Mariia Havrylovych "Active learning and weak supervision in NLP projects"
Download as PPTX, PDF0 likes684 views

The document outlines the application of active learning and weak supervision techniques in natural language processing (NLP) projects at Wix, focusing on the challenges of labeling data and the methods to improve labeling efficiency. It discusses the integration of these techniques to minimize manual efforts while achieving high performance in machine learning models, particularly in spam classification tasks. The results demonstrate that using a combination of active learning and weak supervision significantly reduces the amount of labeled data needed while maintaining high accuracy.



























![Query strategy with
text embeddings
We need to set:
▪ Type of embedding
(TF-IDF, BERT, etc.)
▪ Similarity metric
(cosine, euclidean
distance)
We used Universal
Sentence Encoder and
cosine similarity.
class EmbeddingSimilatitySelection(QueryStartegy):
def selection(self, embedder, num_samples: int, train: pd.DataFrame, pool: pd.DataFrame):
matrix1 = embedder(train.query("label=='spam'")["text"].values).numpy()
matrix2 = embedder(pool["text"].values).numpy()
res = 1 - sp.distance.cdist(matrix1, matrix2, 'cosine')
col_max = np.amax(res, axis=0)
selected_indices = np.argsort(col_max)[-num_samples:]
return selected_indices
Embed the “spam”
examples from labeled
train set
Embed the unlabelled
poolCalculate the cosine
distance](https://image.slidesharecdn.com/activelearningandweaksupervisioninnlpprojects1-200808121915/85/Mariia-Havrylovych-Active-learning-and-weak-supervision-in-NLP-projects-28-320.jpg)



















![References
Active Learning Literature Survey
A Proactive Look at Active Learning Packages - data from the trenches
Snorkel.org
Introduction to Active Learning | Discriminative Active Learning
[1605.07723] Data Programming: Creating Large Training Sets, Quickly
An Overview of Weak Supervision · Snorkel
Building NLP Classifiers Cheaply With Transfer Learning and Weak Supervision
SUMMARY](https://image.slidesharecdn.com/activelearningandweaksupervisioninnlpprojects1-200808121915/85/Mariia-Havrylovych-Active-learning-and-weak-supervision-in-NLP-projects-49-320.jpg)

Mariia Havrylovych "Active learning and weak supervision in NLP projects"
- 1. Mariia Havrylovych, Data Scientist @Wix Active Learning & Weak Supervision in NLP Projects [email protected]
- 2. 19 Languages 4.7M Paid Users Over 190 Countries
- 5. Why and when we need such tools as active learning or weak supervision?
- 8. AI solution cycle INTRODUCTION A lot of high- quality data is highly correlated with success!
- 9. Supervised Machine Learning INTRODUCTION Assign a label Data points Where we get the label?
- 10. INTRODUCTION Where do we get labeled data from? Pre-labeled open source datasets that are available for the public. Manual labeling Crowdsourcing, human labeling, etc. Labels extracted from existing data
- 11. Supervised Machine Learning INTRODUCTION Assign a label Data points Assign a label
- 13. Obstacles while getting the labels ▪ Lacking resources ▪ Domain-specific data ▪ Data contains sensitive information ▪ Imbalanced dataset with very rare classes ▪ “Hungry” models ▪ Very slow labeling process INTRODUCTION
- 14. The main goal is to overcome labelling bottleneck and achieve the best performance with minimum efforts INTRODUCTION
- 15. What are we going to do? INTRODUCTION Spam SMS classification ~5400 samples ~75% - Close your eyes and imagine that there are no labels. 20% is taken as test set ~200 samples took as labeled dataset, from which we start. Mimic labels shortage scenario and show how active learning and weak supervision will shine! Divide this dataset into 3 parts
- 16. The Dataset INTRODUCTION FREEMSG: Our records indicate you may be entitled to 3750 pounds for the Accident you had. To claim for free reply with YES to this msg. To opt out text STOP I'm gonna be home soon and i don't want to talk about this stuff anymore tonight, k? I've cried enough today. SPAM Not SPAM 13% 87%
- 17. Starting components ▪ F1 score for “spam” class as metric ▪ Logistic regression and TF-IDF as base model INTRODUCTION
- 18. What is text embedding? INTRODUCTION Text snippet Move text into numbers
- 19. Couple of words about text embeddings INTRODUCTION Text documents 1 1 2 0 0 ... 1 0 means that text does not have such word. 1 means that corresponding word from vocabulary is present in text 1 time. Put every text in N-size vector Create the vocabulary Set of words in our texts with size N Every cell is representing a word from vocabulary N size
- 21. In active learning we allow the model to be curious and select the data for training.
