



























llm_presentation and deep learning methods
- 2. Agenda • Introduction to generative AI (“genAI”) • Key Features • Exercises • Discussion note: all examples have been developed using chatGPT (3.5 and 4). Other systems (e.g. Bard, Bing, Claude, Ernie Bot) should give similar, but not identical, results.
- 3. TLDR; • We assume that you’re going to use generative AI • We encourage you to use it as a tool to help you learn effectively
- 4. How Do Large Language Models (LLMs) Work? • At their most basic LLMs are statistical pattern-recognition and prediction systems • LLMs output the next likely word (“token”) in a sentence (“sequence”) • token: unit of text e.g. word, character. 1 word ~ 0.75 token • sequence: context - section (“window”) of text e.g. sentence, paragraph, book • input into chatGPT is 4096 tokens; Claude 2 is 100K tokens • The likelihood of the next work appearing is determined by • the context in which the words are seen in a larger body of text (“corpus”) and • the input to the chat
- 5. LLMs “Understand” “Meaning” • Learning from a large corpus allows LLMs to understand the meaning of words. For example • the training data may consist of many sentences beginning with “my favourite colour is…” • the next word will be a colour, allowing LLMs to cluster the words “red, blue, green…” into a set that represents the concept of “colour” • It’s important to note that LLMs don’t really understand anything. They create statistical patterns that groups similar tokens based on a complex measure of how similar or dissimilar they are.
- 6. Data used to Train LLMs • LLMs are trained in an unsupervised manner on vast quantities of open source and licensed data e.g. • The Pile (825GB, incl. web, papers, patents, books, ArXiv, Stack Exchange, maths problems, computer code) • Common Crawl (~20B URLs) • GPT3: 175B parameters; GPT4: undisclosed: est. 500B – 1000B - bigger is better (for now, at least) • Responses are refined using question-response pairs (“InstructGPT”) from the web, humans or bootstrapped (i.e. the LLM outputs its own pairs) • reinforcement learning with human feedback (RLHF) is used to reward LLMs to give appropriate responses (“guardrails”) • “Constitutional AI” – trained to filter responses based on e.g. Universal Declaration of Human Rights (Claude 2)
- 7. Next Word Prediction • is influenced by the frequency the word is seen in various contexts • but there is a degree of randomness so that the word with the highest probability isn’t always seen My favourite colour is green 9.7% red 15% pink 11.6% puce 2.3%
- 8. Meanings can change based on context In each these examples the meaning of the same word changes over time
- 9. LLMs can (seem to) be creative • A consequence of context-based learning and randomness allows the LLMs to generate surprising outputs. • Note though that they’re not creative in a human sense, but driven by pattern recognition and prediction algorithms We can use LLMs to: • identify weakly similar concepts from different disciplines and help understand different disciplines • generate diverse narratives • help with ambiguity • role playing
- 10. Beware! • LLMs may seem to “lie” and “hallucinate” i.e. give what are factually- incorrect responses to questions* • as you now know, they’re not trained to do give you an objectively correct answer! • this is some function of training data (e.g. bias), learning, search and probability • don’t believe the outputs – they always need checking, at least for now * LLMs aren’t people. They have no intentionality. Don’t anthropomorphise them
- 11. Interacting with LLMs using “Prompt Engineering” • Remember that the output of a LLM is determined by both what the system has been trained on and what information you give it • Prompt engineering means tailoring your questions and input so you can get the most out of an LLM • Prompts can take many forms, from instructing the LLM to take on a role (e.g. a helpful teacher, a pirate) or guiding the way it should process its output (e.g. “chain of thought” or a particular method).
- 12. LLMs can help you engineer prompts • prompts shouldn’t be too precise (“What’s the capital of England?”), or too vague (“Tell me about sustainability”) • sometimes you may not know how to ask an LLM to do a task • ask it what it needs and collaborate with it E.g. • “What could I ask you to help me refine my aims for an essay?” • “Do you need any more information?”
