














































































































Ad
More Related Content
Similar to Module 2.pdf (20)
Recently uploaded (20)


















Ad
Module 2.pdf
- 1. Module 2 Parallel and Distributed Programming Paradigm
- 2. 2 Parallel and Distributed Programming Paradigms Introduction, Parallel and distributed system architectures, Strategies for Developing Parallel and Distributed Applications, Methodical Design of Parallel and DistributedAlgorithms Cloud Software Environments - Google App Engine, Amazon AWS, Azure Open-Source tool
- 3. 3 Computing is the process to complete a given goal-oriented task by using a computer technology. Computing may include the design and development of software and hardware systems for a broad range of purposes, often consists of structuring, processing and managing any kind of information.
- 4. 4
- 5. Parallel computing systems are the simultaneous execution of the single task (split up and adapted) on multiple processes in order to obtain results faster. The idea is based on the fact that the process of solving a problem usually can be divided into smaller tasks (divide and conquer), which may be carried out simultaneously with some coordination . The term parallel computing architecture sometimes used for a computer with more than one processor (few to thousand), available for processing. 5
- 6. The recent multi-core processors (chips with more than one processor core ) are some commercial examples which bring parallel computing to the desktop. 6
- 7. 7
- 8. We define a distributed systems as one in which hardware or software components located at networked computers communicate and coordinate their actions only by passing messages. Education System in Current Scenario (Online class) 8
- 9. 9
- 10. 10
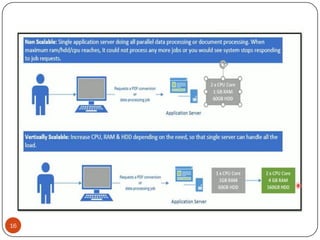
- 11. Scalability is the property of a system to handle a growing amount of work by adding resources to the system. A system is described as scalable if it will remain effective when there is a significant increase in the number of resources and the number of users. 11
- 12. 12
- 13. 13
- 14. 14
- 15. 15
- 16. 16
- 17. 17
- 18. 18
- 19. 19
- 20. 20
- 21. 21
- 22. 22
- 23. Taxonomy- from Greek taxis, meaning arrangement or division Michael J. Flynn (born May 20, 1934) is an American professor at Stanford University. Flynn proposed the Flynn’s taxonomy, a method of classifying digital computer architectures, in 1966. 23
- 24. Computer architecture is a set of rules and methods that describe the functionality, organization and implementation of computer. Computer architecture is concerned with balancing the performance, efficiency, cost and reliability of a computer system. 24
- 25. 25
- 26. 26
- 27. Instruction stream: The sequence of instructions from memory to the control unit. Data stream: The sequence of data from memory to control unit. 27
- 28. 28
- 29. A sequential computer which exploits no parallelism in either the instruction or data streams. Single control unit (CU) fetches single instruction stream (IS) from memory. The CU then generates appropriate control signals to direct single processing element (PE) to operate on single data stream (DS) i.e., one operation at a time. 29
- 30. Advantages It requires less power. There is no issue of complex communication protocol between multiple cores. Disadvantages The speed of SISD architecture is limited just like single-core processors. It is not suitable for larger applications 30
- 31. A single instruction operates on multiple different data streams. Instructions can be executed sequentially, such as by pipelining, or in parallel by multiple functional units. Throughput of the system can be increased by increasing the number of cores of the processor. Processing speed is higher than SISD architecture. There is complex communication between number of cores of processor. 31
- 32. Multiple instructions operate on one data stream. Systems with MISD stream have number of processing units performing different operations by executing instructions on the same data set. 32
- 33. Multiple autonomous processors simultaneously executing different instructions on different data. MIMD architecture include multi-core superscalar processors, and distributed systems, using either one shared memory space or a distributed memory space. 33
- 34. 34
- 35. Process:- A program in execution is called process Thread:- is the segment of a process, means a process can have multiple threads and these multiple threads are contained within a process. 35
- 36. 36
- 37. 37
- 38. 38
- 39. 39 In computer architecture, multithreading is the ability of a single CPU to provide multiple threads of execution concurrently, supported by the OS. Multithreading aims to increase utilization of a single core by using thread level parallelism. Multithreading allow for multiple requests to be satisfied simultaneously, without having to service requests sequentially.
