Как мы готовим MySQL / Николай Королёв (Badoo)

* Исторический экскурс, введение понятия спота, принцип функционального деления баз на группы (споты / не споты), шардирование как способ масштабирования спотов. * Возникновение второго датацентра на другом континенте, создание самодельной репликации, позволяющей работать по схеме много -> много, краткая схема (структура спотов, схема репликации, служебные базы - очереди, репликация, мониторинг), плюсы и минусы этого решения, инструменты диагностики. * Альтеры шадрированых спотов - первый вариант утилиты для этой задачи: схема его работы и возникшие проблемы; вторая версия утилиты - улучшения, а также, что осталось неисправленным. * “Температура” спота, трудности её определения, проблемы, возникающие из-за его “перегрева”, наш способ решения и возникновение проекта “кладбище”. * Деплой и около - почему мы используем MySQL в chroot, как мы его собираем и как деплоим. * Бэкапы спотовых данных - первоначальное решение (ленточные хранилища), работа над ошибками, текущая схема. * Query sampling: проект Minba.
































































































More Related Content
What's hot (20)
Similar to Как мы готовим MySQL / Николай Королёв (Badoo) (20)


















More from Ontico (20)




















Как мы готовим MySQL / Николай Королёв (Badoo)
- 1. Как мы готовим MySQL Николай Королёв Site Reliability Engineer Badoo
- 2. • 320 млн пользователей • 12 млн пользователей ежедневно • 32 млн пользователей ежемесячно • ~ 3000 серверов О компании
- 4. Подробнее о наших базах* • 310 серверов • 370 Тб • 64 млн таблиц • Пиковый QPS > 1 900 000 *кластер пользовательских данных
- 5. Секрет успеха DBA • Стабильность работы баз данных • Приемлемое время выполнения запросов • Сохранность и доступность данных пользователей
- 6. Пользователь
- 8. Активный пользователь с подпиской
- 14. • Партицирование • Репликация Варианты масштабирования ШАРДИРОВАНИЕ
- 15. • Партицирование • Репликация • Шардирование Варианты масштабирования ШАРДИРОВАНИЕ
- 16. Шардирование по ключу user_id ШАРДИРОВАНИЕ
- 17. Шардирование по ключу user_id ШАРДИРОВАНИЕ
- 18. Шардирование по ключу user_id ШАРДИРОВАНИЕ
- 19. набор шардированных таблиц, связанных с определенными пользователями Спот – это … ШАРДИРОВАНИЕ
- 20. Что такое UDB? • KV Storage: user_id => spot_id • HandlerSocket ✓QPS ~ 50k ✓Request time ~ 5ms ШАРДИРОВАНИЕ
- 21. Что делать со spot_id? В коде есть карта; оригинал карты в базе ШАРДИРОВАНИЕ
- 22. Что получилось? • Реализовали схему шардирования данных • Создали кластер серверов бд - dbs • Сделали сервис UDB и карту спотов ШАРДИРОВАНИЕ
- 26. • RTT ~ 120 ms • connect ~ 0.6 s Badoo в 2008 РЕПЛИКАЦИЯ
- 27. A. Проблема внешняя: – Запрос информации с удаленной площадки B. Проблема внутренняя: – Скрипты, работающие со всеми пользователями, работают слишком долго Почему это проблема ? РЕПЛИКАЦИЯ
- 28. Идея! РЕПЛИКАЦИЯ
- 29. Требования • Данные только для чтения • Нужна только часть спота • Другой профиль нагрузки => репликация “много к 1” РЕПЛИКАЦИЯ
- 30. Готовое решение? (2008) MySQL replication: 1. Работает в 1 поток 2. Позволяет только схему “1 к 1” РЕПЛИКАЦИЯ
- 31. Пилим велосипед: своя репликация •Логирование •Доставка •Проигрывание РЕПЛИКАЦИЯ
