Ceph Day NYC: Ceph Performance & Benchmarking
Download as ODP, PDF•7 likes•4,962 views

This document discusses the Ceph distributed storage system. It provides performance test results from a single server configuration reaching over 2GB/s throughput, and from a multi-server configuration at Oak Ridge National Laboratory scaling to over 14GB/s. The effects of replication on throughput are also examined. CephFS performance is briefly discussed, noting it is not yet production ready. Challenges in thoroughly testing Ceph's performance across its many configurations are also mentioned.





























Ceph Day NYC: Ceph Performance & Benchmarking
- 1. That's Ceph, I use Ceph now, Ceph is Cool.
- 2. Who's the crazy guy speaking?
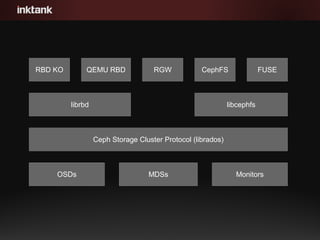
- 4. RBD KO QEMU RBD RGW CephFS FUSE librbd libcephfs Ceph Storage Cluster Protocol (librados) OSDs MonitorsOSDs MDSs
- 6. CRUSH: Hash Based Deterministic Data Placement Pseudo-Random, Weighted, Distribution Hierarchically Defined Failure Domains
- 7. ADVANTAGES: Avoids Centralized Data Lookups Even Data Distribution Healing is Distributed Abstracted Storage Backends
- 8. CHALLENGES: Ceph Loves Homogeneity (Per Pool) Ceph Loves Concurrency Data Integrity is Expensive Data Movement is Unavoidable Distributed Storage is Hard!
- 9. BORING! How fast can we go? Let's test something Fun!
- 10. Supermicro SC847A 36-drive Chassis 2x Intel XEON E5-2630L 4x LSI SAS9207-8i Controllers 24x 1TB 7200rpm spinning disks 8x Intel 520 SSDs Bonded 10GbE Network Total Cost: ~$12k
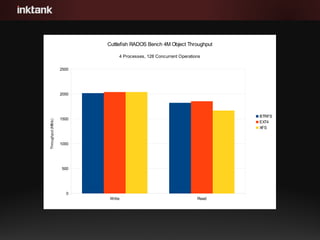
- 11. Write Read 0 500 1000 1500 2000 2500 Cuttlefish RADOS Bench 4M Object Throughput 4 Processes, 128 Concurrent Operations BTRFS EXT4 XFS Throughput(MB/s)
- 12. Yeah, yeah, the bonded 10GbE network is maxed out. Good for you Mark.
- 13. Who cares about RADOS Bench though? I've moved to the cloud and do lots of small writes on block storage.
- 15. OK, if Ceph is so awesome why are you only testing 1 server? How does it scale?
- 16. Oak Ridge National Laboratory 4 Storage Servers, 8 Client Nodes DDN SFA10K Storage Chassis QDR Infiniband Everywhere A Boatload of Drives!
- 17. 1 2 3 4 0 2000 4000 6000 8000 10000 12000 14000 ORNL Multi-Server RADOS Bench Througput 4MB IOs, 8 Client Nodes Writes Reads Writes (Including Journals) Disk Fabric Max Client Network Max Server Nodes (11 OSDs Each) Throughput(MB/s)
- 18. So RADOS is scaling nicely. How much does data replication hurt us?
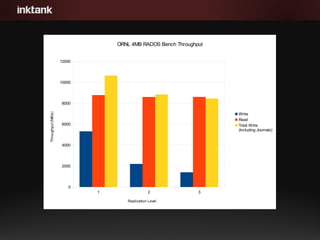
- 19. 1 2 3 0 2000 4000 6000 8000 10000 12000 ORNL 4MB RADOS Bench Throughput Write Read Total Write (Including Journals) Replication Level Throughput(MB/s)
- 20. This is an HPC site. What about CephFS? NOTE: CephFS is not production ready! (Marketing and sales can now sleep again)
- 21. 1 2 3 4 5 6 7 8 0 1000 2000 3000 4000 5000 6000 7000 ORNL 4M CephFS (IOR) Throughput Max Write Avg Write Max Read Avg Read Client Nodes (8 Processes Each) Throughput(MiB/s)
- 22. Hundreds of Cluster Configurations Hundreds of Tunable Settings Hundreds of Potential IO Patterns Too Many Permutations to Test Everything!