- 40. 40 1. Responsiveness- If one thread completes its execution, then its output can be immediately returned. 2. Faster Context switch- context switch time between threads is lower compared to process context switch. Process context switching requires more overhead from the CPU. 3. Effective utilization of multiprocessor system- If we have multiple threads in a single process, then we can schedule multiple threads on multiple processor. This will make process execution faster. 4. Resource sharing- Resources like code, data and files can be shared among all threads within a process. Stack and register can’t be shared.
- 41. 41 5. Communication- Communication between multiple threads is easier, as compared to processes. 6. Enhanced throughput of the system- As each thread’s function is considered as one job, then the number of jobs completed per unit of time is increased, thus increasing the throughput of the system.
- 42. 42
- 43. 43 Shared memory is memory that simultaneously accessed by multiple programs with an intent to provide communication among them or avoid redundant copies. Shared memory is an efficient means of passing data between programs.
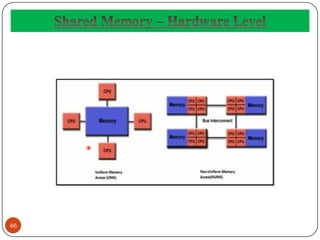
- 44. 44 In computer hardware, shared memory refers to a (typically large) block of Random Access Memory (RAM) that can be accessed by several different CPUs in a multiprocessor computer system.
- 45. 45 In shared memory systems following different approaches may followed:- Uniformly Memory Access (UMA):- all the processors share the physical memory uniformly (example-access time is same etc.) Non-uniform Memory Access (NUMA):-memory access time depends on the memory location relative to a processor. Cache-only Memory Architecture (COMA):- the local memories for the processors at each node is used as cache instead of as actual main memory.
- 46. 46
- 47. Advantage:- A shared memory system is relatively easy to program since all processors share a single view of data and the communication between processors can be as fast as memory accesses to a same location. Challenge:- The issue with shared memory system is that many CPUs need fast access to memory and will likely cache memory, which has two complications. o Access Time degradation- When several processors try to access the same memory location, it causes contention. o Lack of data coherence- whenever one cache is updated with information that may be used by other processors, the change needs to be reflected to the other processors otherwise the different processors will be working with incoherent data. 47
- 48. At software level, shared memory is either: o A method of inter-process communication (IPC) i.e. a way of exchanging data between programs running at the same time. Since both processes can access the shared memory area like regular working memory, this is a very fast way of communication. On the other hand, it is less scalable, and care must be taken to avoid issues if processes sharing memory are running on separate CPUs and the underlying architecture is not cache coherent. 48
- 49. Methodical Design of Parallel and Distributed Algorithms 49
- 50. The model of parallel algorithms are developed by considering a strategy for dividing the data and processing methods and also applying a suitable strategy to reduce interactions. Data Parallel Models Task graph model Work pool model Master slave model Producer consumer/pipeline model Hybrid model 50
- 51. In data parallel model, tasks are assigned to processes and each task performs similar types of operations on different data. Data parallelism is a consequence of single operations that is being applied on multiple data items. Data-parallel model can be applied on shared-address spaces and message- passing paradigms. 51
- 52. 52
- 53. In the task graph model, parallelism is expressed by a task graph. A task graph can be either trivial or nontrivial. In this model, the correlation among the tasks are utilized to promote locality or to minimize interaction costs. This model is enforced to solve problems in which the quantity of data associated with the tasks is huge compared to the number of computation associated with them. The tasks are assigned to help improve the cost of data movement among the tasks. Task has dependence with its predecessor and antecedent task 53
- 54. After completion of one task, the output is transferred to its dependent task. Dependent task executes only when its antecedent tasks finishes execution. 54
- 55. In work pool model, tasks are dynamically assigned to the processes for balancing the load. Therefore, any process may potentially execute any task. This model is used when the quantity of data associated with tasks is comparatively smaller than the computation associated with the tasks. There is no desired pre-assigning of tasks onto the processes. Pointers to the tasks are saved in a physically shared list, in a priority queue, or in a hash table or tree, or they could be saved in a physically distributed data structure. 55
- 56. 56
