NoSQL at Twitter (NoSQL EU 2010)
Download as KEY, PDF538 likes94,446 views

A discussion of the different NoSQL-style datastores in use at Twitter, including Hadoop (with Pig for analysis), HBase, Cassandra, and FlockDB.

























































































































































































Ad
More Related Content
What's hot (20)
Similar to NoSQL at Twitter (NoSQL EU 2010) (20)


















Ad
Recently uploaded (20)




















Ad
NoSQL at Twitter (NoSQL EU 2010)
- 1. NoSQL at Twitter Kevin Weil -- @kevinweil Analytics Lead, Twitter April 21, 2010 TM
- 2. Introduction ‣ How We Arrived at NoSQL: A Crash Course ‣ Collecting Data (Scribe) ‣ Storing and Analyzing Data (Hadoop) ‣ Rapid Learning over Big Data (Pig) ‣ And More: Cassandra, HBase, FlockDB
- 3. My Background ‣ Studied Mathematics and Physics at Harvard, Physics at Stanford ‣ Tropos Networks (city-wide wireless): mesh routing algorithms, GBs of data ‣ Cooliris (web media): Hadoop and Pig for analytics, TBs of data ‣ Twitter: Hadoop, Pig, HBase, Cassandra, machine learning, visualization, social graph analysis, soon to be PBs data
- 4. Introduction ‣ How We Arrived at NoSQL: A Crash Course ‣ Collecting Data (Scribe) ‣ Storing and Analyzing Data (Hadoop) ‣ Rapid Learning over Big Data (Pig) ‣ And More: Cassandra, HBase, FlockDB
- 5. Data, Data Everywhere ‣ Twitter users generate a lot of data ‣ Anybody want to guess?
- 6. Data, Data Everywhere ‣ Twitter users generate a lot of data ‣ Anybody want to guess? ‣ 7 TB/day (2+ PB/yr)
- 7. Data, Data Everywhere ‣ Twitter users generate a lot of data ‣ Anybody want to guess? ‣ 7 TB/day (2+ PB/yr) ‣ 10,000 CDs/day
- 8. Data, Data Everywhere ‣ Twitter users generate a lot of data ‣ Anybody want to guess? ‣ 7 TB/day (2+ PB/yr) ‣ 10,000 CDs/day ‣ 5 million floppy disks
- 9. Data, Data Everywhere ‣ Twitter users generate a lot of data ‣ Anybody want to guess? ‣ 7 TB/day (2+ PB/yr) ‣ 10,000 CDs/day ‣ 5 million floppy disks ‣ 300 GB while I give this talk
- 10. Data, Data Everywhere ‣ Twitter users generate a lot of data ‣ Anybody want to guess? ‣ 7 TB/day (2+ PB/yr) ‣ 10,000 CDs/day ‣ 5 million floppy disks ‣ 300 GB while I give this talk ‣ And doubling multiple times per year
- 11. Syslog? ‣ Started with syslog-ng ‣ As our volume grew, it didn’t scale
- 12. Syslog? ‣ Started with syslog-ng ‣ As our volume grew, it didn’t scale ‣ Resources overwhelmed ‣ Lost data
- 13. Scribe ‣ Surprise! FB had same problem, built and open-sourced Scribe ‣ Log collection framework over Thrift ‣ You write log lines, with categories ‣ It does the rest
- 14. Scribe ‣ Runs locally; reliable in network outage FE FE FE
- 15. Scribe ‣ Runs locally; reliable in network outage ‣ Nodes only know downstream FE FE FE writer; hierarchical, scalable Agg Agg
- 16. Scribe ‣ Runs locally; reliable in network outage ‣ Nodes only know downstream FE FE FE writer; hierarchical, scalable ‣ Pluggable outputs Agg Agg File HDFS
- 17. Scribe at Twitter ‣ Solved our problem, opened new vistas ‣ Currently 30 different categories logged from multiple sources ‣ FE: Javascript, Ruby on Rails ‣ Middle tier: Ruby on Rails, Scala ‣ Backend: Scala, Java, C++
- 18. Scribe at Twitter ‣ We’ve contributed to it as we’ve used it ‣ Improved logging, monitoring, writing to HDFS, compression ‣ Continuing to work with FB on patches ‣ GSoC project! Help make it more awesome. • http://github.com/traviscrawford/scribe • http://wiki.developers.facebook.com/index.php/User:GSoC
- 19. Introduction ‣ How We Arrived at NoSQL: A Crash Course ‣ Collecting Data (Scribe) ‣ Storing and Analyzing Data (Hadoop) ‣ Rapid Learning over Big Data (Pig) ‣ And More: Cassandra, HBase, FlockDB
- 20. How do you store 7TB/day? ‣ Single machine? ‣ What’s HD write speed?
