Native Support of Prometheus Monitoring in Apache Spark 3.0
5 likes2,640 views

All production environment requires monitoring and alerting. Apache Spark also has a configurable metrics system in order to allow users to report Spark metrics to a variety of sinks. Prometheus is one of the popular open-source monitoring and alerting toolkits which is used with Apache Spark together.































![Select a single Spark app
rate(metrics_executor_totalTasks_total{...}[1m])](https://image.slidesharecdn.com/406dongjoonhyundbtsai-200627154223/85/Native-Support-of-Prometheus-Monitoring-in-Apache-Spark-3-0-33-320.jpg)


![Set spark.sql.streaming.metricsEnabled=true (default:false)
Monitoring streaming job behavior (1/2)
Metrics
• latency
• inputRate-total
• processingRate-total
• states-rowsTotal
• states-usedBytes
• eventTime-watermark
Prefix of streaming query metric names
• metrics_[namespace]_spark_streaming_[queryName]
•](https://image.slidesharecdn.com/406dongjoonhyundbtsai-200627154223/85/Native-Support-of-Prometheus-Monitoring-in-Apache-Spark-3-0-36-320.jpg)



































Ad
More Related Content
What's hot (20)
Similar to Native Support of Prometheus Monitoring in Apache Spark 3.0 (20)











![The power of linux advanced tracer [POUG18]](https://cdn.slidesharecdn.com/ss_thumbnails/thepoweroflinuxadvancedtracer-180909125236-thumbnail.jpg?width=560&fit=bounds)






Ad
More from Databricks (20)




















Ad
Recently uploaded (20)















![PRE-NATAL GRnnnmnnnnmmOWTH seminar[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/pre-natalgrowthseminar1-250427093235-de04befc-thumbnail.jpg?width=560&fit=bounds)




