ODI12c as your Big Data Integration Hub
3 likes3,089 views

Presentation from the recent Oracle OTN Virtual Technology Summit, on using Oracle Data Integrator 12c to ingest, transform and process data on a Hadoop cluster.









![HDFS: Low-Cost, Clustered, Fault-Tolerant Storage
•The filesystem behind Hadoop, used to store data for Hadoop analysis
‣Unix-like, uses commands such as ls, mkdir, chown, chmod
•Fault-tolerant, with rapid fault detection and recovery
•High-throughput, with streaming data access and large block sizes
•Designed for data-locality, placing data closed to where it is processed
•Accessed from the command-line, via internet (hdfs://), GUI tools etc
[oracle@bigdatalite mapreduce]$ hadoop fs -mkdir /user/oracle/my_stuff
[oracle@bigdatalite mapreduce]$ hadoop fs -ls /user/oracle
Found 5 items
drwx------ - oracle hadoop 0 2013-04-27 16:48 /user/oracle/.staging
drwxrwxrwx - oracle hadoop 0 2012-09-18 17:02 /user/oracle/moviedemo
drwxrwxrwx - oracle hadoop 0 2012-10-17 15:58 /user/oracle/moviework
drwxrwxrwx - oracle hadoop 0 2013-05-03 17:49 /user/oracle/my_stuff
drwxrwxrwx - oracle hadoop 0 2012-08-10 16:08 /user/oracle/stage
T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or
+61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : info@rittmanmead.com
W : www.rittmanmead.com](https://image.slidesharecdn.com/odi12cbigdatarittman-140825161440-phpapp02/85/ODI12c-as-your-Big-Data-Integration-Hub-10-320.jpg)





![An example Hive Query Session: Connect and Display Table List
[oracle@bigdatalite ~]$ hive
Hive history file=/tmp/oracle/hive_job_log_oracle_201304170403_1991392312.txt
hive> show tables;
OK
dwh_customer
dwh_customer_tmp
i_dwh_customer
ratings
src_customer
src_sales_person
weblog
weblog_preprocessed
weblog_sessionized
Time taken: 2.925 seconds
T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or
+61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : info@rittmanmead.com
W : www.rittmanmead.com
Hive Server lists out all
“tables” that have been
defined within the Hive
environment](https://image.slidesharecdn.com/odi12cbigdatarittman-140825161440-phpapp02/85/ODI12c-as-your-Big-Data-Integration-Hub-16-320.jpg)




























![Distributing SerDe JAR Files for Hive across Cluster
•Hive SerDe functionality typically requires additional JARs to be made available to Hive
•Following steps must be performed across ALL BDA nodes:
‣Add JAR reference to HIVE_AUX_JARS_PATH in /usr/lib/hive/conf/hive.env.sh
!
!
!
‣Add JAR file to /usr/lib/hadoop
!
!
!
‣Restart YARN / MR1 TaskTrackers across cluster
export HIVE_AUX_JARS_PATH=/usr/lib/hive/lib/hive-contrib-0.12.0-cdh5.0.1.jar:$
(echo $HIVE_AUX_JARS_PATH…
[root@bdanode1 hadoop]# ls /usr/lib/hadoop/hive-*
/usr/lib/hadoop/hive-contrib-0.12.0-cdh5.0.1.jar
T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or
+61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : info@rittmanmead.com
W : www.rittmanmead.com](https://image.slidesharecdn.com/odi12cbigdatarittman-140825161440-phpapp02/85/ODI12c-as-your-Big-Data-Integration-Hub-46-320.jpg)
































































Ad
More Related Content
What's hot (20)
Similar to ODI12c as your Big Data Integration Hub (20)


















Ad
More from Mark Rittman (14)














Ad
Recently uploaded (20)












![PRE-NATAL GRnnnmnnnnmmOWTH seminar[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/pre-natalgrowthseminar1-250427093235-de04befc-thumbnail.jpg?width=560&fit=bounds)







ODI12c as your Big Data Integration Hub
- 1. Oracle Data Integrator 12c As Your Big Data Data Integration Hub Mark Rittman Chief Technical Officer Rittman Mead Month 00, 2014 Copyright © 2014 Oracle and/or its affiliates. All rights reserved. | Oracle Confidential – Internal/Restricted/Highly Restricted
- 2. ODI12c as your Big Data Integration Hub Mark Rittman, CTO, Rittman Mead July 2014 T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com
- 3. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com About the Speaker •Mark Rittman, Co-Founder of Rittman Mead •Oracle ACE Director, specialising in Oracle BI&DW •14 Years Experience with Oracle Technology •Regular columnist for Oracle Magazine •Author of two Oracle Press Oracle BI books •Oracle Business Intelligence Developers Guide •Oracle Exalytics Revealed •Writer for Rittman Mead Blog : http://www.rittmanmead.com/blog •Email : [email protected] •Twitter : @markrittman
- 4. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com About Rittman Mead •Oracle BI and DW Gold partner •Winner of five UKOUG Partner of the Year awards in 2013 - including BI •World leading specialist partner for technical excellence, solutions delivery and innovation in Oracle BI •Approximately 80 consultants worldwide •All expert in Oracle BI and DW •Offices in US (Atlanta), Europe, Australia and India •Skills in broad range of supporting Oracle tools: ‣OBIEE, OBIA ‣ODIEE ‣Essbase, Oracle OLAP ‣GoldenGate ‣Endeca
- 5. Traditional Data Warehouse / BI Architectures •Three-layer architecture - staging, foundation and access/performance •All three layers stored in a relational database (Oracle) •ETL used to move data from layer-to-layer T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) Staging Foundation / ODS E : [email protected] W : www.rittmanmead.com Performance / Dimensional ETL ETL BI Tool (OBIEE) with metadata layer OLAP / In-Memory Tool with data load into own database Direct Read Data Load Traditional structured data sources Data Load Data Load Data Load Traditional Relational Data Warehouse
