



























































































Ad
More Related Content
What's hot (20)
Viewers also liked (20)


















Ad
Similar to Non-Relational Databases at ACCU2011 (20)




















Ad
Recently uploaded (20)




















Non-Relational Databases at ACCU2011
- 1. * databases query_language <> ‘SQL’; Gavin Heavyside - ACCU Conference - 16 April 2011
- 3. Me • Director of Engineering at MyDrive • Hands-on coding in Ruby, C++ & others • Big data, SW architecture, robustness, tdd, devops, data analysis • Background of SW for telecoms, mobile, embedded • @gavinheavyside
- 4. MyDrive Solutions • Driver behaviour analysis and scoring for telematics-based insurance • Large-scale geospatial processing of GPS and map data • Relational DBs - PostgreSQL, MySQL • Non-relational DBs - Redis, HBase • Big Data tools - Hadoop • Built on Linux and open-source stack
- 5. RDBMS
- 6. What is an RDBMS • “Codd’s 12 Rules”, 1970 • Relations • e.g. tables, rows, columns • Relational Operators • Manipulate data in tabular form
- 7. ACID • Atomicity • Consistency • Isolation • Durability
- 8. Atomicity • All or nothing • Maintain atomicity across failures
- 9. Consistency • DB moves from one consistent state to another • Only valid data is written to DB • It can only enforce rules it knows about
- 10. Isolation • Transactions can’t see data from other incomplete transactions • Blocking & Deadlocks • Dirty reads • MVCC
- 11. Locking • Row locking • Whole table locking • TX might require lots of locks • Blocking
- 12. MVCC • Multi-Version Concurrency Control • Maintain several versions of objects • Read & write timestamps on transactions • Reads never blocked
- 13. Durability • Data from successful tx is never lost
- 14. What’s wrong with relational DBs?
- 16. All the cool kids use non-relational DBs... Facebook LinkedIn Twitter Google
- 18. What’s wrong with relational DBs? • Nothing • ‘Impedance Mismatch’ • Scaling
- 19. Scaling an RDBMS • Launch successful service • Read saturation - add caching • Write saturation - add hardware (£££) • Queries slow - denormalise • Reads still too slow - prematerialise common queries, stop joining • Writes too slow - drop secondary indexes and triggers
- 20. Denormalising • Normalise logical data design • Joins • Materialised views can optimise queries • Denormalise logical data design • Eliminate joins • Application must ensure data consistency
- 21. Scaling a distributed DB • Just add more commodity servers... • ...we wish
- 22. CAP Theorem • Eric Brewer, 2000 • Distributed System can’t simultaneously be • Consistent • Available • Partition-tolerant
- 23. BASE • Basically Available • Soft state • Eventually consistent • Relaxation of the C in CAP
- 24. Eventual Consistency • All nodes eventually see the same data • Different strategies • One • Quorum • All
- 25. Horizontal Scaling • Partitioning • Sharding • Dynamo-style
- 27. Non-relational Database Families • Document-oriented • Graph • Column-oriented • Key-value & DHT • Others
- 29. Document Databases • IBM Lotus • CouchDB • MongoDB • Riak
- 31. MongoDB • JSON-style documents • Indexes on any field • Replication, auto-sharding • Map/Reduce
- 33. MongoDB Demo
- 34. Other Features • Document linking & embedding • GridFS - store large files • Geospatial indexes and searches
- 35. OM
- 36. Graph DBs http://www.flickr.com/photos/thefangmonster/2301364418/
- 37. Graph Databases • Nodes, relationships & properties • Query by traversing graph • Natural fit for recommendations, shortest paths, social graph
- 38. Graph DBs • FlockDB • Neo4j • Apache Hama • Google Pregel
- 39. Neo4j • Embedded • Server • REST • Components - indexing, management, rdf, geospatial
- 42. Key-Value & DHT
- 43. Key-Value & DHT • Amazon Dynamo • Project Voldemort • Redis • Tokyo Cabinet • Amazon SimpleDB
- 45. redis • By Salvatore Sanfillipo (@antirez) • Sponsored by VMware • data-structure server • strings, hashes, lists • sets, sorted sets • All operations in memory, backed by disk
- 46. Text Interactive Documentation
- 48. Redis Demo
- 49. Other features • Replication (master/slaves) • Persistence • Snapshotting • Append-only log file
- 50. Object Hash Mappers • cf ORM • OHM
- 51. Other KV Stores • Berkeley DB • Memcache • Microsoft Dynomite
- 52. Column-Oriented DBs http://www.flickr.com/photos/nationalmediamuseum/3588099765/
- 53. Column-Oriented Databases • Google Bigtable • Cassandra • Hypertable • HBase
- 54. HBase http://www.flickr.com/photos/negativz/14470756/
- 55. • Apache top-level project • Implementation of Google Bigtable • Distributed • High write throughput • ‘real-time’ read/write
- 56. HBase • Automatic partitioning • Scale linearly and automatically • Commodity HW • Fault tolerant • MapReduce
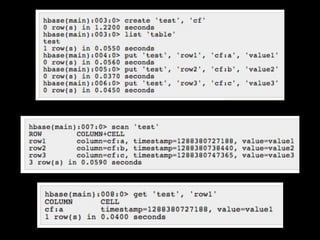
