On Improving Broadcast Joins in Apache Spark SQL

- The document discusses improving broadcast joins in Apache Spark SQL, which are more efficient than shuffle joins when the broadcasted data fits in memory. - Experimenting with increasing the broadcast threshold showed that executor-side broadcasting performs better than driver-side broadcasting by avoiding data shuffling to the driver. - Comparing the cost models of shuffle joins and broadcast joins showed that shuffle joins perform better with more cores while broadcast joins perform better when the size difference between tables is larger. - Applying these techniques to joins in Workday HR customer data pipelines showed that increasing the broadcast threshold did not always improve performance due to the presence of self-joins and outer joins.









































On Improving Broadcast Joins in Apache Spark SQL
- 1. On Improving Broadcast Joins in Spark SQL Jianneng Li Software Engineer, Workday
- 2. This presentation may contain forward-looking statements for which there are risks, uncertainties, and assumptions. If the risks materialize or assumptions prove incorrect, Workday’s business results and directions could differ materially from results implied by the forward-looking statements. Forward-looking statements include any statements regarding strategies or plans for future operations; any statements concerning new features, enhancements or upgrades to our existing applications or plans for future applications; and any statements of belief. Further information on risks that could affect Workday’s results is included in our filings with the Securities and Exchange Commission which are available on the Workday investor relations webpage: www.workday.com/company/investor_relations.php Workday assumes no obligation for and does not intend to update any forward-looking statements. Any unreleased services, features, functionality or enhancements referenced in any Workday document, roadmap, blog, our website, press release or public statement that are not currently available are subject to change at Workday’s discretion and may not be delivered as planned or at all. Customers who purchase Workday, Inc. services should make their purchase decisions upon services, features, and functions that are currently available. Safe Harbor Statement
- 3. Agenda ▪ Apache Spark in Workday Prism Analytics ▪ Broadcast Joins in Spark ▪ Improving Broadcast Joins ▪ Production Case Study
- 4. Spark in Workday Prism Analytics
- 5. Example Spark physical plan of our pipeline shown in Spark UI ▪ Customers use our self- service product to build data transformation pipelines, which are compiled to DataFrames and executed by Spark ▪ Finance and HR use cases ▪ This talk focuses on our HR use cases - more on complex plans than big data Spark in Prism Analytics For more details, see session from SAIS 2019 - Lessons Learned using Apache Spark for Self-Service Data Prep in SaaS World
- 6. Broadcast Joins in Spark
- 7. Node 1 A 1 B 2 C 3 DD 4 Node 2 D 4 E 5 F 6 AA 1 Node 1 Node 2 A 1 B 2 C 3 AA 1 DD 4 D 4 E 5 F 6 AA 1 DD 4 Broadcast Join #UnifiedAnalytics #SparkAISummit Broadcast Join Review
- 8. Broadcast Join Shuffle Join Avoids shuffling the bigger side Shuffles both sides Naturally handles data skew Can suffer from data skew Cheap for selective joins Can produce unnecessary intermediate results Broadcasted data needs to fit in memory Data can be spilled and read from disk Cannot be used for certain outer joins Can be used for all joins Broadcast Join vs. Shuffle Join Where applicable, broadcast join should be faster than shuffle join
- 9. ▪ Spark's broadcasting mechanism is inefficient ▪ Broadcasted data goes through the driver ▪ Too much broadcasted data can run the driver out of memory Broadcasting in Spark Driver Executor 1 Executor 2 (1) Executors sends broadcasted data to driver (2) Driver sends broadcasted data to executors
- 10. ▪ Uses broadcasting mechanism to collect data to driver ▪ Planned per-join using size estimation and config spark.sql.autoBroadcastJoinThreshold Broadcast Joins in Spark ▪ BroadcastHashJoin (BHJ) ▪ Driver builds in-memory hashtable to distribute to executors ▪ BroadcastNestedLoopJoin (BNLJ) ▪ Distributes data as array to executors ▪ Useful for non-equi joins ▪ Disabled in Prism for stability reasons
- 12. Goal: More broadcast joins ▪ Q: Is broadcast join faster as long as broadcasted data fits in memory? ▪ A: It depends ▪ Experiment: increase broadcast threshold, and see what breaks ▪ Spoiler: many things go wrong before driver runs out of memory
- 14. Experiment setup ▪ TPC-H Dataset, 10GB ▪ Query: 60M table (lineitem) joining 15M table (orders) on key ▪ Driver: 1 core, 12 GB memory ▪ Executor: 1 instance, 18 cores, 102 GB memory
- 15. Single join results SELECT lineitem.* FROM lineitem, orders WHERE l_orderkey = o_orderkey
- 16. ▪ Driver collects 15M rows ▪ Driver builds hashtable ▪ Driver sends hashtable to executor ▪ Executor deserializes hashtable Why is BHJ slower?