- 13. Exercise: Understanding Complex Concepts • I’m going to ask you to simplify a piece of text using your LLM of choice. Choose either of the examples in the “notes” box • Firstly, I’d like you to think through the process – how would you do it manually? • what strategies would you use? • what would you focus on? • In pairs, spend 5 minutes detailing the steps you would take to manually simplify a text so you can understand it. • You should then work with the LLM to help you understand your text • Further application: working with an LLM to help you with your aim and objectives for your SGS essay. Note: the rubrics are online.
- 14. Exercise: Role Play • We’re all prone to group-think. bias and defensive thinking or aggressive actions. This ideology isn’t good for progress! • LLMs can help us understand other’s points of view by playing the role of people who may think differently from us. Think of them as providing a “safe space” for ideological debate! • In pairs, think of a group of people who differ ideologically from you e.g. • right wing – left wing; • capitalist – socialist; • nationalism – globalism • feminism – traditionalism • authoritarianism – libertarianism • instruct your LLM to adopt these two roles and debate net zero. Tell it to strictly keep to these roles. • ask the LLM to analyse the conversation and recommend some further reading
- 15. Exercise: Socratic Conversations (to do later) • The Socratic method in teaching is where the teacher ask you open-ended questions to help explore a topic • Helps critical thinking, wider and deeper understanding • Easy to set up in an LLM Ask your LLM • to take the role of a helpful teacher • to explain the steps involved in Socratic conversations • this acts as a guide • to prompt you for a topic and then use those steps as part of Socratic conversation • you may have to intervene until you get correct behaviour. Remember that this acts to guide the LLM!
- 16. Exercise: Testing your understanding (to do later) • You can instruct an LLM to text your understanding of a topic using multiple choice questions and free-form answers • Try to set this up, noting: • it will very likely default to a standard “one correct/three incorrect” MCQ model • ask it what other formats it knows about • make sure to instruct it to stop after each question and explain the answer once you’ve entered your response. • see if you can get it behave like a computer-aided testing (“CAT”) system
- 17. Using LLMs on the MSc • You could get chatGPT to do all your assignments, and possibly pass • or you could be smart and use it to help you get a better understanding of the material • for example, you could use it to help you develop your aim and objectives for your SGS essay, • or, use it to help you structure text or refine your writing style – can be helpful if you haven’t written essays for a while, or if English isn’t your first language
- 18. “Conversational AI”: Imperial Policy • “Conversational AI” (cAI) includes chatGPT, Bard, Bing and all similar tools • There can be an educational benefit to using cAI appropriately • “Submitting work and assessments created by someone or something else, as if it was your own, is plagiarism and is a form of cheating and this includes AI-generated content.” • using chatGPT etc. would likely constitute intentional cheating and could result you failing an assessment and thus the MSc. https://www.imperial.ac.uk/about/leadership-and-strategy/provost/vice-provost-education/generative-ai-tools-guidance/
- 19. What you can’t do, some things you could do, and why you should do Can’t • cAI cannot be an author or co-author; you can’t get it to write for you in whole or in part • cAI cannot be cited or referenced • cAI cannot think for you! Could • proof-reading, but why not use Grammarly? • identify publications, but why not use Scopus/Scholar/Elicit/ScholarAI • summarising ideas, but why not use Wikipedia? • it can suggest ways to restructure, but why not speak to your supervisor?
- 20. TLDR; • We assume that you’re going to use generative AI. We’ve redesigned parts of our marking schemes to take that into account. • We encourage you to use it to help you learn effectively and not do your work for you. This may be treated as plagiarism! • Similarly, we recommend that you use other tools to help you do more formulaic work (e.g. reference manager software) and allow you to concentrate on your ideas. Your ingenuity is the thing that’s going to save the world!
