Mysql For Developers
Download as ODP, PDF30 likes17,932 views

As a developer, it is important to understand MySQL storage engines and how they can impact performance. The key factors to consider include the type of data being stored, concurrency needs, and requirements for transactions. The storage engine chosen affects aspects like locking granularity, indexing support, and performance for queries, inserts, and updates. Explain statements help analyze query execution plans and identify opportunities to improve performance through proper indexing.









































































































Ad
More Related Content
What's hot (20)
Viewers also liked (20)


















Ad
Similar to Mysql For Developers (20)




















Ad
More from Carol McDonald (20)




















Mysql For Developers
- 1. MySQL for Developers Carol McDonald, Java Architect
- 4. Data types
- 5. Indexes Know your SQL Using Explain Partitions
- 6. JPA lazy loading
- 7. Resources
- 8. Why is it significant for a developer to know MySQL? Generics are inefficient
- 9. take advantage of MySQL's strengths
- 10. understanding the database helps you develop better-performing applications better to design a well-performing database-driven application from the start
- 11. ...than try to fix a slow one after the fact!
- 12. MySQL Pluggable Storage Engine Architecture MySQL supports several storage engines that act as handlers for different table types No other database vendor offers this capability
- 13. What makes engines different? Concurrency : table lock vs row lock right locking can improve performance. Storage : how the data is stored on disk size for tables, indexes Indexes : improves search operations
- 14. Memory usage: Different caching strategies Transactions support not every application needs transactions
- 15. So... As a developer, what do I need to know about storage engines, without being a MySQL expert? keep in mind the following questions: What type of data will you be storing?
- 16. Is the data constantly changing ?
- 17. Is the data mostly logs ( INSERT s)?
- 18. requirements for reports ?
- 19. Requirements for transactions ?
- 20. MyISAM Pluggable Storage engine Default MySQL engine
- 21. high-speed Query and Insert capability insert uses shared read lock
- 22. updates,deletes use table-level locking, slower full -text indexing
- 24. good choice for : read-mostly applications that don't require transactions Web, data warehousing, logging, auditing
- 25. InnoDB Storage engine in MySQL Transaction-safe and ACID compliant
- 26. good query performance , depending on indexes
- 27. row -level locking , MultiVersion Concurrency Control (MVCC) allows fewer row locks by keeping data snapshots no locking for SELECT (depending on isolation level)
- 28. high concurrency possible uses more disk space and memory than ISAM
- 29. Good for Online transaction processing ( OLTP ) Lots of users: Slashdot, Google, Yahoo!, Facebook, etc.
- 30. Memory Engine Entirely in-memory engine stores all data in RAM for extremely fast access Hash index used by default
- 31. Good for Summary and transient data
- 32. " lookup " or "mapping" tables,
- 33. calculated table counts,
- 34. for caching Session or temporary tables
- 35. Archive engine Incredible insert speeds
- 37. No UPDATEs
- 38. Ideal for storing and retrieving large amounts of historical data audit data, log files,Web traffic records
- 39. Data that can never be updated
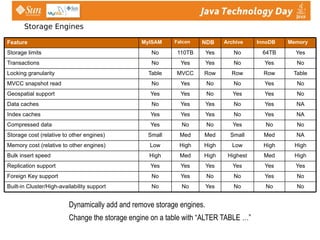
- 40. Storage Engines Dynamically add and remove storage engines. Change the storage engine on a table with “ALTER TABLE …” High High Low High High Low Memory cost (relative to other engines) High Med Highest High Med High Bulk insert speed Yes Yes Yes Yes Yes Yes Replication support No No No Yes No No Built-in Cluster/High-availability support No Yes No No Yes No Foreign Key support NA Med Small Med Med Small Storage cost (relative to other engines) No No Yes No No Yes Compressed data NA Yes No Yes Yes Yes Index caches NA Yes No Yes Yes No Data caches No Yes Yes No Yes Yes Geospatial support No Yes No No Yes No MVCC snapshot read Table Row Row Row MVCC Table Locking granularity No Yes No Yes Yes No Transactions Yes 64TB No Yes 110TB No Storage limits Memory InnoDB Archive NDB Falcon MyISAM Feature
- 41. Does the storage engine really make a difference? Using mysqlslap, against MySQL 5.1.23rc, the Archive engine has 50% more INSERT throughput compared to MyISAM, and 255% more than InnoDB User Load MyISAM Inserts Per Second InnoDB Inserts Per Second Archive Inserts Per Second 1 3,203.00 2,670.00 3,576.00 4 9,123.00 5,280.00 11,038.00 8 9,361.00 5,044.00 13,202.00 16 8,957.00 4,424.00 13,066.00 32 8,470.00 3,934.00 12,921.00 64 8,382.00 3,541.00 12,571.00
- 42. Pluggable storage engines offer Flexibility You can use multiple storage engines in a single application A storage engine for the same table on a slave can be different than that of the master can greatly improve performance master slave innodb isam
- 43. Inside MySQL Replication A storage engine for the same table on a slave
- 44. can be different than that of the master MySQL Master I/O Thread SQL Thread relay binlog MySQL Slave mysqld data index & binlogs mysqld data binlog Replication Web/App Server Writes & Reads Writes
- 45. Using different engines Creating a table with a specified engine CREATE TABLE t1 (...) ENGINE=InnoDB; Changing existing tables ALTER TABLE t1 ENGINE=MyISAM; Finding all your available engines SHOW STORAGE ENGINES;
- 46. The schema Basic foundation of performance Normalization
- 47. Data Types Smaller, smaller, smaller Smaller tables use less disk, less memory, can give better performance Indexing Speeds up retrieval
- 48. Goal of Normalization Eliminate redundant data : Don't store the same data in more than one table
- 49. Only store related data in a table
- 50. reduces database size and errors
- 51. Normalization updates are usually faster . there's less data to change . tables are usually smaller , use less memory , which can give better performance.
- 52. better performance for distinct or group by queries
- 53. taking normalization way too far http://thedailywtf.com/forums/thread/75982.aspx However Normalized database causes joins for queries
- 54. excessively normalized database: queries take more time to complete, as data has to be retrieved from more tables . Normalized better for writes OLTP
- 55. De-normalized better for reads , reporting
- 56. Real World Mixture : normalized schema
- 57. Cache selected columns in memory table Normalize first denormalize later
- 58. Data Types: Smaller, smaller , smaller Use the smallest data type possible
- 59. The smaller your data types, The more index (and data ) can fit into a block of memory , the faster your queries will be. Period.
- 60. Especially for indexed fields Smaller = less disk=less memory= better performance
- 61. Choose your Numeric Data Type MySQL has 9 numeric data types Compared to Oracle's 1 Integer: TINYINT , SMALLINT, MEDIUMINT, INT, BIGINT
- 62. Require 8, 16, 24, 32, and 64 bits of space. Use UNSIGNED when you don't need negative numbers – one more level of data integrity BIGINT is NOT needed for AUTO_INCREMENT INT UNSIGNED stores 4.3 billion values!
