OGH 2015 - Hadoop (Oracle BDA) and Oracle Technologies on BI Projects
7 likes4,079 views

Presentation to the Dutch Oracle Users Group in Jan 2015, on the use of Hadoop and the Oracle Big Data Appliance for Oracle BI&DW projects.








































































































































Ad
More Related Content
What's hot (20)
Viewers also liked (6)




Ad
Similar to OGH 2015 - Hadoop (Oracle BDA) and Oracle Technologies on BI Projects (20)




















Ad
More from Mark Rittman (15)















Recently uploaded (20)












![Pixologic ZBrush Crack Plus Activation Key [Latest 2025] New Version](https://cdn.slidesharecdn.com/ss_thumbnails/fashionevolution2-250322112409-f76abaa7-250428124909-b51264ff-250504160528-fc2bb1c5-thumbnail.jpg?width=560&fit=bounds)







OGH 2015 - Hadoop (Oracle BDA) and Oracle Technologies on BI Projects
- 1. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Hadoop (BDA) and Oracle Technologies on BI Projects Mark Rittman, CTO, Rittman Mead Dutch Oracle Users Group, Jan 14th 2015
- 2. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com About the Speaker •Mark Rittman, Co-Founder of Rittman Mead •Oracle ACE Director, specialising in Oracle BI&DW •14 Years Experience with Oracle Technology •Regular columnist for Oracle Magazine •Author of two Oracle Press Oracle BI books •Oracle Business Intelligence Developers Guide •Oracle Exalytics Revealed •Writer for Rittman Mead Blog : http://www.rittmanmead.com/blog •Email : [email protected] •Twitter : @markrittman
- 3. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com About Rittman Mead •Oracle BI and DW Gold partner •Winner of five UKOUG Partner of the Year awards in 2013 - including BI •World leading specialist partner for technical excellence, solutions delivery and innovation in Oracle BI •Approximately 80 consultants worldwide •All expert in Oracle BI and DW •Offices in US (Atlanta), Europe, Australia and India •Skills in broad range of supporting Oracle tools: ‣OBIEE, OBIA ‣ODIEE ‣Essbase, Oracle OLAP ‣GoldenGate ‣Endeca
- 4. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Agenda •Part 1 : The Hadoop (BDA) technical stack for Oracle BI/DW projects ‣Why are Oracle BI/DW customers adopting Hadoop (BDA) technologies? ‣What are the Oracle and Cloudera products being used? ‣New Oracle products on the roadmap - Big Data Discovery, Big Data SQL futures ‣Where does OBIEE, ODI etc fit in with these new products ‣Rittman Mead’s development platform •Part 2 : Rittman Mead Hadoop (BDA) + Oracle BI Project Experiences ‣What is Cloudera CDH, and the BDA, like to work with? ‣How do we approach projects and PoCs? ‣What architecture and approach do we actually take, now? ‣How well do OBIEE and ODI work with Hadoop and BDA? ‣What are the emerging techs, products and architectures we see for 2015+?
- 5. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Part 1 : The Hadoop (BDA) technical stack for Oracle BI/DW projects or … How did we get here?
- 6. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com 15+ Years in Oracle BI and Data Warehousing •Started back in 1997 on a bank Oracle DW project •Our tools were Oracle 7.3.4, SQL*Plus, PL/SQL and shell scripts •Went on to use Oracle Developer/2000 and Designer/2000 •Our initial users queried the DW using SQL*Plus •And later on, we rolled-out Discoverer/2000 to everyone else •And life was fun…
- 7. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com The Oracle-Centric DW Architecture •Over time, this data warehouse architecture developed •Added Oracle Warehouse Builder to automate and model the DW build •Oracle 9i Application Server (yay!) to deliver reports and web portals •Data Mining and OLAP in the database •Oracle 9i for in-database ETL (and RAC) •Data was typically loaded from Oracle RBDMS and EBS •It was turtles Oracle all the way down…
- 8. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com The State of the Art for BI & DW Was This.. •Oracle Discoverer “Drake” - Combining Relational and OLAP Analysis for Oracle RDBMS •Oracle Portal, part of Oracle 9iAS •Oracle Warehouse Builder 9iAS / “Paris”
- 9. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Then Came Siebel Analytics … and OBIEE
- 10. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com The Oracle BI & DW World Changed •Siebel Analytics replaced Oracle DIscoverer •Oracle Data Integrator replaced Oracle Warehouse Builder •Hyperion Essbase Replaced Oracle OLAP •You were as likely to be loading from SQL Server as from Oracle •They made us do things we didn’t like to do … ‣Add a mid-tier virtual DW engine on top of the database ‣Export data out of Oracle into an OLAP server ‣Improve query performance using tools outside of the Oracle data warehouse ‣It was all a bit scary… ‣… Not to mention that WebLogic stuff
- 11. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Introducing - The Oracle Reference DW Architecture •Recognizing the difference between long-term storage of DW data (the “foundation” layer) •And organizing the data for queries and easy navigation (the “access + performance layer”) •Also recognising where OBIEE had been game-changing - federated queries •… Things are good again