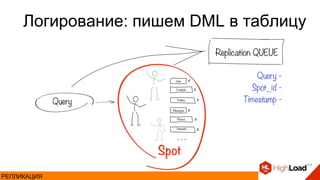
- 32. Логирование: пишем DML в таблицу РЕПЛИКАЦИЯ
- 33. Доставка: сохраняем на диск РЕПЛИКАЦИЯ
- 34. Доставка: сжимаем и отправляем РЕПЛИКАЦИЯ
- 36. Проигрывание: распаковываем, применяем РЕПЛИКАЦИЯ ✓IOPS ✓Memory (fs cache / running scripts )
- 38. • Перезаливка полного отношения Инструменты РЕПЛИКАЦИЯ
- 39. • Перезаливка одной/нескольких таблиц в отношении Инструменты РЕПЛИКАЦИЯ
- 40. • Проверяем отставание репликации • Репликационный лаг мы мониторим Zabbix-ом Репликация: мониторинг РЕПЛИКАЦИЯ
- 41. Плюсы и минусы нашего решения Минусы: • Репликационный лаг от 10 сек до 1 мин • Диагностика и исправление проблем подразумевает наличие глубоких знаний о нашей системе РЕПЛИКАЦИЯ
- 42. Плюсы и минусы нашего решения Минусы: • Репликационный лаг от 10 сек до 1 мин • Диагностика и исправление проблем подразумевает наличие глубоких знаний о нашей системе Плюсы: • Репликация “много”=>”много” • Проигрывание репликации в несколько потоков • Инструменты для восстановления данных на реплике (dbb) РЕПЛИКАЦИЯ
- 43. DDL DDL
- 46. В споте этих изменений нет! DDL Миграция БД
- 47. В споте этих изменений нет! DDL Репликационная пара
- 48. В споте этих изменений нет! До релиза задачи схема должна быть изменена DDL
- 49. Вот так выглядит флоу • Разработчик ставит тикет на DDL (ALTER request) • DBA делает ревью DDL • Выполняется ALTER request на всём кластере • Разработчик выкатывает фичу в продакшн DDL
- 50. Выполнение DDL • Обычный блокирующий ALTER / CREATE / DROP (MySQL 5.6 FTW) • Небольшой размер спота • Среднее время выполнения ~ 40 минут DDL
- 51. Результат выполнения DDL • Скрипт отправляет письмо о завершении и его статусе • DBA убеждается что ALTER успешно выполнен и закрывает тикет • Разработчик может релизить свою задачу (договоренность) DDL
- 52. • Разработчиков много => задач на DDL много • “Легкие” DDL можно сгруппировать, но что делать с остальными? • Нужна очередь Растущие запросы на DDL DDL
- 53. Очередь DDL • Выстраивается вручную DBA • По принципу FIFO • Порядок очереди может быть нарушен DDL
- 54. Вот так и живём! DDL
- 55. Наш кластер • ~ 100 dbs • Железо не гомогенное (серверы покупались в разное время) • Разное соотношение активных/неактивных пользователей Устанавливаем новый сервер => появляются пользователи На сколько хватит сервера? РАСПРЕДЕЛЕНИЕ НАГРУЗКИ
- 57. Жизненный цикл сервера РАСПРЕДЕЛЕНИЕ НАГРУЗКИ
- 58. “Температура” спота v.2 РАСПРЕДЕЛЕНИЕ НАГРУЗКИ
- 59. РАСПРЕДЕЛЕНИЕ НАГРУЗКИ Активный пользователь Неактивный пользователь CPU Memory Disk space IOPS Каждому своё…
- 60. Разделяем профили нагрузки РАСПРЕДЕЛЕНИЕ НАГРУЗКИ
- 61. Проект “кладбище” • Миграция осуществляется в фоновом режиме • DBA активного участия не принимает • Освободилось до 25% ресурсов основного кластера РАСПРЕДЕЛЕНИЕ НАГРУЗКИ
- 62. last but not least БЭКАП
- 63. Бэкап • Общее количество спотов - 360 000 • Количество таблиц в споте > 80 • Общий объем данных > 190 Тб Как это бэкапить? БЭКАП
- 64. Условия успешного бэкапа • Консистентность данных важна в пределах спота • Все таблицы в InnoDB • Маленький размер спота • DDL происходит по расписанию mysqldump БЭКАП
- 66. Итого мы бэкапим • 25 Тб сжатых данных • Время полного бэкапа - менее 24 часов • Последняя копия – на sqlbackup • Остальные – на ленте БЭКАП
- 67. KISS