




































































































Module 5 part-2 concurrency control in dbms
- 1. Concurrency control in DB(read for ur understanding) • Concurrency control techniques • Number of concurrency control techniques that are used to ensure the non interference or isolation property of concurrently executing transactions. • Most of these techniques ensure serializability of schedules. • using concurrency control protocols (sets of rules) that guarantee serializability.
- 2. 1)One important set of protocols—known as two- phase locking protocols—employs the technique of locking data items to prevent multiple transactions from accessing the items concurrently. • Locking protocols are used in some commercial DBMSs, but they are considered to have high overhead. 2) Another set of concurrency control protocols uses timestamps. • A timestamp is a unique identifier for each transaction, generated by the system. Timestamp values are generated in the same order as the transaction start times. Concurrency control protocols that use timestamp ordering are used to ensure serializability.
- 3. • 3)multiversion concurrency control protocols that use multiple versions of a data item. One multiversion protocol extends timestamp order to multiversion timestamp ordering and another extends timestamp order to two phase locking .
- 4. 4)In optimistic concurrency control techniques, also known as validation or certification techniques, no checking is done while the transaction is executing.Several concurrency control methods are based on the validation technique.These are sometimes called optimistic protocols. Then we discuss another protocol that is based on the concept of snapshot isolation, which can utilize techniques similar to those proposed in validation- based and multiversion methods; these protocols are used in a number of commercial DBMSs and in certain cases are considered to have lower overhead than locking-based protocols.
- 5. • Another factor that affects concurrency control is the granularity of the data items— that is, what portion of the database a data item represents. An item can be as small as a single attribute (field) value or as large as a disk block, or even a whole file or the entire database.
- 6. Module begins here Concurrency Control in Database • Concurrency Control is the management procedure that is required for controlling concurrent execution of the operations that take place on a database. • Without concurrency control so many problems are encountered.
- 7. • Purpose of Concurrency Control • To enforce Isolation (through mutual exclusion(Mutual exclusion is enforced using locking protocols (like 2PL) or timestamp ordering to prevent conflicts)) among conflicting transactions. • To preserve database consistency through consistency preserving execution of transactions. • To resolve read-write and write-write conflicts. • Example: • In concurrent execution environment if T1 conflicts with T2 over a data item A, then the existing concurrency control decides if T1 or T2 should get the A and if the other transaction is rolled-back or waits.
- 9. 5.1Two-Phase Locking Techniques for Concurrency Control • The concept of locking data items is one of the main techniques used for controlling the concurrent execution of transactions. • A lock is a variable associated with a data item in the database. • Generally there is a lock for each data item in the database. • A lock describes the status of the data item with respect to possible operations that can be applied to that item. • It is used for synchronizing the access by concurrent transactions to the database items. • A transaction locks an object before using it .When an object is locked by another transaction, the requesting transaction must wait.
- 10. 5.1.1Types of Locks and System Lock Tables Several types of locks are used in concurrency control. 1)binary locks, which are simple but are also too restrictive for database concurrency control purposes and so are not used much. 2)shared/exclusive locks—also known as read/write locks—which provide more general locking capabilities and are used in database locking schemes. 3) an additional type of lock called a certify lock, and it can be used to improve performance of locking protocols.
- 11. • 1. Binary Locks • A binary lock can have two states or values: locked and unlocked (or 1 and 0). • If the value of the lock on X is 1, item X cannot be accessed by a database operation that requests the item. • If the value of the lock on X is 0, the item can be accessed when requested, and the lock value is changed to 1 • Two operations, lock_item and unlock_item, are used with binary locking.
- 12. • A transaction requests access to an item X by first issuing a lock_item(X) operation • If LOCK(X) = 1, the transaction is forced to wait. • If LOCK(X) = 0, it is set to 1 (the transaction locks the item) and the transaction is allowed to access item X • When the transaction is through using the item, it issues an unlock_item(X) operation, which sets LOCK(X) back to 0 (unlocks the item) so that X may be accessed by other transactions • Hence, a binary lock enforces mutual exclusion on the data item.