- 12. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com and now …this happened
- 13. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com
- 14. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Today’s Oracle Information Management Architecture Actionable Events Event Engine Data Reservoir Data Factory Enterprise Information Store Reporting Discovery Lab Actionable Information Actionable Insights Input Events Execution Innovation Discovery Output Events & Data Structured Enterprise Data Other Data
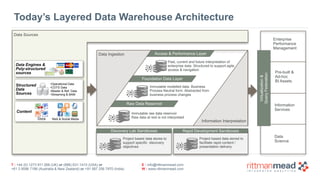
- 15. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Today’s Layered Data Warehouse Architecture Virtualization& QueryFederation Enterprise Performance Management Pre-built & Ad-hoc BI Assets Information Services Data Ingestion Information Interpretation Access & Performance Layer Foundation Data Layer Raw Data Reservoir Data Science Data Engines & Poly-structured sources Content Docs Web & Social Media SMS Structured Data Sources •Operational Data •COTS Data •Master & Ref. Data •Streaming & BAM Immutable raw data reservoir Raw data at rest is not interpreted Immutable modelled data. Business Process Neutral form. Abstracted from business process changes Past, current and future interpretation of enterprise data. Structured to support agile access & navigation Discovery Lab Sandboxes Rapid Development Sandboxes Project based data stores to support specific discovery objectives Project based data stored to facilitate rapid content / presentation delivery Data Sources
- 16. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com The Oracle Data Warehousing Platform - 2014
- 17. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Introducing … The “Data Reservoir”? •A reservoir is a lake than also can process and refine (your data) •Wide-ranging source of low-density, lower-value data to complement the DW
- 18. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Oracle’s Big Data Products •Oracle Big Data Appliance ‣Optimized hardware for Hadoop processing ‣Cloudera Distribution incl. Hadoop ‣Oracle Big Data Connectors, ODI etc •Oracle Big Data Connectors •Oracle Big Data SQL •Oracle NoSQL Database •Oracle Data Integrator •Oracle R Distribution •OBIEE, BI Publisher and Endeca Info Discovery
- 19. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Just Released - Oracle Big Data SQL •Part of Oracle Big Data 4.0 (BDA-only) ‣Also requires Oracle Database 12c, Oracle Exadata Database Machine •… More on this later Exadata Storage Servers Hadoop Cluster Exadata Database Server Oracle Big Data SQL SQL Queries SmartScan SmartScan
- 20. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Coming Soon : Oracle Big Data Discovery •Combining of Endeca Server search, analysis and visualisation capabilities with Apache Spark data munging and transformation ‣Analyse, parse, explore and “wrangle” data using graphical tools and a Spark-based transformation engine ‣Create a catalog of the data on your Hadoop cluster, then search that catalog using Endeca Server ‣Create recommendations of other datasets, based on what you’re looking at now ‣Visualize your datasets, discover new insights
- 21. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Coming Soon : Oracle Data Enrichment Cloud Service •Cloud-based service for loading, enriching, cleansing and supplementing Hadoop data •Part of the Oracle Data Integration product family •Used up-stream from Big Data Discovery •Aims to solve the “data quality problem” for Hadoop
- 22. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Combining Oracle RDBMS with Hadoop + NoSQL •High-value, high-density data goes into Oracle RDBMS •Better support for fast queries, summaries, referential integrity etc •Lower-value, lower-density data goes into Hadoop + NoSQL ‣Also provides flexible schema, more agile development •Successful next-generation BI+DW projects combine both - neither on their own is sufficient
- 23. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Productising the Next-Generation IM Architecture
- 24. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Still a Key Role for Data Integration, and BI Tools •Fast, scaleable low-cost / flexible-schema data capture using Hadoop + NoSQL (BDA) •Long-term storage of the most important downstream data - Oracle RBDMS (Exadata) •Fast analysis + business-friendly interface : OBIEE, Endeca (Exalytics), RTD etc
- 25. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com OBIEE for Enterprise Analysis Across all Data Sources •Dashboards, analyses, OLAP analytics, scorecards, published reporting, mobile •Presented as an integrated business semantic model •Optional mid-tier query acceleration using Oracle Exalytics In-Memory Machine •Access data from RBDMS, applications, Hadoop, OLAP, ADF BCs etc Enterprise Semantic Business Model Business Presentation Layer (Reports, Dashboards) In-Memory Caching Layer Application Sources Hadoop / NoSQL Sources DW / OLAP Sources