- 6. Recent Innovations and Developments in DW Architecture •The rise of “big data” and “hadoop” ‣New ways to process, store and analyse data ‣New paradigm for TCO - low-cost servers, open-source software, cheap clustering •Explosion in potential data-source types ‣Unstructured data ‣Social media feeds ‣Schema-less and schema-on-read databases •New ways of hosting data warehouses ‣In the cloud ‣Do we even need an Oracle database or DW? •Lots of opportunities for DW/BI developers - make our systems cheaper, wider range of data T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com
- 7. Introduction of New Data Sources : Unstructured, Big Data Staging Foundation / ETL ETL T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) ODS Performance / Dimensional E : [email protected] W : www.rittmanmead.com BI Tool (OBIEE) with metadata layer OLAP / In-Memory Tool with data load into own database Direct Read Data Load Traditional structured data sources Data Load Data Load Data Load Traditional Relational Data Warehouse Schema-less / NoSQL data sources Unstructured/ Social / Doc data sources Hadoop / Big Data data sources Data Load
- 8. Unstructured, Semi-Structured and Schema-Less Data •Gaining access to the vast amounts of non-financial / application data out there ‣Data in documents, spreadsheets etc -Warranty claims, supporting documents, notes etc ‣Data coming from the cloud / social media ‣Data for which we don’t yet have a structure ‣Data who’s structure we’ll decide when we choose to access it (“schema-on-read”) •All of the above could be useful information to have in our DW and BI systems ‣But how do we load it in? ‣And what if we want to access it directly? T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Schema-less / NoSQL data sources Unstructured/ Social / Doc data sources Hadoop / Big Data data sources
- 9. Hadoop, and the Big Data Ecosystem •Apache Hadoop is one of the most well-known Big Data technologies ‣Family of open-source products used to store, and analyze distributed datasets ‣Hadoop is the enabling framework, automatically parallelises and co-ordinates jobs ‣MapReduce is the programming framework for filtering, sorting and aggregating data ‣Map : filter data and pass on to reducers ‣Reduce : sort, group and return results ‣MapReduce jobs can be written in any language (Java etc), but it is complicated •Can be used as an extension of the DW staging layer - cheap processing & storage •And there may be data stored in Hadoop that our BI users might benefit from T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com
- 10. HDFS: Low-Cost, Clustered, Fault-Tolerant Storage •The filesystem behind Hadoop, used to store data for Hadoop analysis ‣Unix-like, uses commands such as ls, mkdir, chown, chmod •Fault-tolerant, with rapid fault detection and recovery •High-throughput, with streaming data access and large block sizes •Designed for data-locality, placing data closed to where it is processed •Accessed from the command-line, via internet (hdfs://), GUI tools etc [oracle@bigdatalite mapreduce]$ hadoop fs -mkdir /user/oracle/my_stuff [oracle@bigdatalite mapreduce]$ hadoop fs -ls /user/oracle Found 5 items drwx------ - oracle hadoop 0 2013-04-27 16:48 /user/oracle/.staging drwxrwxrwx - oracle hadoop 0 2012-09-18 17:02 /user/oracle/moviedemo drwxrwxrwx - oracle hadoop 0 2012-10-17 15:58 /user/oracle/moviework drwxrwxrwx - oracle hadoop 0 2013-05-03 17:49 /user/oracle/my_stuff drwxrwxrwx - oracle hadoop 0 2012-08-10 16:08 /user/oracle/stage T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com
- 11. Hadoop & HDFS as a Low-Cost Pre-Staging Layer T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) Staging Foundation / ODS E : [email protected] W : www.rittmanmead.com Performance / Dimensional ETL ETL BI Tool (OBIEE) with metadata layer OLAP / In-Memory Tool with data load into own database Direct Read Data Load Traditional structured data sources Data Load Data Load Data Load Traditional Relational Data Warehouse Schema-less / NoSQL data sources Unstructured/ Social / Doc data sources Hadoop / Big Data data sources Data Load Pre-ETL Filtering & Aggregation (MapReduce) Low-cost file store (HDFS) Data Load Hadoop
- 12. Big Data and the Hadoop “Data Warehouse” T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com BI Tool (OBIEE) with metadata layer Direct Read Data Load Data Load Data Load Schema-less / NoSQL data sources Unstructured/ Social / Doc data sources Hadoop / Big Data data sources Data Load Hadoop Pre-ETL Filtering & Aggregation (MapReduce) Low-cost file store (HDFS) Hadoop DW Layer (Hive) Cloud-Based data sources •Rather than load Hadoop data into the DW, access it directly •Hadoop has a “DW layer” called Hive, which provides SQL access •Could even be used instead of a traditional DW or data mart •Limited functionality now •But products maturing •and unbeatable TCO