- 13. Lock and unlock operations for binary locks. lock_item(X): B: if LOCK(X) = 0 (*item is unlocked*) then LOCK(X) ←1 (*lock the item*) else begin wait (until LOCK(X) = 0) and the lock manager wakes up the transaction); go to B end; ------------------------------------------------------------ unlock_item(X): LOCK(X) ← 0; (* unlock the item *) if any transactions are waiting then wakeup one of the waiting transactions;
- 14. • The lock_item and unlock_item operations must be implemented as indivisible units that is, no interleaving should be allowed once a lock or unlock operation is started until the operation terminates or the transaction waits. • In its simplest form, each lock can be a record with three fields: <Data_item_name,LOCK, Locking_transaction> plus a queue for transactions that are waiting to access the item
- 15. • If the simple binary locking scheme described here is used, every transaction must obey the following rules: • 1. A transaction T must issue the operation lock_item(X) before any read_item(X) or write_item(X) operations are performed in T. • 2. A transaction T must issue the operation unlock_item(X) after all read_item(X) and write_item(X) operations are completed in T. • 3. A transaction T will not issue a lock_item(X) operation if it already holds the lock on item X. • 4. A transaction T will not issue an unlock_item(X) operation unless it already holds the lock on item X.
- 16. Drawbacks of Binary Locks : • Binary locks are highly restrictive. Binary locks have only two states: locked (1) or unlocked (0). • Once a transaction locks an item, no other transaction — even for reading — can access it, which reduces concurrency drastically.As a result, they are not used commercially
- 17. 2. Shared/Exclusive (or Read/Write) Locks. • In this scheme called shared/exclusive or read/write locks there are three locking operations: read_lock(X), write_lock(X), and unlock(X). • A read-locked item is also called share-locked because other transactions are allowed to read the item, whereas a write-locked item is called exclusive-locked because a single transaction exclusively holds the lock on the item • If LOCK(X)=write-locked, the value of locking_transaction(s) is a single transaction that holds the exclusive (write) lock on X(that is if X is locked in exclusive (X) mode. Only one transaction can hold it.) • If LOCK(X)=read-locked, the value of locking transaction(s) is a list of one or more transactions that hold the shared (read) lock on X.(that is if X is locked in shared (S) mode. Multiple transactions can read it.)
- 21. • When we use the shared/exclusive locking scheme, the system must enforce the following rules: • 1. A transaction T must issue the operation read_lock(X) or write_lock(X) before any read_item(X) operation is performed in T.(Explanation(for your understanding) • Before reading X, T must acquire a shared (read) lock or a write (exclusive) lock. • Either lock ensures no conflicting writes happen while reading. • A write lock also allows reading, so either is acceptable. • ) • 2. A transaction T must issue the operation write_lock(X) before any write_item(X) operation is performed in T.( Writing requires exclusive access to prevent both read and write conflicts. • Only one transaction can hold a write lock on X, and no others may read or write it during that time. • )
- 22. • 3. A transaction T must issue the operation unlock(X) after all read_item(X) and write_item(X) operations are completed in T.(Once T is done accessing X, it must release the lock so that others can access it. • Delaying unlock(X) unnecessarily reduces concurrency.) • 4. A transaction T will not issue a read_lock(X) operation if it already holds a read (shared)lock or a write (exclusive) lock on item X.(If T already holds a read lock, there's no need to re-lock — it already has permission to read. • If T holds a write lock, it automatically includes read permission.)
- 23. Conversion (Upgrading, Downgrading) of Locks. • A transaction that already holds a lock on item X is allowed under certain conditions to convert the lock from one locked state to another.
- 24. Upgrading the lock • It is possible for a transaction T to issue a read_lock(X) and then later to upgrade the lock by issuing a write_lock(X) operation. • If T is the only transaction holding a read lock on X at the time it issues the write_lock(X) operation, the lock can be upgraded; otherwise, the transaction must wait.
- 25. Downgrading the Lock • It is also possible for a transaction T to issue a write_lock(X) and then later to downgrade the lock by issuing a read_lock(X) operation.