- 22. Standard ML app creation process ACTIVE LEARNING Unlabeled pool Labeled train set Oracle ML model Randomly select some SMS Update train set Train the model Text SMS
- 23. ML app creation process with pool- based active learning ACTIVE LEARNING Unlabeled pool Labeled train set Oracle ML model Query strategy Update train set Train the model Difference is here!
- 24. ACTIVE LEARNING ML model Query strategy Does the predictions Model prediction - “Spam” proba - 0.97; “Not spam” proba - 0.03 Unlabeled pool SMS 1 SMS 2 SMS 100 Model prediction - “Spam” proba - 0.49; “Not spam” proba - 0.51 The hardest SMS are where “spam” pr. - “not spam” pr. is minimal Easy example! Hard example! We will give to labeler the hardest one!
- 25. Query strategies Random (no active learning) Uncertainty and margin sampling Query by committee Your query strategy ACTIVE LEARNING
- 26. How to select your “hardest”samples? ACTIVE LEARNING We have imbalanced dataset, so let’s consider “spam” samples as the hard one. We can select most similar to “spam” samples
- 27. ACTIVE LEARNING Query strategy with text embedding Unlabeled pool Labeled train set Create text embeddings for “spam” samples Create text embeddings from all samples from unlabelled pool Calculate similarity between these embeddings and choose samples with maximum similarity to “spam” samples from train set
- 28. Query strategy with text embeddings We need to set: ▪ Type of embedding (TF-IDF, BERT, etc.) ▪ Similarity metric (cosine, euclidean distance) We used Universal Sentence Encoder and cosine similarity. class EmbeddingSimilatitySelection(QueryStartegy): def selection(self, embedder, num_samples: int, train: pd.DataFrame, pool: pd.DataFrame): matrix1 = embedder(train.query("label=='spam'")["text"].values).numpy() matrix2 = embedder(pool["text"].values).numpy() res = 1 - sp.distance.cdist(matrix1, matrix2, 'cosine') col_max = np.amax(res, axis=0) selected_indices = np.argsort(col_max)[-num_samples:] return selected_indices Embed the “spam” examples from labeled train set Embed the unlabelled poolCalculate the cosine distance
- 29. How to choose query strategy? ▪ Look at your model (e.g. does it support probabilistic output or not?). ▪ Proportion of classes (classic query strategies may not work with imbalanced dataset). ▪ Data distribution (does it have some high-density clusters). ▪ Amount of initial labeled data. ACTIVE LEARNING
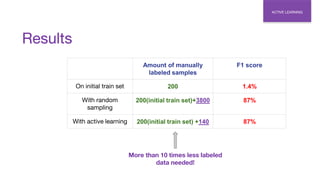
- 30. Results ACTIVE LEARNING Amount of manually labeled samples F1 score On initial train set 200 1.4% With random sampling 200(initial train set)+3800 87% With active learning 200(initial train set) +140 87% More than 10 times less labeled data needed!
- 31. But... Strong coupling between model and train set Selective bias Greedy selection Labeler is still needed ACTIVE LEARNING
- 32. Can we create train set if we do not have labeler?
