 10 2764 . 1 i i ε ∑ = × = 12 1 8 10 3337 . 2 i i iε σ ∑ ∑ = = = 12 1 2 12 1 i i i i i E ε ε σ 3 8 10 2764 . 1 10 3337 . 2 − × × = GPa 84 . 182 = ∑ ∑ = = = n i i n i i i E 1 2 1 ε ε σ
- 31. http://numericalmethods.eng.usf.edu 31 Example 2 Results ε σ 9 10 84 . 182 × = The equation Figure. Linear regression for stress vs. strain data describes the data.
- 32. Additional Resources For all resources on this topic such as digital audiovisual lectures, primers, textbook chapters, multiple-choice tests, worksheets in MATLAB, MATHEMATICA, MathCad and MAPLE, blogs, related physical problems, please visit http://numericalmethods.eng.usf.edu/topics/linear_regr ession.html