- 63. Choose your Numeric Data Type Floating Point: FLOAT, DOUBLE Approximate calculations Fixed Point: DECIMAL Always use DECIMAL for monetary/currency fields, never use FLOAT or DOUBLE! Other: BIT Store 0,1 values
- 64. Character Data Types VARCHAR(n) variable length uses only space it needs Can save disk space = better performance Use : Max column length > avg
- 65. when updates rare (updates fragment) CHAR(n) fixed length Use: short strings, Mostly same length , or changed frequently
- 66. Appropriate Data Types Always define columns as NOT NULL unless there is a good reason not to Can save a byte per column
- 67. nullable columns make indexes , index statistics, and value comparisons more complicated . Use the same data types for columns that will be compared in JOINs Otherwise converted for comparison
- 68. smaller, smaller, smaller The Pygmy Marmoset world's smallest monkey The more records you can fit into a single page of memory/disk, the faster your seeks and scans will be Use appropriate data types
- 69. Keep primary keys small
- 70. Use TEXT sparingly Consider separate tables Use BLOB s very sparingly Use the filesystem for what it was intended
- 71. Indexes Indexes Speed up Querys, SELECT...WHERE name = 'carol'
- 72. only if there is good selectivity: % of distinct values in a column But... each index will slow down INSERT, UPDATE, and DELETE operations
- 73. Missing Indexes Always have an index on join conditions
- 74. Look to add indexes on columns used in WHERE and GROUP BY expressions
- 75. PRIMARY KEY, UNIQUE , and Foreign key Constraint columns are automatically indexed. other columns can be indexed ( CREATE INDEX ..)
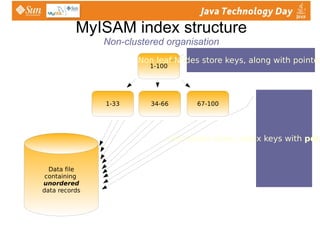
- 76. MyISAM index structure Non-clustered organisation 1-100 Data file containing unordered data records 1-33 34-66 67-100 Non leaf Nodes store keys, along with pointers to nodes Leaf nodes store index keys with pointers to a row data
- 77. Clustered organisation (InnoDB) So, bottom line : When looking up a record by a primary key, for a clustered layout/ organisation , the lookup operation (following the pointer from the leaf node to the data file) is not needed. 1-100 1-33 34-66 67-100 Non leaf Nodes store keys, along with pointers to nodes leaf nodes actually contain all the row data for the record
- 78. InnoDB (Clustered) indexes ISAM InnoDB InnoDB: very important to have as small primary key as possible Why? Primary key value is appended to every record in a secondary index If you don't pick a primary key (bad idea!), one will be created for you Ref: High Performance MySQL
- 79. B-tree indexes B-Tree indexes work well for: Match on key value
- 80. Match on range of values avoid NULLS in the where clause - NULLS aren't indexed Match on left most prefix avoid LIKE beginning with %
- 81. Know how your Queries are executed by MySQL harness the MySQL slow query log and use Explain
- 82. Append EXPLAIN to your SELECT statement shows how the MySQL optimizer has chosen to execute the query You Want to make your queries access less data : are queries accessing too many rows or columns? Use to see where you should add indexes Consider adding an index for slow queries Helps find missing indexes early in the development process
- 83. MySQL Query Analyser Find and fix problem SQL: how long a query took
- 84. how the optimizer handled it Drill downs, results of EXPLAIN statements Historical and real-time analysis query execution counts , run time Its not just slow running queries that are a problem, Sometimes its SQL that executes a lot that kills your system
- 85. Understanding EXPLAIN Just append EXPLAIN to your SELECT statement
- 86. Provides the execution plan chosen by the MySQL optimizer for a specific SELECT statement gives insight into how the MySQL optimizer has chosen to execute the query Use to see where you should add indexes ensures that missing indexes are picked up early in the development process
- 87. EXPLAIN: the execution plan EXPLAIN returns a row of information for each " table " used in the SELECT statement The "table" can mean a real table, a temporary table, a subquery, a union result.
- 88. EXPLAIN example
- 89. Full Table Scan EXPLAIN SELECT * FROM customer id: 1 select_type: SIMPLE table: customer type: ALL possible_keys: NULL key: NULL key_len: NULL ref: NULL rows: 2 Extra: Using where full table scan Avoid: ensure indexes are on columns that are used in the WHERE, ON, and GROUP BY clauses. type : shows the "access strategy" BAD Using SELECT * FROM
- 91. Understanding EXPLAIN EXPLAIN SELECT * FROM customer WHERE custid=1 id: 1 select_type: SIMPLE table: customer type : const possible_keys: PRIMARY key: PRIMARY key_len: 4 ref: const rows: 1 Extra: primary key lookup primary key used in the WHERE very fast because the table has at most one matching row constant
- 92. Range Access type EXPLAIN SELECT * FROM rental WHERE rental_date BETWEEN '2005-06-14' AND '2005-06-16' id: 1 select_type: SIMPLE table: rental type : range possible_keys: rental_date key: rental_date key_len: 8 ref: null rows: 364 Extra: Using where rental_date must be Indexed
- 93. Full Table Scan EXPLAIN SELECT * FROM rental WHERE rental_date BETWEEN '2005-06-14' AND '2005-05-16' id: 1 select_type: SIMPLE table: rental type : ALL possible_keys: rental_date key: null key_len: null ref: null rows: 16000 Extra: Using where when range returns a lot of rows, > 20% table, forces scan If too many rows estimated returned, scan will be used instead
- 94. Scans and seeks A seek jumps to a place (on disk or in memory) to fetch row data Repeat for each row of data needed A scan will jump to the start of the data, and sequentially read (from either disk or memory) until the end of the data
- 95. Large amounts of data? Scan operations are usually better than many seek operations
- 96. When optimizer sees a condition will return > ~20% of the rows in a table, it will prefer a scan versus many seeks
- 97. When do you get a full table scan? No WHERE condition (duh.)
- 98. No index on any field in WHERE condition
- 99. Poor selectivity on an indexed field
- 100. Too many records meet WHERE condition
- 101. scans can be a sign of poor indexing
- 102. Covering indexes When all columns needed from a single table for a SELECT are available in the index
- 103. No need to grab the rest of the columns from the data (file or page) Shows up in Extra column of EXPLAIN as “ Using index ” Important to know the data index organisation of the storage engine!
- 104. Understanding EXPLAIN There is a huge difference between “ index ” in the type column and “ Using index ” in the Extra column type column : "access strategy" Const : primary key= good
- 105. ref : index access = good
- 106. index : index tree is scanned = bad
- 107. ALL : A full table scan = bad Extra column: additional information Using index = good
- 108. filesort or Using temporary = bad means a covering index was found ( good !) means a full index tree scan ( bad !)
- 109. EXPLAIN example
- 110. Operating on indexed column with a function Indexes speed up SELECTs on a column, but...
- 111. indexed column within a function cannot be used SELECT ... WHERE SUBSTR ( name , 3) Most of the time, there are ways to rewrite the query to isolate the indexed column on left side of the equation
- 112. Indexed columns and functions don't mix indexed column should be alone on left of comparison mysql> EXPLAIN SELECT * FROM film WHERE title LIKE 'Tr%' \G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: film type: range possible_keys: idx_title key: idx_title key_len: 767 ref: NULL rows: 15 Extra: Using where mysql> EXPLAIN SELECT * FROM film WHERE LEFT(title ,2) = 'Tr' \G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: film type: ALL possible_keys: NULL key: NULL key_len: NULL ref: NULL rows: 951 Extra: Using where Nice. In the top query, we have a fast range access on the indexed field title Oops. here we have a slower full table scan because of the function operating on the indexed field (the LEFT() function)
- 113. Partitioning Vertical partitioning Split tables with many columns into multiple tables limit number of columns per table Horizontal partitioning Split table by rows into partitions Both are important for different reasons
- 114. Partitioning in MySQL 5.1 is horizontal partitioning for data warehousing Niccolò Machiavelli The Art of War, (1519-1520) : divide the forces of the enemy co me weaker .”