- 13. Hive as the Hadoop “Data Warehouse” •MapReduce jobs are typically written in Java, but Hive can make this simpler •Hive is a query environment over Hadoop/MapReduce to support SQL-like queries •Hive server accepts HiveQL queries via HiveODBC or HiveJDBC, automatically creates MapReduce jobs against data previously loaded into the Hive HDFS tables •Approach used by ODI and OBIEE to gain access to Hadoop data •Allows Hadoop data to be accessed just like any other data source (sort of...) T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com
- 14. How Hive Provides SQL Access over Hadoop •Hive uses a RBDMS metastore to hold table and column definitions in schemas •Hive tables then map onto HDFS-stored files ‣Managed tables ‣External tables •Oracle-like query optimizer, compiler, executor •JDBC and OBDC drivers, plus CLI etc T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Hive Driver (Compile Optimize, Execute) Managed Tables /user/hive/warehouse/ External Tables /user/oracle/ /user/movies/data/ HDFS HDFS or local files loaded into Hive HDFS area, using HiveQL CREATE TABLE command HDFS files loaded into HDFS using external process, then mapped into Hive using CREATE EXTERNAL TABLE command Metastore
- 15. Transforming HiveQL Queries into MapReduce Jobs •HiveQL queries are automatically translated into Java MapReduce jobs •Selection and filtering part becomes Map tasks •Aggregation part becomes the Reduce tasks T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) SELECT a, sum(b) FROM myTable WHERE a<100 GROUP BY a E : [email protected] W : www.rittmanmead.com Map Task Map Task Map Task Reduce Task Reduce Task Result
- 16. An example Hive Query Session: Connect and Display Table List [oracle@bigdatalite ~]$ hive Hive history file=/tmp/oracle/hive_job_log_oracle_201304170403_1991392312.txt hive> show tables; OK dwh_customer dwh_customer_tmp i_dwh_customer ratings src_customer src_sales_person weblog weblog_preprocessed weblog_sessionized Time taken: 2.925 seconds T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Hive Server lists out all “tables” that have been defined within the Hive environment
- 17. An example Hive Query Session: Display Table Row Count T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com hive> select count(*) from src_customer;! Total MapReduce jobs = 1 Launching Job 1 out of 1 Number of reduce tasks determined at compile time: 1 In order to change the average load for a reducer (in bytes): set hive.exec.reducers.bytes.per.reducer= In order to limit the maximum number of reducers: set hive.exec.reducers.max= In order to set a constant number of reducers: set mapred.reduce.tasks= Starting Job = job_201303171815_0003, Tracking URL = http://localhost.localdomain:50030/jobdetails.jsp?jobid=job_201303171815_0003 Kill Command = /usr/lib/hadoop-0.20/bin/ hadoop job -Dmapred.job.tracker=localhost.localdomain:8021 -kill job_201303171815_0003 2013-04-17 04:06:59,867 Stage-1 map = 0%, reduce = 0% 2013-04-17 04:07:03,926 Stage-1 map = 100%, reduce = 0% 2013-04-17 04:07:14,040 Stage-1 map = 100%, reduce = 33% 2013-04-17 04:07:15,049 Stage-1 map = 100%, reduce = 100% Ended Job = job_201303171815_0003 OK ! 25 Time taken: 22.21 seconds Request count(*) from table Hive server generates MapReduce job to “map” table key/value pairs, and then reduce the results to table count MapReduce job automatically run by Hive Server Results returned to user
- 18. Demonstration of Hive and HiveQL T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com
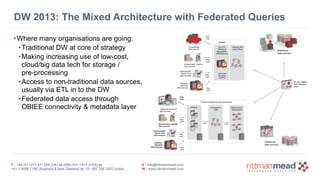
- 19. DW 2013: The Mixed Architecture with Federated Queries •Where many organisations are going: •Traditional DW at core of strategy •Making increasing use of low-cost, cloud/big data tech for storage / pre-processing •Access to non-traditional data sources, usually via ETL in to the DW •Federated data access through OBIEE connectivity & metadata layer T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com
- 20. Oracle’s Big Data Products •Oracle Big Data Appliance - Engineered System for Big Data Acquisition and Processing ‣Cloudera Distribution of Hadoop ‣Cloudera Manager ‣Open-source R ‣Oracle NoSQL Database Community Edition ‣Oracle Enterprise Linux + Oracle JVM •Oracle Big Data Connectors ‣Oracle Loader for Hadoop (Hadoop > Oracle RBDMS) ‣Oracle Direct Connector for HDFS (HFDS > Oracle RBDMS) ‣Oracle Data Integration Adapter for Hadoop ‣Oracle R Connector for Hadoop ‣Oracle NoSQL Database (column/key-store DB based on BerkeleyDB) T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com
- 21. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Oracle Loader for Hadoop •Oracle technology for accessing Hadoop data, and loading it into an Oracle database •Pushes data transformation, “heavy lifting” to the Hadoop cluster, using MapReduce •Direct-path loads into Oracle Database, partitioned and non-partitioned •Online and offline loads •Key technology for fast load of Hadoop results into Oracle DB
- 22. Oracle Direct Connector for HDFS •Enables HDFS as a data-source for Oracle Database external tables •Effectively provides Oracle SQL access over HDFS •Supports data query, or import into Oracle DB •Treat HDFS-stored files in the same way as regular files ‣But with HDFS’s low-cost ‣… and fault-tolerance T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com