- 26. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Bringing it All Together : Oracle Data Integrator 12c •ODI provides an excellent framework for running Hadoop ETL jobs ‣ELT approach pushes transformations down to Hadoop - leveraging power of cluster •Hive, HBase, Sqoop and OLH/ODCH KMs provide native Hadoop loading / transformation ‣Whilst still preserving RDBMS push-down ‣Extensible to cover Pig, Spark etc •Process orchestration •Data quality / error handling •Metadata and model-driven
- 27. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Oracle’s Product Strategy
- 28. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Rittman Mead Hadoop (BDA) + Oracle BI Project Experiences •Working with (Cloudera) Hadoop, + Hive, NoSQL, etc •Working with the Oracle Big Data Appliance •Typical Hadoop + BI Use-Cases •How Rittman Mead approaches Hadoop + Oracle BI projects •Hadoop things that keep the CIO awake at night… •ODI and Hadoop •OBIEE and Hadoop •Oracle Big Data SQL •Futures - Apache Spark, Next-Generation Hive, Big Data Discovery
- 29. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Why is Hadoop of Interest to Us? •Gives us an ability to store more data, at more detail, for longer •Provides a cost-effective way to analyse vast amounts of data •Hadoop & NoSQL technologies can give us “schema-on-read” capabilities •There’s vast amounts of innovation in this area we can harness •And it’s very complementary to Oracle BI & DW
- 30. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Oracle & Hadoop Use-Cases •Use Hadoop as a low-cost, horizontally-scalable DW archive •Use Hadoop, Hive and MapReduce for low-cost ETL staging •Support standalone-Hadoop / Spark analysis with Oracle reference data •Extend the DW with new data sources, datatypes, detail-level data
- 31. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com The Killer, Tech-Focused Use Case : Data Reservoir •A reservoir is a lake than also can process and refine (your data) •Wide-ranging source of low-density, lower-value data to complement the DW
- 32. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Typical Business Use Case : 360 Degree View of Cust / Process •OLTP transactional tells us what happened (in the past), but not “why” •Common customer requirement now is to get a “360 degree view” of their activity ‣Understand what’s being said about them ‣External drivers for interest, activity ‣Understand more about customer intent, opinions •One example is to add details of social media mentions, likes, tweets and retweets etc to the transactional dataset ‣Correlate twitter activity with sales increases, drops ‣Measure impact of social media strategy ‣Gather and include textual, sentiment, contextual data from surveys, media etc
- 33. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Initial PoC over 4-6 Weeks •Focus on high-productivity data analyst tools to identify key data, insights •Typically performed using R, CDH on VMs, lots of scripting, lots of client interaction •Focus on the “discovery” phase ‣Governance, dashboards, productionizing can come later
- 34. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Discovery vs. Exploitation Project Phases •Discovery and monetising steps in Big Data projects have different requirements •Discovery phase ‣Unbounded discovery ‣Self-Service sandbox ‣Wide toolset •Promotion to Exploitation ‣Commercial exploitation ‣Narrower toolset ‣Integration to operations ‣Non-functional requirements ‣Code standardisation & governance
- 35. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Rittman Mead Development Lab 64GB RAM, 6TB Disk Core i7 4x3.6GHz VMWare ESXi 5.5 vmhost2 vmhost3 vmhost4 vmhost5 BDP 2.2 Cluster 5 x nodes CDH 5.3 Cluster 5 x nodes Kerberos-Secured CDH 5.2 Cluster 6 x nodes (16-32GB RAM / node) Oracle RDBMS OBIEE 11g ODI12c BI Apps 11g KDCLDAP 64GB RAM, 6TB Disk Core i7 4x3.6GHz VMWare ESXi 5.5 64GB RAM, 6TB Disk Core i7 4x3.6GHz VMWare ESXi 5.5 64GB RAM, 6TB Disk Core i7 4x3.6GHz VMWare ESXi 5.5 iSCSI LUN shared VMFS cluster filesystem Synology DS414 NAS, 6TB (For testing VMWare VMotion failover, large HDFS datasets etc) Mac Mini Server OS X Server DNS etc EM 12c R4 VCenter 16GB RAM, 1TB Disk Core i7 2x3.6GHz Vigor 2830n Router VPN, DHCP etc •4 x 64GB VM Servers • 256GB RAM across cluster • 36TB Storage • VMWare ESXi 5.5 + VCenter •Additional iSCSI 6TB storage • Synology DS414 NAS •Demo / Free Software Installs ‣Cloudera CDH5 Express - and BDP2.2 for Tez ‣Oracle RBDMS, OBIEE, ODI etc ‣Oracle Big Data Connectors ‣Oracle EM 12cR4
- 36. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Cluster Management •VMWare VSphere 5 + VCenter Server •Oracle Enterprise Manager 12cR4 Cloud Control •OSX Server Yosemite
- 37. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com BigDataLite Demonstration VM •Demo / Training VM downloadable from OTN •Contains Cloudera Hadoop + Oracle Big Data Connectors + Big Data SQL •Similar to setup on Oracle BDA •Contains OBIEE enabling technologies: ‣Apache Hive (SQL access over Hadoop) ‣Apache HDFS (file storage) ‣Oracle Direct Connector for HDFS ‣Oracle R Advanced Analytics for Hadoop ‣Oracle Big Data SQL •Great way to get started with Hadoop ‣Requires 8GB RAM, modern laptop etc
- 38. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com So … how well does it work?