- 21. Examples Mike’s chatGPT archive. Note that these are all done using chatGPT-4
- 22. Exercise: Simplification • GenAI can be used to simplify text • This simplification can be done at various levels of complexity • This is an iterative process In chatGPT type in the following, using your text • read in and acknowledge the following text. Wait for further instructions: “YOUR TEXT HERE” • please simplify the text • does anything need further simplification, or expanding/illustrating? Has it been summarised at a reasonable level (e.g. child, educated reader)? https://chat.openai.com/share/fe8c982e-cda5-465c-ab44-eb996840d8fc # Kraken example
- 23. Ask it what it needs to process your request • if you’re not sure how to develop a reasonable prompt you can prompt the system to ask you for information it needs https://chat.openai.com/share/14790e46-a3f0-4df9-a682-789a994bd157 # Sci-Fi example from Vector magazine • Or, you can get it to describe what it considers the intermediate steps • I'd like you to make some academic text accessible for me. What information do you need from me to do this successfully? https://chat.openai.com/share/eaf2a21c-3eb0-4a1f-a00c-85cb5e79df79 # Sci-Fi example from Vector magazine • you will likely have to steer further
- 24. “Steerability” • chatGPT’s behaviour can be “steered” to take on specific roles e.g. tutor, critic, Socratic partner, pirate (!). Often referred to as taking on a “role” • Output without a steer: https://chat.openai.com/share/2adbdcef-2a27-45cc-af57-1977b2ea6ab5 • Same input with steer: You are a pedagogical expert in higher education. You should respond to user input by giving advice on how to best develop and deploy the user’s input to students. https://chat.openai.com/share/492ea8bf-1a00-47a2-bd56-5f5ecd075ecf
- 25. Exercise: Restructuring text • genAI can be used to read unstructured notes, identify themes and restructure • https://chat.openai.com/share/f8c6d841-3de2-47b4-a71f-9ecdc3258479 # norm competences Exercise. In chatGPT type in the following, using your text • read in and acknowledge the following text. Wait for further instructions: “YOUR TEXT HERE” • please identify the main themes in the text • please restructure the text based on those themes play around with restructuring does it need expanding? themes and subthemes can be identified and turned into codes for qualitative analysis
- 26. Testing Comprehension Socratic questioning • https://chat.openai.com/share/89dd6a17-f6e0-4c50-afdf-b1efd6eb361b • # Star Trek: TNG assessing knowledge comprehension # see correct prompt in the notes • https://chat.openai.com/share/84ccdd27-5f96-43e3-a596-7989f27487d7 or dialogue: • https://chat.openai.com/share/b231b3e0-fd8e-4aa3-ac84-a5d427deffaf
- 27. ChatGPT and Essays • chatGPT has been used to write code to process data and then write a paper: https://www.nature.com/articles/d41586-023-02218-z • so, it can write an SGS essay (of variable quality) • https://chat.openai.com/share/334d7da4-bf35-468b-8066-7ef60889e794 • # writing an essay based on a suggested title • it’s not great at referencing, but there’s a ScholarAI plug-in for that • and https://blog.core.ac.uk/2023/03/17/core-gpt-combining-open-access-research-and- ai-for-credible-trustworthy-question-answering/
- 28. Writing A Research Proposal • pièce de résistance: • https://chat.openai.com/share/cb2e9d26-0a1d-4a21-81a9-9a4d493c 2d42
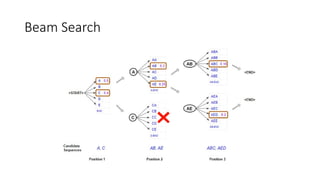
- 29. Beam Search
Editor's Notes
- #1: all notes generated by feeding in slide contents into chatGPT4, followed by further editing.
- #4: How Do Large Language Models (LLMs) Work? Large language models, or LLMs, can be understood as advanced tools built on the principles of statistical pattern recognition and prediction. LLMs are designed to predict the next most probable word—or as we term it, "token"—in a sequence. Think of a "token" as the fundamental unit of text. It can be a word, a character, or even a punctuation mark. On average a single word translates to about 0.75 tokens. The term "sequence" refers to the context or the "window" of text that the model considers when making its predictions. This could be a single sentence, a paragraph, or even a longer body of text like a book chapter. In practice, for models like ChatGPT, the maximum sequence length is 4096 tokens, which is equivalent to a few pages of text. On the other hand, newer models, like "Claude 2", can accommodate up to 100K tokens, which means you can input large texts. The LLM uses two major factors to decide what the next token it outputs should be. 1. The context from the larger body of text it was trained on, which we refer to as the "corpus". This corpus, which consists of vast amounts of diverse text data, helps the model understand patterns and relationships between words. 2. The specific input given by the user. Your input serves as a guidepost, directing the model's response based on what it has learned.
