OneAPI dpc++ Virtual Workshop 9th Dec-20
Download as PPTX, PDF•0 likes•178 views

The document presents an overview of the Intel® oneAPI and DPC++ programming model aimed at simplifying development for heterogeneous architectures while enhancing performance through data parallelism. It includes a 'Hello World' example, highlights the DPC++ compatibility tool for migrating CUDA code, and explains kernel execution models alongside device memory management. Additionally, it emphasizes the open-source nature of DPC++ and encourages community participation in its development.









{
return (std::abs(a) < std::abs(b));
}
);
}
• A convenient way of defining an
anonymous function object right at
the location where it is invoked or
passed as an argument to a function
• Lambda functions can be used to
define kernels in SYCL
• The kernel lambda MUST use copy
for all its captures (i.e., [=])
Capture clause
Parameter list
Lambda body
10](https://image.slidesharecdn.com/oneapidpcvirtualworkshop-9thdec20-201210090944/85/OneAPI-dpc-Virtual-Workshop-9th-Dec-20-10-320.jpg)





 {
16](https://image.slidesharecdn.com/oneapidpcvirtualworkshop-9thdec20-201210090944/85/OneAPI-dpc-Virtual-Workshop-9th-Dec-20-16-320.jpg)

 {
C[i] = A[i] + B[i];});
18
Each iteration (work-
item) will have a
separate index id (i)](https://image.slidesharecdn.com/oneapidpcvirtualworkshop-9thdec20-201210090944/85/OneAPI-dpc-Virtual-Workshop-9th-Dec-20-18-320.jpg)
![Intel Confidential 19
int main() {
float A[N], B[N], C[N];
{ buffer bufA (A, range(N));
buffer bufB (B, range(N));
buffer bufC (C, range(N));
queue myQueue;
myQueue.submit([&](handler& cgh) {
auto A = bufA.get_access(cgh, read_only);
auto B = bufB.get_access(cgh, read_only);
auto C = bufC.get_access(cgh);
cgh.parallel_for<class vector_add>(N, [=](auto i){
C[i] = A[i] + B[i];});
});
}
for (int i = 0; i < 5; i++){
cout << "C[" << i << "] = " << C[i] <<std::endl;
}
return 0;
}
DPC++ “Hello World”: Vector Addition Entire Code
19](https://image.slidesharecdn.com/oneapidpcvirtualworkshop-9thdec20-201210090944/85/OneAPI-dpc-Virtual-Workshop-9th-Dec-20-19-320.jpg)
![Intel Confidential 20
int main() {
float A[N], B[N], C[N];
{ buffer bufA (A, range(N));
buffer bufB (B, range(N));
buffer bufC (C, range(N));
queue myQueue;
myQueue.submit([&](handler& cgh) {
auto A = bufA.get_access(cgh, read_only);
auto B = bufB.get_access(cgh, read_only);
auto C = bufC.get_access(cgh);
cgh.parallel_for<class vector_add>(N, [=](auto i) {
C[i] = A[i] + B[i];});
});
}
for (int i = 0; i < 5; i++){
cout << "C[" << i << "] = " << C[i] <<std::endl;}
return 0;
}
Host code
Anatomy of a DPC++ Application
20
Host code](https://image.slidesharecdn.com/oneapidpcvirtualworkshop-9thdec20-201210090944/85/OneAPI-dpc-Virtual-Workshop-9th-Dec-20-20-320.jpg)
![Intel Confidential 21
int main() {
float A[N], B[N], C[N];
{ buffer bufA (A, range(N));
buffer bufB (B, range(N));
buffer bufC (C, range(N));
queue myQueue;
