Module 6: Ensemble Algorithms
0 likes92 views

This document discusses various ensemble machine learning algorithms including bagging, boosting, and random forests. It explains that ensemble approaches average the predictions of multiple models to improve performance over a single model. Bagging trains models on random subsets of data and averages predictions. Random forests build on bagging by using random subsets of features to de-correlate trees. Boosting iteratively trains weak learners on weighted versions of the data that focus on previously misclassified examples. The document provides examples and comparisons of these ensemble techniques.




































































Ad
More Related Content
What's hot (18)
Similar to Module 6: Ensemble Algorithms (20)
















Ad
Recently uploaded (20)




















Ad
Module 6: Ensemble Algorithms
- 2. This course content is being actively developed by Delta Analytics, a 501(c)3 Bay Area nonprofit that aims to empower communities to leverage their data for good. Please reach out with any questions or feedback to [email protected]. Find out more about our mission here. Delta Analytics builds technical capacity around the world.
- 4. ❏ Ensemble approaches ❏ Bootstrap ❏ Bagging ❏ Random forest ❏ Boosting Module Checklist:
- 5. What we’ve done: Exploratory Analysis Linear Regression (our first model) Decision Trees (our second model) Up next: Even more models! Where are we? Question Exploratory Analysis Modeling Phase Validation Phase Source: Udacity - Model Building and Validation Building intuition Expanding our toolkit }
- 6. Recap: In this example, we predict Sam’s weekend activity using decision rules trained on historical weekend behavior. How much $$ do I have? Raining? Girlfriend? NY Concert! Clubbing!Walk in the park!Movie! Y Y NN Decision Tree Task Defining f(x) The decision tree f(x) predicts the value of a target variable by learning simple decision rules inferred from the data features. Our most important predictive feature is Sam’s budget. How do we know this? Because it is the root node. Source: Friedman, Hastie, and Tibshirani. The elements of statistical learning. Vol. 1. Springer, Berlin: Springer series in statistics, 2001.
- 7. Decision Tree Task Recap: You are Sam’s weekend planner. What should she do this weekend? Let’s get this weekend started! You’ve run a decision tree for Sam, and now you’ve got a model. But does it work well? As always, we use our test data to check our model, before we tell him what to do with this weekend.
- 8. Performance Ability to generalize to unseen data Our goal in evaluating performance is to find a sweet spot between overfitting and underfitting. Recall our discussion of over and underfitting in previous modules: Underfit Overfit Sweet spot Our most important goal is to build a model that will generalize well to unseen data.
- 9. Performance How do we measure underfitting/ overfitting? Figuring out if you are overfitting or underfitting involves knowing how to compare you train to to your test results. Underfit Overfit Sweet spot Training R2 Relationship Test R2 Condition high > low high ~ high Sweet spot low ~ low low < high never happens Overfitting underfitting
- 10. How much $$ do I have? Raining? Partner? < $50 Concert! Clubbing!Walk in the park!Movie! Y Y NN >= $50 n=83 n=19 n=50 n=33 n=3n=31 Let’s see how this works in practice. Firstly, we train our model f(x) using training data. n=30 n=104 train: 83 test: 21 Performance Model evaluation 1. Split data into train/test 2. Run model on train data 3. Test model on test data Model error = Train True Y - Train Y*
- 11. How much $$ do I have? Raining? Partner? < $50 Concert! Clubbing!Walk in the park!Movie! Y Y NN 1. Split data into train/test 2. Run model on train data 3. Test model on test data Remember generalization error? Review Module 4! >= $50 Now, we use our f(x) developed using training data to score unseen test data. n=104 train: 83 test: 21 Performance Model evaluation Output: Test Y* Inputs (x’s) TrueY Test True Y Generalization error = Test True Y - TestY*
- 12. The holdout set method is great - it lets us test our model on unseen data, the most important metric for any model. However, one potential problem arises: What if our test dataset, even though it was picked randomly, is unrepresentative of the data? E.g. We managed to pick the 21 weekends in Sam’s dataset where he had just broken up with his girlfriend, or failed a test, or fought with his friend, and ended up staying home. Then our test set would say that our model is awful and didn’t predict Y* accurately. There are some shortcomings associated with the hold out method as a way to do model evaluation. Performance Model evaluation n=104 train: 83 test: 21 We can do better...
