



































Linux kernel development chapter 10
- 1. Linux Kernel Development Ch9. An Introduction to Kernel Synchronization Hewitt
- 2. • Shared resources require protection from concurrent access because if multiple threads of execution access and manipulate the data at the same time, the threads may overwrite each other’s changes or access data while it is in an inconsistent state. • What makes synchronization so complicated? – Linux 2.0 - Symmetrical multiprocessing. – Linux 2.6 - Kernel preemption.
- 3. Critical Regions and Race Conditions • Critical regions (Critical sections) - code paths that access and manipulate shared data. • Atomic operations - complete without interruption as if the entire critical region were one indivisible instruction. • Race condition - two threads of execution to be simultaneously executing within the same critical region. • Synchronization - ensuring that unsafe concurrency is prevented and that race conditions do not occur.
- 4. Why Do We Need Protection? • ATM • The Single Variable, i++ – atomic instruction
- 5. Locking • A mechanism for preventing access to a resource while another thread of execution is in the marked region. • It works much like a lock on a door. • The most significant difference between the various mechanisms is the behavior when the lock is unavailable because another thread already holds it – busy wait or sleep. • Locks are implemented using atomic operations that ensure no race exists.
- 6. • Causes of Concurrency – Pseudo concurrency - Two things do not actually happen at the same time but interleave with each other, which may be caused by preemption or signal. – True concurrency - A symmetrical multiprocessing machine, two processes can actually be executed in a critical region at the exact same time.
- 7. – Interrupts - An interrupt can occur asynchronously at almost any time, interrupting the currently executing code. – Softirqs and tasklets - The kernel can raise or schedule a softirq or tasklet at almost any time, interrupting the currently executing code. – Kernel preemption - Because the kernel is preemptive, one task in the kernel can preempt another. – Sleeping and synchronization with user-space - A task in the kernel can sleep and thus invoke the scheduler, resulting in the running of a new process. – Symmetrical multiprocessing - Two or more processors can execute kernel code at exactly the same time.
- 8. • Knowing What to Protect – Most global kernel data structures do. A good rule of thumb is that if another thread of execution can access the data, the data needs some sort of locking; if anyone else can see it, lock it. – Remember to lock data, not code. – Provide appropriate protection for the most pessimistic case, SMP with kernel preemption, and all scenarios will be covered.
- 9. Deadlocks • Each thread waits for resources of others results in never make any progress. • Simple rules of using lock – Implement lock ordering. Nested locks must always be obtained in the same order. – Prevent starvation. – Do not double acquire the same lock. – Design for simplicity. Complexity in your locking scheme invites deadlocks.
- 10. Contention and Scalability • Consider a linked list – Lock for the entire list – Lock for each node – Lock for each element in each node • Locking that is too coarse results in poor scalability if there is high lock contention, whereas locking that is too fine results in wasteful overhead if there is little lock contention. • Start simple and grow in complexity only as needed. Simplicity is key.
- 11. Conclusion • Making your code SMP-safe is not something that can be added as an afterthought. • Proper synchronization - locking that is free of deadlocks, scalable, and clean - requires design decisions from start through finish.
- 12. Linux Kernel Development Ch10. Kernel Synchronization Methods Hewitt
- 13. Atomic Operations • Provide instructions that execute atomically - without interruption. • The foundation on which other synchronization methods are built. • Some architectures, lacking direct atomic operations, provide an operation to lock the memory bus for a single operation, thus guaranteeing that another memory- affecting operation cannot occur simultaneously.
- 14. • Atomic Integer Operations – the atomic integer methods operate on a special data type, atomic_t. – the data types are not passed to any nonatomic functions. – the compiler does not (erroneously but cleverly) optimize access to the value. – it can hide any architecture-specific differences in its implementation.
- 16. • 64-Bit Atomic Operations – Functions are prefixed with atomic64 in lieu of atomic. – For portability between all Linux’s supported architectures, developers should use the 32-bit atomic_t type. The 64-bit atomic64_t is reserved for code that is both architecture-specific and that requires 64-bits.
- 17. • Atomic Bitwise Operations – The nonatomic functions are prefixed by double underscores. – Real atomicity requires that all intermediate states be correctly realized.
- 18. Spin Locks • If a thread of execution attempts to acquire a spin lock while it is already held, which is called contended, the thread busy loops – spins - waiting for the lock to become available. If the lock is not contended, the thread can immediately acquire the lock and continue. • The spinning prevents more than one thread of execution from entering the critical region. • It is wise to hold spin locks for less than the duration of two context switches.
