

















































































Ad
More Related Content
What's hot (20)
Similar to lispmeetup#63 Common Lispでゼロから作るDeep Learning (20)


















Ad
More from Satoshi imai (9)









Ad
lispmeetup#63 Common Lispでゼロから作るDeep Learning
- 1. Common Lispで ゼロから作るDeep Learning Satoshi Imai Twitter: @masatoi0 Github: masatoi Blog: masatoi.github.io
- 3. 「ゼロから作るDeep Learning」 ● 売れてる。分かりやすい。Pythonコードがついている ● これをCommon Lispで実装しなおすことでCLの数値計算ライ ブラリへの理解が深まるはず! ● CLにはMGLというディープラーニングライブラリがあるが、更 新が止まっている – 内部構造も自分には分かりづらかったのでシンプルな実装を作りたい – → 新しいDNNのアルゴリズムを実験する際の叩き台にできる
- 4. 「ゼロから作るDeep Learning」 ● 実験用プロジェクト:cl-zerodl – https://github.com/masatoi/cl-zerodl – 依存ライブラリはほぼMGL-MATのみ
- 5. Common Lispの行列演算ライブラリ ● LLA (Lisp Linear Algebra) – 外部の行列演算ライブラリのラッパー ● OpenBLASやIntel MKLが使える ● MGL-MAT – cl-cudaを利用してCUDAに対応する(GPUはなくてもよい) – 内部でLLAを使う – Common Lispの配列と外部の配列オブジェクトの変換を最小限に
- 6. LLAのインストール ● 数値計算ライブラリをインストールしておく – Ubuntuなら sudo apt install libopenblas-dev ● ~/.sbclrcなどにライブラリへのパスを書いておく ● Quicklispで読み込む (defvar *lla-configuration* '(:libraries ("/usr/lib/openblas-base/libblas.so.3"))) (ql:quickload :lla)
- 8. MGL-MATによる行列演算の特徴 ● APIはBLASそのままに近い – プリミティブな操作しかないが、組み合わせれば大抵のこと はできる ● 破壊的操作を多用する – 行列演算の結果を受け取る行列を常に用意する – 煩雑になりがち(デメリット) – 最初に確保した領域で処理が完結する。速い
- 9. MGL-MAT(1)行列オブジェクトの生成 ● 行列オブジェクトを作るにはmake-matを使う – 呼び出し方はmake-arrayと似ている – 数値のデフォルト型は*default-mat-ctype*で指定できる ● 特にGPU計算ではsingle-floatの方が速くなる – 個々の要素にはmrefでアクセスできるが遅い ● できるだけ用意されたAPIを使ってまとめて処理する
- 10. (ql:quickload :mgl-mat) (defpackage mgl-mat-scratch (:use :cl :mgl-mat)) (in-package :mgl-mat-scratch) ;; :floatか:doubleで指定する (setf *default-mat-ctype* :float) (setf *print-length* 100) ;; make-arrayに似た引数でつくれる (defparameter m1 (make-mat '(2 2) :initial-contents '((1 2) (3 4)))) (defparameter m2 (make-mat '(2 2) :initial-contents '((5 6) (7 8)))) (defparameter m3 (make-mat '(2 2) :initial-element 0)) (mat-dimensions m1) ; => (2 2) (mref m1 0 0) ; => 1.0
- 11. MGL-MAT(2)行列同士の演算 ● 行列の足し算 axpy! – αX + Y → Y ● 行列積 gemm! – αAB + βC → C ● 要素ごとの積 geem! – αAB + βC → C (axpy! alpha X Y) (gemm! alpha A B beta C) (geem! alpha A B beta C)
- 12. m1 ;; => #<MAT 2x2 AB #2A((1.0 2.0) (3.0 4.0))> m2 ;; => #<MAT 2x2 B #2A((5.0 6.0) (7.0 8.0))> m3 ;; => #<MAT 2x2 - #2A((0.0 0.0) (0.0 0.0))> (axpy! 1.0 m1 m3) ;; => #<MAT 2x2 F #2A((1.0 2.0) (3.0 4.0))> (gemm! 1.0 m1 m2 0.0 m3) ;; => #<MAT 2x2 AF #2A((19.0 22.0) (43.0 50.0))> (geem! 1.0 m1 m2 0.0 m3) ;; => #<MAT 2x2 ABF #2A((5.0 12.0) (21.0 32.0))>
- 13. MGL-MAT(3)行列の操作 ● 行列のコピー(破壊的代入)copy! – 例)axpy!でAもBも破壊したくないとき ● αA + B → C ● 行列をスカラーで埋める fill! ● αE → X ● 行列を一様乱数で埋める uniform-random! ● 行列を正規乱数で埋める gaussian-random! (copy! B C) (axpy! alpha A C) (fill! alpha X)
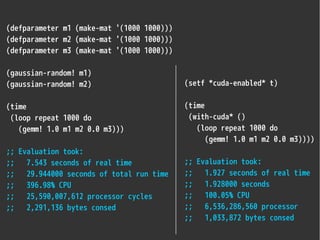