- #5: Large Language Models, or LLMs, appear to "understand" the "meaning" of words. The use of quotation marks around "understand" and "meaning" is intentional – they don’t really understand or infer meaning in the same way that we do. LLMs derive patterns and what appears to be meaning from extensive amounts of data. This is fundamentally grounded in their training on vast and varied corpora. For instance, consider the large number of sentences an LLM might encounter that begin with the phrase “my favourite colour is…”. Given this training, an LLM can predict with a high degree of certainty that the next word is likely to be a colour (although it doesn’t know what “colour” means the way we do). This continual exposure enables LLMs to cluster or group words like “red, blue, green…” into a collective set that represents the abstract concept of “colour”. It's somewhat akin to how we might mentally categorize related terms in our own minds. However—and this is a crucial caveat—it's essential to dispel a common misconception. While it might seem like LLMs truly "understand" concepts in the way humans do, they don't. Their "understanding" is fundamentally different from human comprehension. LLMs generate statistical patterns, grouping similar tokens based on complicated metrics that determine similarity or dissimilarity between tokens. It's less about true comprehension and more about recognizing patterns and connections from vast amounts of data. While LLMs demonstrate impressive capabilities in mimicking understanding, it's important to remember that their "knowledge" is based on pattern recognition, not genuine comprehension.
- #6: At the heart of LLMs lies the principle of unsupervised learning. Unlike traditional models that are given labeled data, LLMs use enormous amounts of data from various open-source or licensed sources. For example, 'The Pile' is a colossal 825GB database, encompassing everything from academic papers, patents, books, and web data to more niche areas like ArXiv, Stack Exchange, maths problems, and computer code. Another mammoth dataset is the 'Common Crawl', which comprises around 20 billion URLs. The term 'parameter' is often associated with these models. These are weights (numbers) that are used to tune the LLM so that it produces the outputs we want. GPT-3, for example, has 175 billion parameters. While the exact parameter count for GPT-4 remains undisclosed, estimates suggest a number between 500 billion to a 1 trillion. In the realm of LLMs, size often correlates with capability, suggesting that, at least for the moment, bigger is indeed better. Raw training data isn't the only thing that matters. LLMs undergo further refinement through 'InstructGPT', a process where the model hones its skills using question-response pairs. These pairs might come directly from the web, human interactions, or even bootstrapping – where the LLM essentially quizzes itself. Additionally, to ensure that LLMs align with our human values and ethical boundaries, a technique called 'reinforcement learning with human feedback' (RLHF) is employed. It's akin to teaching a pet: humans reward or penalize LLM outputs, setting up virtual "guardrails" to guide them towards desirable responses. Lastly, a novel approach in AI, dubbed “Constitutional AI,” aims to embed core human values directly into LLMs. For instance, models like 'Claude 2' are trained to filter responses based on principles from documents like the Universal Declaration of Human Rights. It's a pioneering step towards ensuring ethical AI.
- #7: We've discussed how Large Language Models, or LLMs, make predictions about the next token in a sequence. What factors drive these predictions? Firstly, the likelihood of a word being predicted is heavily influenced by how frequently it appears in diverse contexts within the training data. If a particular word frequently follows a given sequence in the texts the model has been trained on, then it's more likely to be the predicted next word. However, it's not solely about frequency. There's also an element of randomness introduced in the model's predictions. This randomness ensures that the model's outputs aren't monotonously predictable, and it allows for a diversity of responses. Hence, even if a word has the highest probability of being the next in sequence, it won't always be the predicted word every single time. We can illustrate this with a practical example. Imagine you input the first part of a sentence into an LLM: "My favourite colour is...". We also can work out the frequency with which we see the next word take some data, in this case using Google search: "My favourite colour is green" has a frequency of 9.7%. "My favourite colour is red" might have another frequency. "My favourite colour is pink" yet another, and so on. Now, even though "green" might not be the most frequent response overall, it still has a significant representation. Thus, the model might predict "green" based on its understanding of the frequency in the corpus, but also could occasionally predict "red", "pink", or even "puce", depending on the embedded randomness and other context factors. While frequency plays a paramount role in next-word prediction, the element of randomness ensures a rich and varied set of possible outputs. This mirrors the diversity and unpredictability of how we use language.