- 23. When performance is bad, how do you diagnose?
- 26. Collectl
- 30. perf
- 32. Where are we going from here?
- 33. More testing and Bug fixes! Erasure Coding Cloning from Journal Writes (BTRFS) RSOCKETS/RDMA Tiering
- 34. THANK YOU
Editor's Notes
- #2: Yes, that is a Cephalopod attacking a police box. Likeness to any existing objects, characters, or ideas is purely coincidental.
- #3: My Name is Mark and I work for a company called Inktank making an open source distributed storage system called Ceph. Before I started working for Inktank, I worked for the Minnesota Supercomputing Institute. My job was to figure out how to make our clusters run as efficiently as possible. A lot of researchers ran code on the clusters that didn't make good use of the expensive network fabrics those systems have. We worked to find better alternatives for these folks and ended up prototyping a high performance openstack cloud for research computing. The one piece that was missing was the storage solution. That's how I discovered Ceph.
- #4: I had heard of Ceph through my work for the Institute. The original development was funded by a high performance computing research grant at Lawrence Livermore National Laboratory. It had been in development since 2004, but it was only in around 2010 that I really started hearing about people starting to deploy storage with it. Ceph itself is an amazing piece of software. It lets you take commodity servers and turn them into a high performance, fault tolerant, distributed storage solution. It was designed to scale from the beginning and is made up from many distinct components.
- #5: The primary building blocks of Ceph are the daemons that run on the nodes in the cluster. Ceph is composed of OSDs that store data and monitors that keep track of cluster health and state. When using ceph as a distributed POSIX filesystem (CephFS), metadata servers may also be used. On top of these daemons are various APIs. Librados is the lowest level API that can be used to interact with rados directly at the object level. Librbd and libcephfs provide file-like API access to RBD and CephFS respectively. Finally, we have the high level block, object, and filesystem interfaces that make ceph such a versatile storage solution.
- #6: If you take one thing away from this talk, it should be that Ceph is designed to be distributed. Any number of services can run on any number of nodes. You can have as many storage servers as you want. Cluster monitors are distributed and use an election algorithm called PAXOS to avoid split-brain scenarios when servers fail. For S3 or swift compatible object storage, you can distribute requests across multiple gateways. When CephFS (Still Beta!) is used, the metadata servers can be distributed across multiple nodes and store metadata by distributing it across all of the OSD servers. When talking about data distribution specifically though, the crowning achievement in Ceph is CRUSH.
- #7: In many distributed storage systems there is some kind of centralized server that maintains an allocation table of where data is stored in the cluster. Not only is this a single point of failure, but it also can become a bottleneck as clients need to query this server to find out where data should be written or read. CRUSH does away with this. It is a hash based algorithm that allows any client to algorithmically determine where in the cluster data should be placed based on its name. Better yet, data is distributed across OSDs in the cluster pseudo-randomly. CRUSH also provides other benefits, like the ability to hierarchically define failure domains to ensure that replicated data ends up on different hardware.
- #8: From a performance perspective Ceph has a lot of benefits over many other distributed storage systems. There is no centralized server that can become a bottleneck for data allocation lookups. Data is well distributed across OSDs due to the psuedo-random nature of CRUSH. On traditional storage solutions a RAID array is used on each server. When a disk fails, the RAID array needs to be rebuilt which causes a hotspot in the cluster that drags performance down, and RAID rebuilds can last a long time. Because data in Ceph is pseudo-randomly distributed, healing happens cluster wide which dramatically speeds up the recovery process.