myQueue.submit([&](handler& cgh) {
auto A = bufA.get_access(cgh, read_only);
auto B = bufB.get_access(cgh, read_only);
auto C = bufC.get_access(cgh);
cgh.parallel_for<class vector_add>(N, [=](auto i) {
C[i] = A[i] + B[i];});
});
}
for (int i = 0; i < 5; i++){
cout << "C[" << i << "] = " << C[i] <<std::endl;
}
return 0;
}
Accelerator
device code
Anatomy of a DPC++ Application
21
Host code
Host code](https://image.slidesharecdn.com/oneapidpcvirtualworkshop-9thdec20-201210090944/85/OneAPI-dpc-Virtual-Workshop-9th-Dec-20-21-320.jpg)
![Intel Confidential 22
int main() {
float A[N], B[N], C[N];
{ buffer bufA (A, range(N));
buffer bufB (B, range(N));
buffer bufC (C, range(N));
queue myQueue;
myQueue.submit([&](handler& cgh) {
auto A = bufA.get_access(cgh, read_only);
auto B = bufB.get_access(cgh, read_only);
auto C = bufC.get_access(cgh);
cgh.parallel_for<class vector_add>(N, [=](auto i) {
C[i] = A[i] + B[i];});
});
}
for (int i = 0; i < 5; i++){
cout << "C[" << i << "] = " << C[i] <<std::endl;
}
return 0;
}
22
DPC++ basics
Write-buffer is now out-of-scope, so
kernel completes, and host pointer
has consistent view of output.](https://image.slidesharecdn.com/oneapidpcvirtualworkshop-9thdec20-201210090944/85/OneAPI-dpc-Virtual-Workshop-9th-Dec-20-22-320.jpg)
![Intel Confidential 23
int main() {
float A[N], B[N], C[N];
{ buffer bufA (A, range(N));
buffer bufB (B, range(N));
buffer bufC (C, range(N));
queue myQueue;
myQueue.submit([&](handler& cgh) {
auto A = bufA.get_access(cgh, read_only);
auto B = bufB.get_access(cgh, read_only);
auto C = bufC.get_access(cgh);
cgh.parallel_for<class vector_add>(N, [=](auto i) {
C[i] = A[i] + B[i];});
});
}
for (int i = 0; i < 5; i++){
cout << "C[" << i << "] = " << C[i] <<std::endl;
}
return 0;
}
23
DPC++ basics](https://image.slidesharecdn.com/oneapidpcvirtualworkshop-9thdec20-201210090944/85/OneAPI-dpc-Virtual-Workshop-9th-Dec-20-23-320.jpg)






















{
// CODE THAT RUNS ON DEVICE
})
h.parallel_for(range<2>(1920,1080), [=](id<2>
item){
// CODE THAT RUNS ON DEVICE
});
nd_range & nd_item
global
size
local size
(work-group
size)](https://image.slidesharecdn.com/oneapidpcvirtualworkshop-9thdec20-201210090944/85/OneAPI-dpc-Virtual-Workshop-9th-Dec-20-46-320.jpg)


OneAPI dpc++ Virtual Workshop 9th Dec-20
- 1. oneAPI DPC++ Workshop 9th December 2020
- 2. Intel Confidential 2 Agenda • Intel® oneAPI • Introduction • DPC++ • Introduction • DPC++ “Hello world” • Lab • Intel® DPC++ Compatibility Tool • Introduction • Demo Optimization Notice 2
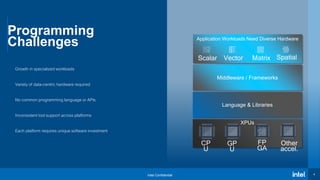
- 4. Intel Confidential 4 XPUs Programming Challenges Growth in specialized workloads Variety of data-centric hardware required No common programming language or APIs Inconsistent tool support across platforms Each platform requires unique software investment Middleware / Frameworks Application Workloads Need Diverse Hardware Language & Libraries Scalar Vector Matrix Spatial 4 CP U GP U FP GA Other accel.