- 115. vertical partitioning Mixing frequently and infrequently accessed attributes in a single table?
- 116. Space in buffer pool at a premium? Splitting the table allows main records to consume the buffer pages without the extra data taking up space in memory Need FULLTEXT on your text columns? CREATE TABLE Users ( user_id INT NOT NULL AUTO_INCREMENT , email VARCHAR(80) NOT NULL , display_name VARCHAR(50) NOT NULL , password CHAR(41) NOT NULL , first_name VARCHAR(25) NOT NULL , last_name VARCHAR(25) NOT NULL , address VARCHAR(80) NOT NULL , city VARCHAR(30) NOT NULL , province CHAR(2) NOT NULL , postcode CHAR(7) NOT NULL , interests TEXT NULL , bio TEXT NULL , signature TEXT NULL , skills TEXT NULL , PRIMARY KEY (user_id) , UNIQUE INDEX (email) ) ENGINE= InnoDB ; Less Frequently referenced, TEXT data Frequently referenced CREATE TABLE Users ( user_id INT NOT NULL AUTO_INCREMENT , email VARCHAR(80) NOT NULL , display_name VARCHAR(50) NOT NULL , password CHAR(41) NOT NULL , PRIMARY KEY (user_id) , UNIQUE INDEX (email) ) ENGINE = InnoDB ; CREATE TABLE UserExtra ( user_id INT NOT NULL , first_name VARCHAR(25) NOT NULL , last_name VARCHAR(25) NOT NULL , address VARCHAR(80) NOT NULL , city VARCHAR(30) NOT NULL , province CHAR(2) NOT NULL , postcode CHAR(7) NOT NULL , interests TEXT NULL , bio TEXT NULL , signature TEXT NULL , skills TEXT NULL , PRIMARY KEY (user_id) , FULLTEXT KEY (interests, skills) ) ENGINE = MyISAM ;
- 117. Understanding the Query Cache Caches the complete query Clients Parser Optimizer Query Cache Pluggable Storage Engine API MyISAM InnoDB MEMORY Falcon Archive PBXT SolidDB Cluster (Ndb) Connection Handling & Net I/O “ Packaging”
- 118. Query cache Caches the complete query Coarse invalidation any modification to any table in the SELECT invalidates any cache entry which uses that table Good for read mostly tables Fast query when no table changes Remedy with vertical table partitioning
- 119. vertical partitioning ... continued Mixing static attributes with frequently updated fields in a single table? Each time an update occurs, queries referencing the table invalidated in the query cache Doing COUNT(*) with no WHERE on an indexed field on an InnoDB table? full table counts slow InnoDB table CREATE TABLE Products ( product_id INT NOT NULL , name VARCHAR(80) NOT NULL , unit_cost DECIMAL(7,2) NOT NULL , description TEXT NULL , image_path TEXT NULL , num_views INT UNSIGNED NOT NULL , num_in_stock INT UNSIGNED NOT NULL , num_on_order INT UNSIGNED NOT NULL , PRIMARY KEY (product_id) , INDEX (name(20)) ) ENGINE = InnoDB ; // Getting a simple COUNT of products // easy on MyISAM, terrible on InnoDB SELECT COUNT (*) FROM Products; frequently updated fields CREATE TABLE Products ( product_id INT NOT NULL , name VARCHAR(80) NOT NULL , unit_cost DECIMAL(7,2) NOT NULL , description TEXT NULL , image_path TEXT NULL , PRIMARY KEY (product_id) , INDEX (name(20)) ) ENGINE = InnoDB ; CREATE TABLE ProductCounts ( product_id INT NOT NULL , num_views INT UNSIGNED NOT NULL , num_in_stock INT UNSIGNED NOT NULL , num_on_order INT UNSIGNED NOT NULL , PRIMARY KEY (product_id) ) ENGINE = InnoDB ; CREATE TABLE TableCounts ( total_products INT UNSIGNED NOT NULL ) ENGINE=MEMORY ; static attributes count
- 120. Solving multiple problems in one query SELECT * FROM Orders WHERE TO_DAYS(CURRENT_DATE()) – TO_DAYS(order_created) <= 7 ; First, we are operating on an indexed column ( order_created ) with a function TO_DAYS – let's fix that: SELECT * FROM Orders WHERE order_created >= CURRENT_DATE() - INTERVAL 7 DAY ; We want to get the orders that were created in the last 7 days we rewrote the WHERE expression to remove the function on the index , we still have a the function CURRENT_DATE() in the statement, which eliminates this query from being placed in the query cache – let's fix that
- 121. Solving multiple problems in one query – let's fix that: SELECT * FROM Orders WHERE order_created >= '2008-01-11' - INTERVAL 7 DAY; We replaced the function CURRENT_DATE() with a constant . However, we are specifying SELECT * instead of the actual fields we need from the table.
- 122. What if there are fields we don't need ? Could cause large result set which may not fit into the query cache and may force a disk-based temporary table SELECT order_id, customer_id, order_total, order_created FROM Orders WHERE order_created >= '2008-01-11' - INTERVAL 7 DAY;
- 123. Scalability: MySQL 5.1 Horizontal Partitioning Split table with many rows into partitions by range, key Logical splitting of tables No need to create separate tables • Transparent to user Why? • To make range selects faster Good for Data Warehouses
- 124. Archival and Date based partitioning CREATE TABLE cust (id int) ENGINE=MyISAM PARTITION BY RANGE (id) ( PARTITION P1 VALUES LESS THAN (10), PARTITION P2 VALUES LESS THAN (20) ) Cust_id 1-999 Cust_id 1000-1999 Cust_id 2000-2999 MySQL Partitioning Web/App Servers
- 125. Scalability: Sharding - Application Partitioning Cust_id 1-999 Cust_id 1000-1999 Cust_id 2000-2999 Sharding Architecture Web/App Servers
- 126. Lazy loading and JPA Default FetchType is LAZY for 1:m and m:n relationships benefits large objects and relationships However for use cases where data is needed can cause n+1 selects
- 127. Capture generated SQL persistence.xml file:<property name=" toplink.logging.level " value=" FINE "> examine the SQL statements optimise the number of SQL statements executed!
- 128. only retrieve the data your application needs! public class Employee{ @OneToMany (mappedBy = "employee") private Collection<Address> addresses; ..... }
- 129. Lazy loading and JPA Relationship can be Loaded Eagerly if you have several related relationships, could load too much ! OR Temporarily override the LAZY fetch type, use Fetch Join in a query: public class Employee{ @OneToMany(mappedBy = "employee", fetch = FetchType.EAGER) private Collection<Address> addresses; ..... } @NamedQueries({ @NamedQuery(name="getItEarly", query="SELECT e FROM Employee e JOIN FETCH e.addresses")}) public class Employee{ ..... }
- 130. MySQL Server 5.4 Scalability improvements - more CPU’s / cores than before.