- 13. A powerful way to overcome any issues with a biased single holdout is to run the model many times. If a single run of your model is one expert opining on the data, an ensemble approach gathers a crowd of experts. Source: Fortmann-Roe, Accurately Measuring Model Prediction Error. http://scott.fortmann-roe.com/docs/MeasuringError.html VS. Our Model Our Model + model friends Performance Model evaluation
- 14. Ensemble approaches 1. Bootstrapping 2. Bagging 3. Random forests Central concept: teamwork!
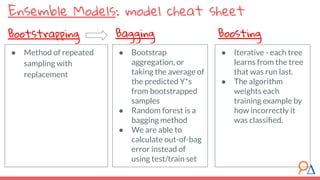
- 15. ● Bootstrap aggregation, or taking the average of the predicted Y*s from bootstrapped samples ● Random forest is a bagging method ● We are able to calculate out-of-bag error instead of using test/train set Ensemble Models: model cheat sheet ● Method of repeated sampling with replacement Bootstrapping Bagging ● Iterative - each tree learns from the tree that was run last. ● The algorithm weights each training example by how incorrectly it was classified. Boosting
- 16. Bootstrapping, bagging, random forests and boosting all leverage a crowd of experts. Bootstrapping Bagging Random Forest Boosting
- 17. Bootstrapping is a resampling method that takes random samples with replacement from whole dataset. n=104 train: 83 test: 21 Instead of only using one holdout, we repeatedly construct different holdouts from the dataset. Bootstrapping Example of a single holdout split. Bootstrapping repeats this many, many times. We set the number of holdouts as a hyperparameter.
- 18. Bagging is an implementation of bootstrapping: it involves taking the average of the random samples drawn by bootstrapping. Bootstrapping Bagging Random Forest Boosting
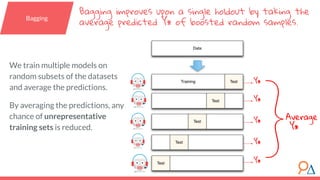
- 19. We train multiple models on random subsets of the datasets and average the predictions. By averaging the predictions, any chance of unrepresentative training sets is reduced. Y* Y* Y* Y* Y* }Average Y* Bagging improves upon a single holdout by taking the average predicted Y* of boosted random samples. Bagging
- 20. Which do you think does a better job of estimating true Y? Y* Y* Y* Y* Y* Average Y* n=104 train: 83 train: 83 train: 83 train: 83 train: 83 } train: 83 Y* Bagging Normal holdout vs. n=104
- 21. In Sam’s case, we still have the problem unrepresentative train dataset. However, now that we’re taking different train sets and averaging them, the chance of an unrepresentative training set over-influencing the Y* is reduced. Y* Y* Y* Y* Y* }Average Y* train: 83 train: 83 train: 83 train: 83 train: 83 Bagging tends to always outperform a single holdout. Bagging n=104
- 22. Out-of-Bag Score Another amazing benefit of using bagging algorithms is the out-of-bag score. The out-of-bag score is the error rate of observations not used in each decision tree. Source: https://www.quora.com/What-is-the-out-of-bag-error-in-Random-Forests Bagging Out-of-bag score Y* Y* Y* Y* Y* train: 83 train: 83 train: 83 train: 83 train: 83 n=104 test = 104-83 = 21 test = 21 test = 21 test = 21 test = 21
- 23. Out-of-Bag Score The out-of-bag score is the error rate of observations not used in each decision tree. Why it matters: There is empirical evidence to show that the out-of-bag estimate is as accurate as using a test set of the same size as the training set. Therefore, using the out-of-bag error estimate removes the need for a set-aside test set. Source: Breiman, 1996 Bagging Out-of-bag score Y* Y* Y* Y* Y* train: 83 train: 83 train: 83 train: 83 train: 83 n=104 test = 104-83 = 21 test = 21 test = 21 test = 21 test = 21
- 24. Out-of-Bag Score Out-of-bag score can be calculated for any bootstrap aggregation method, including: - Random forest - Bagging - Boosting Bagging Out-of-bag score Y* Y* Y* Y* Y* train: 83 train: 83 train: 83 train: 83 train: 83 n=104 test = 104-83 = 21 test = 21 test = 21 test = 21 test = 21 Is bagging perfect? What are some potential tradeoffs?