- 21. How do you store 7TB/day? ‣ Single machine? ‣ What’s HD write speed? ‣ ~80 MB/s
- 22. How do you store 7TB/day? ‣ Single machine? ‣ What’s HD write speed? ‣ ~80 MB/s ‣ 24.3 hours to write 7 TB
- 23. How do you store 7TB/day? ‣ Single machine? ‣ What’s HD write speed? ‣ ~80 MB/s ‣ 24.3 hours to write 7 TB ‣ Uh oh.
- 24. Where do I put 7TB/day? ‣ Need a cluster of machines
- 25. Where do I put 7TB/day? ‣ Need a cluster of machines ‣ ... which adds new layers of complexity
- 26. Hadoop ‣ Distributed file system ‣ Automatic replication, fault tolerance
- 27. Hadoop ‣ Distributed file system ‣ Automatic replication, fault tolerance ‣ MapReduce-based parallel computation ‣ Key-value based computation interface allows for wide applicability
- 28. Hadoop ‣ Open source: top-level Apache project ‣ Scalable: Y! has a 4000 node cluster ‣ Powerful: sorted 1TB of random integers in 62 seconds ‣ Easy packaging: free Cloudera RPMs
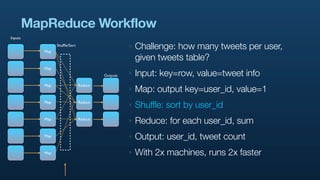
- 29. MapReduce Workflow Inputs Map Shuffle/Sort ‣ Challenge: how many tweets per user, given tweets table? Map Outputs ‣ Input: key=row, value=tweet info Map Reduce ‣ Map: output key=user_id, value=1 Map Reduce ‣ Shuffle: sort by user_id Map Reduce ‣ Reduce: for each user_id, sum Map ‣ Output: user_id, tweet count Map ‣ With 2x machines, runs 2x faster
- 30. MapReduce Workflow Inputs Map Shuffle/Sort ‣ Challenge: how many tweets per user, given tweets table? Map Outputs ‣ Input: key=row, value=tweet info Map Reduce ‣ Map: output key=user_id, value=1 Map Reduce ‣ Shuffle: sort by user_id Map Reduce ‣ Reduce: for each user_id, sum Map ‣ Output: user_id, tweet count Map ‣ With 2x machines, runs 2x faster
- 31. MapReduce Workflow Inputs Map Shuffle/Sort ‣ Challenge: how many tweets per user, given tweets table? Map Outputs ‣ Input: key=row, value=tweet info Map Reduce ‣ Map: output key=user_id, value=1 Map Reduce ‣ Shuffle: sort by user_id Map Reduce ‣ Reduce: for each user_id, sum Map ‣ Output: user_id, tweet count Map ‣ With 2x machines, runs 2x faster
- 32. MapReduce Workflow Inputs Map Shuffle/Sort ‣ Challenge: how many tweets per user, given tweets table? Map Outputs ‣ Input: key=row, value=tweet info Map Reduce ‣ Map: output key=user_id, value=1 Map Reduce ‣ Shuffle: sort by user_id Map Reduce ‣ Reduce: for each user_id, sum Map ‣ Output: user_id, tweet count Map ‣ With 2x machines, runs 2x faster
- 33. MapReduce Workflow Inputs Map Shuffle/Sort ‣ Challenge: how many tweets per user, given tweets table? Map Outputs ‣ Input: key=row, value=tweet info Map Reduce ‣ Map: output key=user_id, value=1 Map Reduce ‣ Shuffle: sort by user_id Map Reduce ‣ Reduce: for each user_id, sum Map ‣ Output: user_id, tweet count Map ‣ With 2x machines, runs 2x faster
- 34. MapReduce Workflow Inputs Map Shuffle/Sort ‣ Challenge: how many tweets per user, given tweets table? Map Outputs ‣ Input: key=row, value=tweet info Map Reduce ‣ Map: output key=user_id, value=1 Map Reduce ‣ Shuffle: sort by user_id Map Reduce ‣ Reduce: for each user_id, sum Map ‣ Output: user_id, tweet count Map ‣ With 2x machines, runs 2x faster
- 35. MapReduce Workflow Inputs Map Shuffle/Sort ‣ Challenge: how many tweets per user, given tweets table? Map Outputs ‣ Input: key=row, value=tweet info Map Reduce ‣ Map: output key=user_id, value=1 Map Reduce ‣ Shuffle: sort by user_id Map Reduce ‣ Reduce: for each user_id, sum Map ‣ Output: user_id, tweet count Map ‣ With 2x machines, runs 2x faster
- 36. Two Analysis Challenges ‣ 1. Compute friendships in Twitter’s social graph ‣ grep, awk? No way. ‣ Data is in MySQL... self join on an n-billion row table? ‣ n,000,000,000 x n,000,000,000 = ?