- 5. Intel Confidential 5 5 introducing oneapi Unified programming model to simplify development across diverse architectures Unified and simplified language and libraries for expressing parallelism Uncompromised native high-level language performance Based on industry standards and open specifications Interoperable with existing HPC programming models Industry Intel Initiative Product Middleware / Frameworks Application Workloads Need Diverse Hardware Scalar Vector Matrix Spatial XPUs CP U GP U FP GA Other accel. oneAPI
- 6. Data Parallel C++ Subarnarekha Ghosal
- 8. Intel Confidential 8 Intel® oneAPI DPC++ Overview DPC++ SYCL Next (Intel Extensions) Latest Available SYCL Spec C++ 17
- 9. Intel Confidential 9 Intel® oneAPI DPC++ Overview 1. • Data Parallel C++ is a high-level language designed to target heterogenous architecture and take advantage of data parallelism. 2. • Reuse Code across CPU and accelerators while performing custom tuning. 3. • Open-source implementation in Github helps to incorporate ideas from end users. 9
- 10. Intel Confidential 10 Before we start Lambda Expressions #include <algorithm> #include <cmath> void abssort(float* x, unsigned n) { std::sort(x, x + n, // Lambda expression [ ](float a, float b) { return (std::abs(a) < std::abs(b)); } ); } • A convenient way of defining an anonymous function object right at the location where it is invoked or passed as an argument to a function • Lambda functions can be used to define kernels in SYCL • The kernel lambda MUST use copy for all its captures (i.e., [=]) Capture clause Parameter list Lambda body 10
- 11. Intel Confidential 11 COMMAND GROUP HANDLER DEVICE (S) Query for the Available device Kernel Model: Send a kernel (lambda) for execution. Queue executes the commands on the device parallel_for will execute in parallel across the compute elements of the device BUF A BUF B BUF C ACC B ACC C Read Read Write ACC A Command groups control execution on the device Dispatches Kernels to the device Buffers and Accessors manage memory across Host and Device QUEUE HOST DPC++ Program Flow
- 12. Intel Confidential 12 DPC++ “Hello world”
- 13. Intel Confidential 13 13 Step 1 #include <CL/sycl.hpp> using namespace cl::sycl;
- 14. Intel Confidential 14 Step 2 buffer bufA (A, range(SIZE) ); buffer bufB (B, range (SIZE) ); buffer bufC (C, range (SIZE) ); 14
- 15. Intel Confidential 15 Step 3 gpu_selector deviceSelector; queue myQueue(deviceSelector); 15 • The device selector can be a default selector or a cpu or gpu selector or intel::fpga_selector. • If the device is not explicitly mentioned during the creation of command queue, the runtime selects one for you. • It is a good practice to specify the selector to make sure the right device is chosen.
- 16. Intel Confidential 16 Step 4 myQueue.submit([&](handler& cgh) { 16
- 17. Intel Confidential 17 Step 5 auto A = bufA.get_access(cgh, read_only); auto B = bufB.get_access(cgh, read_only); auto C = bufC.get_access(cgh); 17
- 18. Intel Confidential 18 Step 6 cgh.parallel_for<class vector_add>(N, [=](auto i) { C[i] = A[i] + B[i];}); 18 Each iteration (work- item) will have a separate index id (i)
- 19. Intel Confidential 19 int main() { float A[N], B[N], C[N]; { buffer bufA (A, range(N)); buffer bufB (B, range(N)); buffer bufC (C, range(N)); queue myQueue; myQueue.submit([&](handler& cgh) { auto A = bufA.get_access(cgh, read_only); auto B = bufB.get_access(cgh, read_only); auto C = bufC.get_access(cgh); cgh.parallel_for<class vector_add>(N, [=](auto i){ C[i] = A[i] + B[i];}); }); } for (int i = 0; i < 5; i++){ cout << "C[" << i << "] = " << C[i] <<std::endl; } return 0; } DPC++ “Hello World”: Vector Addition Entire Code 19
