Managing Thousands of Spark Workers in Cloud Environment with Yuhao Zheng and Boduo Li
1 like331 views

The document outlines the management of thousands of Spark workers in a cloud environment by Datavisor, focusing on fraud detection and the operational costs associated with cloud resources. It discusses challenges like static cluster limitations and proposes dynamic scaling solutions to optimize performance and reduce costs. Key strategies include minimizing idle times, leveraging spot instances, and maximizing resource utilization through better job scheduling.

























Managing Thousands of Spark Workers in Cloud Environment with Yuhao Zheng and Boduo Li
- 1. Managing Thousands of Spark Workers in Cloud Environment #HWCSAIS14 Yuhao Zheng & Boduo Li, DataVisor
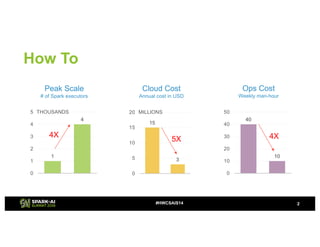
- 2. 1 4 0 1 2 3 4 5 THOUSANDS How To 2#HWCSAIS14 15 3 0 5 10 15 20 MILLIONS 40 10 0 10 20 30 40 50 Peak Scale # of Spark executors Cloud Cost Annual cost in USD Ops Cost Weekly man-hour 4X 5X 4X
- 3. 3#HWCSAIS14 • Focus on fraud detection • Founded in Dec 2013 • 100-person team
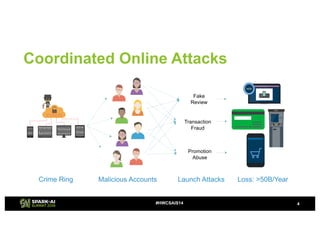
- 4. Coordinated Online Attacks 4#HWCSAIS14 Crime Ring Malicious Accounts Loss: >50B/Year Transaction Fraud Fake Review Promotion Abuse Launch Attacks
- 5. DataVisor: UML Fraud Detection 5#HWCSAIS14 Early Detection Catch incubated accounts High Coverage and Accuracy Detect all bad users in a campaign Unknown Attack Detection Catch unknown suspicious activities Unsupervised Machine Learning
- 6. UML is Expensive 6#HWCSAIS14 Register Profile Login Trasaction … Data Clean, Feature Ext. User Events Feature Pool: Thousands of Features Behavior Pattern Profile Pattern Device Pattern application_freq application_time … … work_year_distrib marriage_distrib promoter_info … deviceid_distrib ip_usage devicetype_var … … … … !(#, %) = ( ) *) ∗ ,)(-. , -/) Clustering Analysis 01 = ( 1 !1(#, %) Association probability Clustering probability …
- 7. Huge Data Volume 7#HWCSAIS14 3 Billion+ user accounts 600 Billion+ events and growing 3 Petabytes of data
- 8. Schedule Dependency 8#HWCSAIS14 Pipeline Module Original Data Pipeline Module Pipeline Module Pipeline Module Pipeline Module Pipeline Module ~20 modules / client Original Data Detection Result
- 9. Naïve Solution: Single Cluster 9#HWCSAIS14 EUEUQOFIF Spark Applications Spark Cluster Estimated Annual Cost 15 Million M S S S S S Static cluster No auto-scale
- 10. Problems of Single Static Cluster 10#HWCSAIS14 Application Executor Memory # Executors 1 2 GB 2 2 6 GB 80 3 12 GB 48 Wasted memory12GB2GBRunning: App Executor12GBQueueing: Cluster Size
- 11. Improvement: Multiple Clusters 11#HWCSAIS14 EUEUQOFIF Small Applications EUEUQOFIF Large Applications 12GB Executors 2GB Executors M S S S S S M S S S S S Estimated Annual Cost 12 Million
- 12. Further Reduce Cost 12#HWCSAIS14 Operational cost • Loss of spot • Job failure Estimated Annual Cost 8 Million Cloud cost • Spot instances • Smaller cluster
- 13. Drawbacks of Static Allocation 13#HWCSAIS14 Fixed Size Always On Over capacity Under capacity Maintenance Cost Human Cost Cloud Cost
- 14. Can We Go Dynamic? 14#HWCSAIS14 Why Not?