- 37. Two Analysis Challenges ‣ 1. Compute friendships in Twitter’s social graph ‣ grep, awk? No way. ‣ Data is in MySQL... self join on an n-billion row table? ‣ n,000,000,000 x n,000,000,000 = ? ‣ I don’t know either.
- 38. Two Analysis Challenges ‣ 2. Large-scale grouping and counting? ‣ select count(*) from users? Maybe... ‣ select count(*) from tweets? Uh... ‣ Imagine joining them... ‣ ... and grouping... ‣ ... and sorting...
- 39. Back to Hadoop ‣ Didn’t we have a cluster of machines?
- 40. Back to Hadoop ‣ Didn’t we have a cluster of machines?
- 41. Back to Hadoop ‣ Didn’t we have a cluster of machines? ‣ Hadoop makes it easy to distribute the calculation ‣ Purpose-built for parallel computation ‣ Just a slight mindset adjustment
- 42. Back to Hadoop ‣ Didn’t we have a cluster of machines? ‣ Hadoop makes it easy to distribute the calculation ‣ Purpose-built for parallel computation ‣ Just a slight mindset adjustment ‣ But a fun and valuable one!
- 43. Analysis at scale ‣ Now we’re rolling ‣ Count all tweets: 12 billion, 5 minutes ‣ Hit FlockDB in parallel to assemble social graph aggregates ‣ Run pagerank across users to calculate reputations
- 44. But... ‣ Analysis typically in Java ‣ “I need less Java in my life, not more.”
- 45. But... ‣ Analysis typically in Java ‣ “I need less Java in my life, not more.” ‣ Single-input, two-stage data flow is rigid
- 46. But... ‣ Analysis typically in Java ‣ “I need less Java in my life, not more.” ‣ Single-input, two-stage data flow is rigid ‣ Projections, filters: custom code
- 47. But... ‣ Analysis typically in Java ‣ “I need less Java in my life, not more.” ‣ Single-input, two-stage data flow is rigid ‣ Projections, filters: custom code ‣ Joins are lengthy, error-prone
- 48. But... ‣ Analysis typically in Java ‣ “I need less Java in my life, not more.” ‣ Single-input, two-stage data flow is rigid ‣ Projections, filters: custom code ‣ Joins are lengthy, error-prone ‣ n-stage jobs hard to manage
- 49. But... ‣ Analysis typically in Java ‣ “I need less Java in my life, not more.” ‣ Single-input, two-stage data flow is rigid ‣ Projections, filters: custom code ‣ Joins are lengthy, error-prone ‣ n-stage jobs hard to manage ‣ Exploration requires compilation!
- 50. Introduction ‣ How We Arrived at NoSQL: A Crash Course ‣ Collecting Data (Scribe) ‣ Storing and Analyzing Data (Hadoop) ‣ Rapid Learning over Big Data (Pig) ‣ And More: Cassandra, HBase, FlockDB
- 51. Pig ‣ High-level language ‣ Transformations on sets of records ‣ Process data one step at a time ‣ Easier than SQL?
- 52. Why Pig? ‣ Because I bet you can read the following script.
- 53. A Real Pig Script
- 54. A Real Pig Script ‣ Now, just for fun... the same calculation in vanilla Hadoop MapReduce.
- 55. No, seriously.