- 39. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Part 2 : Rittman Mead Hadoop (BDA) + Oracle BI Project Experiences
- 40. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Typical RM Project BDA Topology •Starter BDA rack, or full rack •Kerberos-secured using included KDC server •Integration with corporate LDAP for Cloudera Manager, Hue etc •Developer access through Hue, Beeline, R Studio •End-user access through OBIEE, Endeca and other tools ‣With final datasets usually exported to Exadata or Exalytics
- 41. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Oracle Big Data Appliance •Engineered system for big data processing and analysis •Optimized for enterprise Hadoop workloads •288 Intel® Xeon® E5 Processors •1152 GB total memory •648TB total raw storage capacity ‣Cloudera Distribution of Hadoop ‣Cloudera Manager ‣Open-source R ‣Oracle NoSQL Database Community Edition ‣Oracle Enterprise Linux + Oracle JVM ‣New - Oracle Big Data SQL
- 42. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Working with Oracle Big Data Appliance •Don’t underestimate the value of “pre-integrated” - massive time-saver for client ‣No need to integrate Big Data Connectors, ODI Agent etc with HDFS, Hive etc etc •Single support route - raise SR with Oracle, they will route to Cloudera if needed •Single patch process for whole cluster - OS, CDH etc etc •Full access to Cloudera Enterprise features •Otherwise … just another CDH cluster in terms of SSH access etc •We like it ;-)
- 43. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Cloudera Distribution including Hadoop (CDH) •Like Linux, you can set up your Hadoop system manually, or use a distribution •Key Hadoop distributions include Cloudera CDH, Hortonworks HDP, MapR etc •Cloudera CDH is the distribution Oracle use on Big Data Appliance ‣Provides HDFS and Hadoop framework for BDA ‣Includes Pig, Hive, Sqoop, Oozie, HBase ‣Cloudera Impala for real-time SQL access ‣Cloudera Manager & Hue
- 44. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Cloudera Manager and Hue •Web-based tools provided with Cloudera CDH •Cloudera Manager used for cluster admin, maintenance (like Enterprise Manager ‣Commercial tool developed by Cloudera ‣Not enabled by default in BigDataLite VM •Hue is a developer / analyst tool for working with Pig, Hive, Sqoop, HDFS etc ‣Open source project included in CDH
- 45. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com BigDataLite Demonstration VM •Demo / Training VM downloadable from OTN •Contains Cloudera Hadoop + Oracle Big Data Connectors + Big Data SQL •Similar to setup on Oracle BDA •Contains OBIEE enabling technologies: ‣Apache Hive (SQL access over Hadoop) ‣Apache HDFS (file storage) ‣Oracle Direct Connector for HDFS ‣Oracle R Advanced Analytics for Hadoop ‣Oracle Big Data SQL •Great way to get started with Hadoop ‣Requires 8GB RAM, modern laptop etc
- 46. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Working with Cloudera Hadoop (CDH) - Observations •Very good product stack, enterprise-friendly, big community, can do lots with free edition •Cloudera have their favoured Hadoop technologies - Spark, Kafka •Also makes use of Cloudera-specific tools - Impala, Cloudera Manager etc •But ignores some tools that have value - Apache Tez for example •Easy for an Oracle developer to get productive with the CDH stack •But beware of some immature technologies / products ‣Hive != Oracle SQL ‣Spark is very much an “alpha” product ‣Limitations in things like LDAP integration, end-to-end security ‣Lots of products in stack = lots of places to go to diagnose issues
- 47. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com CDH : Things That Work Well •HDFS as a low-cost, flexible data store / reservoir; Hive for SQL access to structured + semi-structured HDFS data •Pig, Spark, Python, R for data analysis and munging •Cloudera Manager and Hue for web-based admin + dev access Real-Time Logs / Events RDBMS Imports File / Unstructured Imports Hive Metastore / HCatalog HDFS Cluster Filesystem
- 48. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Oracle Big Data Connectors •Oracle-licensed utilities to connect Hadoop to Oracle RBDMS ‣Bulk-extract data from Hadoop to Oracle, or expose HDFS / Hive data as external tables ‣Run R analysis and processing on Hadoop ‣Leverage Hadoop compute resources to offload ETL and other work from Oracle RBDMS ‣Enable Oracle SQL to access and load Hadoop data
- 49. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Working with the Oracle Big Data Connectors •Oracle Loader for Hadoop, Oracle SQL Connector for HDFS - rarely used ‣Sqoop works both way (Oracle>Hadoop, Hadoop>Oracle) and is “good enough” ‣OSCH replaced by Oracle Big Data SQL for direct Oracle>Hive access •Oracle R Advanced Analytics for Hadoop has been very useful though ‣Run MapReduce jobs from R ‣Run R functions across Hive tables
- 50. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Oracle R Advanced Analytics for Hadoop Key Features •Run R functions on Hive Dataframes •Write MapReduce functions in R
- 51. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Initial Data Scoping & Discovery using R •R is typically used at start of a big data project to get a high-level understanding of the data •Can be run as R standalone, or using Oracle R Advanced Analytics for Hadoop •Do basic scan of incoming dataset, get counts, determine delimiters etc •Distribution of values for columns •Basic graphs and data discovery •Use findings to drive design of parsing logic, Hive data structures, need for data scrubbing / correcting etc
- 52. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Design Pattern : Discovery Lab Actionable Events Event Engine Data Reservoir Data Factory Enterprise Information Store Reporting Discovery Lab Actionable Information Actionable Insights Input Events Execution Innovation Discovery Output Events & Data Structured Enterprise Data Other Data
- 53. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Design Pattern : Discovery Lab •Specific focus on identifying commercial value for exploitation •Small group of highly skilled individuals (aka Data Scientists) •Iterative development approach – data oriented NOT development oriented •Wide range of tools and techniques applied ‣Searching and discovering unstructured data ‣Finding correlations and clusters ‣Filtering, aggregating, deriving and enhancing data •Data provisioned through Data Factory or own ETL •Typically separate infrastructure but could also be unified Reservoir if resource managed effectively
- 54. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com For the Future - Oracle Big Data Discovery
- 55. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Interactive Analysis & Exploration of Hadoop Data
- 56. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Share and Collaborate on Big Data Discovery Projects