- 26. 5.1.2 Guaranteeing Serializability by Two-Phase Locking • "A transaction follows the two-phase locking protocol if all locking operations (read_lock, write_lock) happen before the first unlock operation.“ • Such a transaction can be divided into two phases: • Expanding or growing (first) phase, during which new locks on items can be acquired but none can be released • Shrinking (second) phase, during which existing locks can be released but no new locks can be acquired • That is You can keep acquiring locks (read/write) — this is the growing phase. • Once you release a lock (unlock), you cannot acquire any new locks — this is the shrinking phase.
- 27. • If lock conversion is allowed, then upgrading of locks (from read-locked to write-locked) must be done during the expanding phase, and downgrading of locks (from write-locked to read- locked) must be done in the shrinking phase. • Lock conversion • "If lock conversion is allowed, upgrading must be in growing phase; downgrading in shrinking phase." • Upgrading = going from read_lock → write_lock (must happen in growing phase). • Downgrading = going from write_lock → read_lock (must happen in shrinking phase).
- 28. • read_lock(X) • read_item(X) • -- Decides it needs to update X • write_lock(X) ← upgrading (must be in growing phase) • write_item(X) • unlock(X) ← enters shrinking phase •
- 29. Example Where 2PL is Violated • Transactions T1 and T2 in Figure in next page do not follow the two-phase locking protocol • because the write_lock(X) operation follows the unlock(Y) operation in T1, and similarly • the write_lock(Y) operation follows the unlock(X) operation in T2.
- 30. Transaction T1: Here, unlock(Y) happens before write_lock(X). That means: you released a lock and then tried to acquire a new one ⇒ ❌ violates 2PL. Transaction T2: Again, unlock(X) happens before write_lock(Y) ⇒ ❌ violates 2PL.
- 31. Explain?
- 32. A nonserializable schedule S that uses locks Schedule S (mix of T1 and T2) ⇒ Final: X = 50, Y = 50 ⇒ This does not match any serial order ⇒ ❌ Not Serializable
- 33. Solution: Fix Transactions to Follow 2PL Transactions T1′ and T2′, which are the same as T1 and T2 but follow the two-phase locking protocol. T1′ (fixed version of T1):Now all locks happen before any unlock ⇒ ✅ 2PL followed. T2′ (fixed version of T2):Same fix applied ⇒ ✅ 2PL followed.
- 34. • ✅ If all transactions follow 2PL, then: – The schedule is always serializable. – No need to manually check for serializability. • ⚠️ Disadvantage of 2PL: – Reduces concurrency. – One transaction may keep a lock longer than needed, blocking others. – You may need to lock items before you even use them.
- 35. 5.1.3Variations of two-phase locking (2PL). • Basic, Conservative, Strict, and Rigorous Two- Phase Locking • The technique just described is known as basic 2PL. • A variation known as conservative 2PL (or static 2PL) requires a transaction to lock all the items it accesses before the transaction begins execution. Conservative 2PL is a variation of the standard two-phase locking protocol. It requires a transaction to lock all data items it will need before it starts executing. If all locks can't be acquired immediately, the transaction waits and doesn't start.
- 36. • Why use Conservative 2PL? • Avoids deadlocks completely ✅ • Ensures serializability ✅ • But may reduce concurrency ❌ (because it might wait to get all locks before doing anything)
- 37. • read_lock(Y); • write_lock(X); -- Lock both before starting • read_item(Y); • read_item(X); • X := X + Y; • write_item(X); • unlock(Y); • unlock(X); • T1 locks Y and X before any read or write starts.
- 38. • read_lock(X); • write_lock(Y); -- Lock both before starting • read_item(X); • read_item(Y); • Y := X + Y; • write_item(Y); • unlock(X); • unlock(Y); • T2 locks X and Y at the start, before doing anything.
- 39. • Strict 2PL: • In this variation, a transaction T does not release any of its exclusive (write) locks until after it commits or aborts. • No other transaction can read or write an item that is written by T unless T has committed.
- 40. • A more restrictive variation of strict 2PL is rigorous 2PL. • In this variation, a transaction T does not release any of its locks (exclusive or shared) until after it commits or aborts.
- 41. 5.1.4Dealing with Deadlock and Starvation • The use of locks can also cause two additional problems: • Deadlock and Starvation. Deadlock occurs when each transaction T in a set of two or more transactions is waiting for some item that is locked by some other transaction T′ in the set. Hence,each transaction in the set is in a waiting queue, waiting for one of the other transactions in the set to release the lock on an item. But because the other transaction is also waiting, it will never release the lock.