- 56. Pig Democratizes Large-scale Data Analysis ‣ The Pig version is: ‣ 5% of the code
- 57. Pig Democratizes Large-scale Data Analysis ‣ The Pig version is: ‣ 5% of the code ‣ 5% of the time
- 58. Pig Democratizes Large-scale Data Analysis ‣ The Pig version is: ‣ 5% of the code ‣ 5% of the time ‣ Within 25% of the execution time
- 59. One Thing I’ve Learned ‣ It’s easy to answer questions ‣ It’s hard to ask the right questions
- 60. One Thing I’ve Learned ‣ It’s easy to answer questions ‣ It’s hard to ask the right questions ‣ Value the system that promotes innovation, iteration
- 61. One Thing I’ve Learned ‣ It’s easy to answer questions ‣ It’s hard to ask the right questions ‣ Value the system that promotes innovation, iteration ‣ More minds contributing = more value from your data
- 62. The Hadoop Ecosystem at Twitter ‣ Running Cloudera’s free distro, CDH2 and Hadoop 0.20.1
- 63. The Hadoop Ecosystem at Twitter ‣ Running Cloudera’s free distro, CDH2 and Hadoop 0.20.1 ‣ Heavily modified Scribe writing LZO-compressed to HDFS ‣ LZO: fast, splittable compression, ideal for HDFS* ‣ * http://www.github.com/kevinweil/hadoop-lzo ‣
- 64. The Hadoop Ecosystem at Twitter ‣ Running Cloudera’s free distro, CDH2 and Hadoop 0.20.1 ‣ Heavily modified Scribe writing LZO-compressed to HDFS ‣ LZO: fast, splittable compression, ideal for HDFS* ‣ Data either as flat files (logs) or in protocol buffer format (newer logs, structured data, etc) ‣ Libs for reading/writing/more open-sourced as elephant-bird** ‣ * http://www.github.com/kevinweil/hadoop-lzo ‣ ** http://www.github.com/kevinweil/elephant-bird
- 65. The Hadoop Ecosystem at Twitter ‣ Running Cloudera’s free distro, CDH2 and Hadoop 0.20.1 ‣ Heavily modified Scribe writing LZO-compressed to HDFS ‣ LZO: fast, splittable compression, ideal for HDFS* ‣ Data either as flat files (logs) or in protocol buffer format (newer logs, structured data, etc) ‣ Libs for reading/writing/more open-sourced as elephant-bird** ‣ Some Java-based MapReduce, a little Hadoop streaming ‣ * http://www.github.com/kevinweil/hadoop-lzo ‣ ** http://www.github.com/kevinweil/elephant-bird
- 66. The Hadoop Ecosystem at Twitter ‣ Running Cloudera’s free distro, CDH2 and Hadoop 0.20.1 ‣ Heavily modified Scribe writing LZO-compressed to HDFS ‣ LZO: fast, splittable compression, ideal for HDFS* ‣ Data either as flat files (logs) or in protocol buffer format (newer logs, structured data, etc) ‣ Libs for reading/writing/more open-sourced as elephant-bird** ‣ Some Java-based MapReduce, some HBase, Hadoop streaming ‣ Most analysis, and most interesting analyses, done in Pig ‣ * http://www.github.com/kevinweil/hadoop-lzo ‣ ** http://www.github.com/kevinweil/elephant-bird
- 67. Data? ‣ Semi-structured: apache logs (search, .com, mobile), search query logs, RoR logs, mysql query logs, A/B testing logs, signup flow logging, and on...
- 68. Data? ‣ Semi-structured: apache logs (search, .com, mobile), search query logs, RoR logs, mysql query logs, A/B testing logs, signup flow logging, and on... ‣ Structured: tweets, users, blocks, phones, favorites, saved searches, retweets, geo, authentications, sms, 3rd party clients, followings
- 69. Data? ‣ Semi-structured: apache logs (search, .com, mobile), search query logs, RoR logs, mysql query logs, A/B testing logs, signup flow logging, and on... ‣ Structured: tweets, users, blocks, phones, favorites, saved searches, retweets, geo, authentications, sms, 3rd party clients, followings ‣ Entangled: the social graph
- 70. So what do we do with it?
- 71. Counting Big Data ‣ standard counts, min, max, std dev ‣ How many requests do we serve in a day?
- 72. Counting Big Data ‣ standard counts, min, max, std dev ‣ How many requests do we serve in a day? ‣ What is the average latency? 95% latency? ‣
- 73. Counting Big Data ‣ standard counts, min, max, std dev ‣ How many requests do we serve in a day? ‣ What is the average latency? 95% latency? ‣ Group by response code. What is the hourly distribution? ‣
- 74. Counting Big Data ‣ standard counts, min, max, std dev ‣ How many requests do we serve in a day? ‣ What is the average latency? 95% latency? ‣ Group by response code. What is the hourly distribution? ‣ How many searches happen each day on Twitter? ‣
- 75. Counting Big Data ‣ standard counts, min, max, std dev ‣ How many requests do we serve in a day? ‣ What is the average latency? 95% latency? ‣ Group by response code. What is the hourly distribution? ‣ How many searches happen each day on Twitter? ‣ How many unique queries, how many unique users? ‣
- 76. Counting Big Data ‣ standard counts, min, max, std dev ‣ How many requests do we serve in a day? ‣ What is the average latency? 95% latency? ‣ Group by response code. What is the hourly distribution? ‣ How many searches happen each day on Twitter? ‣ How many unique queries, how many unique users? ‣ What is their geographic distribution?