- 20. Intel Confidential 20 int main() { float A[N], B[N], C[N]; { buffer bufA (A, range(N)); buffer bufB (B, range(N)); buffer bufC (C, range(N)); queue myQueue; myQueue.submit([&](handler& cgh) { auto A = bufA.get_access(cgh, read_only); auto B = bufB.get_access(cgh, read_only); auto C = bufC.get_access(cgh); cgh.parallel_for<class vector_add>(N, [=](auto i) { C[i] = A[i] + B[i];}); }); } for (int i = 0; i < 5; i++){ cout << "C[" << i << "] = " << C[i] <<std::endl;} return 0; } Host code Anatomy of a DPC++ Application 20 Host code
- 21. Intel Confidential 21 int main() { float A[N], B[N], C[N]; { buffer bufA (A, range(N)); buffer bufB (B, range(N)); buffer bufC (C, range(N)); queue myQueue; myQueue.submit([&](handler& cgh) { auto A = bufA.get_access(cgh, read_only); auto B = bufB.get_access(cgh, read_only); auto C = bufC.get_access(cgh); cgh.parallel_for<class vector_add>(N, [=](auto i) { C[i] = A[i] + B[i];}); }); } for (int i = 0; i < 5; i++){ cout << "C[" << i << "] = " << C[i] <<std::endl; } return 0; } Accelerator device code Anatomy of a DPC++ Application 21 Host code Host code
- 22. Intel Confidential 22 int main() { float A[N], B[N], C[N]; { buffer bufA (A, range(N)); buffer bufB (B, range(N)); buffer bufC (C, range(N)); queue myQueue; myQueue.submit([&](handler& cgh) { auto A = bufA.get_access(cgh, read_only); auto B = bufB.get_access(cgh, read_only); auto C = bufC.get_access(cgh); cgh.parallel_for<class vector_add>(N, [=](auto i) { C[i] = A[i] + B[i];}); }); } for (int i = 0; i < 5; i++){ cout << "C[" << i << "] = " << C[i] <<std::endl; } return 0; } 22 DPC++ basics Write-buffer is now out-of-scope, so kernel completes, and host pointer has consistent view of output.
- 23. Intel Confidential 23 int main() { float A[N], B[N], C[N]; { buffer bufA (A, range(N)); buffer bufB (B, range(N)); buffer bufC (C, range(N)); queue myQueue; myQueue.submit([&](handler& cgh) { auto A = bufA.get_access(cgh, read_only); auto B = bufB.get_access(cgh, read_only); auto C = bufC.get_access(cgh); cgh.parallel_for<class vector_add>(N, [=](auto i) { C[i] = A[i] + B[i];}); }); } for (int i = 0; i < 5; i++){ cout << "C[" << i << "] = " << C[i] <<std::endl; } return 0; } 23 DPC++ basics
- 24. Intel Confidential 24 DPCPP Demo session
- 25. Intel Confidential 25 Intel® oneAPI DPC++ Heterogenous Platform CPU (Host) GPU (Device) FPGA (Device) Other Accelerator (Device) CPU (Device) 25
- 26. 26Intel Confidential For code samples on all these concepts Visit: https://github.com/oneapi-src/oneAPI-samples/
- 27. Intel Confidential 27 DPC++ Summary •DPC++ is an open standard based programming model for Heterogenous Platforms. •It can target different accelerators from different vendors •Single sourced programming model •oneAPI specifications available publicly: https://github.com/intel/llvm/tree/sycl/sycl/doc/extensions Feedback and active participation encouraged
- 28. Intel® DPC++ Compatibility Tool
- 29. Intel Confidential 29 Migrates some portion of their existing code written in CUDA to the newly developed DPC++ language. Our experience has shown that this can vary greatly, but on average, about 80-90% of CUDA code in applications can be migrated by this tool. Completion of the code and verification of the final code is expected to be manual process done by the developer. https://software.intel.com/content/www/us/en/develop/documentation/get-started-with-intel-dpcpp- compatibility-tool/top.html What is the Intel® DPC++ Compatibility Tool?