- 23. Oracle Data Integration Adapter for Hadoop •ODI 11g/12c Application Adapter (pay-extra option) for Hadoop connectivity •Works for both Windows and Linux installs of ODI Studio ‣Need to source HiveJDBC drivers and JARs from separate Hadoop install •Provides six new knowledge modules ‣IKM File to Hive (Load Data) ‣IKM Hive Control Append ‣IKM Hive Transform ‣IKM File-Hive to Oracle (OLH) ‣CKM Hive ‣RKM Hive T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com
- 24. How ODI Accesses Hadoop Data •ODI accesses data in Hadoop clusters through Apache Hive ‣Metadata and query layer over MapReduce ‣Provides SQL-like language (HiveQL) and a data dictionary ‣Provides a means to define “tables”, into which file data is loaded, and then queried via MapReduce ‣Accessed via Hive JDBC driver(separate Hadoop install required on ODI server, for client libs) •Additional access through Oracle Direct Connector for HDFS and Oracle Loader for Hadoop T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Hadoop Cluster MapReduce Hive Server ODI 11g Oracle RDBMS HiveQL Direct-path loads using Oracle Loader for Hadoop, transformation logic in MapReduce
- 25. ODI as Part of Oracle’s Big Data Strategy •ODI is the data integration tool for extracting data from Hadoop/MapReduce, and loading into Oracle Big Data Appliance, Oracle Exadata and Oracle Exalytics •Oracle Application Adaptor for Hadoop provides required data adapters ‣Load data into Hadoop from local filesystem, or HDFS (Hadoop clustered FS) ‣Read data from Hadoop/MapReduce using Apache Hive (JDBC) and HiveQL, load into Oracle RDBMS using Oracle Loader for Hadoop •Supported by Oracle’s Engineered Systems ‣Exadata ‣Exalytics ‣Big Data Appliance T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com
- 26. Support for Heterogenous Sources and Targets •ODI12c isn’t just a big data ETL tool though •Technology adapters for most RDBMSs, file types, OBIEE, application sources •Multidimensional servers such as Oracle Essbase, and associated EPM apps •XML sources, and JMS queues •SOA environments, using messaging and service buses, typically in real-time •All enabled through “knowledge module” approach - ODI acts as orchestrator and code generator, uses E-L-T approach T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com
- 27. The Key to ODI Extensibility - Knowledge Modules •Divides the ETL process into separate steps - extract (load), integrate, check constraints etc •ODI generates native code for each platform, taking a template for each step + adding table names, column names, join conditions etc ‣Easy to extend ‣Easy to read the code ‣Makes it possible for ODI to support Spark, Pig etc in future ‣Uses the power of the target platform for integration tasks T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com -Hadoop-native ETL
- 28. Part of the Wider Oracle Data Integration Platform •Oracle Data Integrator for large-scale data integration across heterogenous sources and targets •Oracle GoldenGate for heterogeneous data replication and changed data capture •Oracle Enterprise Data Quality for data profiling and cleansing •Oracle Data Services Integrator for SOA message-based data federation T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com
- 29. ODI and Big Data Integration Example •In this example, we’ll show an end-to-end ETL process on Hadoop using ODI12c & BDA •Scenario: load webserver log data into Hadoop, process enhance and aggregate, then load final summary table into Oracle Database 12c ‣Process using Hadoop framework ‣Leverage Big Data Connectors ‣Metadata-based ETL development using ODI12c ‣Real-world example T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com
- 30. ETL & Data Flow through BDA System •Five-step process to load, transform, aggregate and filter incoming log data •Leverage ODI’s capabilities where possible •Make use of Hadoop power + scalability Flume Agent T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) Sqoop extract ! posts (Hive Table) IKM Hive Control Append (Hive table join & load into target hive table) categories_sql_ extract (Hive Table) E : [email protected] W : www.rittmanmead.com hive_raw_apache_ access_log (Hive Table) Flume Agent !!!!!! Apache HTTP Server Log Files (HDFS) Flume Messaging TCP Port 4545 (example) IKM File to Hive 1 using RegEx SerDe log_entries_ and post_detail (Hive Table) IKM Hive Control Append (Hive table join & load into target hive table) hive_raw_apache_ access_log (Hive Table) 2 3 Geocoding IP>Country list (Hive Table) IKM Hive Transform (Hive streaming through Python script) 4 5 hive_raw_apache_ access_log (Hive Table) IKM File / Hive to Oracle (bulk unload to Oracle DB)
- 31. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Five-Step ETL Process 1. Take the incoming log files (via Flume) and load into a structured Hive table 2. Enhance data from that table to include details on authors, posts from other Hive tables 3. Join to some additional ref. data held in an Oracle database, to add author details 4. Geocode the log data, so that we have the country for each calling IP address 5. Output the data in summary form to an Oracle database