- #8: The way we use languages evolves over time. One example that aptly illustrates this point is the word "awful". We can trace how its meaning has changed over a hundred years. - 1850s: Picture Victorian England, a world steeped in formality and grandeur. In this setting, "awful" predominantly carried a sense of awe; it denoted something "solemn" or "majestic". A cathedral might be described as "awful" not because it was bad, but because of its overwhelming majesty. - 1900s: Fast forward a few decades. The world has seen significant changes, and with it, so has our word. By this time, "awful" predominantly indicated something "horrible" or distressing. The majestic undertones had faded, and the word was more aligned with negative connotations. - 1990s: Now, leap into the '90s. In some casual and colloquial contexts, "awful" took on a twist. You might hear someone say, "That party was awful good!" Here, "awful" was being used as an intensifier, akin to "really" or "very", lending a sense of "wonderful" or "extremely good" to the statement. This journey of "awful" is a great illustration of how language can be fluid. Words don't merely hold static meanings; they change as we and our cultures change. This context plays a pivotal role in shaping and reshaping word meanings. It's worth noting, especially in the context of large language models, that while they're trained on vast datasets, capturing the nuances of language evolution is a challenging endeavour. Recognizing that words can carry different meanings based on historical or cultural contexts can make interactions with these models even richer and more informed.
- #9: Can LLMs, grounded in data and algorithms, exhibit something like human creativity? The short answer is yes, but the creativity of LLMs isn't the same as the deep, conscious creativity humans possess and can be trained to use. LLMs are fundamentally trained on vast and diverse corpora, absorbing patterns, nuances, and variations of language from these texts. This context-based learning, when paired with the randomness we've discussed earlier, paves the way for LLMs to produce outputs that are not just predictable but sometimes surprising and novel. These 'creative sparks' can be invaluable, especially in fields requiring innovative thinking. For instance, in interdisciplinary research where the goal might be to bridge concepts from disparate disciplines, LLMs can play a pivotal role. They can identify weakly similar concepts that might not be immediately apparent to human researchers, thus serving as a bridge between disciplines and fostering novel discoveries. Think of LLMs as a vast reservoir of knowledge with an uncanny ability to draw unexpected connections, akin to a researcher having a "Eureka!" moment. Whether you're trying to find parallels between quantum physics and ancient philosophy or seeking common grounds between art and mathematics, LLMs can serve as invaluable aides, offering insights that might have been overlooked. capacity to draw unexpected connections and produce surprising outputs makes them powerful tools in the arsenal of any researcher, artist, or innovator. Further notes: Randomness and semantic word embedding (this is a technical term for learning meaning from context) are fundamental components of many modern language models, including LLMs. Here are a few examples to highlight the consequences and benefits of both. In all these cases, the interplay between randomness and semantic understanding enables LLMs to be both innovative and aware of context. 1. Diverse Content Generation: - Randomness: When generating content, the introduction of randomness can ensure that the output is not monotonously predictable, even when given the same prompt multiple times. - Semantic Embedding: Since words are embedded in a semantic space, the model understands context. Thus, it can craft coherent and relevant content that's diversified by randomness. Example: If you prompt an LLM with "Write a story about a cat named Luna", you might get a tale about Luna's adventure in the city one time, and a story about Luna's friendship with a mouse on another occasion. 2. Handling Ambiguity in Questions: - Randomness: For ambiguous queries, randomness can help the model pick one of many correct interpretations. - Semantic Embedding: Helps in understanding the nuances of the query and contextualizing it. Example: Given the ambiguous question "How tall is he?", instead of giving a generic height or admitting confusion every time, randomness could lead the model to sometimes ask for clarification or make educated guesses based on contextual clues, while the semantic understanding ensures that the model recognizes the ambiguity in the first place. 