- 14. (defparameter m1 (make-mat '(1000 1000))) (defparameter m2 (make-mat '(1000 1000))) (defparameter m3 (make-mat '(1000 1000))) (gaussian-random! m1) (gaussian-random! m2) (time (loop repeat 1000 do (gemm! 1.0 m1 m2 0.0 m3))) ;; Evaluation took: ;; 7.543 seconds of real time ;; 29.944000 seconds of total run time ;; 396.98% CPU ;; 25,590,007,612 processor cycles ;; 2,291,136 bytes consed (setf *cuda-enabled* t) (time (with-cuda* () (loop repeat 1000 do (gemm! 1.0 m1 m2 0.0 m3)))) ;; Evaluation took: ;; 1.927 seconds of real time ;; 1.928000 seconds ;; 100.05% CPU ;; 6,536,286,560 processor ;; 1,033,872 bytes consed
- 15. MGL-MAT(4)その他の行列の操作 ● 1引数の破壊的操作 – .square! .sqrt! .log! .exp! .inv!(逆数) ● 比較を行う破壊的操作 .max! .<! (defparameter m4 (make-mat '(2 2) :initial-contents '((1 -2) (-3 4)))) (defparameter zero (make-mat '(2 2) :initial-element 0)) (.<! zero m4) ; => #<MAT 2x2 AB #2A((1.0 0.0) (0.0 1.0))> (defparameter m4 (make-mat '(2 2) :initial-contents '((1 -2) (-3 4)))) (.max! 0 m4) ; => #<MAT 2x2 AB #2A((1.0 0.0) (0.0 4.0))>
- 16. MGL-MAT(5)行列の軸ごとの和、伸長 ● 軸ごとの和 sum! ● 軸ごとの伸長 scale-rows! scale-columns! (defparameter m1 (make-mat '(2 2) :initial-contents '((1 2) (3 4)))) (defparameter v1 (make-mat 2)) (sum! m1 v1 :axis 0) ; => #<MAT 2 AF #(4.0 6.0)> (sum! m1 v1 :axis 1) ; => #<MAT 2 AF #(3.0 7.0)> ;; 1.0で埋めてからv1を列方向/行方向に掛ける (defparameter m2 (make-mat '(2 2) :initial-element 1)) (scale-rows! v1 m2) ; => #<MAT 2x2 B #2A((3.0 3.0) (7.0 7.0))> (fill! 1.0 m2) (scale-columns! v1 m2) ; => #<MAT 2x2 AB #2A((3.0 7.0) (3.0 7.0))>
- 17. MGL-MAT(6)行列のreshape/displace ● 行列中の連続した部分領域を新たな自身の形状にする reshape-and-displace! (参照を変えているだけなので高速) (defparameter m (make-mat '(3 3) :initial-contents '((1 2 3) (4 5 6) (7 8 9)))) (reshape-and-displace! m '(1 3) 0) ; => #<MAT 0+1x3+6 B #2A((1.0 2.0 3.0))> (reshape-and-displace! m '(2 3) 3) ; => #<MAT 3+2x3+0 AB #2A((4.0 5.0 6.0) (7.0 8.0 9.0))> (reshape-and-displace! m 9 0) ; => #<MAT 9 AB #(1.0 2.0 3.0 4.0 5.0 6.0 7.0 8.0 9.0)> 新しい形状 先頭からの差分
- 18. このスライドの流れ ● 動機 ● 数値計算ライブラリの使い方について ● ニューラルネットの全体像 ● 計算グラフによる順伝搬と逆伝搬 ● 学習に関するテクニック ● ベンチマーク ● まとめ
- 19. ニューラルネットの全体像 relu affine relu softmax loss affine affineinput ● アフィン変換(線形変換してバイアスを足す変換)を行うレイ ヤ。重み行列の形状によって出力次元が変わる ● 活性化関数のレイヤ。ReLUやSigmoidなどの非線形関数をかませ る ● 出力層。分類問題の場合Softmax関数でクラス所属確率を出し、 クロスエントロピー関数で教師データとの誤差を計算する
- 21. ニューラルネットの全体像 relu affine relu softmax loss affine affine ソフトマックス関数 クロスエントロピー関数 x E
- 22. レイヤの実装 ● レイヤは入出力次元と、順伝搬/逆伝搬の結果を持つ ● 順伝搬のメソッドforwardと逆伝搬のメソッドbackwardを持つ ● 学習可能なレイヤはパラメータ行列とその勾配への参照を持つ (define-class layer () input-dimensions output-dimensions forward-out backward-out) (defgeneric forward (layer &rest inputs)) (defgeneric backward (layer dout)) (define-class updatable-layer (layer) updatable-parameters gradients)