- 57. In the master-slave model, one or more master processes generate task and allocate it to slave processes.The tasks may be allocated beforehand if − the master can estimate the volume of the tasks, or a random assigning can do a satisfactory job of balancing load, or This model is generally equally suitable to shared-address- space or message-passing paradigms, since the interaction is naturally two ways. 57
- 58. 58
- 59. Care should be taken to assure that the master does not become a congestion point. It may happen if the tasks are too small or the workers are comparatively fast. The tasks should be selected in a way that the cost of performing a task dominates the cost of communication and the cost of synchronization. 59
- 60. It is also known as the producer-consumer model. Here a set of data is passed on through a series of processes, each of which performs some task on it. Here, the arrival of new data generates the execution of a new task by a process in the queue. This model is a chain of producers and consumers. Each process in the queue can be considered as a consumer of a sequence of data items for the process preceding it in the queue and as a producer of data for the process following it in the queue. 60
- 61. 61
- 62. A hybrid algorithm model is required when more than one model may be needed to solve a problem. A hybrid model may be composed of either multiple models applied hierarchically or multiple models applied sequentially to different phases of a parallel algorithm. 62
- 63. Parallel Random Access Machines (PRAM) is a model, which is considered for most of the parallel algorithms. Here, multiple processors are attached to a single block of memory. A PRAM model contains − A set of similar type of processors. All the processors share a common memory unit. Processors can communicate among themselves through the shared memory only. A memory access unit (MAU) connects the processors with the single shared memory. 63
- 64. 64
- 65. Here, n number of processors can perform independent operations on n number of data in a particular unit of time.This may result in simultaneous access of same memory location by different processors. To solve this problem, the following constraints have been enforced on PRAM model − Exclusive Read ExclusiveWrite (EREW) − Here no two processors are allowed to read from or write to the same memory location at the same time. Exclusive Read ConcurrentWrite (ERCW) − Here no two processors are allowed to read from the same memory location at the same time, but are allowed to write to the same memory location at the same time. 65
- 66. Concurrent Read ExclusiveWrite (CREW) − Here all the processors are allowed to read from the same memory location at the same time, but are not allowed to write to the same memory location at the same time. Concurrent Read ConcurrentWrite (CRCW) − All the processors are allowed to read from or write to the same memory location at the same time. 66
- 67. 67
- 68. Cloud Platforms 68 Cloud platforms is the delivery of different services through the internet. These resources include tools and applications like: Data storage Servers Databases Networking Software Cloud platforms are popular options that saves cost, increased productivity, speed and efficiency, performance and security.
- 69. Cloud Platforms examples 69 Amazon Cloud computing (AWS) Google Cloud Platform Azure Cloud Computing (Microsoft Azure) Hadoop Force.com and Salesforce.com
- 70. Amazon Cloud computing (AWS) 70
- 71. Amazon Cloud computing (AWS) 71 AWS Compute Services Elastic Compute Cloud (EC2) LightSail Elastic Beanstalk EKS (Elastic Container Service for Kubernetes) AWS Lambda AWS Migration Services DMS (Database Migration Services) SMS (Server Migration Services) Snowball
- 72. Amazon Cloud computing (AWS) 72 AWS Storage Services Amazon Glacier Amazon Elastic Block Store (EBS) AWS Storage Gateway AWS Database Services Amazon RDS Amazon DynamoDB Neptune Amazon RedShift
- 73. Amazon Cloud computing (AWS) 73 AWS Security Services IAM Inspector Certificate Manager WAF Cloud Directory KMS Shield
- 74. Microsoft Azure 74 AWS Analytics Services Athena CloudSearch ElasticSearch QuickSight Data Pipeline Management Services CloudWatch CloudFormation ServiceCatalog AWSAutoscaling
- 77. Azure Service-Compute 77 Cloud Service Service Fabric Functions
- 78. Azure Service-Networking 78 Azure CDN Express Route Virtual Network Azure DNS
- 79. Azure Service-Storage 79 Disk Storage Blob Storage File Storage Queue Storage
- 80. Azure Applications 80 Application development Testing Application hosting CreatingVirtual Machine Virtual hard drives
- 81. Azure Advantage 81 Storage Efficiency Cost effective Stability Security
- 82. Google Cloud Platform (GCP) 82 GCP is offered by Google It is a suite of cloud computing services that runs on the same infrastructure that google uses internally for its end users products provides a set of management tools it provides a series of cloud services : computing, data storage, data analytics, machine learning GCP is IaaS of google platform.
- 83. Features of GCP 83 Virtual Machines Local SSD Persistent Disks GPUAccelerators Global Load Balancing