- 32. Using Flume to Transport Log Files to BDA •Apache Flume is the standard way to transport log files from source through to target •Initial use-case was webserver log files, but can transport any file from A>B •Does not do data transformation, but can send to multiple targets / target types •Mechanisms and checks to ensure successful transport of entries •Has a concept of “agents”, “sinks” and “channels” •Agents collect and forward log data •Sinks store it in final destination •Channels store log data en-route •Simple configuration through INI files •Handled outside of ODI12c T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com
- 33. GoldenGate for Continuous Streaming to Hadoop •Oracle GoldenGate is also an option, for streaming RDBMS transactions to Hadoop •Leverages GoldenGate & HDFS / Hive Java APIs •Sample Implementations on MOS Doc.ID 1586210.1 (HDFS) and 1586188.1 (Hive) •Likely to be formal part of GoldenGate in future release - but usable now T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com
- 34. Using Flume for Distributed Log Capture to Single Target •Multiple agents can be used to capture logs from many sources, combine into one output •Needs at least one source agent, and a target agent •Agents can be multi-step, handing-off data across the topology •Channels store data in files, or in RAM, as a buffer between steps •Log files being continuously written to have contents trickle-fed across to source •Sink types for Hive, HBase and many others •Free software, part of Hadoop platform T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com
- 35. Configuring Flume for Log Transport to the BDA •Conf file for source system agent •TCP port, channel size+type, source type T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) •Conf file for target system agent •TCP port, channel size+type, sink type E : [email protected] W : www.rittmanmead.com
- 36. Starting the Agents, Check Files Landing in HDFS Directory •Start the Flume agents on source and target (BDA) servers •Check that incoming file data starts appearing in HDFS ‣Note - files will be continuously written-to as entries added to source log files ‣Channel size for source, target agents determines max no. of events buffered ‣If buffer exceeded, new events dropped until buffer < channel size T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com
- 37. Load Incoming Log Files into Hive Table •First step in process is to load the incoming log files into a Hive table ‣Also need to parse the log entries to extract request, date, IP address etc columns ‣Hive table can then easily be used in downstream transformations •Use IKM File to Hive (LOAD DATA) KM ‣Source can be local files or HDFS ‣Either load file into Hive HDFS area, or leave as external Hive table ‣Ability to use SerDe to parse file data T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com 1
- 38. First Though … Need to Setup Topology and Models •HDFS data servers (source) defined using generic File technology •Workaround to support IKM Hive Control Append •Leave JDBC driver blank, put HDFS URL in JDBC URL field T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com
- 39. Defining Physical Schema and Model for HDFS Directory •Hadoop processes typically access a whole directory of files in HDFS, rather than single one •Hive, Pig etc aggregate all files in that directory and treat as single file •ODI Models usually point to a single file though - how do you set up access correctly? T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com
- 40. Defining Physical Schema and Model for HDFS Directory •ODI appends file name to Physical Schema name for Hive access •To access a directory, set physical schema to parent directory •Set model Resource Name to directory you want to use as source •Note - need to manually enter file/ resource names, and “Test” button does not work for HDFS sources T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com
- 41. Defining Topology and Model for Hive Sources •Hive supported “out-of-the-box” with ODI12c (but requires ODIAAH license for KMs) •Most recent Hadoop distributions use HiveServer2 rather than HiveServer •Need to ensure JDBC drivers support Hive version •Use correct JDBC URL format (jdbc:hive2//…) T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com
- 42. Hive Tables and Underlying HDFS Storage Permissions •Hadoop by default has quite loose security •Files in HDFS organized into directories, using Unix-like permissions •Hive tables can be created by any user, over directories they have read-access to ‣But that user might not have write permissions on the underlying directory ‣Causes mapping execution failures in ODI if directory read-only •Therefore ensure you have read/write access to directories used by Hive, and create tables under the HDFS user you’ll access files through JDBC ‣Simplest approach - create Hue user for “oracle”, create Hive tables under that user T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com
- 43. Final Model and Datastore Definitions •HDFS files for incoming log data, and any other input data •Hive tables for ETL targets and downstream processing •Use RKM Hive to reverse-engineer column definition from Hive T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com
- 44. Using IKM File to Hive to Load Web Log File Data into Hive •Create mapping to load file source (single column for weblog entries) into Hive table •Target Hive table should have column for incoming log row, and parsed columns T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com