- 77. Counting Big Data ‣ Where are users querying from? The API, the front page, their profile page, etc? ‣
- 78. Correlating Big Data ‣ probabilities, covariance, influence ‣ How does usage differ for mobile users?
- 79. Correlating Big Data ‣ probabilities, covariance, influence ‣ How does usage differ for mobile users? ‣ How about for users with 3rd party desktop clients?
- 80. Correlating Big Data ‣ probabilities, covariance, influence ‣ How does usage differ for mobile users? ‣ How about for users with 3rd party desktop clients? ‣ Cohort analyses
- 81. Correlating Big Data ‣ probabilities, covariance, influence ‣ How does usage differ for mobile users? ‣ How about for users with 3rd party desktop clients? ‣ Cohort analyses ‣ Site problems: what goes wrong at the same time?
- 82. Correlating Big Data ‣ probabilities, covariance, influence ‣ How does usage differ for mobile users? ‣ How about for users with 3rd party desktop clients? ‣ Cohort analyses ‣ Site problems: what goes wrong at the same time? ‣ Which features get users hooked?
- 83. Correlating Big Data ‣ probabilities, covariance, influence ‣ How does usage differ for mobile users? ‣ How about for users with 3rd party desktop clients? ‣ Cohort analyses ‣ Site problems: what goes wrong at the same time? ‣ Which features get users hooked? ‣ Which features do successful users use often?
- 84. Correlating Big Data ‣ probabilities, covariance, influence ‣ How does usage differ for mobile users? ‣ How about for users with 3rd party desktop clients? ‣ Cohort analyses ‣ Site problems: what goes wrong at the same time? ‣ Which features get users hooked? ‣ Which features do successful users use often? ‣ Search corrections, search suggestions
- 85. Correlating Big Data ‣ probabilities, covariance, influence ‣ How does usage differ for mobile users? ‣ How about for users with 3rd party desktop clients? ‣ Cohort analyses ‣ Site problems: what goes wrong at the same time? ‣ Which features get users hooked? ‣ Which features do successful users use often? ‣ Search corrections, search suggestions ‣ A/B testing
- 86. Correlating Big Data ‣ What is the correlation between users with registered phones and users that tweet?
- 87. Research on Big Data ‣ prediction, graph analysis, natural language ‣ What can we tell about a user from their tweets?
- 88. Research on Big Data ‣ prediction, graph analysis, natural language ‣ What can we tell about a user from their tweets? ‣ From the tweets of those they follow?
- 89. Research on Big Data ‣ prediction, graph analysis, natural language ‣ What can we tell about a user from their tweets? ‣ From the tweets of those they follow? ‣ From the tweets of their followers?
- 90. Research on Big Data ‣ prediction, graph analysis, natural language ‣ What can we tell about a user from their tweets? ‣ From the tweets of those they follow? ‣ From the tweets of their followers? ‣ From the ratio of followers/following?
- 91. Research on Big Data ‣ prediction, graph analysis, natural language ‣ What can we tell about a user from their tweets? ‣ From the tweets of those they follow? ‣ From the tweets of their followers? ‣ From the ratio of followers/following? ‣ What graph structures lead to successful networks?
- 92. Research on Big Data ‣ prediction, graph analysis, natural language ‣ What can we tell about a user from their tweets? ‣ From the tweets of those they follow? ‣ From the tweets of their followers? ‣ From the ratio of followers/following? ‣ What graph structures lead to successful networks? ‣ User reputation
- 93. Research on Big Data ‣ prediction, graph analysis, natural language ‣ Sentiment analysis
- 94. Research on Big Data ‣ prediction, graph analysis, natural language ‣ Sentiment analysis ‣ What features get a tweet retweeted?
- 95. Research on Big Data ‣ prediction, graph analysis, natural language ‣ Sentiment analysis ‣ What features get a tweet retweeted? ‣ How deep is the corresponding retweet tree?