Native Support of Prometheus Monitoring in Apache Spark 3.0
- 1. Native Support of Prometheus Monitoring in Apache Spark 3 Dongjoon Hyun DB Tsai SPARK+AI SUMMIT 2020
- 2. Who am I Dongjoon Hyun Apache Spark PMC and Committer Apache ORC PMC and Committer Apache REEF PMC and Committer https://github.com/dongjoon-hyun https://www.linkedin.com/in/dongjoon @dongjoonhyun
- 3. Who am I DB Tsai Apache Spark PMC and Committer Apache SystemML PMC and Committer Apache Yunikorn Committer Apache Bahir Committer https://github.com/dbtsai https://www.linkedin.com/in/dbtsai @dbtsai
- 4. Three popular methods Monitoring Apache Spark Web UI (Live and History Server) • Jobs, Stages,Tasks, SQL queries • Executors, Storage Logs • Event logs and Spark process logs • Listeners (SparkListener, StreamingQueryListener, SparkStatusTracker, …) Metrics • Various numeric values
- 5. Early warning instead of post-mortem process Metrics are useful to handle gray failures Monitoring and alerting Spark jobs’gray failures • Memory Leak or misconfiguration • Performance degradation • Growing streaming job’s inter-states
- 6. An open-source systems monitoring and alerting toolkit Prometheus Provides • a multi-dimensional data model • operational simplicity • scalable data collection • a powerful query language A good option for Apache Spark Metrics Prometheus Server Prometheus Web UI Alert Manager Pushgateway https://en.wikipedia.org/wiki/Prometheus_(software)
- 7. Using JmxSink and JMXExporter combination Spark 2 with Prometheus (1/3) Enable Spark’s built-in JmxSink in Spark’s conf/metrics.properties Deploy Prometheus' JMXExporter library and its config file Expose JMXExporter port, 9404, to Prometheus Add `-javaagent` option to the target (master/worker/executor/driver/…) -javaagent:./jmx_prometheus_javaagent-0.12.0.jar=9404:config.yaml
- 8. Using GraphiteSink and GraphiteExporter combination Spark 2 with Prometheus (2/3) Set up Graphite server Enable Spark’s built-in Graphite Sink with several configurations Enable Prometheus’GraphiteExporter at Graphite
- 9. Custom sink (or 3rd party Sink) + Pushgateway server Spark 2 with Prometheus (3/3) Set up Pushgateway server Develop a custom sink (or use 3rd party libs) with Prometheus dependency Deploy the sink libraries and its configuration file to the cluster
- 10. Pros and Cons Pros • Used already in production • A general approach Cons • Difficult to setup at new environments • Some custom libraries may have a dependency on Spark versions
- 11. Easy usage Goal in Apache Spark 3 Be independent from the existing Metrics pipeline • Use new endpoints and disable it by default • Avoid introducing new dependency Reuse the existing resources • Use official documented ports of Master/Worker/Driver • Take advantage of Prometheus Service Discovery in K8s as much as possible
- 12. What's new in Spark 3 Metrics
- 13. SPARK-29674 / SPARK-29557 DropWizard Metrics 4 for JDK11 Timeline 2.3 3.02.41.6 2.1 2.22.0 4.1.13.1.53.1.2DropWizard Metrics Spark 20202019201820172016Year
- 14. DropWizard Metrics 4.x (Spark 3) SPARK-29674 / SPARK-29557 DropWizard Metrics 4 for JDK11 Timeline DropWizard Metrics 3.x (Spark 1/2) metrics_master_workers_Value 0.0 metrics_master_workers_Value{type="gauges",} 0.0 metrics_master_workers_Number{type=“gauges",} 0.0 2.3 3.02.41.6 2.1 2.22.0 4.1.13.1.53.1.2DropWizard Metrics Spark 20202019201820172016Year
- 15. A new metric source ExecutorMetricsSource Collect executor memory metrics to driver and expose it as ExecutorMetricsSource and REST API (SPARK-23429, SPARK-27189, SPARK-27324, SPARK-24958) • JVMHeapMemory / JVMOffHeapMemory • OnHeapExecutionMemory / OffHeapExecutionMemory • OnHeapStorageMemory / OffHeapStorageMemory • OnHeapUnifiedMemory / OffHeapUnifiedMemory • DirectPoolMemory / MappedPoolMemory • MinorGCCount / MinorGCTime • MajorGCCount / MajorGCTime • ProcessTreeJVMVMemory • ProcessTreeJVMRSSMemory • ProcessTreePythonVMemory • ProcessTreePythonRSSMemory • ProcessTreeOtherVMemory • ProcessTreeOtherRSSMemory JVM Process Tree
- 16. Prometheus-format endpoints Support Prometheus more natively (1/2) PrometheusServlet: A friend of MetricSevlet • A new metric sink supporting Prometheus-format (SPARK-29032) • Unified way of configurations via conf/metrics.properties • No additional system requirements (services / libraries / ports)
- 17. Prometheus-format endpoints Support Prometheus more natively (1/2) PrometheusServlet: A friend of MetricSevlet • A new metric sink supporting Prometheus-format (SPARK-29032) • Unified way of configurations via conf/metrics.properties • No additional system requirements (services / libraries / ports) PrometheusResource: A single endpoint for all executor memory metrics • A new metric endpoint to export all executor metrics at driver (SPARK-29064/SPARK-29400) • The most efficient way to discover and collect because driver has all information already • Enabled by `spark.ui.prometheus.enabled` (default:false)
- 18. spark_info and service discovery Support Prometheus more natively (2/2) Add spark_info metric (SPARK-31743) • A standard Prometheus way to expose version and revision • Monitoring Spark jobs per version Support driver service annotation in K8S (SPARK-31696) • Used by Prometheus service discovery
- 19. Under the hood
- 20. SPARK-29032AddPrometheusServlettomonitorMaster/Worker/Driver PrometheusServlet Make Master/Worker/Driver expose the metrics in Prometheus format at the existing port Follow the output style of "Spark JMXSink + Prometheus JMXExporter + javaagent" way Port Prometheus Endpoint (New in 3.0) JSON Endpoint (Since initial release) Driver 4040 /metrics/prometheus/ /metrics/json/ Worker 8081 /metrics/prometheus/ /metrics/json/ Master 8080 /metrics/master/prometheus/ /metrics/master/json/ Master 8080 /metrics/applications/prometheus/ /metrics/applications/json/
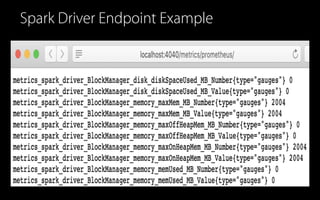
- 21. Spark Driver Endpoint Example