- 131. MySQL/InnoDB scales up to 16-way x86 servers and 64-way CMT servers Subquery optimizations decrease response times (in some cases > 99%) New join methods improve speed of queries And more ( Dtrace probes, replication heartbeat)…
- 132. GA Target: December 2009
- 133. MySQL Server 5.4 Scalability improvements Solaris x86 sysbench benchmark – MySQL 5.4 vs. 5.1
- 134. Dozens for Reads Dozens for Reads Dozens for Reads Dozens for Reads # of Slaves Master/Slave(s) No Yes MySQL Replication Yes No Varies No No MySQL Replication Master/Slave(s) No Yes MySQL Replication Yes No Varies No Yes MySQL Replication + Heartbeat Active/Passive If configured correctly MySQL Replication MySQL Replication MySQL Replication Yes < 30 secs Yes Yes MySQL, Heartbeat + DRBD Yes Automated DB Fail Over 255 # of Nodes per Cluster Yes Write Intensive Yes Read Intensive Yes Built-in Load Balancing Scalability MySQL Replication Geographic Redundancy Yes Auto Resynch of Data < 3 secs Typical Fail Over Time No Automated IP Fail Over Availability MySQL Cluster Requirements
- 135. MySQL: #3 Most Deployed Database Gartner 2006 Source: Gartner 63% Are Deploying MySQL or Are Planning To Deploy
- 136. MySQL Enterprise Subscription: MySQL Enterprise License (OEM): Embedded Server
- 137. Support MySQL Cluster Carrier-Grade
- 138. Training
- 139. Consulting
- 140. NRE Server Monitor Support MySQL Enterprise Server
- 143. Hot Fix Program
- 144. Extended End-of-Life Global Monitoring of All Servers
- 146. Built-in Advisors
- 147. Expert Advice
- 148. Specialized Scale-Out Help 24 x 7 x 365 Production Support
- 150. Consultative Help
- 152. Added Value of MySQL Enterprise Comprehensive offering of production support, monitoring tools , and MySQL database software
- 153. Optimal performance, reliability, security, and uptime Open-source server with pluggable APIs Monitoring Enterprise manager Query analysis Hot fixes Service packs Best practices rules Knowledge base 24x7 support Advanced backup Load balancer
- 154. MySQL Enterprise Monitor Single, consolidated view into entire MySQL environment
- 155. Auto-discovery of MySQL servers, replication topologies
- 156. Customizable rules-based monitoring and alerts
- 157. Identifies problems before they occur
- 158. Reduces risk of downtime
- 159. Makes it easier to scale out without requiring more DBAs A Virtual MySQL DBA Assistant!
- 161. facebook Application Facebook is a social networking site Key Business Benefit MySQL has enabled facebook to grow to 70 million users. Why MySQL? “ We are one of the largest MySQL web sites in production. MySQL has been a revolution for young entrepreneurs.” Owen Van Natta Chief Operating Officer Facebook
- 162. eBay Application Real-time personalization for advertising Key Business Benefits Handles eBay’s personalization needs. Manages 4 billion requests per day Why MySQL Enterprise? Cost-effective
- 163. Performance: 13,000 TPS on Sun Fire x4100
- 164. Scalability: Designed for 10x future growth
- 165. Monitoring: MySQL Enterprise Monitor Chris Kasten, Kernel Framework Group, eBay
- 166. Zappos Application $800 Million Online Retailer of shoes. Zappos stocks over 3 million items. Key Business Benefit Zappos selected MySQL because it was the most robust, affordable database software available at the time. Why MySQL? "MySQL provides the perfect blend of an enterprise-level database and a cost-effective technology solution. In my opinion, MySQL is the only database we would ever trust to power the Zappos.com website." Kris Ongbongan, IT Manager
- 167. Glassfish and MySQL Part 2
- 168. Catalog Sample Java EE Application DB Registration Application Managed Bean JSF Components Session Bean Entity Class Catalog Item ManagedBean
- 169. Glassfish and MySQL Part 3
- 170. Web Service Client Catalog Sample JAX-WS Application DB Registration Application Managed Bean JSF Components Web Service Entity Class Catalog EJB Item ManagedBean SOAP
- 171. Glassfish and MySQL Part 4
- 172. RIA App REST Web Services Persistence-tier DataBase RESTful Catalog DB Registration Application JAX-RS class JavaFX JAXB class Entity Class ItemsConverter Item ItemsResource HTTP
- 173. In Conclusion Understand the storage engines
- 174. Keep data types small Data size = Disk I/O = Memory = Performance Know your SQL Use EXPLAIN , use the Query Analyzer Understand the query optimizer
- 175. Use good indexing
- 176. Resources MySQL Forge and the Forge Wiki http://forge.mysql.com/ Planet MySQL http://planetmysql.org/ MySQL DevZone http://dev.mysql.com/ High Performance MySQL book
Editor's Notes
- #4: To get the most from MySQL, you need to understand its design , MySQL's architecture is very different from that of other database servers, and makes it useful for a wide range of purposes. The point about understanding the database is especially important for Java developers, who typically will use an abstraction or ORM layer like Hibernate, which hides the SQL implementation (and often the schema itself). ORMs tend to obscure the database schema for the developer, which leads to poorly-performing index and schema strategies, one-engine designs that are not optimal, and queries that use inefficient SQL constructs such as correlated subqueries.
- #5: query parsing, analysis, optimization, caching, all the built-in functions, stored procedures, triggers, and views is provided across storage engines. A storage engine is responsible for storing and retrieving all the data stored . The storage engines have different functionality, capabilities and performance characteristics, A key difference between MySQL and other database platforms is the pluggable storage engine architecture of MySQL, which allows you to select a specialized storage engine for a particular application need such as data warehousing, transaction processing, high availability... in many applications choosing the right storage engine can greatly improve performance. IMPORTANT: There is not one single best storage engine. Each one is good for specific data and application characteristics. Query cache is a MySQL-specific result-set cache that can be excellent for read-intense applications but must be guarded against for mixed R/W apps.
- #6: Each set of the pluggable storage engine infrastructure components are designed to offer a selective set of benefits for a particular application Some of the key differentiations include: Concurrency -- some applications have more granular lock requirements (such as row-level locks) than others. Choosing the right locking strategy can reduce overhead and therefore help with overall performance. This area also includes support for capabilities like multi-version concurrency control or 'snapshot'? read. Transaction Support - not every application needs transactions, but for those that do, there are very well defined requirements like ACID compliance and more. Referential Integrity - the need to have the server enforce relational database referential integrity through DDL defined foreign keys. Physical Storage - this involves everything from the overall page size for tables and indexes as well as the format used for storing data to physical disk. Index Support - different application scenarios tend to benefit from different index strategies, and so each storage engine generally has its own indexing methods, although some (like B-tree indexes) are common to nearly all engines. Memory Caches - different applications respond better to some memory caching strategies than others, so while some memory caches are common to all storage engines (like those used for user connections, MySQL's high-speed Query Cache, etc.), others are uniquely defined only when a particular storage engine is put in play. Performance Aids - includes things like multiple I/O threads for parallel operations, thread concurrency, database checkpointing, bulk insert handling, and more. Miscellaneous Target Features - this may include things like support for geospatial operations, security restrictions for certain data manipulation operations, and other like items.
- #7: The MySQL storage engines provide flexibility to database designers, and also to allow for the server to take advantage of different types of storage media. Database designers can choose the appropriate storage engines based on their application’s needs. each one comes with a distinct set of benefits and drawbacks As we discuss each of the available storage engines in depth, keep in mind the following questions: · What type of data will you eventually be storing in your MySQL databases? · Is the data constantly changing? · Is the data mostly logs (INSERTs)? · Are your end users constantly making requests for aggregated data and other reports? · For mission-critical data, will there be a need for foreign key constraints or multiplestatement transaction control? The answers to these questions will affect the storage engine and data types most appropriate for your particular application.