- 57. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Typical RM Big Data Project Tools Used Data prep via R scripts, Python scripts etc Data Loading Real-time via Flume Conf scripts Batch via Sqoop cmd-line exec Sharing output via Hive tables, Impala tables, HDFS files etc Data Export Batch via Sqoop cmd-line exec a.k.a. “data munging” Data analysis via R scripts, Python scripts, Pig, Spark etc a.k.a. “the magic” “Discovery” phase “Exploitation” phase
- 58. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Data Loading into Hadoop •Default load type is real-time, streaming loads ‣Batch / bulk loads only typically used to seed system •Variety of sources including web log activity, event streams •Target is typically HDFS (Hive) or HBase •Data typically lands in “raw state” ‣Lots of files and events, need to be filtered/aggregated ‣Typically semi-structured (JSON, logs etc) ‣High volume, high velocity -Which is why we use Hadoop rather than RBDMS (speed vs. ACID trade-off) ‣Economics of Hadoop means its often possible to archive all incoming data at detail level Loading Stage Real-Time Logs / Events File / Unstructured Imports
- 59. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Apache Flume : Distributed Transport for Log Activity •Apache Flume is the standard way to transport log files from source through to target •Initial use-case was webserver log files, but can transport any file from A>B •Does not do data transformation, but can send to multiple targets / target types •Mechanisms and checks to ensure successful transport of entries •Has a concept of “agents”, “sinks” and “channels” •Agents collect and forward log data •Sinks store it in final destination •Channels store log data en-route •Simple configuration through INI files •Handled outside of ODI12c
- 60. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Apache Kafka : Reliable, Message-Based •Developed by LinkedIn, designed to address Flume issues around reliability, throughput ‣(though many of those issues have been addressed since) •Designed for persistent messages as the common use case ‣Website messages, events etc vs. log file entries •Consumer (pull) rather than Producer (push) model •Supports multiple consumers per message queue •More complex to set up than Flume, and can use Flume as a consumer of messages ‣But gaining popularity, especially alongside Spark Streaming
- 61. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com GoldenGate for Continuous Streaming to Hadoop •Oracle GoldenGate is also an option, for streaming RDBMS transactions to Hadoop •Leverages GoldenGate & HDFS / Hive Java APIs •Sample Implementations on MOS Doc.ID 1586210.1 (HDFS) and 1586188.1 (Hive) •Likely to be formal part of GoldenGate in future release - but usable now •Can also integrate with Flume for delivery to HDFS - see MOS Doc.ID 1926867.1
- 62. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com NoSQL Databases •Family of database types that reject tabular storage, SQL access and ACID compliance •Useful as a way of landing data quickly + supporting random cell-level access by ETL process •Focus is on scalability, speed and schema-on-read ‣Oracle NoSQL Database - speed and scalability ‣Apache HBase - speed, scalability and Hadoop ‣MongoDB - native storage of JSON documents •May or may not run on Hadoop, but associated with it •Great choice for high-velocity data capture •CRUD approach vs write-once/read many in HDFS
- 63. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com ODI on Hadoop - Big Data Projects Discover ETL Tools •ODI provides an excellent framework for running Hadoop ETL jobs ‣ELT approach pushes transformations down to Hadoop - leveraging power of cluster •Hive, HBase, Sqoop and OLH/ODCH KMs provide native Hadoop loading / transformation ‣Whilst still preserving RDBMS push-down ‣Extensible to cover Pig, Spark etc •Process orchestration •Data quality / error handling •Metadata and model-driven
- 64. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com ODI on Hadoop - How Well Does It Work? •Very good for set-based processing of Hadoop data (HiveQL) ‣Can run python, R etc scripts as procedures •Brings metadata and team-based ETL development to Hadoop •Process orchestration, error-handling etc •Rapid innovation from the ODI Product Dev team - Spark KMs etc coming soon •But requires Hadoop devs to learn ODI, or add ODI developer to the project
- 65. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Options for Sharing Hadoop Output with Wider Audience •During the discovery phase of a Hadoop project, audience are likely technical ‣Most comfortable with data analyst tools, command-line, low-level access to the data •During the exploitation phase, audience will be less technical ‣Emphasis on graphical tools, and integration with wider reporting toolset + metadata •Three main options for visualising and sharing Hadoop data 1.Coming Soon - Oracle Big Data Discovery (Endeca on Hadoop) 2.OBIEE reporting against Hadoop direct using Hive/Impala, or Oracle Big Data SQL 3.OBIEE reporting against an export of the Hadoop data, on Exalytics / RDBMS
- 66. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Oracle Business Analytics and Big Data Sources •OBIEE 11g can also make use of big data sources ‣OBIEE 11.1.1.7+ supports Hive/Hadoop as a data source ‣Oracle R Enterprise can expose R models through DB functions, columns ‣Oracle Exalytics has InfiniBand connectivity to Oracle BDA •Endeca Information Discovery can analyze unstructured and semi-structured sources ‣Increasingly tighter-integration between OBIEE and Endeca
- 67. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com New in OBIEE 11.1.1.7 : Hadoop Connectivity through Hive •MapReduce jobs are typically written in Java, but Hive can make this simpler •Hive is a query environment over Hadoop/MapReduce to support SQL-like queries •Hive server accepts HiveQL queries via HiveODBC or HiveJDBC, automatically creates MapReduce jobs against data previously loaded into the Hive HDFS tables •Approach used by ODI and OBIEE to gain access to Hadoop data •Allows Hadoop data to be accessed just like any other data source
- 68. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Importing Hadoop/Hive Metadata into RPD •HiveODBC driver has to be installed into Windows environment, so that BI Administration tool can connect to Hive and return table metadata •Import as ODBC datasource, change physical DB type to Apache Hadoop afterwards •Note that OBIEE queries cannot span >1 Hive schema (no table prefixes) 1 2 3
- 69. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com OBIEE 11.1.1.7 / HiveServer2 ODBC Driver Issue •Most customers using BDAs are using CDH4 or CDH5 - which uses HiveServer2 •OBIEE 11.1.1.7 only ships/supports HiveServer1 ODBC drivers •But … OBIEE 11.1.1.7 on Windows can use the Cloudera HiveServer2 ODBC drivers ‣which isn’t supported by Oracle ‣but works!
