





![DMX QueriesRetrieving a Summary of Training DataQuery to retrieve the data from the node specified.Because the statistics are stored in a nested table, the FLATTENED keyword is used to make the results easier to view. SELECT FLATTENED MODEL_NAME, (SELECT ATTRIBUTE_NAME, ATTRIBUTE_VALUE, [SUPPORT], [PROBABILITY], VALUETYPE FROM NODE_DISTRIBUTION) AS t FROM TM_NaiveBayes.CONTENT WHERE NODE_TYPE = 26](https://image.slidesharecdn.com/microsoftnaivebayesalgorithm-100712053856-phpapp01/85/MS-SQL-SERVER-Microsoft-naive-bayes-algorithm-7-320.jpg)














MS SQL SERVER: Microsoft naive bayes algorithm
- 1. Microsoft Naive Bayes Algorithm
- 2. overviewNaive Bayes AlgorithmDMX QueriesExploring a Naive Bayes ModelNaive Bayes PrinciplesNaive Bayes Parameters
- 3. Naive Bayes AlgorithmThe Microsoft Naive Bayes algorithm is a classification algorithm provided by Microsoft SQL Server Analysis Services for use in predictive modeling. The name Naive Bayes derives from the fact that the algorithm uses Bayes theorem but does not take into account dependencies that may exist, and therefore its assumptions are said to be naive.
- 4. How to use the Naive Bayes algorithm in SQL server?This algorithm is less computationally intense than other Microsoft algorithmsIt is therefore is useful for quickly generating mining models to discover relationships between input columns and predictable columns. The algorithm considers each pair of input attribute values and output attribute values.Exploring a Naive Bayes model will tell you how your attributes are related to each other.
- 5. DMX When you create a query against a data mining modelyou can create either a content query, which provides details about the patterns discovered in analysis, or you can create a prediction query, which uses the patterns in the model to make predictions for new data You can also retrieve metadata about the model by using a query against the data mining schema rowset.
- 6. DMX QueriesSELECT MODEL_CATALOG, MODEL_NAME, DATE_CREATED, LAST_PROCESSED, SERVICE_NAME, PREDICTION_ENTITY, FILTER FROM $system.DMSCHEMA_MINING_MODELS WHERE MODEL_NAME = 'TM_NaiveBayes_Filtered‘Getting Model Metadata by Using DMXyou can find metadata for the model, by querying the data mining schema rowset.This might include when the model was created, when the model was last processed, the name of the mining structure that the model is based on, and the name of the columns used as the predictable attribute.
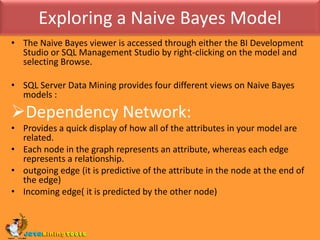
- 7. DMX QueriesRetrieving a Summary of Training DataQuery to retrieve the data from the node specified.Because the statistics are stored in a nested table, the FLATTENED keyword is used to make the results easier to view. SELECT FLATTENED MODEL_NAME, (SELECT ATTRIBUTE_NAME, ATTRIBUTE_VALUE, [SUPPORT], [PROBABILITY], VALUETYPE FROM NODE_DISTRIBUTION) AS t FROM TM_NaiveBayes.CONTENT WHERE NODE_TYPE = 26
- 8. DMX QueriesFinding More Information about AttributesExample to show how to return information from the model about a particular attribute( here ”Region”) The Result of this query is shown in the next slide.SELECT NODE_TYPE, NODE_CAPTION, MSOLAP_NODE_SCORE FROM TM_NaiveBayes.CONTENT WHERE ATTRIBUTE_NAME = 'Region'
- 9. DMX QueriesSample Resultto showinginformation from the model about a particular attribute ”Region”
- 10. DMX QueriesSELECT NODE_CAPTION, MSOLAP_NODE_SCORE FROM TM_NaiveBayes.CONTENT WHERE NODE_TYPE = 10 ORDER BY MSOLAP_NODE_SCORE DESCQuery returns theimportance scores ofall attributes in theModel. The Result of this query is shown in the next slide.
- 11. DMX Queriesquery returns theimportance scores ofall attributes in theModel.
- 12. Exploring a Naive Bayes ModelThe convenient way to start analyzing a new data set is to create a Naive Bayes model and mark all the non-key columns as both input and predictive.The content of each model is presented as a series of nodes. A node is an object within a mining model that contains metadata and information about a portion of the model. Nodes are arranged in a hierarchy.
- 13. Naive Bayes Model Content
- 14. Exploring a Naive Bayes ModelThe Naive Bayes viewer is accessed through either the BI Development Studio or SQL Management Studio by right-clicking on the model and selecting Browse.SQL Server Data Mining provides four different views on Naive Bayes models :Dependency Network: Provides a quick display of how all of the attributes in your model are related. Each node in the graph represents an attribute, whereas each edge represents a relationship. outgoing edge (it is predictive of the attribute in the node at the end of the edge)Incoming edge( it is predicted by the other node)
- 15. Exploring a Naive Bayes ModelAttribute Profiles:provides you with an exhaustive report of how each input attribute corresponds to each output attribute, one attribute at a time. At the top of the Attribute Profiles view, you select which output you want to look at, and the rest of the view shows how all of the input attributes are correlated to the states of the selected output attribute.
- 16. Exploring a Naive Bayes ModelAttribute Characteristics:This tab allows you to select an output attribute and value and shows you a description of the cases where that attribute and value occur.Attribute Discrimination: Provides the answers to the most interesting question: What is the difference between X and Y? With this viewer, you choose the attribute you are interested in, and select the states you want to compare.
- 17. Naive Bayes PrinciplesBayes mathematical methods use a combination of conditional and unconditional probabilities.The Naive part of Naive Bayes tells you to treat all of your input attributes as independent of each other with respect to the target variable. This may be a faulty assumption, but it allows you to multiply your probabilities to determine the likelihood of each state.
- 18. Naive Bayes PrinciplesThe Bayes rule states that if you have a hypothesis Hand evidence about that hypothesis E, then the probability of H is calculated using the following formula:P(H | E) = P(E | H) × P(H) P(E)This simply states that the probability of your hypothesis given the evidence is equal to the probability of the evidence given the hypothesis multiplied by the probability of the hypothesis, and then normalized.
- 19. Naive Bayes ParametersMAXIMUM _INPUT _ATTRIBUTES determines the number of attributes that will be considered as inputs for training. If there is more than this number of inputs, the algorithm will select the most important inputs and ignore the rest. Setting this parameter to 0 causes the algorithm to consider all attributes.The default value is 255.MAXIMUM _OUTPUT _ATTRIBUTES determines the number of attributes that will be considered as outputs for training. If there is more than this number of outputs, the algorithm will select the most important outputs and ignore the rest. Setting this parameter to 0 causes the algorithm to consider all attributes.The default value is 255.
- 20. Naive Bayes ParametersMAXIMUM _STATES controls how many states of an attribute are considered. If an attribute has more than this number of states, only the most popular states will be used. States that are not selected will be considered to be missing data. This parameter is useful when an attribute has a high cardinality
- 21. SummaryNaive Bayes AlgorithmDMX QueriesNaive Bayes Model ContentExploring a Naive Bayes ModelNaive Bayes PrinciplesNaive Bayes Parameters
- 22. Visit more self help tutorialsPick a tutorial of your choice and browse through it at your own pace.The tutorials section is free, self-guiding and will not involve any additional support.Visit us at www.dataminingtools.net