- #8: MyISAM excels at high-speed operations that don't require the integrity guarantees (and associated overhead) of transactions MyISAM locks entire tables, not rows. Readers obtain shared (read) locks on all tables they need to read. Writers obtain exclusive (write) locks. However, you can insert new rows into the table while select queries are running against it (concurrent inserts). This is a very important and useful feature. Read-only or read-mostly tables Tables that contain data used to construct a catalog or listing of some sort (jobs, auctions, real estate, etc.) are usually read from far more often than they are written to. This makes them good candidates for MyISAM It is a great engine for data warehouses because of that environment's high read-to-write ratio and the need to fit large amounts of data in a small amount of space MyISAM doesn't support transactions or row-level locks. MyISAM is not a good general purpose storage engine for any application that has: a) high concurrency b) lots of UPDATEs or DELETEs (INSERTs and SELECTs are fine)
- #9: InnoDB - supports ACID transactions, multi-versioning, row-level locking, foreign key constraints, crash recovery, and good query performance depending on indexes. InnoDB uses row-level locking with multiversion concurrency control (MVCC). MVCC can allow fewer row locks by keeping data snapshots. Depending on the isolation level, InnoDB does not require any locking for a SELECT. This makes high concurrency possible, with some trade-offs: InnoDB requires more disk space compared to MyISAM, and for the best performance, lots of memory is required for the InnoDB buffer pool. InnoDB is a good choice for any order processing application, any application where transactions are required. InnoDB was designed for transaction processing. Its performance and automatic crash recovery make it popular for non transactional storage needs, too. When you deal with any sort of order processing, transactions are all but required. Another important consideration is whether the engine needs to support foreign key constraints.
- #10: Memory - stores all data in RAM for extremely fast access. Useful when you need fast access to data that doesn't change or doesn't need to persist after a restart. Good for &quot;lookup&quot; or &quot;mapping&quot; tables, for caching the results of periodically aggregated data, for intermediate results when analyzing data. The Memory Engine tables are useful when you need fast access to data that either never changes or doesn't need to persist after a restart. Memory tables are generally faster . All of their data is stored in memory, so queries don't have to wait for disk I/O. The table structure of a Memory table persists across a server restart, but no data survives. good uses for Memory tables:For &quot;lookup&quot; or &quot;mapping&quot; tables, such as a table that maps postal codes to state names For caching the results of periodically aggregated data For intermediate results when analyzing data Memory tables support HASH indexes, which are very fast for lookup queries. . They use table-level locking, which gives low write concurrency, and they do not support TEXT or BLOB column types. They also support only fixed-size rows, so they really store VARCHARs as CHARs, which can waste memory.
- #11: Archive tables are ideal for logging and data acquisition, where analysis tends to scan an entire table, or where you want fast INSERT queries on a replication master. # Archive - provides for storing and retrieving large amounts of seldom-referenced historical, archived, or security audit information. More specialized engines: FEDERATED – Kind of like “linked tables” in MS SQL Server or MS Access. Allows a remote server's tables to be used as if they were local. Not good performance, but can be useful at times. NdbCluster – Highly-available clustered storage engine. Very specialized and much harder to administer than regular MySQL storage engines CSV – stores in tab-delimited format. Useful for large bulk imports or exports Blackhole – the /dev/null storage engine. Useful for benchmarking and some replication scenarios # Merge - allows to logically group together a series of identical MyISAM tables and reference them as one object. Good for very large DBs like data warehousing.
- #14: you can use multiple storage engines in a single application; you are not limited to using only one storage engine in a particular database. So, you can easily mix and match storage engines for the given application need. This is often the best way to achieve optimal performance for truly demanding applications: use the right storage engine for the right job. You can use multiple storage engines in a single application. This is particularly useful in a replication setup where a master copy of a database on one server is used to supply copies, called slaves, to other servers. A storage engine for a table in a slave can be different than a storage engine for a table in the master. In this way, you can take advantage of each engine's abilities. For instance, assume a master with two slaves environment. We can have InnoDB tables on the master, for referential integrity and transactional safety. One slave can also be set up with innoDB or the ARCHIVE engine in order to do backups in a consistent state. Another can be set up with MyISAM and MEMORY tables in order to take advantage of FULLTEXT (MyISAM) or HASH-based indexing (MEMORY).
- #17: In a normalized database, each fact is represented once and only once. Conversely, in a denormalized database, information is duplicated, or stored in multiple places. People who ask for help with performance issues are frequently advised to normalize their schemas, especially if the workload is write-heavy. This is often good advice. It works well for the following reasons: Normalized updates are usually faster than denormalized updates. When the data is well normalized, there's little or no duplicated data, so there's less data to change. Normalized tables are usually smaller, so they fit better in memory and perform better. The lack of redundant data means there's less need for DISTINCT or GROUP BY queries when retrieving lists of values. Consider the preceding example: it's impossible to get a distinct list of departments from the denormalized schema without DISTINCT or GROUP BY, but if DEPARTMENT is a separate table, it's a trivial query. The drawbacks of a normalized schema usually have to do with retrieval. Any nontrivial query on a well-normalized schema will probably require at least one join, and perhaps several. This is not only expensive, but it can make some indexing strategies impossible. For example, normalizing may place columns in different tables that would benefit from belonging to the same index.
- #18: Normalization is the process of efficiently organizing data in a database. There are two goals of the normalization process: eliminating redundant data (for example, storing the same data in more than one table) and ensuring data dependencies make sense (only storing related data in a table). Both of these are worthy goals as they reduce the amount of space a database consumes and ensure that data is logically stored. Database normalization minimizes duplication of information, this makes updates simpler and faster because the same information doesn't have to be updated in multiple tables. With a normalized database: * updates are usually faster. * there's less data to change. * tables are usually smaller, use less memory, which can give better performance. * better performance for distinct or group by queries
- #19: In a normalized database, each fact is represented once and only once. Conversely, in a denormalized database, information is duplicated, or stored in multiple places. People who ask for help with performance issues are frequently advised to normalize their schemas, especially if the workload is write-heavy. This is often good advice. It works well for the following reasons: Normalized updates are usually faster than denormalized updates. When the data is well normalized, there's little or no duplicated data, so there's less data to change. Normalized tables are usually smaller, so they fit better in memory and perform better. The lack of redundant data means there's less need for DISTINCT or GROUP BY queries when retrieving lists of values. Consider the preceding example: it's impossible to get a distinct list of departments from the denormalized schema without DISTINCT or GROUP BY, but if DEPARTMENT is a separate table, it's a trivial query. The drawbacks of a normalized schema usually have to do with retrieval. Any nontrivial query on a well-normalized schema will probably require at least one join, and perhaps several. This is not only expensive, but it can make some indexing strategies impossible. For example, normalizing may place columns in different tables that would benefit from belonging to the same index.
- #20: In a denormalized database, information is duplicated, or stored in multiple places. The disadvantages of a normalized schema are queries typically involve more tables and require more joins which can reduce performance. Also normalizing may place columns in different tables that would benefit from belonging to the same index, which can also reduce query performance. More normalized schemas are better for applications involving many transactions, less normalized are better for reporting types of application. You should normalize your schema first, then de-normalize later. Applications often need to mix the approaches, for example use a partially normalized schema, and duplicate, or cache, selected columns from one table in another table. A denormalized schema works well because everything is in the same table, which avoids joins. If you don't need to join tables, the worst case for most queries—even the ones that don't use indexes—is a full table scan. This can be much faster than a join when the data doesn't fit in memory, because it avoids random I/O. A single table can also allow more efficient indexing strategies. In the real world, you often need to mix the approaches, possibly using a partially normalized schema, cache tables, and other techniques. The most common way to denormalize data is to duplicate, or cache, selected columns from one table in another table.
- #21: In general, try to use the smallest data type that you can. Small and simple data types usually give better performance because it means fewer disk accesses (less I/O), more data in memory, and less CPU to process operations.