- 23. affineレイヤの実装 ● affineレイヤはupdatable-layerであり、順伝搬時の入力 と重みとバイアスを持つ ● 各スロットにMGL-MATの行列を持たせるコンストラクタ make-affine-layerを定義しておく (define-class affine-layer (updatable-layer) x weight bias) (make-affine-layer input-dimensions output-dimensions)
- 24. affineレイヤの順伝搬計算 (defmethod forward ((layer affine-layer) &rest inputs) (let* ((x (car inputs)) (W (weight layer)) (b (bias layer)) (out (forward-out layer))) (copy! x (x layer)) (fill! 1.0 out) (scale-columns! b out) (gemm! 1.0 x W 1.0 out)))
- 25. affineレイヤの逆伝搬計算 (defmethod backward ((layer affine-layer) dout) (bind (((dx dW db) (backward-out layer))) (gemm! 1.0 dout (weight layer) 0.0 dx :transpose-b? t) ; dx (gemm! 1.0 (x layer) dout 0.0 dW :transpose-a? t) ; dW (sum! dout db :axis 0) ; db (backward-out layer)))
- 26. ReLUレイヤの実装 ● reluレイヤは学習パラメータは持たないが、入力が0を超 えているかどうか調べるマスク行列を持つ ● コンストラクタ (define-class relu-layer (layer) zero mask) (defun make-relu-layer (input-dimensions) (make-instance 'relu-layer :input-dimensions input-dimensions :output-dimensions input-dimensions :forward-out (make-mat input-dimensions) :backward-out (make-mat input-dimensions) :zero (make-mat input-dimensions :initial-element 0.0) :mask (make-mat input-dimensions :initial-element 0.0)))
- 27. affineレイヤの順伝搬計算 (defmethod forward ((layer relu-layer) &rest inputs) (let ((zero (zero layer)) (mask (mask layer)) (out (forward-out layer))) ;; set mask (copy! (car inputs) mask) (.<! zero mask) ;; set output (copy! (car inputs) out) (.max! 0.0 out)))
- 28. affineレイヤの逆伝搬計算 (defmethod backward ((layer relu-layer) dout) (geem! 1.0 dout (mask layer) 0.0 (backward-out layer)))
- 30. Softmax関数の実装 (defun average! (a batch-size-tmp &key (axis 0)) (sum! a batch-size-tmp :axis axis) (scal! (/ 1.0 (mat-dimension a axis)) batch-size-tmp)) (defun softmax! (a result batch-size-tmp &key (avoid-overflow-p t)) ;; In order to avoid overflow, subtract average value for each column. (when avoid-overflow-p (average! a batch-size-tmp :axis 1) (fill! 1.0 result) (scale-rows! batch-size-tmp result) (axpy! -1.0 result a)) ; a - average(a) (.exp! a) (sum! a batch-size-tmp :axis 1) (fill! 1.0 result) (scale-rows! batch-size-tmp result) (.inv! result) (.*! a result))
- 31. クロスエントロピー関数の実装 ● ネットワークの出力 y と教師データ t を比較してその誤 差を損失関数にする(Nはバッチサイズ) (defun cross-entropy! (y target tmp batch-size-tmp &key (delta 1e-7)) (let ((batch-size (mat-dimension target 0))) (copy! y tmp) (.+! delta tmp) (.log! tmp) (.*! target tmp) (sum! tmp batch-size-tmp :axis 1) (/ (asum batch-size-tmp) batch-size)))
- 33. Softmax/lossレイヤの実装 ● 逆伝搬が単純な形になるようにSotfmax関数とクロスエ ントロピー関数を選んだ ● 順伝搬時のSoftmax関数の値を保存しておく必要がある (define-class softmax/loss-layer (layer) y target batch-size-tmp)
- 34. Softmax/lossレイヤの順伝搬計算 (defmethod forward ((layer softmax/loss-layer) &rest inputs) (bind (((x target) inputs) (tmp (target layer)) ; use (target layer) as tmp (y (y layer)) (batch-size-tmp (batch-size-tmp layer))) (copy! x tmp) (softmax! tmp y batch-size-tmp) (let ((out (cross-entropy! y target tmp batch-size-tmp))) (copy! target (target layer)) (setf (forward-out layer) out) out)))