- #9: One of the challenges in any distributed storage system is what happens when you have hotspots in the cluster. If any one server is slow to fulfill requests, they will start backing up. Eventually a limit is reached where all outstanding requests will be concentrated on the slower server(s) starving the other faster servers and potentially degrading overall cluster performance significantly. Likewise distributed storage systems in general need a lot of concurrency to keep all of the servers and disks constantly working. From a performance perspective, another challenge regarding Ceph specifically is that Ceph works really hard to ensure data integrity. It does a full write of the data for every journal commit, does crc32 checksums for every data transfer, and regularly does background scrubs.
- #10: You guys have been patient so far but if you are anything like me then your attention span is starting to wear thin about now. Email or slashdot could be looking appealing. So let's switch things up a little bit. We've talked about why Ceph is conceptually so amazing, but what can it really deliver as far as performance goes? That was the question we asked about a year ago after seeing some rather lacklustre results on some of our existing internal test hardware. Our director of engineering told me to go forth and build a system that would give us some insight into how Ceph could perform on (what in my opinion would be) an ideal setup.
- #11: One of the things that we noticed from our previous testing is that some systems are harder to get working well than others. One potential culprit appeared to be that some expander backplanes may not behave entirely properly. For this system, we decided to skip expanders entirely and directly connect each drive in the system to it's own controller SAS lane. That means that with 24 spinning disks and 8 SSDs we needed 4 dual-port controllers to connect all of the drives. With so many disks in this system, we'd need a lot of external network connectivity and opted for a bonded 10GbE setup. We only have a single client which could be a bottleneck, but at that point we were just hoping to break 1GB/s to start out with which seemed feasible. So where we able to do it?
- #12: What you are looking at is a chart showing the write and read throughput on our test platform using our RADOS bench tool. This tool directly utilizes librados to write objects out as fast as possible and after writes complete, read them back. We're doing syncs and flushes between the tests on both the client and server and have measured the underlying disk throughput to make sure the results are accurate. What you are seeing here is that for writes, we not only hit 1GB/s, but are in fact hitting 2GB/s and maxing out the bonded 10GbE link. Reads aren't quite saturating the network but are coming pretty close. This is really good news because it means that with the right hardware, you can build Ceph nodes that can perform extremely well.
- #13: I like to show the previous slide because it makes a big impact and I get to feel vindicated regarding spending a bunch of our startup money on new toys. And who doesn't like seeing a single server able to write out 2GB/s+ of data? The problem though is that reading and writing out 4MB objects directly via librados isn't necessarily a great representation of how Ceph will really perform once you layer block or S3 storage on top of it.
- #14: Say for instance that you are using Ceph to provide block storage via RBD for openstack and have an application that does lots of 4K writes. Testing RADOS Bench with 4K objects might give you some rough idea of how RBD performs with small IOs, but it's also misleading. One of the things that you might not know is that RBD stores each block in a 4MB object behind the scenes. Doing 4K writes to 4MB objects results in different behavior that writing out distinct 4K objects themselves. Throw in the writeback cache implementation in QEMU RBD and things get complicated very fast. Ultimately you really do have to do the tests directly on RBD to know what's going on.
- #15: ...And we've done that. In alarming detail. What you are seeing here is a comparison of sequential and random 4K writes using a really useful benchmarking tool called fio. We are testing Kernel RBD and QEMU RBD at differing concurrency and IO depth values. What you may notice is that the scaling behavior and throughput looks very different in each case. QEMU RBD with the writeback cache enabled is performing much better. Interestingly RBD cache not only helps sequential writes, but seems to help with random writes too (especially at low levels of concurrency). This is one example of the kind of testing we do, but we have thousands of graphs like this exploring different workloads and system configurations. It's a lot of work!
- #16: We've gotten a lot of interesting results from our high performance test node and published quite a bit of those results in different articles on the web. Unfortunately we only have 1 of those nodes and our readers have started asking for are tests showing how performance scales across nodes. Do you remember what I said earlier about Ceph loving homogeneity and lots of concurrency? The truth is that the more consistently your hardware behaves, especially over time, the better your cluster is going to scale. Since I like to show good results instead of bad ones, lets take a look at an example of a cluster that's scaling really well.