- 34. Data Programming Paradigm The goal: we want to create labeled train set automatically without manual labelling. The central concept is Labeling Function (LF) - user-defined functions, based on some rule, heuristic, etc. that assign a label to some part of the dataset. WEAK SUPERVISION One data point can have multiple labels from different labeling functions! LF 1: Does SMS come from your phone book number? Yes No Not Spam Unsure LF 2: Does SMS contain “give me money” phrase? No Yes Spam One SMS can meet both rules
- 35. Data Programming Paradigm WEAK SUPERVISION Labeling function 1 Labeling function 2 Labeling function 3 Unlabelled data Smartly aggregate labels from LFs into single (probabilistic) output ... Label for sample 1 Label for sample 2 Train the model These labels contain mistakes (are “noisy”)
- 36. What do we need to start? WEAK SUPERVISION Unlabeled pool Development set Small labeled set. From it you will get the ideas for your labeling functions.
- 37. Labeling functions ● Simple LF ○ Keyword-based ( “free”, “award”, “prize”, “call now”, etc) WEAK SUPERVISION FREEMSG: Our records indicate you may be entitled to 3750 pounds for the Accident you had. To claim for free reply with YES to this msg. To opt out text STOP We create 5 keyword-based LFs! @labeling_function() def free(x): return SPAM if “free” in x.text.lower() else ABSTAIN
- 38. Labeling functions ● Simple LF ○ Feature-based (sms length, number of verbs/nouns, etc.) WEAK SUPERVISION @labeling_function() def comment_length(x): return HAM if len(x.text.split()) < 10 else ABSTAIN Spam SMS are longer.
- 39. Labeling function with text embeddings We used Universal Sentence Encoder and cosine similarity. 1. Detect the similarity threshold on development set. 2. Assign to particular class samples which are above the similarity threshold. @labeling_function() def use_similarity(x): return SPAM if x.similarity_spam>threshold else ABSTAIN Set the threshold on 0.2
- 40. Results WEAK SUPERVISION Amount of labeled data points F1 score With simple labeling functions 200 from development set 77% With more complex labeling functions 200 from development set 90% No manual labelling at all!
- 41. But... ▪ Subjective target does not allow to clearly define the rules. ▪ Broad classes is hard to properly cover with LFs. ▪ Expert may be needed. ▪ Noisiness of labels can make an impact (especially in case of imbalanced datasets) . WEAK SUPERVISION
- 42. Weak supervision and active learning together 03
- 43. How can we combine AL & WS? If weak supervision labels contain too many mistakes, we can add them as an extra feature. And keep train model with active learning. AL & WS Unlabeled pool Labeled train set Oracle ML model Query strategy Update train set Train the model Feature 1 Feature 2 ... Weak supervision label as feature Manual Label ham spam ham ham spam
- 44. How can we combine AL & WS? AL & WS Oracle Query strategyUpdate train set Train the model Labeled train set ML model The hardest data points The easiest data points Labeling functions
- 45. How can we combine AL & WS? AL & WS We will try to implement this scenario! Feature 1 Feature 2 ... Label Manual label Manual label Weak supervision label Weak supervision label Weak supervision label Enlarge initial train set with programmatically labeled samples Unlabeled pool Labeled train set Oracle ML model Query strategy Update train set Train the model
- 46. Results AL AND WS Amount of labeled data points F1 score With random sampling 200 (initial train set) + 3800 87% With active learning 200 (initial train set) + 140 87% Weak supervision: Simple LFs 200 (development set) 77% Weak supervision: All LFs 200 (development set) 90% Active learning and weak supervision 200 (initial train set) + 130 87%
- 47. Summary ● In Wix we use active learning and weak supervision for a lot of projects, despite we have a Data Curation and Labeler department ● Mostly we do not use some particular tool, but in combination At Wix, AL & WS help us to minimize efforts, speed up creating and delivering AI solutions to the customers! SUMMARY
- 48. Do not give up, if nothing helps you! SUMMARY
- 49. References Active Learning Literature Survey A Proactive Look at Active Learning Packages - data from the trenches Snorkel.org Introduction to Active Learning | Discriminative Active Learning [1605.07723] Data Programming: Creating Large Training Sets, Quickly An Overview of Weak Supervision · Snorkel Building NLP Classifiers Cheaply With Transfer Learning and Weak Supervision SUMMARY