Microsoft Big Data @ SQLUG 2013
11 likes•10,076 views

The document discusses big data and Hadoop. It provides an overview of key components in Hadoop including HDFS for storage, MapReduce for distributed processing, Hive for SQL-like queries, Pig for data flows, HBase for column-oriented storage, and Storm for real-time processing. It also discusses building a layered data system with batch, speed, and serving layers to process streaming data at scale.





































































































Microsoft Big Data @ SQLUG 2013
- 1. BIG DATA Wesley Backelant Technology Advisor Microsoft @WesleyBackelant Nathan Bijnens Big Data Consultant DataCrunchers @nathan_gs
- 2. AGENDA • Big Data • Hadoop (& Ecosystem) • How does it fit in the Microsoft world? • Demo • Resources • Q&A
- 3. THE WORLD OF DATA IS CHANGING
- 4. TODAY A NEW SET OF QUESTIONS ARE BEING ASKED OF THE BUSINESS: What’s the social How do I better sentiment for my predict future brand or products outcomes? How do I optimize my fleet based on weather and traffic patterns?
- 5. TRANSFORMATION OF ONLINE MARKETING BLOGS.FORBES.COM/DAVEFEINLEIB
- 6. TRANSFORMATION OF OPERATIONS BLOGS.FORBES.COM/DAVEFEINLEIB
- 7. TRANSFORMATION OF CUSTOMER SERVICE BLOGS.FORBES.COM/DAVEFEINLEIB
- 9. TRANSFORMATION OF FRAUD DETECTION Then… Now…
- 10. NEW HARDWARE APPROACH Traditional Big Data Exotic HW Commodity HW • Big central servers • racks of pizza boxes • SAN • Ethernet • RAID • JBOD Hardware reliability Unreliable HW Limited scalability Scales further Cost effective
- 11. NEW SOFTWARE APPROACH Traditional Big Data Monolotic Distributed • Centralized - storage & compute nodes • RDBMS Raw data Schema first Proprietary
- 12. HADOOP & BIG DATA ECOSYSTEM MapReduce HDFS
- 14. HDFS
- 15. HDFS
- 17. MAPREDUCE
- 18. MAPREDUCE
- 19. MAPREDUCE
- 20. HIVE
- 21. HIVE A data warehouse infrastructure built on top of Hadoop for providing data summarization, query, and analysis. – Ideal for ad hoc querying – Query execution via MapReduce. Key Building Principles: – SQL – Extensibility – Types – Functions – Scripts
- 22. HIVE It supports many SQL features like: – Data partitioning – Aggregations – Grouping – Joins
- 23. HIVE And it’s extendable using UDFs. package com.example.hive.udf; import org.apache.hadoop.hive.ql.exec.UDF; import org.apache.hadoop.io.Text; public final class Lower extends UDF { public Text evaluate(final Text s) { if (s == null) { return null; } return new Text(s.toString().toLowerCase()); } } There are many UDFs published by external parties, for: - Loading / Saving (SerDe) - Field Transformations
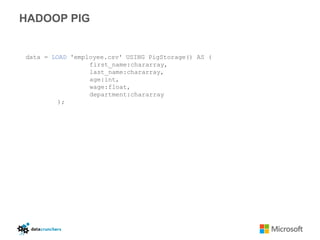
- 25. HADOOP PIG: INTRO Pig is a high level data flow language.
- 26. HADOOP PIG: 3 COMPONENTS • Pig Latin • Grunt • PigServer
- 27. HADOOP PIG data = LOAD 'employee.csv' USING PigStorage() AS ( first_name:chararray, last_name:chararray, age:int, wage:float, department:chararray );
- 28. HADOOP PIG grouped_by_department = GROUP data BY department; total_wage_by_department = FOREACH grouped_by_department GENERATE group AS department, COUNT(data) as employee_count, SUM(data::wage) AS total_wage; total_ordered = ORDER total_wage_by_department BY total_wage; total_limited = LIMIT total_ordered 10;
- 29. HADOOP PIG DUMP total_limited; STORE total_limited INTO ‘/test/’;
- 30. UDF ● Custom Load and Store classes. ● Hbase ● ProtocolBuffers ● CombinedLog ● Custom extraction eg. date, ... ● Take a look at the PiggyBank.
- 32. HBASE A distributed, versioned, column-oriented database. • Main features: • Horizontal scalability • Machine failure tolerance • Row-level atomic operations including compare-and-swap ops like incrementing counters • Augmented key-value schemas, the user can group columns into families which are configured independently • Multiple clients like its native Java library, Thrift, and REST • Upcoming Security
- 34. STORM
- 35. STORM
- 36. STORM • Message passing. • Distributed processing. • Horizontally scalable. • Incremental algorithms. • Fast. • Data in motion.