3. Improvisation in Art and Music: - Randomness: Introducing unpredictability, leading to novel compositions. - Semantic Embedding: Ensuring compositions remain within a semantically coherent space, respecting the essence of art or music genres. Example: When generating music, an LLM could infuse elements from jazz and classical genres, producing an innovative fusion piece that still feels grounded in both genres. Jazz is also incredibly cool and can be used as a guide to help LLMs improvise! 4. Detecting Uncommon Associations: - Randomness: It can sometimes make the leap to less common, but valid, associations. - Semantic Embedding: Helps discern how various topics relate, even if they aren't commonly connected. Example: In an interdisciplinary research context, an LLM might find parallels between concepts in neuroscience and biodiversity offsets. While randomness helps explore a broad array of connections, semantic understanding ensures those connections have substantive relevance. 5. Role-playing and Simulation Scenarios: - Randomness: Can ensure characters or scenarios exhibit varied behaviours, making simulations more lifelike. - Semantic Embedding: Ensures characters' actions and dialogues are contextually appropriate and meaningful. Example: In a virtual training scenario, an LLM can simulate different characters' responses to a given situation, like a negotiation or conflict resolution. Randomness ensures diverse reactions, while semantic grounding keeps those reactions believable and relevant.
- #10: It's vital to approach LLMs with caution. You might have heard or even experienced moments where LLMs appear to "lie" or "hallucinate," producing outputs that deviate from factual accuracy. Your LLM isn’t trying to deceive you! It's tempting to view LLMs as authoritative sources, given their vast knowledge and impressive capabilities. However, for now, it's imperative always to verify their outputs, especially in critical applications. There are a number of causes for these inaccuracies: Training Data: LLMs learn from vast amounts of information, and this training data might contain biases or errors. It is very likely that they’ll contain conflicting views for some of the things we’re interested in when studying sustainability – this is different from errors though! Learning Process: During training, LLMs attempt to find patterns and generalize, which can occasionally lead to over-simplifications or inaccuracies. Search and Probability: LLMs rely on probabilistic models, which means they predict the "most likely" next word or phrase. This process, influenced by the contexts seen during training, might not always align with factual accuracy. Remember, LLMs aren’t humans. While we might sometimes speak of them as if they have intentions or feelings, it's a simplification for our understanding. In reality, they don’t have consciousness or intent. They are sophisticated tools, not sentient beings. So, let's not anthropomorphize them! If you’re interested in the idea of robot sentience watch “The Measure of a Man”, S02E09 of Star Trek: The Next Generation!
- #11: A crucial aspect of interaction with an LLM is through Prompt Engineering. While LLMs come equipped with vast knowledge and predictive abilities, they are, in essence, tools. Much like how the precision of a scalpel's cut depends on the hand guiding it, the utility and effectiveness of an LLM depend on the input, or "prompt," it receives. First and foremost, it's crucial to remember that the LLM's output is a determined by its training data and the information you provide. The training data forms its knowledge base, while your prompt becomes the lens through which it views that knowledge. Prompt engineering is the art and science of crafting these inputs to optimize and direct the LLM's responses. By refining our questions, we can navigate the enormous amount of information and possibilities that the LLM offers, and help to steer to outputs towards something we want and find useful. Prompts can be incredibly versatile. They might: - Instruct the LLM to adopt a certain role, such as behaving like "a helpful teacher" or "a medieval historian.“ - Guide its processing pattern or approach, akin to instructing a chain of thought or a specific analytical method.