- 70. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Dealing with Hadoop / Hive Latency Option 1 : Impala •Hadoop access through Hive can be slow - due to inherent latency in Hive •Hive queries use MapReduce in the background to query Hadoop •Spins-up Java VM on each query •Generates MapReduce job •Runs and collates the answer •Great for large, distributed queries ... •... but not so good for “speed-of-thought” dashboards
- 71. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Dealing with Hadoop / Hive Latency Option 1 : Use Impala •Hive is slow - because it’s meant to be used for batch-mode queries •Many companies / projects are trying to improve Hive - one of which is Cloudera •Cloudera Impala is an open-source but commercially-sponsored in-memory MPP platform •Replaces Hive and MapReduce in the Hadoop stack •Can we use this, instead of Hive, to access Hadoop? ‣It will need to work with OBIEE ‣Warning - it won’t be a supported data source (yet…)
- 72. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com How Impala Works •A replacement for Hive, but uses Hive concepts and data dictionary (metastore) •MPP (Massively Parallel Processing) query engine that runs within Hadoop ‣Uses same file formats, security, resource management as Hadoop •Processes queries in-memory •Accesses standard HDFS file data •Option to use Apache AVRO, RCFile, LZO or Parquet (column-store) •Designed for interactive, real-time SQL-like access to Hadoop Impala Hadoop HDFS etc BI Server Presentation Svr Cloudera Impala ODBC Driver Impala Hadoop HDFS etc Impala Hadoop HDFS etc Impala Hadoop HDFS etc Impala Hadoop HDFS etc Multi-Node Hadoop Cluster
- 73. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Connecting OBIEE 11.1.1.7 to Cloudera Impala •Warning - unsupported source - limited testing and no support from MOS •Requires Cloudera Impala ODBC drivers - Windows or Linux (RHEL etc/SLES) - 32/64 bit •ODBC Driver / DSN connection steps similar to Hive
- 74. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com So Does Impala Work, as a Hive Substitute? •With ORDER BY disabled in DB features, it appears to •But not extensively tested by me, or Oracle •But it’s certainly interesting •Reduces 30s, 180s queries down to 1s, 10s etc •Impala, or one of the competitor projects (Drill, Dremel etc) assumed to be the real-time query replacement for Hive, in time ‣Oracle announced planned support for Impala at OOW2013 - watch this space
- 75. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Dealing with Hadoop / Hive Latency Option 2 : Export to Data Mart •In most cases, for general reporting access, exporting into RDBMS makes sense •Export Hive data from Hadoop into Oracle Data Mart or Data Warehouse •Use Oracle RDBMS for high-value data analysis, full access to RBDMS optimisations •Potentially use Exalytics for in-memory RBDMS access Loading Stage Processing Stage Store / Export Stage Real-Time Logs / Events RDBMS Imports File / Unstructured Imports RDBMS Exports File Exports
- 76. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Dealing with Hadoop / Hive Latency Option 3 : Big Data SQL •Preferred solution for customers with Oracle Big Data Appliance is Big Data SQL •Oracle SQL Access to both relational, and Hive/NoSQL data sources •Exadata-type SmartScan against Hadoop datasets •Response-time equivalent to Impala or Hive on Tez •No issues around HiveQL limitations •Insulates end-users around differences between Oracle and Hive datasets
- 77. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Oracle Big Data SQL •Part of Oracle Big Data 4.0 (BDA-only) ‣Also requires Oracle Database 12c, Oracle Exadata Database Machine •Extends Oracle Data Dictionary to cover Hive •Extends Oracle SQL and SmartScan to Hadoop •Extends Oracle Security Model over Hadoop ‣Fine-grained access control ‣Data redaction, data masking ‣Uses fast c-based readers where possible (vs. Hive MapReduce generation) ‣Map Hadoop parallelism to Oracle PQ ‣Big Data SQL engine works on top of YARN ‣Like Spark, Tez, MR2 Exadata Storage Servers Hadoop Cluster Exadata Database Server Oracle Big Data SQL SQL Queries SmartScan SmartScan
- 78. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com View Hive Table Metadata in the Oracle Data Dictionary •Oracle Database 12c 12.1.0.2.0 with Big Data SQL option can view Hive table metadata ‣Linked by Exadata configuration steps to one or more BDA clusters •DBA_HIVE_TABLES and USER_HIVE_TABLES exposes Hive metadata •Oracle SQL*Developer 4.0.3, with Cloudera Hive drivers, can connect to Hive metastore SQL> col database_name for a30 SQL> col table_name for a30 SQL> select database_name, table_name 2 from dba_hive_tables; DATABASE_NAME TABLE_NAME ------------------------------ ------------------------------ default access_per_post default access_per_post_categories default access_per_post_full default apachelog default categories default countries default cust default hive_raw_apache_access_log
- 79. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Big Data SQL Server Dataflow •Read data from HDFS Data Node ‣Direct-path reads ‣C-based readers when possible ‣Use native Hadoop classes otherwise •Translate bytes to Oracle •Apply SmartScan to Oracle bytes ‣Apply filters ‣Project columns ‣Parse JSON/XML ‣Score models Disks% Data$Node$ Big$Data$SQL$Server$ External$Table$Services$ Smart$Scan$ RecordReader% SerDe% 10110010%10110010%10110010% 1% 2% 3% 1 2 3