- 37. STORM Nimbus Zookeeper Supervisor Supervisor Supervisor Worker Worker Worker Worker Worker Worker Worker Worker Worker Worker Node Worker Node Worker Node
- 40. STORM • Grouping
- 41. A DATA SYSTEM
- 42. DATA IS MORE THAN INFORMATION Not all information is equal. Some information is derived from other pieces of information.
- 43. DATA IS MORE THAN INFORMATION Eventually you will reach the most ‘raw’ form of information. This is the information you hold true, simple because it exists. Let’s call this ‘data’, very similar to ‘event’.
- 44. EVENTS Everything we do generates events: • Pay with Credit Card • Commit to Git • Click on a webpage • Tweet
- 45. EVENTS - BEFORE Events used to manipulate the master data.
- 46. EVENTS - AFTER Today, events are the master data.
- 47. DATA SYSTEM Let’s store everything.
- 48. EVENTS Data is Immutable
- 49. EVENTS Data is Time Based
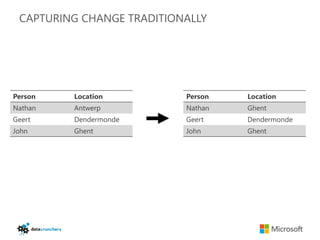
- 50. CAPTURING CHANGE TRADITIONALLY Person Location Person Location Nathan Antwerp Nathan Ghent Geert Dendermonde Geert Dendermonde John Ghent John Ghent
- 51. CAPTURING CHANGE Person Location Timestamp Person Location Time Nathan Antwerp 2005-01-01 Nathan Antwerp 2005-01-01 Geert Dendermonde 2011-10-08 Geert Dendermonde 2011-10-08 John Ghent 2010-05-02 John Ghent 2010-05-02 Nathan Ghent 2013-02-03
- 52. QUERY The data you query is often transformed, aggregated, ... Rarely used in it’s original form.
- 53. QUERY Query = function ( data )
- 54. NUMBER OF PEOPLE LIVING IN EACH CITY. Person Location Time Location Count Nathan Antwerp 2005-01-01 Ghent 2 Dendermonde 1 Geert Dendermonde 2011-10-08 John Ghent 2010-05-02 Nathan Ghent 2013-02-03
- 55. QUERY All Data Query
- 56. QUERY: PRECOMPUTE All Data Precomputed View Query
- 57. LAYERED ARCHITECTURE Batch Layer Speed Layer Serving Layer
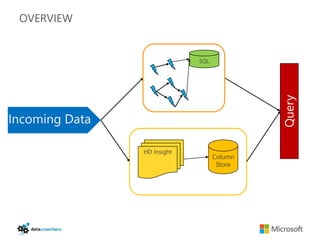
- 58. LAYERED ARCHITECTURE SQL Query Incoming Data HD Insight Column Store
- 59. BATCH LAYER
- 60. BATCH LAYER Incoming Data HD Insight Column Store
- 61. BATCH LAYER Unrestrained computation.
- 62. BATCH LAYER Horizontal scalable.
- 63. BATCH LAYER High Latency. Let’s pretend temporarily that update latency doesn’t matter.
- 64. BATCH LAYER Stores master copy of data set... append only.
- 65. BATCH LAYER
- 66. BATCH: VIEW GENERATION View #1 Master Dataset View #2 MapReduce View #3
- 67. MAPREDUCE 1. Take a large problem and divide it into sub-problems … MAP 2. Perform the same function on all sub-problems … DoWork() DoWork() DoWork() 3. Combine the output from all sub-problems REDUCE … Output
- 68. BATCH VIEW DATABASE Read only database. No random writes required.
- 69. BATCH LAYER We are not done yet… Just a few hours of data. Not yet Data absorbed into Batch Views absorbed. Time Now
- 70. SPEED LAYER
- 71. OVERVIEW SQL Incoming Data HD Insight Column Store
- 72. SPEED LAYER Stream processing.
- 73. SPEED LAYER Continuous computation.
- 74. SPEED LAYER Transactional.
- 75. SPEED LAYER Storing a limited window of data. Compensating for the last few hours of data.
- 76. SPEED LAYER All the complexity is isolated in the Speed layer. If anything goes wrong, it’s auto-corrected.
- 77. CAP You have a choice between: • Availability • Queries are eventual consistent. • Consistency • Queries are consistent.
- 78. EVENTUAL ACCURACY Some algorithms are hard to implement in real time. For those cases we could estimate the results.
- 79. SPEED LAYER Real Time View 1 Incoming Data Real Time View 2
- 80. SPEED LAYER VIEWS • The views are stored in Read & Write database. • MS SQL Server • Column Store • Cassandra • … • Much more complex than a read only view.
- 81. SERVING LAYER
- 82. OVERVIEW SQL Query Incoming Data HD Insight Column Store
- 83. SERVING LAYER This layer queries the Batch & Real Time views and merges it.
- 84. SERVING LAYER Batch Views Merge Real Time Views
- 85. SERVING LAYER Polybase is a great fit.