- 57. Data Model • Schema-less • Versioned cells • key/column family/cell qualifier/timestamp • Column Families
- 58. http://www.larsgeorge.com/2009/10/hbase-architecture-101-storage.html
- 61. Other DBs • Couchbase • Kyoto Cabinet • Many more I’ve omitted
- 62. Wrap Up • RDBMS vs non-relational • Distribute DBs • Non-relational families
Editor's Notes
- #2: \n
- #3: \n
- #4: \n
- #5: \n
- #6: \n
- #7: 13 rules, numbered 0 to 12\nNo popular DBMS is actually &#x2018;relational&#x2019; by 12 rules - they all break some of them\nLeading commercial - Oracle, MS, IBM (DB2)\nLeading open-source - MySQL, PostgreSQL, SQLite\n
- #8: \n
- #9: If one part of transaction fails, it all fails, DB left unchanged.\nFailures: HW, system, DB (disk etc), application (violate constraints on data)\n
- #10: The DB will enforce consistency and relationships/constraints that have been specified in the schema - everything else is the responsibility of the application\n
- #11: Dirty reads - allow other transactions to read, but not modify uncommitted data - improve performance\n
- #12: \n
- #13: DB creates new version of data for a TX\nOther TXes read the old version until TX completed.\nMVCC used by some non-relational databases\n
- #14: Usually use a transaction log that can be replayed to rebuild data in event of failure.\n
- #15: \n
- #16: \n
- #17: What most of these companies have in common is scale\nHow would an RDBMS handle the size of data they deal with?\nMost of the big companies have built their own solutions.\nMost of them also use RDBMSes - Facebook is huge MySQL user.\n
- #18: \n
- #19: Scaling - RDBMs don&#x2019;t scale linearly - big box == $$$$\ne.g. Graph relationships don&#x2019;t map to tables & rows easily\nSemi/Unstructured data, lots of columns, lots of nulls\n
- #20: Caching - e.g. memcacheDB, store common queries in memory\ndenormalise - add redundant data, grouped data to reduce table joins - reduce load on physical hardware - improve locality of reference\nSo... you choose a distributed NOSQL fancy modern DB\n
- #21: \n
- #22: Not really...\n
- #23: C - all nodes see same data at the same time\nA - survivors continue to operate when nodes fail\nP - system continues to operate despite message loss between nodes\nMany systems relax consistency\n
- #24: Also by Eric Brewer \nBASE system relaxes the C in CAP\nBA - might lose access to some data if nodes fail\nSS - System state might change over time without input (eventual consistency, propagation)\n
- #25: Different ways to consider whether a write has succeeded, whether new value is returned.\n
- #26: \n
- #27: Consistent Smashing - video from Basho/Riak\n
- #28: Lots of overlap between families - esp. column & key-value/DHT\n
- #29: \n
- #30: Schema-less way of looking at data as documents rather than fields - all related data in document. \nMaps very well to a lot of applications\n
- #31: huMONGOus\n10gen\n
- #32: Can be ACID if using replication for durability\n
- #33: \n
- #34: \n
- #35: \n
- #36: Object mapper - not ORM\n
- #37: \n
- #38: \n
- #39: FlockDB - Twitter, social graph - simpler than neo4j\nNeo4j - dual open-source/commercial license\nHama - apache project\n
- #40: ACID transactions\npersistence\nconcurrency\nscalable\n
- #41: \n
- #42: \n
- #43: \n
- #44: Tokyo Tyrant - network access protocol for Tokyo Cabinet DB\nVoldemort - LinkedIn\n
- #45: \n
- #46: Can be ACID if aof fsyncs all the time\n
- #47: \n
- #48: \n
- #49: \n
- #50: replication non-blocking on master. Writes will work even if slave blocked.\nReplication for scaling (read-only slaves) or for redundancy.\nAOF log - everything that changes the dataset.\nIf server crashes redis replays the AOF\nBGREWRITEAOF to optimize AOF - minimum steps to rebuild dataset in memory\nconfigurable fsync options - every command, every second, never\n\n
- #51: \n
- #52: Oracle Berkeley DB, Berkeley DB Java, Berkeley DB XML\nMemcache + Berkeley DB = MemcacheDB, a bit like Redis, for KV\n\n
- #53: OSDI 2006 (MapReduce was 2004)\n
- #54: Bigtable - column families, distributed, scale\n
- #55: \n
- #56: Consider a whiteboard overview of Hadoop here. \nReal-time (low-latency) as opposed to Hadoop & mapreduce batch jobs. \nNot ACID - effect of distributed writes on consistency and isolation of views\nRelaxes A of cap - consistent & partition tolerant\n
- #57: partitioned on row count/size\nRegion is basic unit of availability\n\n
- #58: \n
- #59: \n
- #60: \n
- #61: Queries - no support for complex queries\nCompute query in application (mapreduce, etc)\nall necessary data is denormalised in the row - wide table with lots of columns.\n&#x201C;versioned get&#x201D; returns older version of row\n
- #62: Couchbase - combination of CouchDB, Membase, Memcached\nKyoto Cabinet - C++ implementation by Tokyo Cabinet author.\n
- #63: Impedance Mismatch\nCAP Theorem, Eventual Consistency\nRedis, MongoDB, Neo4j, HBase\n
- #64: \n