- #12: The art of questioning is a skill, and as with any skill, practice and experience will refine your ability to engage most effectively with LLMs (and with your studies!). Crafting the ideal prompt means that you have to balance between being sufficiently but not overly precise and vague, but not too vague. On one end of the spectrum, being overly precise might force the LLM down a narrow path, potentially missing out on broader insights. On the other, being too vague can yield generalized or unspecific responses. However, what happens when you're uncertain about how to best phrase your prompt? Or when you're unsure about what kind of information might optimize the LLM's output? The answer is simple: Engage in a dialogue with your LLM. Treat the LLM as a collaborator rather than just a tool and it can help you think about and write your better prompts. For instance: - You could ask, “What could I ask you to help me refine my aims for an essay?” This turns the LLM into a partner in the process, collaboratively refining your query. - Or, you might prompt with a basic request, and if the model seems unsure or requires further specificity, it might respond with, “Do you need any more information?” This allows for iterative refinement, ensuring both you and the model are on the same page. Further notes: The precision of a question can greatly influence the outcome when interacting with Large Language Models (LLMs) or any information retrieval system. Let's explore the consequences of both ends of the spectrum: Questions that are too precise: Limit Scope: Overly specific questions may limit the scope of the answer. For instance, if you ask, "What is the capital of France in 1850?", you'll receive a simple response like "Paris." A broader query might have revealed historical contexts or related events. Missed Insights: Precise questions can lead to missed opportunities for holistic understanding. If you inquire about a very specific aspect of a topic, you may overlook other interconnected facets that could provide a richer perspective. Risk of Overfitting: Just like in machine learning where a model can become too tuned to training data, overly specific questions can "overfit" the LLM's response, making responses too narrow and missing the broader picture. Redundancy: If you already know most of the specifics and only seek confirmation, the LLM might just echo back what's already known without adding value. Questions that are too vague: Overwhelming Breadth: A vague question can lead to broad answers that cover a wide range of topics. For instance, asking "Tell me about space?" could yield information from the solar system to galaxies to space travel, potentially overwhelming the user. Lack of Focus: Without specific direction, the LLM may not focus on what's most relevant to the user, leading to potential dissatisfaction with the answer. Potential for Misunderstanding: Ambiguous questions can be interpreted in multiple ways. Without clarity, the LLM might address an angle of the topic you didn't intend. Iterative Clarification: You might find yourself in a loop of refining your question over multiple interactions to get to the desired answer, which can be time-consuming. Taking a Balanced Approach: For optimal interactions with LLMs, it's often best to strike a balance. Start with a moderately specific question to guide the LLM's focus, then refine or broaden based on the initial response. This iterative approach ensures both precision and breadth, harnessing the full potential of the LLM.
- #13: for reference – my chats: example 1 using chatGPT3.5 (https://chat.openai.com/share/bbb9a363-1947-434d-9025-9bee8947fd0e); example 1 using chatGPT4 (https://chat.openai.com/share/3173dfb3-9e9a-4169-9d89-32a4159c1091); example 2 using chatGPT4 (https://chat.openai.com/share/21145caa-ad26-4088-96f3-f466a6b3f3f8) example 1 text: "The analysis in this article shows that the 2030 GDA constructs a fantasmatic explanation of international development and sustainability issues that conceals the antagonistic dimension of social, political and economic issues. In this way, it blurs the political decisions that shaped the present, undesirable situation that the agenda describes. To do so, the 2030 GDA uses ‘sustainable development’ as an empty signifier that keeps disparate and even contradictory demands united. In this sense, the agenda is a depoliticizing political device that makes an inherently political issue look not political. It could be argued that, rather than a fantasmatic narrative, the 2030 GDA is a utopian project that sets a desirable aim and enables different people to work together. The difference between a utopian project and a fantasy is that the former is based on a rational narrative, whereas the latter relies on affects, fears and desires at the level of the unconscious (Glynos, 2021: 99). Regardless of the achievability of the utopic aim, a project constructed at the rational level would first diagnose the causes of the addressed problems and, then, would explain that not everyone shares the principles, interests and objectives promoted by the utopic project, and that, accordingly, any agreement benefits some at the expense of others. This