- 17. Can we reduce BHJ overhead? ▪ Yes - executor side broadcast
- 18. Executor Side Broadcast ▪ Based on prototype from SPARK-17556 ▪ Data is broadcasted between executors directly Driver Executor 1 Executor 2 Executors sends broadcasted data to each other Driver keeps track of executor’s data blocks
- 19. Executor BHJ vs. Driver BHJ Pros Cons Driver has less memory pressure Each executor builds its own hashtable Less data shuffled across network More difficult to know size of broadcast Pros of executor BHJ outweigh cons
- 20. New results SELECT lineitem.* FROM lineitem, orders WHERE l_orderkey = o_orderkey
- 21. Why is BHJ still slower? ▪ Let's compare the cost models of the joins
- 22. SMJ Cost ▪ Assume n cores, tables A and B, where A > B 1. Read A/n, Sort, Write A/n 2. Read B/n, Sort, Write B/n 3. Read A/n, Read B/n, Join ▪ Considering only I/O costs: 3 A/n + 3 B/n
- 23. BHJ Cost ▪ Assume n cores, tables A and B, where A > B 1. Read B/n, Build hashtable, Write B 2. Read A/n, Read B, Join ▪ Considering only I/O costs: A/n + B/n + 2B
- 24. ▪ SMJ: 3 A/n + 3 B/n ▪ BHJ: A/n + B/n + 2B ▪ SMJ - BHJ: (2 A/n + 2 B/n) - (2B) Comparing SMJ and BHJ costs ▪ Analysis ▪ More cores, better performance from SMJ ▪ Larger A, better performance from BHJ SMJ vs. BHJ: (A + B)/n vs. B
- 25. Varying cores - SMJ better with more cores SELECT lineitem.* FROM lineitem, orders WHERE l_orderkey = o_orderkey
- 26. Varying size of A - BHJ better with larger difference SELECT lineitem.* FROM lineitem, orders WHERE l_orderkey = o_orderkey
- 27. Increasing size of B - driver BHJ fails, executor BHJ best SELECT lineitem.* FROM lineitem, orders WHERE l_orderkey = o_orderkey
- 28. Other broadcast join improvements ▪ Increase Xms and MetaspaceSize to reduce GC ▪ Fetch all broadcast variables concurrently ▪ Other memory improvements in planning and whole-stage codegen ▪ Planning to contribute code changes back to open source
- 30. ▪ 98% of our joins are inner joins or left outer joins Join types in HR customer pipelines
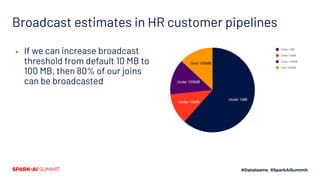
- 31. Broadcast estimates in HR customer pipelines ▪ If we can increase broadcast threshold from default 10 MB to 100 MB, then 80% of our joins can be broadcasted
- 32. ▪ 30 tables ▪ 29 tables 10K rows ▪ 1 table 3M rows ▪ ~160 joins ▪ Using 18 executor cores HR use case pipeline ▪ Can broadcast joins make the pipeline run faster?
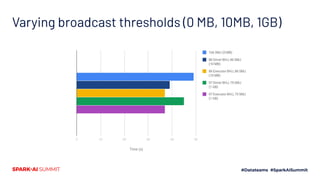
- 33. Varying broadcast thresholds (0 MB, 10MB, 1GB)
- 34. What if we increase the 3M table? ▪ Will it bring similar performance improvements as single join?
- 35. 30M rows for the big table
- 36. Why are more broadcast joins slower? ▪ Self joins and left outer joins ▪ In the highest threshold, the biggest table gets broadcasted ▪ Introduces broadcast overhead ▪ Reduces join parallelism ▪ Takes up storage memory
- 37. Closing Thoughts
- 38. ▪ Executor side broadcast is better than driver side broadcast ▪ When evaluating whether broadcast is better, consider: ▪ Number of cores available ▪ Relative size difference between bigger and smaller tables ▪ Relative size of broadcast tables and available memory ▪ Presence of self joins and outer joins Broadcast joins are better… with caveats
- 39. Future improvements in broadcast joins ▪ Adaptive Query Execution in Spark 3.0 ▪ Building hashtables in BHJ with multiple cores ▪ Smaller footprint for BHJ hashtables ▪ Skew handling in sort merge join using broadcast
- 40. Thank you
- 41. Questions?
- 42. Feedback Your feedback is important to us. Don’t forget to rate and review the sessions.