- 45. Specifying a SerDe to Parse Incoming Hive Data •SerDe (Serializer-Deserializer) interfaces give Hive the ability to process new file formats •Distributed as JAR file, gives Hive ability to parse semi-structured formats •We can use the RegEx SerDe to parse the Apache CombinedLogFormat file into columns •Enabled through OVERRIDE_ROW_FORMAT IKM File to Hive (LOAD DATA) KM option T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com
- 46. Distributing SerDe JAR Files for Hive across Cluster •Hive SerDe functionality typically requires additional JARs to be made available to Hive •Following steps must be performed across ALL BDA nodes: ‣Add JAR reference to HIVE_AUX_JARS_PATH in /usr/lib/hive/conf/hive.env.sh ! ! ! ‣Add JAR file to /usr/lib/hadoop ! ! ! ‣Restart YARN / MR1 TaskTrackers across cluster export HIVE_AUX_JARS_PATH=/usr/lib/hive/lib/hive-contrib-0.12.0-cdh5.0.1.jar:$ (echo $HIVE_AUX_JARS_PATH… [root@bdanode1 hadoop]# ls /usr/lib/hadoop/hive-* /usr/lib/hadoop/hive-contrib-0.12.0-cdh5.0.1.jar T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com
- 47. Executing First ODI12c Mapping •EXTERNAL_TABLE option chosen in IKM File to Hive (LOAD DATA) as Flume will continue writing to it until source log rotate •View results of data load in ODI Studio T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com
- 48. Join to Additional Hive Tables, Transform using HiveQL •IKM Hive to Hive Control Append can be used to perform Hive table joins, filtering, agg. etc. •INSERT only, no DELETE, UPDATE etc •Not all ODI12c mapping operators supported, but basic functionality works OK •Use this KM to join to other Hive tables, adding more details on post, title etc •Perform DISTINCT on join output, load into summary Hive table T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com 2
- 49. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Joining Hive Tables •Only equi-joins supported •Must use ANSI syntax •More complex joins may not produce valid HiveQL (subqueries etc)
- 50. Filtering, Aggregating and Transforming Within Hive •Aggregate (GROUP BY), DISTINCT, FILTER, EXPRESSION, JOIN, SORT etc mapping operators can be added to mapping to manipulate data •Generates HiveQL functions, clauses etc T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com
- 51. Executing Second Mapping •ODI IKM Hive to Hive Control Append generates HiveQL to perform data loading •In the background, Hive on BDA creates MapReduce job(s) to load and transform HDFS data •Automatically runs across the cluster, in parallel and with fault tolerance, HA T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com
- 52. Bring in Reference Data from Oracle Database •In this third step, additional reference data from Oracle Database needs to be added •In theory, should be able to add Oracle-sourced datastores to mapping and join as usual •But … Oracle / JDBC-generic LKMs don’t get work with Hive T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com 3
- 53. Options for Importing Oracle / RDBMS Data into Hadoop •Using ODI, only KM option currently is IKM File to Hive (LOAD DATA) •But this involves an unnecessary export to file before loading •One option is to use Apache Sqoop, and call from an ODI Procedure •Hadoop-native, automatically runs in parallel •Uses native JDBC drivers, or OraOop (for example) •Bi-directional in-and-out of Hadoop to RDBMS •Run from OS command-line T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com
- 54. Creating an ODI Procedure to Invoke Sqoop •Create an OS task, can then reference whole Oracle tables, or an SQL SELECT T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com
- 55. Sqoop Command-Line Parameters sqoop import —connect jdbc:oracle:thin:@centraldb11gr2.rittmandev.com:1521/ ctrl11g.rittmandev.com —username blog_refdata —password password —query ‘SELECT p.post_id, c.cat_name from post_one_cat p, categories c where p.cat_id = c.cat_id and $CONDITIONS’ —target_dir /user/oracle/post_categories —hive-import —hive-overwrite —hive-table post_categories —split-by p.post_id •—username, —password : database account username and password •—query : SELECT statement to retrieve data (can use —table instead, for single table) •$CONDITIONS, —split-by : column by which MapReduce jobs can be run in parallel •—hive-import, —hive-overwrite, —hive-table : name and load mode for Hive table •— target_dir : target HDFS directory to land data in initially (required for SELECT) T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com
- 56. Initial Sqoop Invocation to Create Hive Target Table •Run Sqoop once (from command-line, or from ODI Procedure) to create the target Hive table •Can then reverse-engineer the table metadata using RKM Hive, to add to Model •Thereafter, run as part of Package or Load Plan T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com
- 57. Join Oracle-Sourced Hive Table to Existing Hive Table •Oracle-sourced reference data in Hive can then be joined to existing Hive table as normal •Filters, aggregation operators etc can be added to mapping if required •Use IKM Hive Control Append as integration KM T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com