- 96. Research on Big Data ‣ prediction, graph analysis, natural language ‣ Sentiment analysis ‣ What features get a tweet retweeted? ‣ How deep is the corresponding retweet tree? ‣ Long-term duplicate detection
- 97. Research on Big Data ‣ prediction, graph analysis, natural language ‣ Sentiment analysis ‣ What features get a tweet retweeted? ‣ How deep is the corresponding retweet tree? ‣ Long-term duplicate detection ‣ Machine learning
- 98. Research on Big Data ‣ prediction, graph analysis, natural language ‣ Sentiment analysis ‣ What features get a tweet retweeted? ‣ How deep is the corresponding retweet tree? ‣ Long-term duplicate detection ‣ Machine learning ‣ Language detection
- 99. Research on Big Data ‣ prediction, graph analysis, natural language ‣ Sentiment analysis ‣ What features get a tweet retweeted? ‣ How deep is the corresponding retweet tree? ‣ Long-term duplicate detection ‣ Machine learning ‣ Language detection ‣ ... the list goes on.
- 100. Research on Big Data ‣ How well can we detect bots and other non-human tweeters?
- 101. Introduction ‣ How We Arrived at NoSQL: A Crash Course ‣ Collecting Data (Scribe) ‣ Storing and Analyzing Data (Hadoop) ‣ Rapid Learning over Big Data (Pig) ‣ And More: Cassandra, HBase, FlockDB
- 102. HBase ‣ BigTable clone on top of HDFS ‣ Distributed, column-oriented, no datatypes ‣ Unlike the rest of HDFS, designed for low-latency ‣ Importantly, data is mutable
- 103. HBase at Twitter ‣ We began building real products based on Hadoop ‣ People search
- 104. HBase at Twitter ‣ We began building real products based on Hadoop ‣ People search ‣ Old version: offline process on a single node
- 105. HBase at Twitter ‣ We began building real products based on Hadoop ‣ People search ‣ Old version: offline process on a single node ‣ New version: complex user calculations, hit extra services in real time, custom indexing
- 106. HBase at Twitter ‣ We began building real products based on Hadoop ‣ People search ‣ Old version: offline process on a single node ‣ New version: complex user calculations, hit extra services in real time, custom indexing ‣ Underlying data is mutable ‣ Mutable layer on top of HDFS --> HBase
- 107. People Search ‣ Import user data into HBase
- 108. People Search ‣ Import user data into HBase ‣ Periodic MapReduce job reading from HBase ‣ Hits FlockDB, multiple other internal services in mapper ‣ Custom partitioning
- 109. People Search ‣ Import user data into HBase ‣ Periodic MapReduce job reading from HBase ‣ Hits FlockDB, multiple other internal services in mapper ‣ Custom partitioning ‣ Data sucked across to sharded, replicated, horizontally scalable, in-memory, low-latency Scala service ‣ Build a trie, do case folding/normalization, suggestions, etc
- 110. People Search ‣ Import user data into HBase ‣ Periodic MapReduce job reading from HBase ‣ Hits FlockDB, multiple other internal services in mapper ‣ Custom partitioning ‣ Data sucked across to sharded, replicated, horizontally scalable, in-memory, low-latency Scala service ‣ Build a trie, do case folding/normalization, suggestions, etc ‣ See http://www.slideshare.net/al3x/building-distributed-systems- in-scala for more
- 111. HBase ‣ More products now being built on top of it ‣ Flexible, easy to connect to MapReduce/Pig
- 112. HBase vs Cassandra ‣ “Their origins reveal their strengths and weaknesses”
- 113. HBase vs Cassandra ‣ “Their origins reveal their strengths and weaknesses” ‣ HBase built on top of batch-oriented system, not low latency
- 114. HBase vs Cassandra ‣ “Their origins reveal their strengths and weaknesses” ‣ HBase built on top of batch-oriented system, not low latency ‣ Cassandra built from ground up for low latency
- 115. HBase vs Cassandra ‣ “Their origins reveal their strengths and weaknesses” ‣ HBase built on top of batch-oriented system, not low latency ‣ Cassandra built from ground up for low latency ‣ HBase easy to connect to batch jobs as input and output
- 116. HBase vs Cassandra ‣ “Their origins reveal their strengths and weaknesses” ‣ HBase built on top of batch-oriented system, not low latency ‣ Cassandra built from ground up for low latency ‣ HBase easy to connect to batch jobs as input and output ‣ Cassandra not so much (but we’re working on it)
