NoSQL Riak MongoDB Elasticsearch - All The Same?
4 likes3,458 views

Gives a general introduction to NoSQL and modeling data with JSON. Goes on to compare MongoDB, Riak and Elasticsearch - that seem to be the same at first sight but are in fact pretty different. Presented at JavaLand.







































































































Ad
More Related Content
What's hot (20)
Viewers also liked (10)








Ad
Similar to NoSQL Riak MongoDB Elasticsearch - All The Same? (20)




















Ad
More from Eberhard Wolff (20)




















Recently uploaded (20)




















NoSQL Riak MongoDB Elasticsearch - All The Same?
- 1. MongoDB, Elasticsearch, Riak – all the same? Eberhard Wolff Freelancer Head Technology Advisory Board adesso AG http://ewolff.com
- 2. Eberhard Wolff - @ewolff Leseprobe: http://bit.ly/CD-Buch
- 3. Eberhard Wolff - @ewolff Modeling: Relational Databases vs. JSON
- 4. Eberhard Wolff - @ewolff Financial System • Different financial products • Mapping objects / database • Inheritance
- 5. Eberhard Wolff - @ewolff E/R Model Asset Stock Zero Bond Option Country> 20 database tables Up to 25 attributes Currency
- 6. Eberhard Wolff - @ewolff JOINs L
- 7. Get all asset with interest rate x
- 8. Eberhard Wolff - @ewolff
- 9. Eberhard Wolff - @ewolff JSON
- 10. Eberhard Wolff - @ewolff Asset Type ID Zero Bond Interest Rate Fixed Rate Bond Interest Rate Stock Option … Preferred Underlying asset Country Price Country Currency
- 11. Eberhard Wolff - @ewolff { "ID" : "42", "type" : "Fixed Rate Bond", "Country" : "DE", "Currency" : "EUR", "ISIN" : "DE0001141562", "Interest Rate" : "2.5" }
- 12. Eberhard Wolff - @ewolff All stores in this presentation support JSON
- 13. Eberhard Wolff - @ewolff Scaling Relational Databases
- 14. Eberhard Wolff - @ewolff Larger Server DB Server DB Server Expensive Server Limited
- 15. Eberhard Wolff - @ewolff Common Storage DB Server Expensive Storage Limited DB Server DB Server DB Server e.g. Oracle RAC
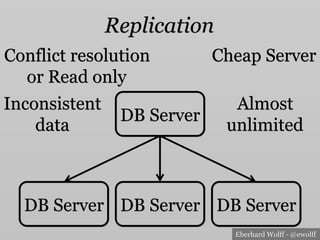
- 16. Eberhard Wolff - @ewolff Replication Cheap Server Almost unlimited DB Server DB Server DB Server DB Server Inconsistent data Conflict resolution or Read only
- 17. Eberhard Wolff - @ewolff Replication DB Server DB Server DB Server DB Server MySQL Master-Slave Oracle Advanced Replication
- 18. Eberhard Wolff - @ewolff Network Failure • Either Answer & provide outdated data • or Don’t answer i.e. always provide up to date data
- 19. Eberhard Wolff - @ewolff CAP • Consistency • Availability • Network Partition Tolerance • If network fails provide a potentially incorrect answer or no at all?
- 20. Eberhard Wolff - @ewolff BASE • Basically Available • Soft State • Eventually (= in the end) consistent • i.e. give potentially incorrect answer
- 21. Eberhard Wolff - @ewolff BASE and Relational DBs • Very limited • Stand by • Read only replica • No truly distributed DB
- 22. Eberhard Wolff - @ewolff Relational & BASE • Most relational operations cover multiple tables • Needs locks across multiple servers • Not realistically possible
- 23. Eberhard Wolff - @ewolff NoSQL & BASE • Typical operation covers one data structure • …that contains more information • No complex locking • More sophisticated BASE
- 24. Eberhard Wolff - @ewolff Naïve View on NoSQL
- 25. Eberhard Wolff - @ewolff Key / Value Stores • Map Key to Value • For simple data structure • Retrieval only by key • Easy scalability • Only for simple applications Key Value 42 Some data
- 26. Eberhard Wolff - @ewolff Document Oriented • Documents e.g. JSON • Complex structures & queries • Still great scalability • For more complex applications { "author":{ "name":"Eberhard Wolff", "email":"[email protected]" }, "title": "Continuous Delivery”, }
- 27. Eberhard Wolff - @ewolff Graph, Column Oriented…
- 28. Eberhard Wolff - @ewolff Educated View on NoSQL
- 29. Eberhard Wolff - @ewolff Key / value Document-based Search engine All the same?
- 30. Eberhard Wolff - @ewolff MongoDB elasticsearch Riak
- 31. Eberhard Wolff - @ewolff MongoDB elasticsearch Riak
- 32. Eberhard Wolff - @ewolff • Key / value • Truly distributed database What is Riak?
- 33. Eberhard Wolff - @ewolff Riak: Technologies • Erlang • Open Source (Apache 2.0) • Company: Basho
- 34. Eberhard Wolff - @ewolff • Allows secondary indices • Riak Search 2.0: Solr integration • Solr: Lucene based search engine • API compatible to Solr • Key / value or document based? More indices
- 35. Eberhard Wolff - @ewolff • Map/reduce • Scans all datasets • Can store large binary objects More Features