- #22: If you're storing whole numbers, use one of the integer types: TINYINT, SMALLINT, MEDIUMINT, INT, or BIGINT. These require 8, 16, 24, 32, and 64 bits of storage space, respectively. They can store values from –2(N–1) to 2(N–1)–1, where N is the number of bits of storage space they use. FLOAT, DOUBLE: supports approximate calculations with standard floating-point math. DECIMAL: use DECIMAL when you need exact results, always use for monetary/currency fields. Floating-point types typically use less space than DECIMAL to store the same range of values use DECIMAL only when you need exact results for fractional numbers BIT: to store 0,1 values.
- #23: INT(1) does not mean 1 digit! The number in parentheses is the ZEROFILL argument, and specifies the number of characters some tools reserve for display purposes. For storage and computational purposes, INT(1) is identical to INT(20). Integer data types work best for primary key data types. Use UNSIGNED when you don't need negative numbers, this doubles the bits of storage space. BIGINT is not needed for AUTO_INCREMENT, INT UNSIGNED stores 4.3 billion values! Always use DECIMAL for monetary/currency fields, never use FLOAT or DOUBLE!
- #24: The CHAR and VARCHAR types are declared with a length that indicates the maximum number of characters to store. VARCHAR(n) stores variable-length character strings. VARCHAR uses only as much space as it needs, which helps performance because it saves disk space.. However, because the rows are variable-length, they can grow when you update them, which can cause extra work. use VARCHAR when the maximum column length is much larger than the average length; when updates to the field are rare, so fragmentation is not a problem; CHAR(n) is fixed-length: MySQL allocates enough space for the specified number of characters. Useful to store very short strings, when all the values are nearly the same length, and for data that's changed frequently. AR is also better than VARCHAR for data that's changed frequently, Changing an ENUM or SET field's definition requires an entire rebuild of the table . When VARCHAR Is Bad VARCHAR(255) Poor Design - No understanding of underlying data Disk usage may be efficient MySQL internal memory usage is not
- #25: Use NOT NULL always unless you want or really expect NULL values You should define fields as NOT NULL whenever you can.It's harder for MySQL to optimize queries that refer to nullable columns, because they make indexes, index statistics, and value comparisons more complicated.if you're planning to index columns, avoid making them nullable if possible. NOT NULL Saves up to a byte per column per row of data Double benefit for indexed columns NOT NULL DEFAULT '' is bad design
- #26: smaller is usually better. In general, try to use the smallest data type that can correctly store and represent your data. Simple is good. Fewer CPU cycles are typically required to process operations on simpler data types. Disk = Memory = Performance Every single byte counts Less disk accesses and more data in memory
- #27: Indexes are data structures that help retrieve row data with specific column values faster. Indexes can especially improve performance for larger data bases. ,but they do have some downsides. Index information needs to be updated every time there are changes made to the table. This means that if you are constantly updating, inserting and removing entries in your table this could have a negative impact on performance. You can add an index to a table with CREATE INDEX
- #29: Most MySQL storage engines support B-tree indexes. a B-tree is a tree data structure that sorts data values, tree nodes define the upper and lower bounds of the values in the child nodes. B-trees are kept balanced by requiring that all leaf nodes are at the same depth. MyISAM Leaf nodes have pointers to the row data corresponding to the index key .
- #30: In a clustered layout, the leaf nodes actually contain all the data for the record (not just the index key, like in the non-clustered layout) so When looking up a record by a primary key, for a clustered layout/organization, the lookup operation (following the pointer from the leaf node to the data file) involved in a non-clustered layout is not needed. InnoDB leaf nodes refers to the index by its primary key values. InnoDB's clustered indexes store the row data in the leaf nodes, it's called clustered because rows with close primary key values are stored close to each other. This can make retrieving indexed data fast, since the data is in the index. But this can be slower for updates , secondary indexes, and for full table scans.
- #32: Covering Indexes are indexes that contain all the data values needed for a query, these queries can improve performance because the row does not have to be read. Covering indexes When MySQL can locate every field needed for a specific table within an index (as opposed to the full table records) the index is known as a covering index . Covering indexes are critically important for performance of certain queries and joins. When a covering index is located and used by the optimizer, you will see “ Using index” show up in the Extra column of the EXPLAIN output.
- #33: You need to understand the SQL queries your application makes and evaluate their performance To Know how your query is executed by MySQL, you can harness the MySQL slow query log and use EXPLAIN. Basically you want to make your queries access less data: is your application retrieving more data than it needs, are queries accessing too many rows or columns? is MySQL analyzing more rows than it needs? Indexes are a good way to reduce data access. When you precede a SELECT statement with the keyword EXPLAIN, MySQL displays information from the optimizer about the query execution plan. That is, MySQL explains how it would process the SELECT, including information about how tables are joined and in which order. With the help of EXPLAIN, you can see where you should add indexes to tables to get a faster SELECT that uses indexes to find rows. You can also use EXPLAIN to check whether the optimizer joins the tables in an optimal order. Developers should run EXPLAIN on all SELECT statements that their code is executing against the database. This ensures that missing indexes are picked up early in the development process and gives developers insight into how the MySQL optimizer has chosen to execute the query.
- #34: MySQL Query Analyzer The MySQL Query Analyzer is designed to save time and effort in finding and fixing problem queries. It gives DBAs a convenient window, with instant updates and easy-to-read graphics, The analyzer can do simple things such as tell you how long a recent query took and how the optimizer handled it (the results of EXPLAIN statements). But it can also give historical information such as how the current runs of a query compare to earlier runs. Most of all, the analyzer will speed up development and deployment because sites will use it in conjunction with performance testing and the emulation of user activity to find out where the choke points are in the application and how they can expect it to perform after deployment. The MySQL Query Analyzer saves time and effort in finding and fixing problem queries by providing: Aggregated view into query execution counts, run time, result sets across all MySQL servers with no dependence on MySQL logs or SHOW PROCESSLIST Sortable views by all monitored statisticsSearchable and sortable queries by query type, content, server, database, date/time, interval range, and &quot;when first seen&quot;Historical and real-time analysis of all queries across all serversDrill downs into sampled query execution statistics, fully qualified with variable substitutions, and EXPLAIN results The new MySQL Query Analyzer was added into the MySQL Enterprise Monitor and it packs a lot of punch for those wanting to ensure their systems are free of bad running SQL code. let me tell you the two things I particularly like about it from a DBA perspective: 1. It's Global: If you have a number of servers, you'll love what Query Analyzer does for you. Even Oracle and other DB vendors only provide single-server views of bad SQL that runs across their servers. Query Analyzer bubbles to the top the worst SQL across all your servers – which is a much more efficient way to work. No more wondering what servers you need to spend your time on or which have the worst code. 2. It's Smart: Believe it or not, sometimes it's not slow-running SQL that kills your system – it's SQL that executes way more times than you think it is. You really couldn't see this well before Query Analyzer, but now you can. One customer already shaved double-digits off their response time by finding queries that were running more much than they should have been. And that's just one area Query Analyzer looks at; there's much more intelligence there too, along with other stats you can't get from the general server utilities.
- #35: When you precede a SELECT statement with the keyword EXPLAIN, MySQL displays information from the optimizer about the query execution plan. That is, MySQL explains how it would process the SELECT, including information about how tables are joined and in which order. With the help of EXPLAIN, you can see where you should add indexes to tables to get a faster SELECT that uses indexes to find rows. You can also use EXPLAIN to check whether the optimizer joins the tables in an optimal order. EXPLAIN returns a row of information for each &quot;table&quot; used in the SELECT statement, which shows each part and the order of the execution plan. The &quot;table&quot; can mean a real schema table, a derived or temporary table, a subquery, a union result... Developers should run EXPLAIN on all SELECT statements that their code is executing against the database. This ensures that missing indexes are picked up early in the development process and gives developers insight into how the MySQL optimizer has chosen to execute the query.