- 80. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Hive Access through Oracle External Tables + Hive Driver •Big Data SQL accesses Hive tables through external table mechanism ‣ORACLE_HIVE external table type imports Hive metastore metadata ‣ORACLE_HDFS requires metadata to be specified •Access parameters cluster and tablename specify Hive table source and BDA cluster CREATE TABLE access_per_post_categories( hostname varchar2(100), request_date varchar2(100), post_id varchar2(10), title varchar2(200), author varchar2(100), category varchar2(100), ip_integer number) organization external (type oracle_hive default directory default_dir access parameters(com.oracle.bigdata.tablename=default.access_per_post_categories));
- 81. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Use Rich Oracle SQL Dialect over Hadoop (Hive) Data •Ranking Functions ‣rank, dense_rank, cume_dist, percent_rank, ntile •Window Aggregate Functions ‣Avg, sum, min, max, count, variance, first_value, last_value •LAG/LEAD Functions •Reporting Aggregate Functions ‣Sum, Avg, ratio_to_report •Statistical Aggregates ‣Correlation, linear regression family, covariance •Linear Regression ‣Fitting of ordinary-least-squares regression line to set of number pairs •Descriptive Statistics •Correlations ‣Pearson’s correlation coefficients •Crosstabs ‣Chi squared, phi coefficinet •Hypothesis Testing ‣Student t-test, Bionomal test •Distribution ‣Anderson-Darling test - etc.
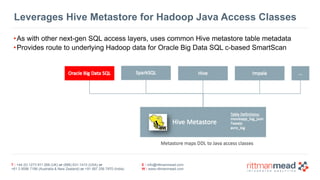
- 82. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Leverages Hive Metastore for Hadoop Java Access Classes •As with other next-gen SQL access layers, uses common Hive metastore table metadata •Provides route to underlying Hadoop data for Oracle Big Data SQL c-based SmartScan
- 83. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Extending SmartScan, and Oracle SQL, Across All Data •Brings query-offloading features of Exadata to Oracle Big Data Appliance •Query across both Oracle and Hadoop sources •Intelligent query optimisation applies SmartScan close to ALL data •Use same SQL dialect across both sources •Apply same security rules, policies, user access rights across both sources
- 84. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Example : Using Big Data SQL to Add Dimensions to Hive Data •We want to add country and post details to a Hive table containing page accesses •Post and Country details are stored in Oracle RBDMS reference tables Hive Weblog Activity table Oracle Dimension lookup tables Combined output in report form
- 85. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Create ORACLE_HIVE External Table over Hive Table •Use the ORACLE_HIVE access driver type to create Oracle external table over Hive table •ACCESS_PER_POST_EXTTAB now appears in Oracle data dictionary
- 86. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Import Oracle Tables, Create RPD joining Tables Together •No need to use Hive ODBC drivers - Oracle OCI connection instead •No issue around HiveServer1 vs HiveServer2; also Big Data SQL handles authentication with Hadoop cluster in background, Kerberos etc •Transparent to OBIEE - all appear as Oracle tables •Join across schemas if required
- 87. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Create Physical Data Model from Imported Table Metadata •Join ORACLE_HIVE external table containing log data, to reference tables from Oracle DB
- 88. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Create Business Model and Presentation Layers •Map incoming physical tables into a star schema •Add aggregation method for fact measures •Add logical keys for logical dimension tables •Remove columns from fact table that aren’t measures
- 89. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Create Initial Analyses Against Combined Dataset •Create analyses using full SQL features •Access to Oracle RDBMS Advanced Analytics functions through EVALUATE, EVALUATE_AGGR etc •Big Data SQL SmartScan feature provides fast, ad-hoc access to Hive data, avoiding MapReduce
- 90. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Oracle / Hive Query Federation at the RDBMS Level •Oracle Big Data SQL feature (not BI Server) takes care of query federation •SQL required for fact table (web log activity) access sent to Big Data SQL agent on BDA •Only columns (projection) and rows (filtering) required to answer query sent back to Exadata •Storage Indexes used on both Exadata Storage Servers and BDA nodes to skip block reads for irrelevant data •HDFS caching used to speed-up access to commonly-used HDFS data
- 91. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Access to Full Set of Oracle Join Types •No longer restricted to HiveQL equi-joins - Big Data SQL supports all Oracle join operators •Use to join Hive data (using View over external table) to a IP range country lookup table using BETWEEN join operator
- 92. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Add In Time Dimension Table •Enables time-series reporting; pre-req for forecasting (linear regression-type queries) •Map to Date field in view over ORACLE_HIVE table ‣Convert incoming Hive STRING field to Oracle DATE for better time-series manipulation
- 93. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Now Enables Time-Series Reporting Incl. Country Lookups
- 94. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com What About Oracle Big Data SQL and ODI12c? •Hive, and MapReduce, are well suited to batch-type ETL jobs, but … •Not all join types are available in Hive - joins must be equality joins •Any data from external Oracle RDBMS sources has to be staged in Hadoop before joining •Limited set of HiveQL functions vs. Oracle SQL •Oracle-based mappings have to import Hive data into DB before accessing it