- 86. OVERVIEW
- 87. OVERVIEW SQL Query Incoming Data HD Insight Column Store
- 88. LAMBDA ARCHITECTURE • Can discard any view, batch and real time, and just recreate everything from the master data. • Mistakes are corrected via recomputation. • Write bad data? Remove the data & recompute. • Bug in view generation? Just recompute the view. • Data storage is highly optimized.
- 90. WHAT IS MICROSOFT DOING ON THE BI & DEVELOPMENT SIDE
- 91. INSIGHTS FROM ANY DATA, ANY SIZE, ANYWHERE 010101010101010101 1010101010101010 01010101010101 101010101010
- 92. WE DELIVER INSIGHTS TO EVERYONE BY ENABLING BIG DATA ANALYSIS WITH FAMILIAR END USER TOOLS Benefits Interaction and analysis of unstructured data in Hadoop Key Features Hive add-in for Excel
- 93. UNLOCKING IMMERSIVE INSIGHTS FROM ALL DATA WITH MICROSOFT BI TOOLS Benefits Familiar self service BI tools Key Features Hive ODBC Driver integrates Hadoop to SQL Server Analysis Services, PowerPivot, and Power View
- 94. WHILE DRAMATICALLY SIMPLIFYING PROGRAMMING ON HADOOP MapReduce programs Benefits in JavaScript Simplified Simplified Deployment of Programming MapReduce jobs Key Features JS Deploy JavaScript Hadoop Integration with .NET and jobs from a simple web new JavaScript libraries for browser on any supported Hadoop device
- 95. WE MANAGE STREAMING DATA WITH STREAMINSIGHT Benefits Key Features StreamInsight SQL StreamInsight
- 96. WHAT IS MICROSOFT DOING ON THE HADOOP & INTEGRATION SIDE?
- 97. WE MANAGE RELATIONAL DATA WITH MICROSOFT ENTERPRISE DATA WAREHOUSE SOLUTIONS Reference Architectures Appliances Dell Parallel HP Enterprise Data Data Fast Track for Warehouse Warehouse Dell HP Business Quickstart Data Data Warehouse Warehouse
- 98. INTRODUCING POLYBASE Fundamental Breakthrough in Data Processing Single Query; Structured and Unstructured SQL • Query and join Hadoop tables with Relational Tables SQL Server 2012 • Use Standard SQL language PDW Powered • Select, From Where by PolyBase Existing SQL No IT Save Time Analyze All Skillset Intervention and Costs Data Types
- 99. AND SUPPORT UNSTRUCTURED DATA WITH ENTERPRISE CLASS HADOOP ON PREMISE AND IN THE CLOUD Benefits Key Features
- 100. MICROSOFT BRINGS THE SIMPLICITY AND MANAGEABILITY OF WINDOWS AND SQL SERVER TO HADOOP Benefits Key Features
- 101. MICROSOFT DELIVERS BIG DATA THROUGH OPEN PLATFORM AND A RICH PARTNER ECOSYSTEM Benefits Key Features
- 102. BIG DATA DEMO: FROM DATA TO INSIGHTS! Analysis with familiar Collaboration on Simplicity tools insights
- 103. THANK YOU!!!
- 104. RESOURCES • Microsoft Big Data Solution: www.microsoft.com/bigdata • Windows Azure: www.windowsazure.com/en-us/home/scenarios/big-data • Try Now: https://www.hadooponazure.com • HDInsight For Windows Beta Download: http://hortonworks.com/download/ • HDInsight Services For Windows: http://social.technet.microsoft.com/wiki/contents/articles/6204.hdinsight-services-for- windows.aspx#videos • Hadoop in PowerPivot: http://social.technet.microsoft.com/wiki/contents/articles/6294.how-to- connect-excel-powerpivot-to-hive-on-azure-via-hiveodbc.aspx • Hadoop in SSIS: http://msdn.microsoft.com/en-us/library/jj720569.aspx • Hurricane Sandy: http://sqlcat.com/sqlcat/b/msdnmirror/archive/2013/02/01/hurricane-sandy- mash-up-hive-sql-server-powerpivot-amp-power-view.aspx • Hadoop PowerShell: http://blogs.msdn.com/b/cindygross/archive/2012/08/23/how-to-install-the- powershell-cmdlets-for-apache-hadoop-based-services-for-windows.aspx • SQL Server BCP to Hive: http://blogs.msdn.com/b/cindygross/archive/2012/09/28/load-sql-server- bcp-data-to-hive.aspx • Internal vs External Table Hive: http://blogs.msdn.com/b/cindygross/archive/2013/02/06/hdinsight- hive-internal-and-external-tables-intro.aspx • Microsoft.NET SDK for Hadoop: http://hadoopsdk.codeplex.com/ • Twitter Analytics Example: http://twitterbigdata.codeplex.com/
- 105. DATACRUNCHERS We enable companies in envisioning, defining and implementing a data strategy. A one-stop-shop for all your Big Data needs. The first Big Data Consultancy agency in Belgium.