is not what the 2030 GDA does. On the contrary, it relies on evocative rhetoric to draw the global scenario through a fantasmatic narrative that glosses over the causes of the problems to solve and assumes that the entire humankind agree on certain specific objectives and, accordingly, can work together. Similarly, it could be argued that the vagueness and emptiness of the agenda are part of a political strategy intended to reach a wide consensus, flexible enough to let each member of the agreement (each country) adapt the goals set by the agenda to its national needs and preferences. Again, this is not what the 2030 GDA does. On the contrary, it sets the ontological and political limits that condition the way global issues are understood and tackled in practice. First, the agenda imposes a specific ontological essentialist position regarding social, political and economic issues. Such an understanding of global issues precludes a relational (non-essentialistic) approach that would take to the fore the power relations and structures that sustain the status quo where these problems emerged. Second, the agenda implicitly imposes a specific reading of recent history, where the economic and political events that took the world to the current situation are naturalized, and the political decisions that constructed the actual order are sedimented and forgotten. In this sense, the 2030 GDA is not a general and neutral framework that each country can apply according to its needs and interests; on the contrary, it is an ideological device that conditions the way we tackle global problems by imposing implicit ontological and political limitations. In general terms, the analysis above shows that the 2030 GDA is diverting our attention from the real problems that humankind will face during the 21st century. At the moment, the challenge is not how to overcome the threat of a menacing ‘Other’ in order to achieve the common objectives of humankind, as the agenda proposes. Rather, the challenge is to find the way to manage diverse, different, and even contradictory legitimate principles, interests and objectives within a peaceful and respectful coexistence. Evoking a homogeneous humankind and, accordingly, assuming the existence of common principles, interests and aims may be motivational and inspiring. It can help to believe that people can be mobilized together to transform the world. However, the world is different to the post-war international order where the UN was created and, accordingly, the oversimplistic diagnosis proposed by the 2030 GDA agenda does not help in realizing that the problems do not come from a horrific other, but from ‘Us’.“ example 2 text: We introduced a new approach to analyze the impact of the SDGs on tracking in persons. Our goal was to introduce mathematics of uncertainty to the analysis of sustainable goals pertinent to tracking in persons. This includes the important area of Dempster-Shafer theory. We considered countries that are members of the Organization for Economic Cooperation and Development (OECD). We found that Denmark, Finland, Iceland, and Sweden ranked the highest of the OECD counties in achieving the sustainable development goals pertinent to human tracking. In the future, we plan to examine the regions East and South Asia, Eastern Europe and Central Asia, Latin America and Caribbean, Middle East and North Africa, Sub-Saharan Africa. The purpose for the use of t-norms in this paper was to maintain the philosophy of [9, 10] that for a goal or target to score highly, it must meet all criteria. Other operators in mathematics of uncertainty can be used to examine other philosophies. For example, aggregation operators would measure the overall achievement of a country's success in achieving an SDG. Similarity measures can be used to make a wide variety of comparisons such as country rankings between years or comparison of regions. Once the door is open to techniques from fuzzy set theory, other areas such as rough sets and soft sets could come into play.
- #14: for reference – my chat log: https://chat.openai.com/share/d4882926-4bd2-4b3e-b149-54c8f76fd3fe
- #22: teaching tricky concepts: https://chat.openai.com/share/94954493-22ef-4001-a735-48de1cb39b82 https://chat.openai.com/share/14dea1f3-824c-453d-9f40-80e0af3b7b2b
- #26: I need to assess the level of comprehension that students have of particular topics and would like you to help as a diagnostic tool. I'll give you the subject and then I want you to ask me progressively more difficult questions until you've got sufficient information to state that I have beginner-level, intermediate-level or advanced-level comprehension. I would like you to start with basic questions and get progressively harder. As the diagnostic system, Please ask a question and wait for the response. Assess whether the question is correct or not, tell me why, and then ask the next one until you're able to place me on the scale above. You should ask the questions in a variety of formats, including MCQs, yes/no and free form. Note that GPT4 is considerably more accurate than GPT3.5
- #29: https://towardsdatascience.com/foundations-of-nlp-explained-visually-beam-search-how-it-works-1586b9849a24