- 22. Use conf/metrics.properties like the other sinks PrometheusServlet Configuration Copy conf/metrics.properties.template to conf/metrics.properties Uncomment like the following in conf/metrics.properties *.sink.prometheusServlet.class=org.apache.spark.metrics.sink.PrometheusServlet *.sink.prometheusServlet.path=/metrics/prometheus master.sink.prometheusServlet.path=/metrics/master/prometheus applications.sink.prometheusServlet.path=/metrics/applications/prometheus
- 23. SPARK-29064AddPrometheusResourcetoexportexecutormetrics PrometheusResource New endpoint with the similar information of JSON endpoint Driver exposes all executor memory metrics in Prometheus format Port Prometheus Endpoint (New in 3.0) JSON Endpoint (Since 1.4) Driver 4040 /metrics/executors/prometheus/ /api/v1/applications/{id}/executors/
- 24. Use spark.ui.prometheus.enabled PrometheusResource Configuration Run spark-shell with configuration Run `curl` with the new endpoint $ bin/spark-shell -c spark.ui.prometheus.enabled=true -c spark.executor.processTreeMetrics.enabled=true $ curl http://localhost:4040/metrics/executors/prometheus/ | grep executor | head -n1 metrics_executor_rddBlocks{application_id="...", application_name="...", executor_id="..."} 0
- 25. Monitoring in K8s cluster
- 26. Key Monitoring Scenarios on K8s clusters Monitoring batch job memory behavior Monitoring dynamic allocation behavior Monitoring streaming job behavior
- 27. Key Monitoring Scenarios on K8s clusters Monitoring batch job memory behavior Monitoring dynamic allocation behavior Monitoring streaming job behavior => A risk to be killed? => Unexpected slowness? => Latency?
- 28. Use Prometheus Service Discovery Monitoring batch job memory behavior (1/2) Configuration Value spark.ui.prometheus.enabled true spark.kubernetes.driver.annotation.prometheus.io/scrape true spark.kubernetes.driver.annotation.prometheus.io/path /metrics/executors/prometheus/ spark.kubernetes.driver.annotation.prometheus.io/port 4040
- 29. Monitoring batch job memory behavior (2/2) spark-submit --master k8s://$K8S_MASTER --deploy-mode cluster -c spark.driver.memory=2g -c spark.executor.instances=30 -c spark.ui.prometheus.enabled=true -c spark.kubernetes.driver.annotation.prometheus.io/scrape=true -c spark.kubernetes.driver.annotation.prometheus.io/path=/metrics/executors/prometheus/ -c spark.kubernetes.driver.annotation.prometheus.io/port=4040 -c spark.kubernetes.container.image=spark:3.0.0 --class org.apache.spark.examples.SparkPi local:///opt/spark/examples/jars/spark-examples_2.12-3.0.0.jar 200000
- 31. Set spark.dynamicAllocation.* Monitoring dynamic allocation behavior spark-submit --master k8s://$K8S_MASTER --deploy-mode cluster -c spark.dynamicAllocation.enabled=true -c spark.dynamicAllocation.executorIdleTimeout=5 -c spark.dynamicAllocation.shuffleTracking.enabled=true -c spark.dynamicAllocation.maxExecutors=50 -c spark.ui.prometheus.enabled=true … (the same) … https://gist.githubusercontent.com/dongjoon-hyun/.../dynamic-pi.py 10000
- 32. Set spark.dynamicAllocation.* Monitoring dynamic allocation behavior spark-submit --master k8s://$K8S_MASTER --deploy-mode cluster -c spark.dynamicAllocation.enabled=true -c spark.dynamicAllocation.executorIdleTimeout=5 -c spark.dynamicAllocation.shuffleTracking.enabled=true -c spark.dynamicAllocation.maxExecutors=50 -c spark.ui.prometheus.enabled=true … (the same) … https://gist.githubusercontent.com/dongjoon-hyun/.../dynamic-pi.py 10000 `dynamic-pi.py` computes Pi, sleeps 1 minutes, and computes Pi again.
- 33. Select a single Spark app rate(metrics_executor_totalTasks_total{...}[1m])
- 34. Inform Prometheus both metrics endpoints Driver service annotation spark-submit --master k8s://$K8S_MASTER --deploy-mode cluster -c spark.ui.prometheus.enabled=true -c spark.kubernetes.driver.annotation.prometheus.io/scrape=true -c spark.kubernetes.driver.annotation.prometheus.io/path=/metrics/prometheus/ -c spark.kubernetes.driver.annotation.prometheus.io/port=4040 -c spark.kubernetes.driver.service.annotation.prometheus.io/scrape=true -c spark.kubernetes.driver.service.annotation.prometheus.io/path=/metrics/executors/prometheus/ -c spark.kubernetes.driver.service.annotation.prometheus.io/port=4040 …
- 36. Set spark.sql.streaming.metricsEnabled=true (default:false) Monitoring streaming job behavior (1/2) Metrics • latency • inputRate-total • processingRate-total • states-rowsTotal • states-usedBytes • eventTime-watermark Prefix of streaming query metric names • metrics_[namespace]_spark_streaming_[queryName] •
- 37. All metrics are important for alert Monitoring streaming job behavior (2/2) latency > micro-batch interval • Spark can endure some situations, but the job needs to be re-design to prevent future outage states-rowsTotal grows indefinitely • These jobs will die eventually due to OOM - SPARK-27340 Alias on TimeWindow expression cause watermark metadata lost (Fixed at 3.0) - SPARK-30553 Fix structured-streaming java example error
- 38. Separation of concerns Prometheus Federation and Alert Prometheus Server Prometheus Web UI Alert Manager Pushgateway namespace1 (User) … Prometheus Server Prometheus Web UI Alert Manager Pushgateway namespace2 (User) Prometheus Server Prometheus Web UI Alert Manager Pushgateway Cluster-wise prometheus (Admin) Metrics for batch job monitoring Metrics for streaming job monitoring a subset of metrics (spark_info + ...)
- 39. New endpoints are still experimental Limitations and Tips New endpoints expose only Spark metrics starting with `metrics_` or `spark_info` • `javaagent` method can expose more metrics like `jvm_info` PrometheusSevlet does not follow Prometheus naming convention • Instead, it's designed to follow Spark 2 naming convention for consistency in Spark The number of metrics grows if we don't set the followings writeStream.queryName("spark") spark.metrics.namespace=spark
- 40. Summary Spark 3 provides a better integration with Prometheus monitoring • Especially, in K8s environment, the metric collections become much easier than Spark 2 New Prometheus style endpoints are independent and additional options • Users can migrate into new endpoints or use them with the existing methods in a mixed way
- 41. Thank you!