- 42. Example • The two transactions T1′ and T2′ are deadlocked in a partial schedule; T1′ is in the waiting queue for X, which is locked by T2′, whereas T2′ is in the waiting queue for Y, which is locked by T1′. • Neither T1′ nor T2′ nor any other transaction can access items X and Y.
- 43. • T1′ holds a read lock on Y and wants a write lock on X • T2′ holds a read lock on X and wants a write lock on Y • Each transaction is waiting for a lock held by the other, and neither can proceed — this is a classic deadlock.
- 44. Deadlock Prevention Protocols • One way to prevent deadlock is to use a deadlock prevention protocol. • (1)One deadlock prevention protocol,which is used in Conservative 2PL (or static 2PL) requires a transaction to lock all the items it accesses before the transaction begins execution. • if any of the items cannot be obtained, none of the items are locked. • The transaction waits and then tries again to lock all the items it needs. • Obviously, this solution further limits concurrency.
- 45. • (2)A second protocol, which also limits concurrency, involves ordering all the items in the database and making sure that a transaction that needs several items will lock them according to that order. • This requires that the programmer (or the system) is aware ofthe chosen order of the items, which is also not practical in the database context • Both approaches impractical.
- 46. • (3)A number of other deadlock prevention schemes have been proposed that make a decision about what to do with a transaction involved in a possible deadlock situation: • Should it be blocked and made to wait or should it be aborted, or should the transaction preempt and abort another transaction? • Some of these techniques use the concept of transaction timestamp TS(T′), which is a unique identifier assigned to each transaction.
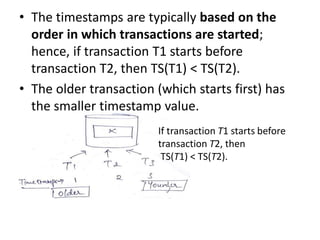
- 47. • The timestamps are typically based on the order in which transactions are started; hence, if transaction T1 starts before transaction T2, then TS(T1) < TS(T2). • The older transaction (which starts first) has the smaller timestamp value. If transaction T1 starts before transaction T2, then TS(T1) < TS(T2).
- 48. Protocols based on a timestamp • Wait-die • Wound-wait • Suppose that transaction Ti tries to lock an item X but is not able to because X is locked by some other transaction Tj with a conflicting lock. • The rules followed by these schemes are: • Wait-die. If TS(Ti) < TS(Tj), then (Ti older than Tj) Ti is allowed to wait; otherwise (Ti younger than Tj) abort Ti (Ti dies) and restart it later with the same timestamp. • That is • (If an older transaction requests a lock held by a younger one → it waits. • If a younger transaction requests a lock held by an older one → it is aborted (dies) and restarted with the same timestamp. • )
- 49. • Example: Wait-Die • Let’s assume: • TS(T1) = 5 (T1 is older) • TS(T2) = 10 (T2 is younger) • Scenario A: • T1 wants to write X, but X is already locked by T2. • → Since T1 is older, T1 is allowed to wait. • Scenario B: • T2 wants to write X, but X is already locked by T1. • → Since T2 is younger, T2 is aborted (dies) and will restart with TS = 10.
- 50. • Wound-wait. If TS(Ti) < TS(Tj), then (Ti older than Tj) abort Tj (Ti wounds Tj) and restart it later with the same timestamp; otherwise (Ti younger than Tj) Ti is allowed to wait. • That is • If an older transaction requests a lock held by a younger one → it wounds (aborts) the younger one. • If a younger transaction requests a lock held by an older one → it waits.
- 51. • Example: Wound-Wait • Again: • TS(T1) = 5 (older) • TS(T2) = 10 (younger) • Scenario A: • T1 wants to write X, but X is already locked by T2. • → T1 is older, so T1 wounds T2 (T2 is aborted and restarted with TS=10). T1 proceeds. • Scenario B: • T2 wants to write X, but X is already locked by T1. • → T2 is younger, so T2 waits.
- 52. • Both schemes end up aborting the younger of the two transactions (the transaction that started later) that may be involved in a deadlock, assuming that this will waste less processing. • It can be shown that these two techniques are deadlock-free, since in wait-die,transactions only wait for younger transactions so no cycle is created. • Similarly, in wound-wait, transactions only wait for older transactions so no cycle is created.