- #36: . With the help of EXPLAIN, you can see where you should add indexes to tables to get a faster SELECT that uses indexes to find rows. You can also use EXPLAIN to check whether the optimizer joins the tables in an optimal order. EXPLAIN returns a row of information for each &quot;table&quot; used in the SELECT statement, which shows each part and the order of the execution plan. The &quot;table&quot; can mean a real schema table, a derived or temporary table, a subquery, a union result. rows: the number of rows MySQL estimates it must examine to execute the query. type The “access strategy” used to grab the data in this set possible_keys keys available to optimizer keys keys chosen by the optimizer rows An estimate of the number of rows Extra Extra information the optimizer chooses to give you Extra: additional information about how MySQL resolves the query. Watch out for Extra values of Using filesort and Using temporary. Using index means information is retrieved from the table using only information in the index tree without having to do an additional seek to read the actual row. This strategy can be used when the query uses only columns that are part of a single index (Covering Index).
- #37: . With the help of EXPLAIN, you can see where you should add indexes to tables to get a faster SELECT that uses indexes to find rows. You can also use EXPLAIN to check whether the optimizer joins the tables in an optimal order. EXPLAIN returns a row of information for each &quot;table&quot; used in the SELECT statement, which shows each part and the order of the execution plan. The &quot;table&quot; can mean a real schema table, a derived or temporary table, a subquery, a union result. rows: the number of rows MySQL estimates it must examine to execute the query. type The “access strategy” used to grab the data in this set possible_keys keys available to optimizer keys keys chosen by the optimizer rows An estimate of the number of rows Extra Extra information the optimizer chooses to give you Extra: additional information about how MySQL resolves the query. Watch out for Extra values of Using filesort and Using temporary. Using index means information is retrieved from the table using only information in the index tree without having to do an additional seek to read the actual row. This strategy can be used when the query uses only columns that are part of a single index (Covering Index).
- #38: How do you know if a scan is used? In the EXPLAIN output, the “type” for the table/set will be “ALL” or “index”. “ALL” means a full table data record scan is performed. “index” means a full index record scan. Avoid them by ensuring indexes are on columns that are used in the WHERE, ON, and GROUP BY clauses.
- #39: system, or const: very fast because the table has at most one matching row (For example a primary key used in the WHERE) The const access strategy is just about as good as you can get from the optimizer. It means that a WHERE clause was provided in the SELECT statement that used: ● an equality operator ● on a field indexed with a unique non-nullable key ● and a constant value was supplied The access strategy of system is related to const and refers to when a table with only a single row is referenced in the SELECT
- #40: let's assume we need to find all rentals that were made between the 14th and 16th of June, 2005. We'll need to make a change to our original SELECT statement to use a BETWEEN operator: SELECT * FROM rental WHERE rental_date BETWEEN '2005-06-14' AND '2005-06-16'G As you can see, the access strategy chosen by the optimizer is the range type. This makes perfect sense, since we are using a BETWEEN operator in the WHERE clause. The BETWEEN operator deals with ranges, as do <, <=, IN, >, >=. The MySQL optimizer is highly optimized to deal with range optimizations. Generally, range operations are very quick, but here's some things you may not be aware of regarding the range access strategy: An index must be available on the field operated upon by a range operator If too many records are estimated to be returned by the condition, the range operator won't be used an index or a full table scan will instead be preferred The field must not be operated on by a function call
- #41: To demonstrate this scan versus seek choice, the range query has been modified to include a larger range of rental_dates. the optimizer is no longer using the range access strategy, because the number of rows estimated to be matched by the range condition > certain % of total rows in the table which the optimizer uses to determine whether to perform a single scan or a seek operation for each matched record. In this case, the optimizer chose to perform a full table scan, which corresponds to the ALL access strategy you see in the type column of the EXPLAIN output
- #42: The scan vs seek dilemma Behind the scenes, the MySQL optimizer has to decide what access strategy to use in order to retrieve information from the storage engine. One of the decisions it must make is whether to do a seek operation or a scan operation. A seek operation, generally speaking, jumps into a random place -- either on disk or in memory -- to fetch the data needed. The operation is repeated for each piece of data needed from disk or memory. A scan operation, on the other hand, will jump to the start of a chunk of data, and sequentially read data -- either from disk or from memory -- until the end of the chunk of data. With large amounts of data, sequentially scanning through contiguous data on disk or in memory is faster than performing many random seek operations. MySQL keeps stats about the uniqueness of values in an index in order to estimate the rows returned (rows in the explain output). If the estimated number of matched rows is greater than a certain % of total rows in the table, then MySQL will do a scan.
- #43: The ALL access strategy (Full Table Scan) The full table scan (ALL type column value) is definitely something you want to watch out for, particularly if: ? You are not running a data warehouse scenario ? You are supplying a WHERE clause to the SELECT ? You have very large data sets Sometimes, full table scans cannot be avoided -- and sometimes they can perform better than other access strategies -- but generally they are a sign of a lack of proper indexing on your schema. If you don't have an appropriate index, no range optimization
- #44: Covering Indexes are indexes that contain all the data values needed for a query, these queries can improve performance because the row does not have to be read. Covering indexes When MySQL can locate every field needed for a specific table within an index (as opposed to the full table records) the index is known as a covering index . Covering indexes are critically important for performance of certain queries and joins. When a covering index is located and used by the optimizer, you will see “ Using index” show up in the Extra column of the EXPLAIN output.
- #45: Remember that “index” in the type column means a full index scan. “ Using index” in the Extra column means a covering index is being used. The benefit of a covering index is that MySQL can grab the data directly from the index records and does not need to do a lookup operation into the data file or memory to get additional fields from the main table records. One of the reasons that using SELECT * is not a recommended practice is because by specifying columns instead of *, you have a better chance of hitting a covering index.
- #46: . With the help of EXPLAIN, you can see where you should add indexes to tables to get a faster SELECT that uses indexes to find rows. You can also use EXPLAIN to check whether the optimizer joins the tables in an optimal order. EXPLAIN returns a row of information for each &quot;table&quot; used in the SELECT statement, which shows each part and the order of the execution plan. The &quot;table&quot; can mean a real schema table, a derived or temporary table, a subquery, a union result. rows: the number of rows MySQL estimates it must examine to execute the query. type The “access strategy” used to grab the data in this set possible_keys keys available to optimizer keys keys chosen by the optimizer rows An estimate of the number of rows Extra Extra information the optimizer chooses to give you Extra: additional information about how MySQL resolves the query. Watch out for Extra values of Using filesort and Using temporary. Using index means information is retrieved from the table using only information in the index tree without having to do an additional seek to read the actual row. This strategy can be used when the query uses only columns that are part of a single index (Covering Index).
- #47: Indexes can quickly find the rows that match a WHERE clause, however this works only if the index is NOT used in a function or expression in the WHERE clause.
- #48: In the 1 st example a fast range &quot;access strategy&quot; is chosen by the optimizer, and the index scan on title is used to winnow the query results down. 2 nd example A slow full table scan (the ALL&quot;access strategy&quot;) is used because a function (LEFT) is operating on the title column. Operating on an indexed column with a function (in this case the LEFT() function) means the optimizer cannot use the index to satisfy the query. Typically, you can rewrite queries in order to not operate on an indexed column with a function.