- 30. Intel Confidential 30 DPCT* Demo session
- 32. Intel Confidential 32 DPC++ Deep Dive
- 33. Intel Confidential 33 Intel® oneAPI DPC++ Heterogenous Platform CPU (Host) GPU (Device) FPGA (Device) Other Accelerator (Device) CPU (Device) 33
- 34. Intel Confidential 34 Execution Flow Global/Constant Memory Host Memory Host Device (CPU) (GPU, MIC, FPGA, …) Compute Unit (CU) LocalMemoryLocalMemoryLocalMemoryLocalMemory Command Group • Synchronization cmd • Data movement ops • User-defined kernels Command GroupCommand GroupCommand Group Command Queue Executed on… submits... Command QueueCommand Queue Host code Executed on… DPC++ Application Device code Private Memory 34
- 35. Intel Confidential 35 Execution Flow Contd. Execution of Kernel Instances Device (GPU, FPGA, …) Compute Unit (CU) Kernel instance = Kernel object & nd_range & work-group decomposition Work-pool Command QueueCommand QueueCommand Queue enqueued… 35
- 36. Intel Confidential 36 Memory Model
- 37. Intel Confidential 37 Hardware Architecture
- 38. Intel Confidential 38 Global memory: Accessible to all work-items in all work- groups. Reads and writes may be cached. Persistent across kernel invocations Memory Model Constant memory: • A region of global memory that remains constant during the execution of a kernel Local Memory: • Memory region shared between work-items in a single work-group. Private Memory: • Region of memory private to a work-item. Variables defined in one work-item’s private memory are not visible to another work-item Global/Constant Memory Device (GPU, FPGA, …) Compute Unit (CU) LocalMemoryLocalMemoryLocalMemoryLocalMemory Private Memory 38
- 39. Intel Confidential 39 DPC++ - device memory model Local Memory Private Memory Work-Item Private Memory Work-Item Private Memory Work-Item Work-Group Global Memory Constant Memory Device Work-Group …… Work-GroupWork-Group … … Local Memory Private Memory Work-Item Private Memory Work-Item Private Memory Work-Item… Work-Group … Device
- 40. Intel Confidential 40 Unified Shared Memory SYCL 1.2.1 specification offers: – Buffer/Accessor: For tracking and managing memory transfer and guarantee data consistency across host and DPC++ devices. Many HPC and Enterprise applications use pointers to manage data. DPC++ Extension for Pointer Based programming: – Unified Shared Memory (USM): Device Kernels can access the data using pointers
- 41. Intel Confidential 41 USM Allocation Device(Explicit data movement) Host(Data sent over bus, such as PCIe) Shared(Data can migrate b/w host and memory) Types of USM
- 42. Intel Confidential 42 Kernel Model
- 43. Intel Confidential 43 Kernel Execution Model Kernel Parallelism Multi Dimensional Kernel ND-Range Sub-group Work-Group Work Item
- 44. Intel Confidential 44 Kernel Execution Model Explicit ND-range for control- similar to programming models such as OpenCL, SYCL, CUDA. ND-range Global work size Work-group Work-item 44
- 45. Intel Confidential 45 nd_range & nd_item Example: Process every pixel in a 1920x1080 image Each pixel needs processing, kernel is executed on each pixel (work-item) 1920 x 1080 = 2M pixels = global size Not all 2M can run in parallel on device, there is hardware resource limits. We have to split into smaller groups of pixel blocks = local size (work-group) Either let the complier determine work-group size OR we can specify the work-group size using nd_range()
- 46. Intel Confidential 46 Example: Process every pixel in a 1920x1080 image Let compiler determine work-group size Programmer specifies work-group size h.parallel_for(nd_range<2>(range<2>(1920,1080),range<2>(8,8)), [=](id<2> item){ // CODE THAT RUNS ON DEVICE }) h.parallel_for(range<2>(1920,1080), [=](id<2> item){ // CODE THAT RUNS ON DEVICE }); nd_range & nd_item global size local size (work-group size)
- 47. Intel Confidential 47 nd_range & nd_item Example: Process every pixel in a 1920x1080 image How do we choose work-group size? • Work-group size of 8x8 divides equally for 1920x1080 • Work-group size of 9x9 does not divide equally for 1920x1080 • Compiler will throw error (invalid work group size error) • Work-group size of 10x10 divides equally for 1920x1080 • Works, but always better to use multiple of 8 for better resource utilization • Work-group size of 24x24 divides equally for 1920x1080 • 24x24=576, will fail compile assuming GPU max work-group size is 256 GOOD
- 48. 48