- 53. • (4)Another group of protocols that prevent deadlock do not require timestamps. • These include the • No waiting (NW) and • cautious waiting (CW) algorithms No waiting algorithm, • if a transaction is unable to obtain a lock, it is immediately aborted and then restarted after a certain time delay without checking whether a deadlock will actually occur or not. • no transaction ever waits, so no deadlock will occur • this scheme can cause transactions to abort and restart needlessly
- 54. cautious waiting • try to reduce the number of needless aborts/restarts. • Suppose that transaction Ti tries to lock an item X but is not able to do so because X is locked by some other transaction Tj with a conflicting lock. • The cautious waiting rules are as follows: • If Tj is not blocked (i.e., it is actively running and not waiting for any other item) → Allow Ti to wait for Tj to release X. • If Tj is blocked (i.e., it's already waiting for some other transaction) → Abort Ti immediately and restart it later. • It can be shown that cautious waiting is deadlock-free, because no transaction will ever wait for another blocked transaction.
- 55. Deadlock Detection. • A second, more practical approach to dealing with deadlock is deadlock detection,where the system checks if a state of deadlock actually exists. • A simple way to detect a state of deadlock is for the system to construct and maintain a wait-for graph. • One node is created in the wait-for graph for each transaction that is currently executing. • Whenever a transaction Ti is waiting to lock an item X that is currently locked by a transaction Tj, a directed edge (Ti Tj) is created in the wait-for graph. • When Tj releases the lock(s) on the items that Ti was waiting for, the directed edge is dropped from the wait- for graph. • We have a state of deadlock if and only if the wait-for graph has a cycle.
- 56. One problem with this approach is the matter of determining when the system should check for a deadlock. • 1)One possibility is to check for a cycle every time an edge is added to the wait for graph, but this may cause excessive overhead. • 2)Periodic Checking • Check for cycles every X milliseconds or seconds. • 3)Threshold-Based Checking • Only run deadlock detection if: – The number of waiting transactions exceeds a threshold value. • 4)Timeout-Based Approach • If a transaction has been waiting too long (e.g., 5 seconds), assume it might be part of a deadlock. • Either run a check or just abort the transaction.
- 57. • If the system is in a state of deadlock, some of the transactions causing the deadlock must be aborted. • Choosing which transactions to abort is known as victim selection. • The algorithm for victim selection should generally avoid selecting transactions that have been running for a long time and that have performed many updates, and it should try instead to select transactions that have not made many changes (younger transactions).
- 58. Timeouts • Another simple scheme to deal with deadlock is the use of timeouts. • This method is practical because of its low overhead and simplicity. • In this method, if a transaction waits for a period longer than a system-defined timeout period, the system assumes that the transaction may be deadlocked and aborts it regardless of whether a deadlock actually exists or not.
- 59. Starvation. Another problem that may occur when we use locking is starvation, which occurs when a transaction cannot proceed for an indefinite period of time while other transactions in the system continue normally. • This may occur if the waiting scheme for locked items is unfair, giving priority to some transactions over others. • One solution for starvation is to have a fair waiting scheme, such as using a firstcome- first-served queue; transactions are enabled to lock an item in the order in which they originally requested the lock. • Another scheme allows some transactions to have priority over others but increases the priority of a transaction the longer it waits, until it eventually gets the highest priority and proceeds. • Starvation can also occur because of victim selection if the algorithm selects the same transaction as victim repeatedly, thus causing it to abort and never finish execution. • The algorithm can use higher priorities for transactions that have been aborted multiple times to avoid this problem.
- 60. 5.2 Concurrency Control Based on Timestamp Ordering • Timestamp ordering is a concurrency control method used in databases to ensure that transactions execute in a serializable order, based on timestamps assigned to them. • Unlike Two-Phase Locking (2PL), it does not use locks, so deadlocks cannot occur.
- 61. • What is a Timestamp? • A timestamp is a unique identifier given to each transaction when it starts. • Denoted as TS(T) for a transaction T. • Typically assigned in the order transactions arrive. • Two ways to generate timestamps: – Counter-based (e.g., 1, 2, 3, ...) – System clock time (current time ensures uniqueness)
- 62. The Timestamp Ordering Algorithm • The idea for this scheme is to order the transactions based on their timestamps. • Timestamp Ordering ensures that transactions are executed in a serializable manner, consistent with the timestamp assigned to each transaction. This means: • If Transaction T1 has a smaller timestamp than Transaction T2, then T1 should appear before T2 in the equivalent serial schedule. • The system ensures this order even if operations interleave.