- 15. More Requirements • Product features – Affect module dependencies • Job priority – SLA assurance 15#HWCSAIS14 High priority Normal priority Product A Product B
- 17. DataVisor SparkGen 17#HWCSAIS14 Prod Job Scheduler Spark Resource Manager Prod Jobs Dev Jobs Developers M S S S M S S S S S M S S S S Estimated Annual Cost 3 Million
- 18. Cost Equations Cost = Machine Cost + Human Cost Machine Cost = Machine Up Time x Unit Price Human Cost = Operation Overhead 18#HWCSAIS14
- 19. Reduce Machine Up Time Single Static Cluster ⊕ One-time launch ⊖ Low utilization ⊖ Idle time 19#HWCSAIS14 Multiple Static Clusters ⊕ One-time launch Moderate utilization ⊖ Idle time One Job Per Cluster ⊖ Per-job launch ⊕ High utilization ⊕ No idle time ⊕ Dynamic max concurrency ⊕ No inter-job interference ⊕ Low maintenance overhead ⊖ Limited concurrency ⊖ Inter-job interference ⊖ High maintenance overhead ⊖ Limited concurrency ⊖ Inter-job interference ⊖ High maintenance overhead 60% Saving Job JobLaunch Time Utilization 1 0 Idle Idle Under-utilized Resource Idle
- 20. Reduce Launch Time • Pre-built AMI – Systems & libs (dockerized) – Pre-configured (non-runtime) • Concurrent master/slave initialization • Result: 30 min → 3 min 20#HWCSAIS14 Amazon Machine Image (AMI) Docker Docker Spark Ganglia Docker Libs Slave Initialization (2 phases) 1 2 Require Master Ready • Phase 1 • Launch instance • Upload runtime configuration • Start services (local) • Phase 2 • Start services (connect to master) Sequential Launch Time Master Init 1 2 1 2 Concurrent Launch Time Master Init 1 1 2 2
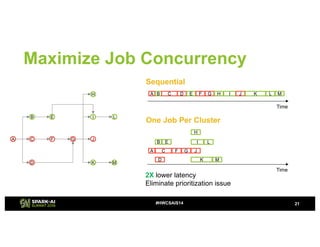
- 21. Maximize Job Concurrency 21#HWCSAIS14 A D C F G B E J K I M L H A B C D E F G J H K M I L A B C D E F G H I LJ K M Sequential 2X lower latency Eliminate prioritization issue Time Time One Job Per Cluster
- 22. Cost Equations Cost = Machine Cost + Human Cost Machine Cost = Machine Up Time x Unit Price Human Cost = Operation Overhead 22#HWCSAIS14
- 23. Reduce Unit Price • Spot Slaves (75% Saving) • Reserved Masters (40% Saving) 23#HWCSAIS14 0 0.1 0.2 0.3 0.4 0.5 0.6 SPOT RESERVED ON DEMAND R4.2XLARGE HOURLY $
- 24. Cost Equations Cost = Machine Cost + Human Cost Machine Cost = Machine Up Time x Unit Price Human Cost = Operation Overhead 24#HWCSAIS14
- 25. Reduce Operation Overhead • One Job Per Cluster – Dynamic scale out – No inter-job interference – Easy patch/re-launch clusters – Spot Fleet • Higher availability (diversified) • Maintain minimum capacity 25#HWCSAIS14 zone a, r4.2xlarge zone b, r4.8xlarge zone c, r4.xlarge zone b, r4.4xlarge zone b, r4.2xlarge
- 26. Why Not Yarn? • Compared to One Job Per Cluster – Single-point of failure (Master) – Slower to scale – One more system to configure / maintain 26#HWCSAIS14
- 27. Job Scheduler 27#HWCSAIS14 Spark Resource Manager Product Features Auto Generate Dependency Simple Per-client Spec
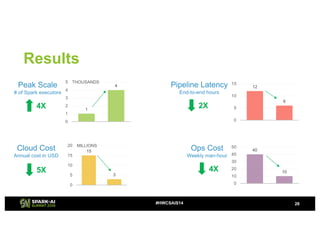
- 28. Results 28#HWCSAIS14 40 10 0 10 20 30 40 50 12 6 0 5 10 15 Peak Scale # of Spark executors Cloud Cost Annual cost in USD Ops Cost Weekly man-hour Pipeline Latency End-to-end hours 4X 5X 4X 2X1 4 0 1 2 3 4 5 THOUSANDS 15 3 0 5 10 15 20 MILLIONS