- 36. Eberhard Wolff - @ewolff Scaling Riak • Based on the Dynamo paper • Well understood • …and battle proofed at Amazon
- 37. Eberhard Wolff - @ewolff Scaling Riak Server A Shard1 Shard3 Shard4 Server B Shard2 Shard1 Shard4 Server D Shard4 Shard2 Shard3 Server C Shard3 Shard2 Shard1
- 38. Eberhard Wolff - @ewolff Scaling Riak Server A Shard1 Shard3 Shard4 Server B Shard2 Shard1 Shard4 Server D Shard4 Shard2 Shard3 Server C Shard3 Shard2 Shard1
- 39. Eberhard Wolff - @ewolff Scaling Riak Server A Shard1 Shard3 Shard4 Server B Shard2 Shard1 Shard4 Server D Shard4 Shard2 Shard3 Server C Shard3 Shard2 Shard1 New Server
- 40. Eberhard Wolff - @ewolff Tuning BASE • N node with replica • R nodes read from • W nodes written to • Trade off
- 41. Eberhard Wolff - @ewolff Is it bullet proof?
- 42. Eberhard Wolff - @ewolff Jepsen • Test suite for network failures etc • https://aphyr.com/tags/jepsen • Riak succeeds • …if tuned correctly • …might still need to merge versions • https://aphyr.com/posts/285-call-me- maybe-riak
- 43. Eberhard Wolff - @ewolff MongoDB elasticsearch Riak
- 44. Eberhard Wolff - @ewolff MongoDB elasticsearch Riak
- 45. Eberhard Wolff - @ewolff MongoDB elasticsearch Riak
- 46. Eberhard Wolff - @ewolff • Document-oriented • MMAPv1 Memory-mapped files + journal • New in 3.0: WiredTiger for complex loads Humongous What is MongoDB?
- 47. Eberhard Wolff - @ewolff MongoDB: Technologies • C++ • Open Source (AGPL) • Company: MongoDB, Inc.
- 48. Eberhard Wolff - @ewolff • Can store large binary objects • Its own full text search More Features
- 49. Eberhard Wolff - @ewolff More Features • Map / Reduce • JavaScript • Aggregation framework
- 50. Eberhard Wolff - @ewolff Scaling MongoDB Replica 1 Shard 1 Replica 2 Replica 3 Shard 2 Replica 1 Replica 2 Replica 3
- 51. Eberhard Wolff - @ewolff Availability Replica 1 Shard 1 Replica 2 Replica 3 Shard 2 Replica 1 Replica 2 Replica 3
- 52. Eberhard Wolff - @ewolff Scaling MongoDB Replica 1 Shard 1 Replica 2 Replica 3 Replica 1 Shard 2 Replica 2 Replica 3 Replica 1 Shard 3 Replica 2 Replica 3
- 53. Eberhard Wolff - @ewolff Scaling MongoDB Replica 1 Shard 1 Replica 2 Replica 3 Shard 2 Replica 1 Replica 2 Replica 3 ?
- 54. Eberhard Wolff - @ewolff Tuning BASE • Write concerns • How many nodes should acknowledge the write? • Read from primary • …or also secondaries
- 55. Eberhard Wolff - @ewolff Jepsen • Mongo loses writes • A bug – might still be there • Also: non-acknowledge writes might still survive • …and overwrite other data • https://aphyr.com/posts/284-call-me- maybe-mongodb
- 56. Eberhard Wolff - @ewolff MongoDB elasticsearch Riak
- 57. Eberhard Wolff - @ewolff MongoDB elasticsearch Riak
- 58. Eberhard Wolff - @ewolff MongoDB elasticsearch Riak
- 59. Eberhard Wolff - @ewolff Database =Storage + Search
- 60. Eberhard Wolff - @ewolff elasticsearch =Storage + Search
- 61. Eberhard Wolff - @ewolff What is elasticsearch? • Search Engine • Also stores original documents • Based on Lucene Search Libray • Easy scaling
- 62. Eberhard Wolff - @ewolff elasticsearch: Technologies • Java • REST • Open Source (Apache) • Backed by company elasticsearch
- 63. Eberhard Wolff - @ewolff elasticsearch Internals • Append only file • Many benefits • But not too great for updates
- 64. Eberhard Wolff - @ewolff Scaling elasticsearch Server Server Server Shard 1 Replica 1 Replica 2 Shard 2 Replica 3Shard 3
- 65. Eberhard Wolff - @ewolff Tuning BASE • Write acknowledge: 1, majority, all • Including indexing • Read from primary • …or also secondaries
- 66. Eberhard Wolff - @ewolff Jepsen • Loses data even if just one node is partioned (June 2014) • Actively worked on • It’s a search engine… • https://aphyr.com/posts/317-call-me- maybe-elasticsearch • http://www.elasticsearch.org/guide/ en/elasticsearch/resiliency/current/
- 67. Eberhard Wolff - @ewolff Scenarios elasticsearch
- 68. Eberhard Wolff - @ewolff Search • Powerful query language • Configurable index • Text analysis • Stop words • Stemming
- 69. Eberhard Wolff - @ewolff Facets • Number of hits by category • Useful for statistics • & Big Data • Statistical facet (+ computation) • Range facets etc.
- 70. Eberhard Wolff - @ewolff MongoDB elasticsearch Riak
- 71. Eberhard Wolff - @ewolff MongoDB elasticsearch Riak
- 72. Eberhard Wolff - @ewolff Conclusion • Relational databases might be BASE • NoSQL embraces BASE better • Key / Value, Document stores and search engine: very similar features • Care about scaling • Care about resilience
- 73. Eberhard Wolff - @ewolff
- 74. Eberhard Wolff - @ewolff Thank You!