Monitoring Big Data Systems "Done the simple way" - Demi Ben-Ari - Codemotion Rome 2017
1 like349 views

Once you start working with distributed Big Data systems, you start discovering a whole bunch of problems you won’t find in monolithic systems. All of a sudden to monitor all of the components becomes a big data problem itself. In the talk we’ll mention all of the aspects that you should take in consideration when monitoring a distributed system once you’re using tools like: Web Services, Apache Spark, Cassandra, MongoDB, Amazon Web Services. Not only the tools, what should you monitor about the actual data that flows in the system? And we’ll cover the simplest solution with your day to day open source tools, the surprising thing, that it comes not from an Ops Guy.



























































































More Related Content
What's hot (20)
Similar to Monitoring Big Data Systems "Done the simple way" - Demi Ben-Ari - Codemotion Rome 2017 (20)








![[WSO2Con EU 2018] The Rise of Streaming SQL](https://cdn.slidesharecdn.com/ss_thumbnails/1-181113084942-thumbnail.jpg?width=560&fit=bounds)









More from Demi Ben-Ari (20)




















Recently uploaded (20)









![Download Wondershare Filmora Crack [2025] With Latest](https://cdn.slidesharecdn.com/ss_thumbnails/neo4j-howkgsareshapingthefutureofgenerativeaiatawssummitlondonapril2024-240426125209-2d9db05d-250419-250428115407-a04afffa-thumbnail.jpg?width=560&fit=bounds)