- 63. • The algorithm allows interleaving of transaction operations, but it must ensure that for each pair of conflicting operations in the schedule, the order in which the item is accessed must follow the timestamp order. • If this order is violated, then transaction T is aborted and resubmitted to the system as a new transaction with a new timestamp.
- 64. • The algorithm enforces that conflicting operations (reads/writes on the same data item) happen in timestamp order. Conflicts arise between: • Read and Write on the same item. • Write and Read on the same item. • Write and Write on the same item.
- 65. • How the TO Protocol Works: • Each data item X maintains: • read_TS(X): Largest timestamp of any transaction that successfully read X. • write_TS(X): Largest timestamp of any transaction that successfully wrote X.
- 66. • Now consider Transaction T with timestamp TS(T) trying to: • Read X: – If TS(T) < write_TS(X) → Reject(abort) T (T is too old; a newer write happened). – Else → Allow the read, and update read_TS(X) if needed. • Write X: – If TS(T) < read_TS(X) → Reject T (A newer transaction has already read the value). – If TS(T) < write_TS(X) → Reject T (A newer transaction already wrote the value). – Else → Allow the write and update write_TS(X).
- 67. • Example Step-by-Step: • Initial Setup: • Assume: – Transaction T1 → Timestamp TS(T1) = 5 – Transaction T2 → Timestamp TS(T2) = 10 – Data item X: • read_TS(X) = 0 • write_TS(X) = 0 • Step 1: T2 writes to X • TS(T2) = 10 • Check: – TS(T2) < read_TS(X)? → 10 < 0 ❌ → No – TS(T2) < write_TS(X)? → 10 < 0 ❌ → No • ✅ So, T2 is allowed to write X • Update: – write_TS(X) = 10
- 68. • State now: • read_TS(X) = 0 • write_TS(X) = 10 • Step 2: T1 tries to read X • TS(T1) = 5 • Check: – TS(T1) < write_TS(X)? → 5 < 10 ✅ → Yes • ❌ T1 is too old and tries to read a version of X that was written by a transaction with a higher timestamp (T2). • So, T1 is aborted to maintain the serial order.
- 69. • Transactions should only see the effects of transactions that came before them (in Timestamp order). • TO protocol prevents reading into the future or writing into the past. • Why is T1 Aborted? • Even though T1 started earlier, it tries to read a value written by T2 (which logically started later). If this were allowed, it would violate the logical timestamp order, leading to an inconsistent, non- serializable schedule.
- 70. • 5. Drawback: Cascading Rollback • If a transaction is aborted, other transactions that used its written data must also be rolled back. This leads to cascading rollbacks, making basic TO non-recoverable.
- 71. • Solution: Strict TO or Strict Schedules • To prevent cascading rollbacks: • Use Strict Timestamp Ordering or Strict Schedules: – Delay both reads and writes until the writing transaction commits – So, T2 cannot read from T1 until T1 is committed – Prevents any other transaction from depending on an uncommitted transaction
- 72. • What is Strict Timestamp Ordering? • Strict TO is an enhanced version of the Basic Timestamp Ordering (TO) protocol. • It ensures two things: • ✔ Conflict-serializability (like basic TO) • ✔ Strictness: No transaction can read or write a data item written by another uncommitted transaction • Goal: Prevent dirty reads/writes and cascading rollbacks
- 74. • Example • Let’s say we have: • Transaction T1: TS(T1) = 100 (older) • Transaction T2: TS(T2) = 200 (younger) • Step-by-step Execution: • T1 writes to X: – write_TS(X) = 100 (from T1) – T1 is still running (not committed yet) • T2 tries to read X: – TS(T2) = 200 > write_TS(X) = 100 – T2 must wait until T1 commits or aborts • This avoids reading uncommitted data (dirty read) • Once T1 commits, T2 is allowed to proceed with read(X).
