Log System As Backbone – How We Built the World’s Most Advanced Vector Database on Pulsar - Pulsar Summit Asia 2021
0 likes1,454 views

The document outlines the architecture and features of Milvus, an open-source vector database designed for efficient similarity searches on dense vectors. It emphasizes the importance of unstructured data processing, the use of Apache Pulsar for log storage, and the database's scalability and ease of use. Real-world use cases include applications in customer service chatbots and face recognition, showcasing Milvus's capacity for real-time data ingestion and system extensibility.

























Log System As Backbone – How We Built the World’s Most Advanced Vector Database on Pulsar - Pulsar Summit Asia 2021
- 1. Log System as Backbone Xiaofan Luan 2022.1 How We Build Cloud native Vector Database on Pulsar
- 2. About Zilliz and me •Open-source company behind Milvus •Mission: Reinvent Data Science • Graduate from Cornell University • Partner, Director of engineering at ZILLIZ • member of TAC of LF AI & data foundation • Architect of Milvus Community Career History:
- 3. CONTENTS What is Vector Database 01 Architecture Overview of Milvus 2.0 02 Real-world cases 03
- 4. Agenda What is Vector Database 01 Design Philosophy behind Milvus 2.0 02 Architecture Overview 03 Real-world cases 04
- 5. What is Vector Database?
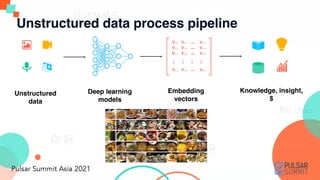
- 6. Unstructured data process pipeline Embedding vectors Deep learning models Unstructured data Knowledge, insight, $
- 7. Why vector database Arithmetic operation Number comparison 1–10 1–5 6–10 1 2 3 4 5 6 7 8 9 10 Numbers Similarity (eg. Euclidean distance) Similarity comparison Vectors Operation Organization
- 8. Data structure inside vector db • Hashing-based • Tree partitioning based • Inverted index based • Graph Based
- 9. What is Milvus From the user’s perspective of, we need a more easy- to-use and powerful database, not just a faster library. ➢ It’s a database with CRUD support ➢ Designed for efficient similarity search on dense vectors ➢ Highly scalable and robust, performance on demand ➢ Open source, world’s most popular vector database
- 10. Journey of Milvus The Idea Milvus 0.1 Release Open Source Joined LF&AI Milvus 1.0 Release Milvus 2.0 RC1 Release Milvus 2.0 GA Release 2022.1 2021.10 2021.3 2020.3 2019.10 2019.04 2018.10
- 11. Architecture overview of Milvus 2.0
- 12. Design space in vector database Tradeoffs - Consistency, Availability, Partition - Data freshness, Query performance, Resources - Another CAP, Cost, Accuracy, Performance No silver bullets fits all!!
- 13. Design choices Milvus take - Availability over Consistency - Scalability over single node performance - Ease of use over knob tuning - But everything is tunable thanks to log backbone and micro service design
- 14. Log Sequence as back bone
- 15. Tunable Consistency Strong consistency: wait for all data arrived before search Bounded Staleness: search unless data is delayed Session: read until sync time reached write ts Consistent Prefix: consume log in order Eventual: persistent log ensure data is eventual consistent
- 16. Unified Streaming/Batching Data: Growing + Historical Storage: Stream based log storage + Batch based blob storage
- 18. Time tick mechanism Logs are assigned to a window based on timestamp Data can be written out of order by proxy Time tick trigger message pack consumption
- 19. Why Apache Pulsar as log storage? ➢ Tiered Storage ➢ Unlimited topic numbers ➢ Geo Replication ➢ Multi tenancy ➢ Pulsar functions ➢ Integrated with K8s and other cloud infrastructure ➢ Timely and Kindly community support
- 20. Overall architecture of modern DB
- 21. Real world use case
- 22. Users 1000+ Enterprise users around the global
- 23. Related product search and recommendations ElasticsearchforkeywordsearchwithASCIIcodes. Thecodeweknowaboutthesetwoarraysofnumbersisthat breadnotequaltotoast. Weassumethatsimilarcontextsrepresentsimilarthings,and trytocomparethemusingmathematicalmethods.Wecould evenfindawaytoencodewholesentencesbytheirmeaning.
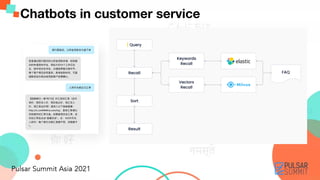
- 24. Chatbots in customer service
- 25. Face recognition
- 26. 1. Milvus can be stateless and better compatible with K8s, thanks to the usage of streaming storage. 2. System can be easily extended with other features such as key word search and analytic queries 3. Vector search can be used under more real time use cases because of supporting of streaming ingestion 4. And More: Cross datacenter/cloud replication, No more need to worry about complicated consensus protocol, UDF implementation… Conclusion
- 27. THANK YOU FOR WATCHING