Mongodb - Scaling write performance
48 likes15,628 views

- MongoDB allows for automatic sharding of data across multiple servers to improve write performance. However, scaling write performance is challenging due to the way B-tree indexes handle random inserts. - To improve write performance, one can partition data by time or use a hash shard key. However, these have limitations as the data grows large. The best approach is to use a low-cardinality hash prefix combined with a sequential part for the shard key. - Proper choice of shard key is crucial for scaling MongoDB's write performance as data size increases. Linear scalability is difficult to achieve and alternative databases may be better if extremely high write throughput is required.











































































Ad
More Related Content
What's hot (20)
Similar to Mongodb - Scaling write performance (20)


















Ad
More from Daum DNA (20)










![Daum devday 13 [bap]](https://cdn.slidesharecdn.com/ss_thumbnails/daumdevday13-bap-130225010411-phpapp02-thumbnail.jpg?width=560&fit=bounds)









Ad
Mongodb - Scaling write performance
- 1. MongoDB: Scaling write performance Junegunn Choi
- 2. MongoDB • Document data store • JSON-like document • Secondary indexes • Automatic failover • Automatic sharding
- 3. First impression: Easy • Easy installation • Easy data model • No prior schema design • Native support for secondary indexes
- 4. Second thought: Not so easy • No SQL • Coping with massive data growth • Setting up and operating sharded cluster • Scaling write performance
- 5. Today we’ll talk about insert performance
- 6. Insert throughput on a replica set
- 7. Steady 5k inserts/sec * 1kB record. ObjectId as PK * WriteConcern: Journal sync on Majority
- 8. Insert throughput on a replica set with a secondary index
- 10. Culprit: B+Tree index • Good at sequential insert • e.g. ObjectId, Sequence #, Timestamp • Poor at random insert • Indexes on randomly-distributed data
- 11. Sequential vs. Random insert 1 55 2 75 3 78 4 1 5 99 6 36 7 80 8 91 9 52 10 B+Tree 63 B+Tree 11 56 12 33 working set working set Sequential insert ➔ Small working set Random insert ➔ Large working set ➔ Fits in RAM ➔ Sequential I/O ➔ Cannot fit in RAM ➔ Random I/O (bandwidth-bound) (IOPS-bound)
- 12. So, what do we do now?
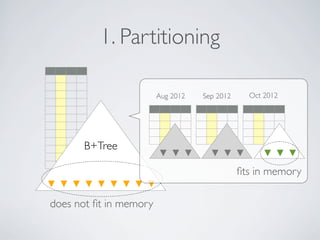
- 13. 1. Partitioning Aug 2012 Sep 2012 Oct 2012 B+Tree fits in memory does not fit in memory
- 14. 1. Partitioning • MongoDB doesn’t support partitioning • Partitioning at application-level • e.g. Daily log collection • logs_20121012
- 15. Switch collection every hour
- 16. 2. Better H/W • More RAM • More IOPS • RAID striping • SSD • AWS Provisioned IOPS (1k ~ 10k)
- 18. 3. More H/W: Sharding • Automatic partitioning across nodes SHARD1 SHARD2 SHARD3 mongos router
- 19. 3 shards (3x3)
- 20. 3 shards (3x3) on RAID 1+0
- 21. There’s no free lunch • Manual partitioning • Incidental complexity • Better H/W • $ • Sharding • $$ • Operational complexity
- 22. “Do you really need that index?”
- 23. Scaling insert performance with sharding
- 24. = Choosing the right shard key
- 25. Shard key example: year_of_birth 64MB chunk ~ 1950 1971 ~ 1990 1951 ~ 1970 1991 ~ 2005 2006 ~ 2010 2010 ~ ∞ USERS USERS USERS SHARD1 SHARD2 SHARD3 mongos router
- 26. 5k inserts/sec w/o sharding
- 27. Sequential key • ObjectId as shard key • Sequence # • Timestamp
- 28. Worse throughput with 3x H/W.
- 29. Sequential key 1000 ~ 2000 • All inserts into one chunk 5000 ~ 7500 • Cannot scale insert performance 9000 ~ ∞ • Chunk migration overhead USERS SHARD-x 9001, 9002, 9003, 9004, ...
- 30. Sequential key
- 31. Hash key • e.g. SHA1(_id) = 9f2feb0f1ef425b292f2f94 ... • Distributes inserts evenly across all chunks
- 33. Hash key • Performance drops as collection grows • Why? Mandatory index on shard key • B+Tree problem again!
- 34. Sequential key Hash key
- 35. Sequential + hash key • Coarse-grained sequential prefix • e.g. Year-month + hash value • 201210_24c3a5b9 B+Tree 201208_* 201209_* 201210_*
- 36. But what if... B+Tree large working set 201208_* 201209_* 201210_*
- 37. Sequential + hash key • Can you predict data growth rate? • Balancer not clever enough • Only considers # of chunks • Migration slow during heavy-writes
- 38. Sequential key Hash key Sequential + hash key
- 39. Low-cardinality hash key • Small portion of hash value Shard key range: A ~ D • e.g. A~Z, 00~FF • Alleviates B+Tree problem Local • Sequential access on fixed # B+Tree of parts • Cardinality / # of shards A A A B B B C C C
- 41. Low-cardinality hash key • Limits the # of possible chunks • e.g. 00 ~ FF ➔ 256 chunks • Chunk grows past 64MB • Balancing becomes difficult
- 42. Sequential key Hash key Sequential + hash key Low-cardinality hash key
- 43. Low-cardinality hash prefix + sequential part Shard key range: A000 ~ C999 • e.g. Short hash prefix + timestamp • Nice index access pattern Local B+Tree • Unlimited number of chunks A000 A123 B000 B123 C000 C123
- 45. Lessons learned • Know the performance impact of secondary index • Choose the right shard key • Test with large data sets • Linear scalability is hard • If you really need it, consider HBase or Cassandra • SSD
- 46. Thank you. Questions? 유응섭 [email protected] 최준건 [email protected]