- 19. • Spin Lock Methods – Linux kernel’s spin locks are not recursive. – Spin locks can be used in interrupt handlers, whereas semaphores cannot be used because they sleep. – If a lock is used in an interrupt handler, you must also disable local interrupts (interrupt requests on the current processor) before obtaining the lock. disable kernel preemption & disable interrupts disable kernel preemption not recommended
- 21. • Spin Locks and Bottom Halves – Because a bottom half might preempt process context code, if data is shared between a bottom-half process context, you must protect the data in process context with both a lock and then disabling of bottom halves. – two tasklets of the same type do not ever run simultaneously. Thus, there is no need to protect data used only within a single type of tasklet. – …
- 22. Reader-Writer Spin Locks • One or more readers can concurrently hold the reader lock. The writer lock, conversely, can be held by at most one writer with no concurrent readers. • Linux reader-writer spin locks is that they favor readers over writers.
- 24. Semaphore • It’s sleeping locks in Linux. • When a task attempts to acquire a semaphore that is unavailable, the semaphore places the task onto a wait queue and puts the task to sleep. The processor is then free to execute other code. • Unlike spin locks, semaphores do not disable kernel preemption and, consequently, code holding a semaphore can be preempted. This means semaphores do not adversely affect scheduling latency.
- 25. • Counting and Binary Semaphores – Counting semaphore - the number of permissible simultaneous holders of semaphores can be set at declaration time. This value is called the usage count or simply the count. – Binary semaphore – one lock holder at a time. Also called as mutex, because it enforces mutual exclusion. – A semaphore supports two atomic operations, P() and V(). Later systems called these methods down() and up(), respectively, and so does Linux. – Counting semaphores are not used to enforce mutual exclusion. It enforces limits in certain code.
- 27. Reader-Writer Semaphores • All reader-writer semaphores are mutexes - that is, their usage count is one - although they enforce mutual exclusion only for writers, not readers. • Reader-writer semaphores have a unique method that their reader-writer spin lock cousins do not have: downgrade_write().This function atomically converts an acquired write lock to a read lock. • It is worthwhile using only if your code naturally splits along a reader/writer boundary.
- 28. Mutexes • It behaves similar to a semaphore with a count of one, but it has a simpler interface, more efficient performance, and additional constraints on its use. – Only one task can hold the mutex at a time. That is, the usage count on a mutex is always one. – Whoever locked a mutex must unlock. – Recursive locks and unlocks are not allowed. That is, you cannot recursively acquire the same mutex, and you cannot unlock an unlocked mutex. – A process cannot exit while holding a mutex. – A mutex cannot be acquired by an interrupt handler or bottom half, even with mutex_trylock(). – A mutex can be managed only via the official API: It must be initialized via the methods described in this section and cannot be copied, hand initialized, or reinitialized.
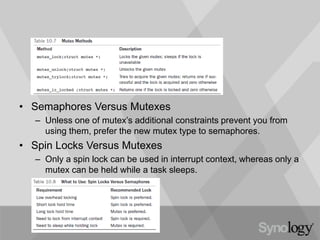
- 29. • Semaphores Versus Mutexes – Unless one of mutex’s additional constraints prevent you from using them, prefer the new mutex type to semaphores. • Spin Locks Versus Mutexes – Only a spin lock can be used in interrupt context, whereas only a mutex can be held while a task sleeps.
- 30. Completion Variables • It’s an easy way to synchronize between two tasks in the kernel when one task needs to signal to the other that an event has occurred.
- 31. BKL: The Big Kernel Lock • A global spin lock that was created to ease the transition from Linux’s original SMP implementation to fine-grained locking. • BKL properties: – Sleep is allowed while holding the BKL. The lock is automatically dropped when the task is unscheduled and reacquired when the task is rescheduled. – The BKL is a recursive lock. – BKL only can be used in process context. – New users of the BKL are forbidden.
- 32. Sequential Locks • It’s generally shortened to seq lock, is a newer type of lock introduced in the 2.6 kernel. • It works by maintaining a sequence counter. – Whenever the data in question is written to, a lock is obtained and a sequence number is incremented. Prior to and after reading the data, the sequence number is read. If the values are the same, a write did not begin in the middle of the read. Further, if the values are even, a write is not underway. • Seq locks are useful to provide a lightweight and scalable lock for use with many readers and a few writers. Seq locks, however, favor writers over readers.
- 33. • A prominent user of the seq lock is jiffies, the variable that stores a Linux machine’s uptime.
- 34. Preemption Disabling • Because the kernel is preemptive, a process in the kernel can stop running at any instant to enable a process of higher priority to run. • The kernel preemption code uses spin locks as markers of nonpreemptive regions. • Per-processor data may not require a spin lock, but do need kernel preemption disabled.
- 35. • A cleaner solution to per-processor data issues.
- 36. Ordering and Barriers • When dealing with synchronization between multiple processors or with hardware devices, it is sometimes a requirement that memory-reads (loads) and memory- writes (stores) issue in the order specified in your program code. • All processors that do reorder reads or writes provide machine instructions to enforce ordering requirements. • It is also possible to instruct the compiler not to reorder instructions around a given point. These instructions are called barriers.
- 37. • Barrier functions ensure no load/store are reordered across it.