- 35. Softmax/lossレイヤの逆伝搬計算 (defmethod backward ((layer softmax/loss-layer) dout) (let* ((target (target layer)) (y (y layer)) (out (backward-out layer)) (batch-size (mat-dimension target 0))) (copy! y out) (axpy! -1.0 target out) (scal! (/ 1.0 batch-size) out)))
- 36. networkクラスの実装 ● ネットワークはレイヤのベクタを持つ ● 予測は入力側から順に各レイヤでforwardを実行 (define-class network () layers batch-size initializer optimizer) (defun predict (network x) (let* ((layers (layers network)) (len (length layers))) (loop for i from 0 below (1- len) do (setf x (forward (aref layers i) x))) x)) (defun loss (network x target) (let ((y (predict network x))) (forward (last-layer network) y target)))
- 37. ネットワークに対する逆伝搬の計算 ● ネットワークの各レイヤに対してforwardとbackwardを実行 ● 各レイヤのbackward-outスロットに逆伝搬の結果が入る (defmethod set-gradient! ((network network) x target) (let ((layers (layers network)) dout) ;; forward (loss network x target) ;; backward (setf dout (backward (last-layer network) 1.0)) (loop for i from (- (length layers) 2) downto 0 do (let ((layer (svref layers i))) (setf dout (backward layer (if (listp dout) (car dout) dout)))))))
- 38. optimizerクラスの実装 ● 逆伝搬が計算できたらパラメータ更新のためのoptimizerクラスを 定義する ● 最も単純な更新手法は確率的勾配降下法(SGD) – 勾配に学習率をかけてパラメータから引くだけ (define-class optimizer ()) (define-class sgd (optimizer) (learning-rate 0.1)) (defmethod update! ((optimizer sgd) parameter gradient) (axpy! (- (learning-rate optimizer)) gradient parameter))
- 39. 学習部分の実装 ● network中のupdatable-layerに対して操作をするマクロdo- updatable-layerを定義しておく (defun update-network! (network) (do-updatable-layer (layer network) (mapc (lambda (param grad) (update! (optimizer network) param grad)) (updatable-parameters layer) (gradients layer)))) (defun train (network x target) (set-gradient! network x target) (update-network! network))
- 40. ミニバッチの設定 ● 訓練データ/テストデータは(データ数×特徴次元数)の行列 ● データ行列の一部分をreshape-and-displace!でミニバッチにする ;;; Set/Reset mini-batch (defun set-mini-batch! (dataset start-row-index batch-size) (let ((dim (mat-dimension dataset 1))) (reshape-and-displace! dataset (list batch-size dim) (* start-row-index dim)))) (defun reset-shape! (dataset) (let* ((dim (mat-dimension dataset 1)) (len (/ (mat-max-size dataset) dim))) (reshape-and-displace! dataset (list len dim) 0)))
- 41. 具体例:MNISTに対する学習 (defparameter mnist-network (make-network '((affine :in 784 :out 256) (relu :in 256) (affine :in 256 :out 256) (relu :in 256) (affine :in 256 :out 10) (softmax :in 10)) :batch-size 100 :initializer (make-instance 'he-initializer))) (loop repeat (* 600 15) do (let* ((batch-size (batch-size mnist-network)) (rand (random (- 60000 batch-size)))) (set-mini-batch! mnist-dataset rand batch-size) (set-mini-batch! mnist-target rand batch-size) (train mnist-network mnist-dataset mnist-target)))