- 95. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Combining Oracle and Hadoop (Hive) Data in Mappings •Example scenario : log data in Hadoop needs to be enriched with customer data in Oracle ‣Hadoop (Hive) contains log activity and customer etc IDs ‣Reference / customer data held in Oracle RBDMS •How do we create a mapping that joins both datasets? movieapp_log_odistage.custid = CUSTOMER.CUSTID
- 96. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Options for Importing Oracle / RDBMS Data into Hadoop •Could export RBDMS data to file, and load using IKM File to Hive •Oracle Big Data Connectors only export to Oracle, not import to Hadoop •One option is to use Apache Sqoop, and new IKM SQL to Hive-HBase-File knowledge module •Hadoop-native, automatically runs in parallel •Uses native JDBC drivers, or OraOop (for example) •Bi-directional in-and-out of Hadoop to RDBMS •Join performed in Hive, using HiveQL ‣With HiveQL limitations (only equi-joins) movieapp_log_odistage.custid = customer.custid Sqoop extract
- 97. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com New Option - Using Oracle Big Data SQL •Oracle Big Data SQL provides ability for Exadata to reference Hive tables •Use feature to create join in Oracle, bringing across Hive data through ORACLE_HIVE table
- 98. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Oracle Big Data SQL and Data Integration •Gives us the ability to easily bring in Hadoop (Hive) data into Oracle-based mappings •Allows us to create Hive-based mappings that use Oracle SQL for transforms, joins •Faster access to Hive data for real-time ETL scenarios •Through Hive, bring NoSQL and semi-structured data access to Oracle ETL projects •For our scenario - join weblog + customer data in Oracle RDBMS, no need to stage in Hive
- 99. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Using Big Data SQL in an ODI12c Mapping •By default, Hive table has to be exposed as an ORACLE_HIVE external table in Oracle first •Then register that Oracle external table in ODI repository + model External table creation in Oracle Logical Mapping using just Oracle tables 1 2 Register in ODI Model 3
- 100. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Custom KM : LKM Hive to Oracle (Big Data SQL) •ODI12c Big Data SQL example on BigDataLite VM uses a custom KM for Big Data SQL ‣LKM Hive to Oracle (Big Data SQL) - KM code downloadable from java.net ‣Allows Hive+Oracle joins by auto-creating ORACLE_HIVE extttab definition to enable Big Data SQL Hive table access
- 101. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com ODI12c Mapping Creates Temp Exttab, Joins to Oracle 1 2 Register in ODI Model 3 4 Hive table AP uses LKM Hive to Oracle (Big Data SQL) IKM Oracle Insert Big Data SQL Hive External Table created as temp object Main integration SQL routines uses regular Oracle SQL join
- 102. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Finally … What Keeps the CIO Awake at Night •Security and Privacy Regulations ‣Are we analysing and sharing data in compliance with privacy regulations? -And if we are - would customers think our use of it is ethical? ‣Do I know if the data in my Hadoop cluster is *really* secure?
- 103. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Hadoop Security “By Default” •Connections between Hadoop services, and by users to services, aren’t authenticated •Security is fragmented : HDFS, Hive, OS user accounts, Hue, CM all separate models •No single place to define security policies, groups, access rights •No single tool to audit access and permissions •By default, everything is open and trusted - reflects roots in academia, R&D, marketing depts
- 104. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com “Secured” Hadoop : Kerberos, Sentry, Data Encryption etc •Available for most Hadoop distributions, part of core Hadoop •Kerberos Authentication - enables service-to-service, and client-to-service authentication using MIT Kerberos or MS AD Kerberos •Apache Sentry - Role-based Access Control for Hive, Impala and HDFS (CDH5.3+) •Transparent at-rest HDFS encryption (CDH5.3+) •Closes security loopholes, goes some way to Oracle-type data security
- 105. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Oracle Big Data SQL : Single RBDMS/Hadoop Security Model •Potential to extend Oracle security model over Hadoop (Hive) data ‣Masking / Redaction ‣VPD ‣FGAC
- 106. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Summary •Hadoop and Oracle Big Data Appliance are increasingly appearing in BI+DW Projects •Gives DW projects the ability to store more data, cheaper and more flexibly than before •Enables non-relational (SQL) query tools and analysis techniques (R, Spark etc) •Extends BI’s capability to report and analyze across wider data sources •Maturity varies widely in terms of tool maturity, and Oracle integration with Hadoop •Trend is for Oracle to “productize” big data, creating tools + products around Oracle BDA •We are probably at early stages - but very interesting times to be an Oracle BI+DW dev!
- 107. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Thank You for Attending! •Thank you for attending this presentation, and more information can be found at http:// www.rittmanmead.com •Contact us at [email protected] or [email protected] •Look out for our book, “Oracle Business Intelligence Developers Guide” out now! •Follow-us on Twitter (@rittmanmead) or Facebook (facebook.com/rittmanmead)
- 108. T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India) E : [email protected] W : www.rittmanmead.com Hadoop and Oracle Technologies on BI Projects Mark Rittman, CTO, Rittman Mead Dutch Oracle Users Group, Jan 14th 2015