- 58. Note - New in ODI12c 12.1.3 - Sqoop KM and HBase KMs •At the time of writing (May 2013) there was no official Sqoop support in ODI12c •ODI 12.1.3 (introduced July 2013) introduced a number of new KMs including ‣IKM SQL to Hive-HBase-File (Sqoop) ‣LKM HBase to Hive ‣IKM Hive to HBase ‣RKM HBase ‣IKM File-Hive to SQL (Sqoop) •See http://www.ateam-oracle.com/importing-data- from-sql-databases-into-hadoop-with-sqoop- and-oracle-data-integrator-odi/ for details T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com
- 59. ODI Static and Flow Control : Data Quality and Error Handling •CKM Hive can be used with IKM Hive to Hive Control Append to filter out erroneous data •Static controls can be used to create “data firewalls” •Flow control used in Physical mapping view to handle errors, exceptions •Example: Filter out rows where IP address is from a test harness T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com
- 60. Enabling Flow Control in IKM Hive to Hive Control Append •Check the ENABLE_FLOW_CONTROL option in KM settings •Select CKM Hive as the check knowledge module •Erroneous rows will get moved to E_ table in Hive, not loaded into target Hive table T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com
- 61. Using Hive Streaming and Python for Geocoding Data •Another requirement we have is to “geocode” the webserver log entries •Allows us to aggregate page views by country •Based on the fact that IP ranges can usually be attributed to specific countries •Not functionality normally found in Hive etc, but can be done with add-on APIs T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com 4
- 62. How GeoIP Geocoding Works •Uses free Geocoding API and database from Maxmind •Convert IP address to an integer •Find which integer range our IP address sits within •But Hive can’t use BETWEEN in a join… T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com
- 63. Solution : IKM Hive Transform •IKM Hive Transform can pass the output of a Hive SELECT statement through a perl, python, shell etc script to transform content •Uses Hive TRANSFORM … USING … AS functionality hive> add file file:///tmp/add_countries.py; Added resource: file:///tmp/add_countries.py hive> select transform (hostname,request_date,post_id,title,author,category) > using 'add_countries.py' > as (hostname,request_date,post_id,title,author,category,country) > from access_per_post_categories; T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com
- 64. Creating the Python Script for Hive Streaming •Solution requires a Python API to be installed on all Hadoop nodes, along with geocode DB wget ! https://raw.github.com/pypa/pip/master/contrib/get-pip.py python ! get-pip.py pip install pygeoip ! •Python script then parses incoming stdin lines using tab-separation of fields, outputs same (but with extra field for the country) #!/usr/bin/python import sys sys.path.append('/usr/lib/python2.6/site-packages/') import pygeoip gi = pygeoip.GeoIP('/tmp/GeoIP.dat') for line in sys.stdin: line = line.rstrip() hostname,request_date,post_id,title,author,category = line.split('t') country = gi.country_name_by_addr(hostname) print hostname+'t'+request_date+'t'+post_id+'t'+title+'t'+author T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com +'t'+country+'t'+category
- 65. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Setting up the Mapping •Map source Hive table to target, which includes column for extra “country” column ! ! ! ! ! ! ! •Copy script + GeoIP.dat file to every node’s /tmp directory •Ensure all Python APIs and libraries are installed on each Hadoop node
- 66. Configuring IKM Hive Transform •TRANSFORM_SCRIPT_NAME specifies name of script, and path to script •TRANSFORM_SCRIPT has issues with parsing; do not use, leave blank and KM will use existing one •Optional ability to specify sort and distribution columns (can be compound) •Leave other options at default T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com
- 67. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Executing the Mapping •KM automatically registers the script with Hive (which caches it on all nodes) •HiveQL output then runs the contents of the first Hive table through the script, outputting results to target table
- 68. Bulk Unload Summary Data to Oracle Database •Final requirement is to unload final Hive table contents to Oracle Database •Several use-cases for this: •Use Hadoop / BDA for ETL offloading •Use analysis capabilities of BDA, but then output results to RDBMS data mart or DW •Permit use of more advanced SQL query tools •Share results with other applications •Can use Sqoop for this, or use Oracle Big Data Connectors •Fast bulk unload, or transparent Oracle access to Hive T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com 5
- 69. Oracle Direct Connector for HDFS •Enables HDFS as a data-source for Oracle Database external tables •Effectively provides Oracle SQL access over HDFS •Supports data query, or import into Oracle DB •Treat HDFS-stored files in the same way as regular files •But with HDFS’s low-cost •… and fault-tolerance T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com
- 70. Oracle Loader for Hadoop (OLH) •Oracle technology for accessing Hadoop data, and loading it into an Oracle database •Pushes data transformation, “heavy lifting” to the Hadoop cluster, using MapReduce •Direct-path loads into Oracle Database, partitioned and non-partitioned •Online and offline loads •Load from HDFS or Hive tables •Key technology for fast load of Hadoop results into Oracle DB T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com