- 117. HBase vs Cassandra ‣ “Their origins reveal their strengths and weaknesses” ‣ HBase built on top of batch-oriented system, not low latency ‣ Cassandra built from ground up for low latency ‣ HBase easy to connect to batch jobs as input and output ‣ Cassandra not so much (but we’re working on it) ‣ HBase has SPOF in the namenode
- 118. HBase vs Cassandra ‣ Your mileage may vary ‣ At Twitter: HBase for analytics, analysis, dataset generation ‣ Cassandra for online systems
- 119. HBase vs Cassandra ‣ Your mileage may vary ‣ At Twitter: HBase for analytics, analysis, dataset generation ‣ Cassandra for online systems ‣ As with all NoSQL systems: strengths in different situations
- 120. FlockDB ‣ Realtime, distributed social graph store ‣ NOT optimized for data mining ‣ Note: the following slides largely come from @nk’s more complete talk at http://www.slideshare.net/nkallen/ q-con-3770885
- 121. FlockDB ‣ Realtime, distributed Intersection Temporal social graph store ‣ NOT optimized for data mining ‣ Who follows who (nearly 8 Counts orders of magnitude!) ‣ Intersection/set operations ‣ Cardinality ‣ Temporal index
- 122. Set operations? ‣ This tweet needs to be delivered to people who follow both @aplusk (4.7M followers) and @foursquare (53K followers)
- 123. Original solution ‣ MySQL table source_id destination-id ‣ Indices on source_id 20 12 and destination_id 29 12 ‣ Couldn’t handle write 34 16 throughput ‣ Indices too large for RAM
- 124. Next Try ‣ MySQL still ‣ Denormalized ‣ Byte-packed ‣ Chunked ‣ Still temporally ordered
- 125. Next Try ‣ Problems ‣ O(n) deletes ‣ Data consistency challenges ‣ Inefficient intersections ‣ All of these manifested strongly for huge users like @aplusk or @lancearmstrong
- 126. FlockDB ‣ MySQL underneath still (like PNUTS from Y!) ‣ Partitioned by user_id, gizzard handles sharding/partitioning ‣ Edges stored in both directions, indexed by (src, dest) ‣ Denormalized counts stored Forward Backward source_id destination_id updated_at x destination_id source_id updated_at x 20 12 20:50:14 x 12 20 20:50:14 x 20 13 20:51:32 12 32 20:51:32 20 16 12 16
- 127. FlockDB Timings ‣ Counts: 1ms
- 128. FlockDB Timings ‣ Counts: 1ms ‣ Temporal Query: 2ms
- 129. FlockDB Timings ‣ Counts: 1ms ‣ Temporal Query: 2ms ‣ Writes: 1ms for journal, 16ms for durability
- 130. FlockDB Timings ‣ Counts: 1ms ‣ Temporal Query: 2ms ‣ Writes: 1ms for journal, 16ms for durability ‣ Full walks: 100 edges/ms
- 131. FlockDB is Open Source ‣ We will maintain a community at ‣ http://www.github.com/twitter/flockdb ‣ http://www.github.com/twitter/gizzard ‣ See Nick Kallen’s QCon talk for more ‣ http://www.slideshare.net/nkallen/q- con-3770885
- 132. Cassandra ‣ Why Cassandra, for Twitter?
- 133. Cassandra ‣ Why Cassandra, for Twitter? ‣ Old/current: vertically, horizontally partitioned MySQL
- 134. Cassandra ‣ Why Cassandra, for Twitter? ‣ Old/current: vertically, horizontally partitioned MySQL ‣ All kinds of caching layers, all application managed
- 135. Cassandra ‣ Why Cassandra, for Twitter? ‣ Old/current: vertically, horizontally partitioned MySQL ‣ All kinds of caching layers, all application managed ‣ Alter table impossible, leads to bitfields, piggyback tables
- 136. Cassandra ‣ Why Cassandra, for Twitter? ‣ Old/current: vertically, horizontally partitioned MySQL ‣ All kinds of caching layers, all application managed ‣ Alter table impossible, leads to bitfields, piggyback tables ‣ Hardware intensive, error prone, etc
- 137. Cassandra ‣ Why Cassandra, for Twitter? ‣ Old/current: vertically, horizontally partitioned MySQL ‣ All kinds of caching layers, all application managed ‣ Alter table impossible, leads to bitfields, piggyback tables ‣ Hardware intensive, error prone, etc ‣ Not to mention, we hit MySQL write limits sometimes