- 25. One key trade off is that training and assessing the performance of every additional holdout costs us computational power and time. The computational cost is driven by the data sample size and number of holdouts. There are a few key limitations to bagging. Y* Y* Y* Y* Y* }Average Y* Bagging
- 26. Subsets of the same data may split on the same features and result in very similar predictions. How much $$ do I have? Raining? Girlfriend? < $50 Concert! Clubbing!Walk in the park!Movie! Y Y NN >= $50 A key limitation of bagging is that it may yield correlated (or very similar) trees. Bagging How much $$ do I have? Raining? Girlfriend? < $50 Concert! Clubbing!Walk in the park!Movie! Y Y NN >= $50 How much $$ do I have? Raining? Girlfriend? < $50 Concert! Clubbing!Walk in the park!Movie! Y Y NN >= $50
- 27. Many identical trees becomes an echo chamber of overfitted trees that repeatedly yields a similar Y* value, and repeatedly yields the same important features. This gives us false confidence in our results. Y* Y* Y* Y* Y* }Average Y* n=104 train: 83 train: 83 train: 83 train: 83 train: 83 We can do better .... You’re doing “great”! Budget is the best feature, believe me Correlated trees may give us false confidence since they repeatedly yield the same features. Bagging
- 28. Random forest improves on bagging’s tendency to result in correlated trees. Bootstrapping Bagging Random Forest Boosting
- 29. Random forest improves upon bagging by only considering a random subset of features. Source: https://dimensionless.in/introduction-to-random-forest/ Random forest is an implementation of bagging. It improves on bagging by de-correlating trees. At every split, it only considers a random subset of the features. I’m going to grow a tree using a, b, c! I’m going to grow a tree using a, e, d! I’m going to grow a tree using d, e, f! I’m going to grow a tree using b, c, d! Y* Y* Y* Y* }Average Y* Feature Set: a, b, c, d, e, f Random Forest
- 30. Random forest adjusts overfit models Here, we are still using a subset of the data, but instead of randomly selecting a number of observations, we randomly select some number of features. Random forest helps solve the problem of overfitting. Note that we can still calculate an accuracy score using OOB Performance Improving on bagging I’m going to grow a tree using a, b, c! I’m going to grow a tree using a, e, d! I’m going to grow a tree using d, e, f! I’m going to grow a tree using b, c, d! Set: a, b, c, d, e, f
- 31. Finally, boosting is a procedure that iteratively learns by combining many weak classifiers to produce a powerful committee. Bootstrapping Bagging Random Forest Boosting IMPORTANT NOTE: Boosting is one of the most powerful learning ideas introduced in the last 20 years. It sounds similar to but is fundamentally different from bagging and other committee-based approaches.
- 32. Boosting also creates subsets of training data using bootstrap, but each tree learns from the previous trees: that is, each tree is not random. Source: Carnegie Mellon University, http://www.cs.cmu.edu/~guestrin/Class/10701-S06/Sli des/decisiontrees-boosting.pdf Our model gets “brighter” Y* Unlike random forest, each tree is not random in boosting Boosting How does the model learn?
- 33. Boosting uses many weak classifiers to make a single strong classifier. A weak classifier is defined as those whose error rates is only slightly better than random guessing. Boosting sequentially applies weak classification algorithms to repeatedly modified versions of the data. How is the data modified? Our Model gets “brighter” Y* Boosting Combining weak classifiers = one strong classifier
- 34. Each prediction is combined through a weighted majority vote to produce the final prediction. For each iteration, the algorithm weights higher observations that were classified incorrectly. This forces the algorithm to concentrate on training observations that were classified incorrectly in previous iterations. Our Model gets “brighter” Y* Boosting Let’s go through each step of the algorithm Boosting forces the model to focus in on hard-to-classify observations
- 35. 1. Use the whole data set to train a model to produce Y* 2. Evaluate performance (true Y - Y*) 3. Create training set #2 including observations that were incorrectly classified 4. Repeat steps 2-3 Results in low model error, but there is risk of overfitting Source: https://www.analyticsvidhya.com/blog/2015/09/questions-ensemble- modeling/ Our Model gets “brighter” Y* Boosting Let’s go through step by step:
- 36. We’ve covered a lot! By now, you have an arsenal of supervised learning algorithms to apply in many situations. In the next module, we will look at unsupervised algorithms and what they can tell us. Bootstrapping Bagging Random Forest Boosting
- 37. End of theory
- 38. ✓ Ensemble approaches ✓ Bootstrap ✓ Bagging ✓ Random forest ✓ Boosting Module Checklist:
- 39. You are on fire! Go straight to the next module here. Need to slow down and digest? Take a minute to write us an email about what you thought about the course. All feedback small or large welcome! Email: [email protected]
- 40. Congrats! You finished module 6 Find out more about Delta’s machine learning for good mission here.