- #17: About a year and a half ago Oak Ridge National Laboratory (ORNL) reached out to Inktank to investigate how Ceph performs on a high performance storage system they have in their lab. This platform is a bit different than the typical platform that we deploy Ceph on. It has a ton (over 400!) of drives configured in RAID LUNs that are in chassis connected to the servers via QDR Infiniband links. As a result, the back-end storage maxes out at about 12GB/s but has pretty consistent performance characteristics since there are so many drives behind the scenes. Initially the results ORNL was seeing were quite bad. We worked together with them to find optimal hardware settings and did a lot of tuning and testing. By the time we were done performance had improved quite a bit.
- #18: This chart shows performance on the ORNL cluster in it's final configuration using RADOS bench. Notice that throughput is scaling fairly linearly as we add storage nodes to the cluster. The blue and red lines represent write and read performance respectively. If you just look at the write performance, the results might seem disappointing. Ceph however, is doing full data writes to the journals to guarantee the atomicity of it's write operations. Normally in high performance situations we get around this by putting journals on SSDs, but this solution unfortunately doesn't have any. Another limitation is that the client network is using IPoIB, and on this hardware that means the clients will never see more than about 10GB/s aggregate throughput. Despite these limitations, we are scaling well and throughput to the storage chassis is pretty good!
- #19: All of the results I've shown so far have been designed to showcase how much throughput we can push from the client and are not using any kind of replication. On the ORNL hardware this is probably justifiable because they are using RAID5 arrays behind the scenes and for some solutions like HPC scratch storage, running without replication may be acceptable. For a lot of folks Ceph's seamless support for replication is what makes it so compelling. So how much does replication hurt?
- #20: As you might expect, replication has a pretty profound impact on write performance. Between doing journal writes and 3x replication, we see that client write performance is over 6 times slower than the actual write speed to the DDN chassis. What is probably more interesting is how the total write throughput changes. Going from 1x to 2x replication lowers the overall write performance by about 15-20%. When Ceph writes data to an OSD, the data must be written to the journal (BTRFS is a special case), and to the replica OSD's journal before the acknowledgement can be sent to the client. This not only results in extra data being written, but extra latency for every write. Read performance remains high regardless of replication.
- #21: So again I've shown a bunch of RADOS bench results, but that's not what people ultimately care about. For high performance computing, customers really want CephFS: Our distributed POSIX filesystem. Before we go on, let me say that our block and object layers are production ready, but CephFS is still in beta. It's probably the most complex interface we have on top of Ceph and there are still a number of known bugs. We've also done very little performance tuning, so when we started this testing we were pretty unsure about how it would perform.
- #22: To test CephFS, we settled on a tool that is commonly used in the HPC space called IOR. It coordinates IO on multiple client nodes using MPI and has many options that are useful for testing high performancre storage system s. When we first started testing CephFS, the performance was lower than we hoped. Through a series of tests, profiling, and investigation we were able to tweak the configuration to produce the results you see here. With 8 client nodes, writes are nearly as high as what we saw with RADOS bench, but reads have topped out lower. We are still seeing some variability in the results and have more tuning to do, but are happy with the performance we've been able to get so far given CephFS's level of maturity.
- #23: The results that we've shown thus far are only a small sample of the barrage of tests that we run. We have hundreds, if not thousands of graphs and charts showcasing performance of Ceph on different hardware, and serving different kinds of IO. Given how open Ceph is, this is ultimately going to be a losing battle. There are too many platforms, too many applications, and too many ways performance can be impacted to capture them all.
- #24: So given that you can't catch everything ahead of time, what do you do when cluster performance is lower than you expected? First, make a pot of coffee because you may be in for a long night. It's going to take some blood, sweat and tears, but luckily some other folks have paved the way and developed some very useful tools that can make the job a lot easier.
- #25: Ha, ran out of time. Slide notes end here. :)