- 75. • Purpose • Prevents cascading rollbacks • Ensures that a transaction never reads or overwrites data from another uncommitted transaction
- 76. • Why Strict TO Prevents Deadlock • In Strict Timestamp Ordering: • Only younger transactions wait for older ones. • So TS(T2) > TS(T1) ⇒ T2 can wait for T1, but T1 will never wait for T2. • This one-directional waiting (younger → older only) means cycles are impossible.
- 77. • What is Thomas's Write Rule? • It is a relaxed version of Basic Timestamp Ordering (TO) that: • Reduces unnecessary aborts of transactions • Allows more schedules than Basic TO • But does not guarantee conflict- serializability (still maintains serializability in general)
- 78. • Rule 1: • If TS(T)< read_TS(X), then abort and roll back T and reject the operation. • Rule 2: • If TS(T)< write_TS(X), then do not execute the write operation but continue processing. • Rule 3: • If neither (1) nor (2) is true, then execute the write_item(X) operation of T and set write_TS(X) = TS(T).
- 79. Rule Condition Action 1 read_TS(X) > TS(T) ❌ Abort & Rollback T 2 write_TS(X) > TS(T) ✅ Ignore write, continue T 3 Otherwise ✅ Perform write, set write_TS(X) = TS(T)
- 80. 5.3 Multiversion Concurrency Control(MVCC) • These protocols for concurrency control keep copies of the old values of a data item when the item is updated (written); • they are known as multiversion concurrency control because several versions (values) of an item are kept by the system. • When a transaction requests to read an item, the appropriate version is chosen.
- 81. • An obvious drawback of multiversion techniques is that more storage is needed to maintain multiple versions of the database items.
- 82. Multiversion Technique Based on Timestamp Ordering(MVTO) • Based on timestamps: Every transaction is assigned a unique timestamp when it begins. • In this method, several versions X1, X2, ..., Xk of each data item X are maintained. • For each version, the value of version Xi and the following two timestamps are kept: – write_TS(Xi): Timestamp of the transaction that wrote this version. – read_TS(Xi): Latest timestamp of any transaction that read this version. • Version selection: – When a transaction reads a data item, it reads the latest version written by a transaction with a smaller timestamp. – When a transaction writes, the system checks whether any newer transaction has already read an older version. If yes, the write is rejected (to maintain consistency).
- 83. Multiversion Two-Phase Locking(MV2PL) • Combines MVCC and 2PL: Uses multiple versions of data along with locking mechanisms. • Locks: – Transactions acquire locks (shared or exclusive) on data items. – Read operations read the appropriate version. – Write operations create new versions after acquiring the proper locks. • Phases: – Growing phase: Transactions acquire locks and create versions. – Shrinking phase: All locks are released.
- 84. 5.4Validation (Optimistic) Concurrency Control Techniques • Optimistic Concurrency Control (OCC) is a concurrency control technique based on the assumption that conflicts are rare. • Instead of preventing conflicts using locks, OCC allows transactions to execute without any restrictions and checks for conflicts only at the end, during a validation phase. • That is In optimistic concurrency control techniques, also known as validation or certification techniques, no checking is done while the transaction is executing. • In this scheme, updates in the transaction are not applied directly to the database items until the transaction reaches its end.
- 87. • If serializability is not violated, the transaction is committed and the database is updated from the local copies; • otherwise, the transaction is aborted and then restarted later.
- 88. Granularity of Data Items and Multiple Granularity Locking • Factor that affects concurrency control is the granularity of the data items—that is, what portion of the database a data item represents. • An item can be as small as a single attribute (field) value or as large as a disk block, or even a whole file or the entire database.
- 89. • All concurrency control techniques assume that the database is formed of a number of named data items. A database item could be chosen to be one of the following: • A field value of a database record:A field is a single attribute or column value within a record • A database record: A record is a single row in a table, consisting of multiple fields. • A disk block(page):A block or page is a unit of data storage on disk, typically containing multiple records. • A whole file:Refers to an entire file that stores all records of a table (e.g., the whole Student table stored in one file). • The whole database • The granularity can affect the performance of concurrency control and recovery
- 90. Granularity Level Considerations for Locking • The size of data items is often called the data item granularity. • Fine granularity refers to small item sizes, whereas coarse granularity refers to large item sizes.