- 42. 具体例:MNISTに対する学習
- 43. 具体例:MNISTに対する学習 ● ベンチマーク:「ゼロから作るDeep Learning」の公式のPythonコードと比較 – 破壊的に行列を更新しているので領域の確保と開放のコストがない分速い – いちおうNumpyにもin-placeな行列の更新方法があるのでそれで比較した ら分からない
- 45. ● その他に実装したもの – 各種オプティマイザ ● Momentum SGD、Aggregated Momentum SGD ● Adagrad ● Adam – 各種イニシャライザ (Xavier、He) – Batch Normalization – Dropout ● 実装中のもの – 畳み込みニューラルネットワーク
- 46. Batch Normalization ● affineレイヤの出力をミニバッチ単位で正規化する(平均で引いて 標準偏差で割る) ● 勾配が均されてパラメータ全体がまんべんなく更新されるように なる → 収束高速化、過学習を抑制して汎化性能向上 relu affine relu softmax loss affine affineinput BN BN
- 48. (define-class batch-normalization-layer (updatable-layer) epsilon beta gamma var sqrtvar ivar x^ xmu tmp)
- 49. (defmethod forward ((layer batch-normalization-layer) &rest inputs) (let ((x (car inputs)) (epsilon (epsilon layer)) (beta (beta layer)) (gamma (gamma layer)) (var (var layer)) (sqrtvar (sqrtvar layer)) (ivar (ivar layer)) (x^ (x^ layer)) (xmu (xmu layer)) (tmp (tmp layer)) (out (forward-out layer))) (average! x (ivar layer)) ; use ivar as tmp ;; calc xmu (fill! 1.0 xmu) (scale-columns! ivar xmu) (axpy! -1.0 x xmu) (scal! -1.0 xmu) ;; calc var (copy! xmu x^) ; use x^ as tmp (.square! x^) (average! x^ var) ;; calc sqrtvar (copy! var sqrtvar) (.+! epsilon sqrtvar) (.sqrt! sqrtvar) ;; calc ivar (copy! sqrtvar ivar) (.inv! ivar) ;; calc x^ (fill! 1.0 x^) (scale-columns! ivar x^) (.*! xmu x^) ;; calc output (fill! 1.0 tmp) (scale-columns! gamma tmp) (.*! x^ tmp) (fill! 1.0 out) (scale-columns! beta out) (axpy! 1.0 tmp out)))
- 51. (defmethod backward ((layer batch-normalization-layer) dout) (bind (((dx dbeta dgamma) (backward-out layer)) (epsilon (epsilon layer)) (gamma (gamma layer)) (var (var layer)) (sqrtvar (sqrtvar layer)) (ivar (ivar layer)) (x^ (x^ layer)) (xmu (xmu layer)) (tmp (tmp layer))) ;; calc dx^ -> tmp (fill! 1.0 tmp) (scale-columns! gamma tmp) (.*! dout tmp) ;; calc dxmu1 -> dx (fill! 1.0 dx) (scale-columns! ivar dx) (.*! tmp dx) ;; calc divar -> dbeta (.*! xmu tmp) (sum! tmp dbeta :axis 0) ;; calc dsqrtvar -> dbeta (copy! sqrtvar dgamma) (.square! dgamma) (.inv! dgamma) (geem! -1.0 dbeta dgamma 0.0 dbeta) ;; calc dvar -> dbeta (copy! var dgamma) (.+! epsilon dgamma) (.sqrt! dgamma) (.inv! dgamma) (geem! 0.5 dbeta dgamma 0.0 dbeta) ;; calc dsq -> tmp (fill! 1.0 tmp) (scale-columns! dbeta tmp) (scal! (/ 1.0 (mat-dimension tmp 0)) tmp) ;; calc dxmu2 -> tmp (geem! 2.0 xmu tmp 0.0 tmp) ;; calc dx1 -> dx (axpy! 1.0 tmp dx) ;; calc -dmu -> dbeta (sum! dx dbeta :axis 0) ;; calc dx2 -> tmp (fill! 1.0 tmp) (scale-columns! dbeta tmp) (scal! (/ -1.0 (mat-dimension tmp 0)) tmp) ;; calc dx (axpy! 1.0 tmp dx) ;; calc dbeta (sum! dout dbeta :axis 0) ;; calc dgamma (geem! 1.0 dout x^ 0.0 tmp) (sum! tmp dgamma :axis 0) dx))