- #49: the main goal of partitioning is to reduce the amount of data read for particular SQL operations so that the overall response time is reduced Vertical Partitioning – this partitioning scheme is traditionally used to reduce the width of a target table by splitting a table vertically so that only certain columns are included in a particular dataset, with each partition including all rows. An example of vertical partitioning might be a table that contains a number of very wide text or BLOB columns that aren't addressed often being broken into two tables that has the most referenced columns in one table and the seldom-referenced text or BLOB data in another. Horizontal Partitioning – this form of partitioning segments table rows so that distinct groups of physical row-based datasets are formed that can be addressed individually (one partition) or collectively (one-to-all partitions). All columns defined to a table are found in each set of partitions so no actual table attributes are missing. An example of horizontal partitioning might be a table that contains historical data being partitioned by date.
- #50: An example of vertical partitioning might be a table that contains a number of very wide text or BLOB columns that aren't addressed often being broken into two tables that has the most referenced columns in one table and the seldom-referenced text or BLOB data in another. • limit number of columns per table • split large, infrequently used columns into a separate one-to-one table By removing the VARCHAR column from the design, you actually get a reduction in query response time. Beyond partitioning, this speaks to the effect wide tables can have on queries and why you should always ensure that all columns defined to a table are actually needed.
- #54: Here is an example of improving a query: SELECT * FROM Orders WHERE TO_DAYS(CURRENT_DATE()) – TO_DAYS(order_created) <= 7; First, we are operating on an indexed column (order_created) with a function TO_DAYS – let's fix that: SELECT * FROM Orders WHERE order_created >= CURRENT_DATE() - INTERVAL 7 DAY;
- #55: Although we rewrote the WHERE expression to remove the function on the index, we still have a non-deterministic function CURRENT_DATE() in the statement, which eliminates this query from being placed in the query cache. Any time a non-deterministic function is used in a SELECT statement, the query cache ignores the query. In read-intensive applications, this can be a significant performance problem. – let's fix that: SELECT * FROM Orders WHERE order_created >= '2008-01-11' - INTERVAL 7 DAY; We replaced the function with a constant (probably using our application programming language). However, we are specifying SELECT * instead of the actual fields we need from the table. What if there is a TEXT field in Orders called order_memo that we don't need to see? Well, having it included in the result means a larger result set which may not fit into the query cache and may force a disk-based temporary table. – let's fix that: SELECT order_id, customer_id, order_total, order_created FROM Orders WHERE order_created >= '2008-01-11' - INTERVAL 7 DAY;
- #56: An important new 5.1 feature is horizontal partitioning # Increased performance – during scan operations, the MySQL optimizer knows what partitions contain the data that will satisfy a particular query and will access only those necessary partitions during query execution. Partitioning is best suited for VLDB's that contain a lot of query activity that targets specific portions/ranges of one or more database tables. other situations lend themselves to partitioning as well (e.g. data archiving, etc.) good for datawarehousing not designed for OLTP environments
- #58: Lazy loading and JPA With JPA many-to-one and many-to-many relationships lazy load by default , meaning they will be loaded when the entity in the relationship is accessed. Lazy loading is usually good, but if you need to access all of the &quot;many&quot; objects in a relationship, it will cause n+1 selects where n is the number of &quot;many&quot; objects. You can change the relationship to be loaded eagerly as follows : public class Employee{ @OneToMany(mappedBy = &quot;employee&quot;, fetch = FetchType.EAGER) private Collection<Address> addresses; ..... } However you should be careful with eager loading which could cause SELECT statements that fetch too much data. It can cause a Cartesian product if you eagerly load entities with several related collections. If you want to temporarily override the LAZY fetch type, you could use Fetch Join. For example this query would eagerly load the employee addresses: @NamedQueries({ @NamedQuery(name=&quot;getItEarly&quot;, query=&quot;SELECT e FROM Employee e JOIN FETCH e.addresses&quot;)}) public class Employee{ ..... }
- #59: Lazy loading and JPA With JPA many-to-one and many-to-many relationships lazy load by default , meaning they will be loaded when the entity in the relationship is accessed. Lazy loading is usually good, but if you need to access all of the &quot;many&quot; objects in a relationship, it will cause n+1 selects where n is the number of &quot;many&quot; objects. You can change the relationship to be loaded eagerly as follows : public class Employee{ @OneToMany(mappedBy = &quot;employee&quot;, fetch = FetchType.EAGER) private Collection<Address> addresses; ..... } However you should be careful with eager loading which could cause SELECT statements that fetch too much data. It can cause a Cartesian product if you eagerly load entities with several related collections. If you want to temporarily override the LAZY fetch type, you could use Fetch Join. For example this query would eagerly load the employee addresses: @NamedQueries({ @NamedQuery(name=&quot;getItEarly&quot;, query=&quot;SELECT e FROM Employee e JOIN FETCH e.addresses&quot;)}) public class Employee{ ..... }
- #68: Facebook is an excellent example of a company that started using MySQL in its infancy and has scaled MySQL to become one of the top 10 most trafficked web sites in the world. Facebook uses deploys hundreds of MySQL Servers with Replication in multiple data centers to manage: - 175M active users - 26 billion photos - Serve 250,000 photos every second Facebook is also a heavy user of Memcached, an open source caching layer to improve performance and scalability: - Memcache handles 50,000-100,000 requests/second alleviating the database burden MySQL also helps Facebook manage their Facebook applications 20,000 applications which are helping other web properties grow exponentially. iLike (Music Sharing) added 20,000 users/hour after launching their facebook application
- #69: - eBay is a heavy Oracle user, but Oracle was become too expensive and it was cost-prohibitive to deploy new applications.b - MySQL is used to run the eBay’s Personalization Platform which serves advertisements based on user interest. - A business critical system running on MySQL Enterprise for one of the largest scale websites in the world - Highly scalable and low cost system that handles all of eBay’s personalization and session data needs - Ability to handle 4 billion requests per day of 50/50 read/write operations for approximately 40KB of data per user / session - Approx 25 Sun 4100’s running 100% of eBay’s personalization and session data service (2 CPU, Dual core Opteron, 16 GB RAM, Solaris 10 x86) - Highly manageable system for entire operational life cycle - Leveraging MySQL Enterprise Dashboard as a critical tool in providing insight into system performance, trending, and identifying issues - Adding new applications to ebay.com domain that previously would have been in a different domain because of cookie constraints - Creating several new business opportunities that would not have been possible without this new low cost personalization platform - Leveraging MySQL Memory Engine for other types of caching tiers that are enabling new business opportunities
- #70: Zappos is one of the world's largest online retailers with over $1 billion in annual sales. They focus on selling shoes, handbags, eyewear as well as other apparel. However their primary focus is delivering superior customers service. They believe delivering the best customer services is key to a successful online shopping experience. MySQL plays a critical role in delivering that customer service by providing Zappos with: High performance and scalability enabling millions of customers to shop on Zappos.com every day. 99.99% database availability so that Zappos' customers don't experience service interruptions that impact revenue - A cost-effective solution saving Zappos over $1 million per year, allowing them to spend more money on their customer service and less on their technical infrastructure. Since Zappos was founded in 1999 they have used MySQL as their primary database to power their web site, internal tools and reporting tasks. In the early days of Zappos, they could not afford a proprietary enterprise database. But, as Zappos has grown, MySQL has been able to scale with their business making it a perfect solution even at their current sales volume. Its been an important piece of infrastructure that they have scaled as the company has grown to $1 billion in sales. Compared to proprietary enterprise systems, Zappos estimates they are saving about $1 million per year in licensing fees and salaries of dedicated DBAs that can only manage individual systems. In the lifetime of Zappos, they estimate they have saved millions of dollars using MySQL.