- 91. • For example, if the data item size is a disk block, a transaction T that needs to lock a record B must lock the whole disk block X that contains B because a lock is associated with the whole data item (block). Now, if another transaction S wants to lock a different record C that happens to reside in the same block X in a conflicting lock mode, it is forced to wait. • (that is If T wants to update record B, and locking is at block level, it must lock the whole block. • If S wants record C in the same block, it must wait — even if there's no actual conflict.) If the data item size was a single record, transaction S would be able to proceed, because it would be locking a different data item (record).
- 92. • The smaller the data item size is, the more the number of items in the database. • Because every item is associated with a lock, the system will have a larger number of active locks to be handled by the lock manager. More lock and unlock operations will be performed, causing a higher overhead
- 93. • The best item size depends on the types of transactions involved. • If a typical transaction accesses a small number of records, it is advantageous to have the data item granularity be one record • On the other hand, if a transaction typically accesses many records in the same file, it may be better to have block or file granularity so that the transaction will consider all those records as one (or a few) data items
- 94. Multiple Granularity Level Locking • Since the best granularity size depends on the given transaction, it seems appropriate that a database system should support multiple levels of granularity, where the granularity level can be different for various mixes of transactions • Figure 22.7 shows a simple granularity hierarchy with a database containing two files,each file containing several disk pages, and each page containing several records. • This can be used to illustrate a multiple granularity level 2PL protocol, where a lock can be requested at any level
- 95. Figure 22.7 A granularity hierarchy for illustrating multiple granularity level locking
- 96. • To make multiple granularity level locking practical, additional types of locks, called intention locks, are needed • There are three types of intention locks: • 1. Intention-shared (IS) indicates that one or more shared locks will be requested on some descendant node(s). (IS on f1 means: you’re planning to read somewhere under f1). • 2. Intention-exclusive (IX) indicates that one or more exclusive locks will be requested on some descendant node(s). IX on f1 means: you’re planning to write under f1, • 3. Shared-intention-exclusive (SIX) indicates that the current node is locked in shared mode but that one or more exclusive locks will be requested on some descendant node(s).(I'm taking a shared lock on this node (I want to read it), and I plan to take exclusive locks (write) on some of its descendants.")
- 97. Why Intention Locks Are Needed • Situation Without Intention Locks: • T2 wants to read r1nj, so it places a shared lock on r1nj. • Now, T1 wants to update the entire file f1, so it requests an exclusive (X) lock on f1. • Problem: • The lock manager now has to check every single record under f1 (all pages, all records) to see if any locks exist. • This is slow and inefficient, especially in large databases.
- 98. Situation With Intention Locks • T2 reads r1nj (a record): • It places locks on the full path: – IS(db) – IS(f1) – IS(p1n) – S(r1nj) ✅ (actual shared lock on record) I plan to read something under f1, so I’m declaring that intention early.” • Now, T1 wants to write to entire f1: • It requests: – X(f1) (exclusive lock on the whole file)
- 99. • Conflict Detection: • The lock manager immediately sees that f1 is already locked in IS mode (by T2). • It knows someone is reading something under f1. • So, T1’s X(f1) request cannot proceed. • T1 is made to wait, and conflict is detected efficiently — without checking all descendants!
- 100. • Lock Compatibility Matrix Held by → / Requested by ↓ IS IX S SIX X IS ✔ ✔ ✔ ✔ ❌ IX ✔ ✔ ❌ ❌ ❌ S ✔ ❌ ✔ ❌ ❌ SIX ✔ ❌ ❌ ❌ ❌ X ❌ ❌ ❌ ❌ ❌ ✔️ Compatible = Lock can be granted ❌ Not compatible = Lock must wait How to Use This Matrix 1)Suppose T1 holds S(f1) and T2 requests IX(f1) → Check the cell: S vs IX = ❌ → So T2 must wait. 2)If T1 holds IS(db) and T2 requests IX(db) → IS vs IX = ✔ → So T2 can proceed.
- 101. The multiple granularity locking (MGL) protocol consists of the following rules: • Follow lock compatibility matrix (e.g., S & IS are compatible; X & IS are not). • Start from root (db) and move down. • To get S/IS on a node, parent must be locked in IS/IX. • To get X/IX/SIX on a node, parent must be locked in IX or SIX. • Two-phase locking (2PL) must still be followed. • You can unlock a node only when none of its children are locked.