NLP todo
Download as PPTX, PDF•0 likes•563 views

The document discusses various natural language processing (NLP) techniques including implementing search, document level analysis, sentence level analysis, and concept extraction. It provides details on tokenization, word normalization, stop word removal, stemming, evaluating search results, parsing and part-of-speech tagging, entity extraction, word sense disambiguation, concept extraction, dependency analysis, coreference, question parsing systems, and sentiment analysis. Implementation details and useful tools are mentioned for various techniques.









NLP todo
- 1. NLP - to do Rohit Verma
- 2. Text Retrieval and Search • Implementing Search • Evaluating Search Results NLP - Document Level Analysis • Parsing and Part of Speech Tagging • Entity Extraction • Word Sense Disambiguation • Concept Extraction • Concept Polarity ( positive, negative , objective) NLP - Sentence Level Analysis • Dependency Analysis and Coreference • Example Question Parsing System • SentimentAnalysis } In progress
- 3. Implementing search 1. Tokenization For each document, we split it into paragraphs, split paragraphs into sentences and sentences into words. Attempt possible spell corrections. 2. Word Normalisation Index text and query terms have same form e.g. match U.S.A and USA, Usually lower cased 3. Stop word Removal An optional step where a predefined list of stop words are removed. More important for small corpuses 4. Stemming - Reduce terms to their stems 4.1 Language dependent - in English, every word has 2 parts, the stem and the affix 4.2 automate(s), automatic, automation => automat, plural forms like cats => cat 4.3 The “stem” may not be an actual word for e.g. consolidating => consolid Evaluating Search Results 1. High Precision 2. High Recall 3. FMeasure
- 4. Extracting Concepts From Text We apply various NLP techniques to analyze the contents of a document. Some example are: Mentions of people, places, locations etc. Central Themes or concepts in the document This is different from search Search follows a pull model where the users take initiative in querying the system for relevant documents. In concept extraction, we can infer abstract concepts from text and push it to interested users. We may also be able to infer the concepts a user is interested in based on the content they consume.
- 5. Sentence Segmentation 1. Periods are ambiguous - Abbreviations, decimals etc. !, ? - Less ambiguous 2. Classifier - rules (using case, punctuation rules etc.), ML etc. 3. StanfordNLP sentence detection and tokenizer Refer : http://nlp.stanford.edu/software/tokenizer.shtml Trained on Penn Bank dataset and is hence suited towards more formal english. 4. OpenNLP has a sentence detection and tokenizer as well. Refer: https://opennlp.apache.org https://github.com/dpdearing/nlp 5. Elasticsearch tokenizer , ES lacks sentence detection but provides various tokenizer for natural languages Refer : https://www.elastic.co/guide/en/elasticsearch/guide/current/languages.html All these libraries perform pretty well for English for Evature integration Elasticsearch is the way for general NLP an evaluation of other libs are required as well Part of Speech Tagging
- 6. Named Entity Recognition Named Entity Recognition is the NLP task of recognizing proper nouns in a document. Named Entity Recognition consists of three steps: 1. Spotting: Statistical model pre-trained on well known corpus data help us “spot” entities in the text. 2. Disambiguation: Once spots are found, we may need to disambiguate them (for e.g. there are multiple entities with the same name and the correct url needs to be retrieved) 3. Filtering - remove named entities whose types we are not interested in or entities that have very few links pointing to them. At the end of NER, we get back a set of url of resources that were referenced e.g. I go to school at <ORGANIZATION>Stanford University</ORGANIZATION>, which is located in <LOCATION>California</LOCATION>. Useful tools 1. While using elasticsearch one can leverage Dbpedia Spotlight, it is an API that can be used to perform all 3 steps of NER Refer: https://github.com/dbpedia-
- 7. Concept Extraction Word sense Disambiguation 1. For many words, multiple senses of the word exists based on the context. For e.g. there are multiple senses for the word “bank” (even within the same part of speech) 2. Extremely difficult for Computers.. A combination of context and common sense information make this quite easy for humans. 3.Word Sense Disambiguation can be useful for 3.1 Machine translation between languages (surface form loses value during translation because the only thing that matters is the sense of the word) 3.2 Information Retrieval - Correct interpretation of the query. However this can be overcome by providing enough terms to only retrieve relevant documents. 3.3 Automatic annotation of text 3.4 Measuring semantic relatedness between documents. Supervised vs. Unsupervised WSD If we have training data, word sense disambiguation reduces to a classification problem. Additional training data may be supplied in the form of dictionary definitions, ontologies such as Medical Subject Headings (MeSH), or lexical resources like WordNet. If there is no training data, word sense disambiguation is a clustering problem. Hierarchical clusterings may make sense; the dictionaries sited above break meanings of the word "run" down into senses and sub-senses. Useful tools Knowledge inventories -> Wordnet*, Wikipedia, Freebase, ConceptNet Collection of processing Algos —> Lingpipe, Deepdive ML libs —> Most of Algos are with Lingpipe/Deepdive, Weka also has some extended libs *WordNet is a hierarchically organized lexical database widely used in NLP applications. Started at Princeton in 1985.
- 8. Concept Graph WordNet does not capture any common sense information. For e.g. bank (financial institution) and money do not have a close relationship in WordNet. It is possible to use other resource like ConceptNet that map common sense knowledge to WordNet (and ontologies like dbpedia). For e.g. we can download mappings for concepts like Money, Love, Sports, Family etc. Another option is to deploy a custom concept graph: Deploy WordNet onto a Graph database that is Neo4j. That forms the base graph. Deploy custom concept mapping to the WordNet synsets. Custom concept mapping can be created in form of ontologies using tools like Protege Add mappings for relevant wikipedia (dbpedia) categories Concept Polarity Opinion mining (OM – also known as “sentiment classification”) is a recent subdiscipline at the crossroads of infor- mation retrieval and computational linguistics which is concerned not with the topic a text is about, but with the opin- ion it expresses. Sentiwordnet is an opensource tool for Opinion mining. E.g. “They are really happy to be here” => happy#a#1 has a very positive polarity. Refer : http://sentiwordnet.isti.cnr.it
- 9. Concept Extraction Architecture Rokitt Level, NLP strategic
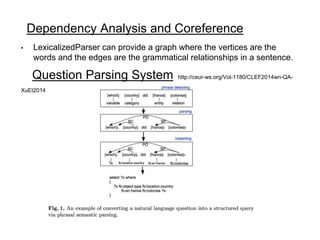
- 10. Dependency Analysis and Coreference • LexicalizedParser can provide a graph where the vertices are the words and the edges are the grammatical relationships in a sentence. Question Parsing System http://ceur-ws.org/Vol-1180/CLEF2014wn-QA- XuEt2014.pdf
- 11. Thoughts• Explore textRank and query suggest based on that rank. Google way • Shallow nlp generally employed in text retrieval and search provide good results for general search use cases. • Deeper NLP involves semantic parsing, common sense interpolation (both local and global knowledge bases) and tends to be harder. • Deeper NLP is more practical after picking a specific domain for e.g. medical records, legal documents etc. • Sentiment Analysis (http://watson-um-demo.mybluemix.net)