- 71. IKM File/Hive to Oracle (OLH/ODCH) •KM for accessing HDFS/Hive data from Oracle •Either sets up ODCH connectivity, or bulk-unloads via OLH •Map from HDFS or Hive source to Oracle tables (via Oracle technology in Topology) T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com
- 72. Environment Variable Requirements •Hardest part in setting up OLH / IKM File/Hive to Oracle is getting environment variables correct - OLH needs to be able to see correct JARs, configuration files •Set in /home/oracle/.bashrc - see example below export HIVE_HOME=/usr/lib/hive export HADOOP_CLASSPATH=/home/oracle/oracle/product/oraloader-3.0.0-h2/jlib/*:/etc/hive/conf:$HIVE_HOME/lib/ hive-metastore-0.12.0-cdh5.0.1.jar:$HIVE_HOME/lib/libthrift.jar:$HIVE_HOME/lib/libfb303-0.9.0.jar:$HIVE_HOME/ lib/hive-common-0.12.0-cdh5.0.1.jar:$HIVE_HOME/lib/hive-exec-0.12.0-cdh5.0.1.jar export OLH_HOME=/home/oracle/oracle/product/oraloader-3.0.0-h2 export HADOOP_HOME=/usr/lib/hadoop export JAVA_HOME=/usr/java/jdk1.7.0_60 export ODI_HIVE_SESSION_JARS=/usr/lib/hive/lib/hive-contrib.jar export ODI_OLH_JARS=/home/oracle/oracle/product/oraloader-3.0.0-h2/jlib/ojdbc6.jar,/home/oracle/oracle/ product/oraloader-3.0.0-h2/jlib/orai18n.jar,/home/oracle/oracle/product/oraloader-3.0.0-h2/jlib/orai18n-utility. jar,/home/oracle/oracle/product/oraloader-3.0.0-h2/jlib/orai18n-mapping.jar,/home/oracle/oracle/ product/oraloader-3.0.0-h2/jlib/orai18n-collation.jar,/home/oracle/oracle/product/oraloader-3.0.0-h2/jlib/ oraclepki.jar,/home/oracle/oracle/product/oraloader-3.0.0-h2/jlib/osdt_cert.jar,/home/oracle/oracle/product/ oraloader-3.0.0-h2/jlib/osdt_core.jar,/home/oracle/oracle/product/oraloader-3.0.0-h2/jlib/commons-math- 2.2.jar,/home/oracle/oracle/product/oraloader-3.0.0-h2/jlib/jackson-core-asl-1.8.8.jar,/home/oracle/ oracle/product/oraloader-3.0.0-h2/jlib/jackson-mapper-asl-1.8.8.jar,/home/oracle/oracle/product/ oraloader-3.0.0-h2/jlib/avro-1.7.3.jar,/home/oracle/oracle/product/oraloader-3.0.0-h2/jlib/avro-mapred-1.7.3- hadoop2.jar,/home/oracle/oracle/product/oraloader-3.0.0-h2/jlib/oraloader.jar,/usr/lib/hive/lib/hive-metastore. jar,/usr/lib/hive/lib/libthrift-0.9.0.cloudera.2.jar,/usr/lib/hive/lib/libfb303-0.9.0.jar,/usr/lib/ hive/lib/hive-common-0.12.0-cdh5.0.1.jar,/usr/lib/hive/lib/hive-exec.jar T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com
- 73. Configuring the KM Physical Settings •For the access table in Physical view, change LKM to LKM SQL Multi-Connect •Delegates the multi-connect capabilities to the downstream node, so you can use a multi-connect IKM such as IKM File/Hive to Oracle T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com
- 74. Configuring the KM Physical Settings •For the target table, select IKM File/Hive to Oracle •Only becomes available to select once LKM SQL Multi-Connect selected for access table •Key option values to set are: •OLH_OUTPUT_MODE (use JDBC initially, OCI if Oracle Client installed on Hadoop client node) •MAPRED_OUTPUT_BASE_DIR (set to directory on HFDS that OS user running ODI can access) T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com
- 75. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Executing the Mapping •Executing the mapping will invoke OLH from the OS command line •Hive table (or HDFS file) contents copied to Oracle table
- 76. Create Package to Sequence ETL Steps •Define package (or load plan) within ODI12c to orchestrate the process •Call package / load plan execution from command-line, web service call, or schedule T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com
- 77. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Execute Overall Package •Each step executed in sequence •End-to-end ETL process, using ODI12c’s metadata-driven development process, data quality handing, heterogenous connectivity, but Hadoop-native processing
- 78. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Conclusions •Hadoop, and the Oracle Big Data Appliance, is an excellent platform for data capture, analysis and processing •Hadoop tools such as Hive, Sqoop, MapReduce and Pig provide means to process and analyse data in parallel, using languages + approach familiar to Oracle developers •ODI12c provides several benefits when working with ETL and data loading on Hadoop ‣Metadata-driven design; data quality handling; KMs to handle technical complexity •Oracle Data Integrator Adapter for Hadoop provides several KMs for Hadoop sources •In this presentation, we’ve seen an end-to-end example of big data ETL using ODI ‣The power of Hadoop and BDA, with the ETL orchestration of ODI12c
- 79. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Thank You for Attending! •Thank you for attending this presentation, and more information can be found at http:// www.rittmanmead.com •Contact us at [email protected] or [email protected] •Look out for our book, “Oracle Business Intelligence Developers Guide” out now! •Follow-us on Twitter (@rittmanmead) or Facebook (facebook.com/rittmanmead)
- 80. ODI12c as your Big Data Integration Hub Mark Rittman, CTO, Rittman Mead July 2014 T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com