Monitoring Big Data Systems "Done the simple way" - Demi Ben-Ari - Codemotion Rome 2017
- 1. Monitoring Big Data Systems - Done “The Simple Way” Demi Ben-Ari - VP R&D @ ROME 24-25 MARCH 2017
- 2. About Me Demi Ben-Ari, Co-Founder & VP R&D @ Panorays ● BS’c Computer Science – Academic College Tel-Aviv Yaffo ● Co-Founder ○ “Big Things” Big Data Community ○ Google Developer Group Cloud In the Past: ● Sr. Data Engineer - Windward ● Team Leader & Sr. Java Software Engineer Missile defense and Alert System - “Ofek” – IAF Interested in almost every kind of technology – A True Geek
- 3. Agenda ● A lot of (NOT) funny Jokes ● Problem definition and Environment ● Monitoring pipeline solutions ○ Metrics ○ Datastores ○ Dashboards ○ Alerting ● Summary ● (Not going to address Service discovery and monitoring)
- 4. Say “Distributed”, Say “Big Data”, Say….
- 5. What is Big Data (IMHO)? And What to Monitor? ● Systems involving the “3 Vs”: What are the right questions we want to ask? ○ Volume - How much? ○ Velocity - How fast? ○ Variety - What kind? (Difference)
- 7. Monolith Structure OS CPU Memory Disk Processes Java Application Server Database Web Server Load Balancer Users - Other Applications Monitoring System UI Many times...all of this was on a single physical server!
- 8. Distributed Microservices Architecture Service A Queue DB Service B DBCache Cache DBService C Web Server DB Analytics Cluster Master Slave Slave Slave Monitoring System???
- 10. Basic Concepts ● Monitoring ● White-box ○ internals ● Black-box ○ behavior ● Dashboard ● Alert ● Root cause ● Node and machine ● Deploy ○ Any change to a service’s running software or its configuration. ● KPI - Key Performance Indicator
- 11. Data flow and Environment (Our Use Case)
- 12. Structure of the Data ● Maritime analytics Platform ● Geo Locations + Metadata ● Arriving over time ● Different types of messages being reported by satellites ● Encoded (For compression reasons) ● Might arrive later than actually transmitted
- 13. Data Flow Diagram External Data Source Analytics Layers Data Pipeline Parsed Raw Entity Resolution Process Building insights on top of the entities Data Output Layer Anomaly Detection Trends UI for End Users
- 14. Environment Description Cluster Dev Testing Live Staging ProductionEnv OB1K RESTful Java Services
- 15. Monitoring Stack - Let’s fill in the blanks Alerting Metrics Collection Datastore Dashboard Data Monitoring Log Monitoring
- 17. MongoDB + Spark Worker 1 Worker 2 …. …. … … Worker N Spark Cluster Master Write Read MasterSahrded MongoDB Replica Set
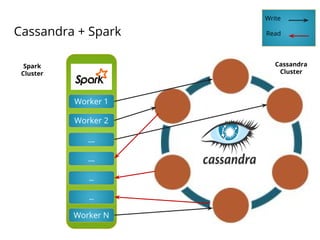
- 18. Cassandra + Spark Worker 1 Worker 2 …. …. … … Worker N Cassandra Cluster Spark Cluster Write Read
- 19. Cassandra + Serving Cassandra Cluster Write Read UI Client UI Client UI Client UI Client Web ServiceWeb ServiceWeb ServiceWeb Service
- 20. Problems ● Multiple physical servers ● Multiple logical services ● Want Scaling => More Servers ● Even if you had all of the metrics ○ You’ll have an overflow of the data ● Your monitoring becomes a “Big Data” problem itself
- 21. This is what “Distributed” really Means The DevOps Guy (It might be you)
- 24. Monitoring Operation System Metrics ● What to measure: ○ CPU ○ Memory ○ Disk Space ● How to measure: ○ CollectD or StatsD reporting to Graphite ○ New Relic ■ Nice and easy UI ■ Even the free account gives great tool ■ Alerting of thresholds
- 25. Some help from “the Cloud”
- 26. AWS’s CloudWatch / GCP StackDriver
- 27. Report to Where? ● We chose: ● Graphite (InfluxDB) + Grafana ● Can correlate System and Application metrics in one place :)
- 28. Report to Where? ● Save DevOps efforts if you’re willing to Pay :) ● Hosted Graphite ○ https://www.hostedgraphite.com/ ● Throwing the “Big Data” volume monitoring problem at someone else
- 30. Drivers to Datastores ● Actions they usually do: ○ Open connection ○ Apply actions ■ Select, Insert, Update, Delete ○ Close connection ● Do you monitor each? ○ Hint: Yes!!!! Hell Yes!!! ● Creating a wrapper in any programming language and reporting the metrics ○ Count, execution times, errors… ○ Infrastructure code that will give great visibility
- 32. Monitoring Cassandra ● OpsCenter - by DataStax
- 33. Monitoring Cassandra ● Is the enough?... We can connect it to Graphite also (Blog: “Monitoring the hell out of Cassandra”) ● Plug & Play the metrics to Graphite - Internal Cassandra mechanism ● Back to the basics: dstat, iostat, iotop, jstack
- 35. Monitoring Spark
- 36. What to monitor in an Apache Spark Cluster ● Application execution ● Resource consumption and allocation ● Task Failures ● Environment and Amount of servers ● Physical OS metrics ● Infrastructure services
- 37. Ways to Monitoring Spark ● Sending Metrics: Spark → Graphite (Execution) ● http://spark.apache.org/docs/latest/monitoring.html
- 38. Ways to Monitoring Spark ● Sending Metrics: Spark → Graphite (JVM metrics) ● http://spark.apache.org/docs/latest/monitoring.html
- 39. Ways to Monitoring Spark ● Grafana-spark-dashboards ○ Blog: http://www.hammerlab.org/2015/02/27/monitoring-spar k-with-graphite-and-grafana/ ● Spark UI - Online on each application running ● Spark History Server - Offline (After application finishes) ● Spark REST API ○ Querying via inner tools to do ad-hoc monitoring ● Back to the basics: dstat, iostat, iotop, jstack ● Blog post by Tzach Zohar - “Tips from the Trenches”
- 41. Data Questions? What should be measure ● Did all of the computation occur? ○ Are there any data layers missing? ● How much data do we have? (Volume) ● Is all of the data in the Database? ● Data Quality Assurance
- 42. Data Answers! ● KISS (Keep it simple stupid) ● Jenkins + Maven (JUnit) for the rescue ● Creating a maven “monitoring” project. ○ Running scheduled tasks, each for the relevant data source ■ Database data existence ■ S3 files existence ■ Data flow that keeps on coming from sensors ■ (Any other data source that you can imagine…) ○ Scheduled task that write amount metrics to Graphite -> Dashboards ○ Report task execution to Graphite
- 43. Data Answers! ● The method doesn’t really matter, as long as you: ○ Can follow the results over time ○ Know what your data flow, know what might fail ○ It’s easy for anyone to add more monitoring (For the ones that add the new data each time…) ○ It don’t trust others to add monitoring (It will always end up the DevOps’s “fault” -> No monitoring will be applied)
- 45. ● Elastic ● Architecture: Server Server Server ELK - Elasticsearch + Logstash + Kibana Shippers Queue Indexer Web UIStorage
- 46. ● (Simpler) Architecture: ○ The problem: Log42 only works with TCP :( => Log4J2 works with UDP too Server Server Server ELK - Elasticsearch + Logstash + Kibana Indexer Web UIStorage TCP / UDP
- 47. ELK - Elasticsearch + Logstash + Kibana http://www.digitalgov.gov/2014/05/07/analyzing-search-data-in-real-time-to-drive-decisions/
- 49. Redash ● http://redash.io/ ● Open Source: https://github.com/getredash/redash ● Came out as one of many Open source tool by Everything.me ● Created and Maintained by Arik Fraimovich (You rock!) ● Written in Python ● Has an on-premise and hosted solution ●רןאאקמ
- 51. Alerting
- 52. Alerting ● Syren - Open source ● Reporting to: ○ Email, Flowdock, HipChat, HTTP, Hubot, IRCcat, PagerDuty, Pushover, SLF4J, Slack, SNMP, Twilio
- 53. Summary - Monitoring Stack Alerting Metrics Collection Datastore Dashboard Data Monitoring Log Monitoring
- 54. Not my problem...or is it? https://cdn.meme.am/instances/500x/22605665.jpg
- 55. So...Who does the monitoring in our company? https://imgflip.com/i/18kvv1
- 56. Our DevOps guy eventually, Happy! Zion, Respect! :)
- 57. Conclusions ● Correlating Application and System metrics!!!! ● Ask the right monitoring questions -> answer with Dashboards ● KISS - simple is key, what’s hard, we tend not to do at all ● Alert about what you can actually react to ○ (And to the relevant person) ● Measure whatever you can ○ only way to know if you’re improving ● Monitor your business KPIs too
- 58. Conclusions ● If all of what I’ve said is not enough… Graphs are fricking cool! http://www.rantlifestyle.com/2013/09/23/how-happy-this-baby-is-will-shock-you/
- 59. Questions?
- 60. ● LinkedIn ● Twitter: @demibenari ● Blog: http://progexc.blogspot.com/ ● [email protected] ● “Big Things” Community Meetup, YouTube, Facebook, Twitter ● GDG Cloud
- 62. Resources ● Monitoring distributed systems - A case study in how Google monitors its complex systems