- 138. Cassandra ‣ Why Cassandra, for Twitter? ‣ Old/current: vertically, horizontally partitioned MySQL ‣ All kinds of caching layers, all application managed ‣ Alter table impossible, leads to bitfields, piggyback tables ‣ Hardware intensive, error prone, etc ‣ Not to mention, we hit MySQL write limits sometimes ‣ First goal: move all tweets to Cassandra
- 139. Cassandra ‣ Why Cassandra, for Twitter? ‣ Decentralized, fault-tolerant ‣ All kinds of caching layers, all application managed ‣ Alter table impossible, leads to bitfields, piggyback tables ‣ Hardware intensive, error prone, etc ‣ Not to mention, we hit MySQL write limits sometimes ‣ First goal: move all tweets to Cassandra
- 140. Cassandra ‣ Why Cassandra, for Twitter? ‣ Decentralized, fault-tolerant ‣ All kinds of caching layers, all application managed ‣ Alter table impossible, leads to bitfields, piggyback tables ‣ Hardware intensive, error prone, etc ‣ Not to mention, we hit MySQL write limits sometimes ‣ First goal: move all tweets to Cassandra
- 141. Cassandra ‣ Why Cassandra, for Twitter? ‣ Decentralized, fault-tolerant ‣ All kinds of caching layers, all application managed ‣ Flexible schema ‣ Hardware intensive, error prone, etc ‣ Not to mention, we hit MySQL write limits sometimes ‣ First goal: move all tweets to Cassandra
- 142. Cassandra ‣ Why Cassandra, for Twitter? ‣ Decentralized, fault-tolerant ‣ All kinds of caching layers, all application managed ‣ Flexible schema ‣ Elastic ‣ Not to mention, we hit MySQL write limits sometimes ‣ First goal: move all tweets to Cassandra
- 143. Cassandra ‣ Why Cassandra, for Twitter? ‣ Decentralized, fault-tolerant ‣ All kinds of caching layers, all application managed ‣ Flexible schema ‣ Elastic ‣ High write throughput ‣ First goal: move all tweets to Cassandra
- 144. Eventually Consistent? ‣ Twitter is already eventually consistent
- 145. Eventually Consistent? ‣ Twitter is already eventually consistent ‣ Your system may be even worse
- 146. Eventually Consistent? ‣ Twitter is already eventually consistent ‣ Your system may be even worse ‣ Ryan’s new term: “potential consistency” ‣ Do you have write-through caching? ‣ Do you ever have MySQL replication failures?
- 147. Eventually Consistent? ‣ Twitter is already eventually consistent ‣ Your system may be even worse ‣ Ryan’s new term: “potential consistency” ‣ Do you have write-through caching? ‣ Do you ever have MySQL replication failures? ‣ There is no automatic consistency repair there, unlike Cassandra
- 148. Eventually Consistent? ‣ Twitter is already eventually consistent ‣ Your system may be even worse ‣ Ryan’s new term: “potential consistency” ‣ Do you have write-through caching? ‣ Do you ever have MySQL replication failures? ‣ There is no automatic consistency repair there, unlike Cassandra ‣ http://www.slideshare.net/ryansking/scaling- twitter-with-cassandra
- 149. Rolling out Cassandra ‣ 1. Integrate Cassandra alongside MySQL ‣ 100% reads/writes to MySQL ‣ Dynamic switches for % dark reads/writes to Cassandra
- 150. Rolling out Cassandra ‣ 1. Integrate Cassandra alongside MySQL ‣ 100% reads/writes to MySQL ‣ Dynamic switches for % dark reads/writes to Cassandra ‣ 2. Turn up traffic to Cassandra
- 151. Rolling out Cassandra ‣ 1. Integrate Cassandra alongside MySQL ‣ 100% reads/writes to MySQL ‣ Dynamic switches for % dark reads/writes to Cassandra ‣ 2. Turn up traffic to Cassandra ‣ 3. Find something that’s broken, set switch to 0%
- 152. Rolling out Cassandra ‣ 1. Integrate Cassandra alongside MySQL ‣ 100% reads/writes to MySQL ‣ Dynamic switches for % dark reads/writes to Cassandra ‣ 2. Turn up traffic to Cassandra ‣ 3. Find something that’s broken, set switch to 0% ‣ 4. Fix it
- 153. Rolling out Cassandra ‣ 1. Integrate Cassandra alongside MySQL ‣ 100% reads/writes to MySQL ‣ Dynamic switches for % dark reads/writes to Cassandra ‣ 2. Turn up traffic to Cassandra ‣ 3. Find something that’s broken, set switch to 0% ‣ 4. Fix it ‣ 5. GOTO 2
- 154. Cassandra for Realtime Analytics ‣ Starting a project around realtime analytics ‣ Cassandra as the backing store ‣ Using, developing, testing Digg’s atomic incr patches ‣ More soon.
- 155. That was a lot of slides ‣ Thanks for sticking with me.
- 156. Questions? Follow me at twitter.com/kevinweil TM