OpenLSH - a framework for locality sensitive hashing
2 likes2,307 views

The document discusses limitations of the k-means clustering algorithm and proposes alternatives like locality-sensitive hashing (LSH) for clustering large document collections. LSH hashes documents into "buckets" based on similarity so that similar documents are hashed to the same buckets, allowing efficient retrieval of nearest neighbors. The document demonstrates LSH using minhashing, which represents documents as sets of "shingles" or fragments, and hashes the minimum value found. It also describes an open-source implementation of LSH called OpenLSH that works with large-scale databases like Cassandra.






![Another line of inquiry: Nearest Neighbor
• Based on partitioning the search space
– Quad Trees
– kd-Trees
7
© DataThinks 2013-15
7
– Locality-Sensitive Hashing
• Hash functions are locality-sensitive, if, for a
random hash function h, for any pair of points p,q :
– Pr[h(p)=h(q)] is “high” if p is “close” to q
– Pr[h(p)=h(q)] is “low” if p is “far” from q](https://image.slidesharecdn.com/openlsh-aframeworkforlocalitysensitivehashing-150316183035-conversion-gate01/85/OpenLSH-a-framework-for-locality-sensitive-hashing-7-320.jpg)
![More on Nearest Neighbor…
• Locality-Sensitive Hashing†
– Hash functions are locality-sensitive, if, for a random hash
random function h, for any pair of points p,q we have:
• Pr[h(p)=h(q)] is “high” if p is “close” to q
• Pr[h(p)=h(q)] is “low” if p is”far” from q
8
© DataThinks 2013-15
8
†Indyk-Motwani’98](https://image.slidesharecdn.com/openlsh-aframeworkforlocalitysensitivehashing-150316183035-conversion-gate01/85/OpenLSH-a-framework-for-locality-sensitive-hashing-8-320.jpg)












































Ad
More Related Content
What's hot (20)
Similar to OpenLSH - a framework for locality sensitive hashing (20)


















Ad
More from J Singh (16)
















Ad
Recently uploaded (20)




















OpenLSH - a framework for locality sensitive hashing
- 1. Going Beyond k-meansGoing Beyond k-means Developments in the ≈60 years since its publication J Singh and Teresa Brooks March 17, 2015
- 2. Hello Bulgaria • A website with thousands of pages... – Some pages identical to other pages – Some pages nearly identical to other pages • We want smart indexing of the collection 2 © DataThinks 2013-15 2 • We want smart indexing of the collection – Save just one copy of the duplicate pages – Save one copy of the nearly duplicate pages – Filter out similar documents when returning search results • And we want to keep the index up to date – Detect content changes quickly, possibly without reading old copies from a slow storage
- 3. The Naïve Way to Address this Challenge • Represent each document as a dot in d-dimensional space • Run a k-means algorithm on the document set – Resulting in k clusters • When presented with a new document 3 © DataThinks 2013-15 3 • When presented with a new document – Find the “nearest cluster” – Find the documents within the nearest cluster that are nearest to the document in question • Can be skipped if the cluster is small enough • i.e., k is large enough that everything in the cluster is close!
- 4. The Naïve Way has conceptual problems • No good way to decide optimal k • All documents have to be re-clustered if we want to change k • A document may “belong” to multiple clusters • All clusters are roughly the same size 4 © DataThinks 2013-15 4 • All clusters are roughly the same size – In practice, this terrain is lumpy – some documents are one-of-a-kind and others are similar to many others.
- 5. The Naïve Way has technical problems • End result is subject to initial choice of centroids – Leads to results not being repeatable • Performance is O(nk), or worse! – Especially unfortunate because we want k to be large • Algorithm is not easily adapted to map/reduce 5 © DataThinks 2013-15 5 • Algorithm is not easily adapted to map/reduce – We need a pipeline of map/reduce jobs to compute it
- 6. Any Evolutionary Alternatives? • Clustering has been picked over quite well due to its combination of interesting math and wide applicability • Two dominant types have emerged: – Hierarchical clustering 6 © DataThinks 2013-15 6 – Hierarchical clustering – Partitional clustering (e.g., k-means) • k-Means Variations based on – Choice of Initial Centroids – Choice of k – Parameters at each iteration
- 7. Another line of inquiry: Nearest Neighbor • Based on partitioning the search space – Quad Trees – kd-Trees 7 © DataThinks 2013-15 7 – Locality-Sensitive Hashing • Hash functions are locality-sensitive, if, for a random hash function h, for any pair of points p,q : – Pr[h(p)=h(q)] is “high” if p is “close” to q – Pr[h(p)=h(q)] is “low” if p is “far” from q
- 8. More on Nearest Neighbor… • Locality-Sensitive Hashing† – Hash functions are locality-sensitive, if, for a random hash random function h, for any pair of points p,q we have: • Pr[h(p)=h(q)] is “high” if p is “close” to q • Pr[h(p)=h(q)] is “low” if p is”far” from q 8 © DataThinks 2013-15 8 †Indyk-Motwani’98
- 9. The LSH Idea • Treat items as vectors in d- dimensional space. • Draw k random hyper-planes in that space. • For each hyper-plane: 4 5 9 © DataThinks 2013-15 9 – Is each vector on the (0) side of the hyperplane or the (1) side? • Hash(Item1) = 000 • Hash(Item3) = 101 • Hashes each item into a number • The magic is in choosing h1, h2, … 2 13 6 7 h3 h1 h2
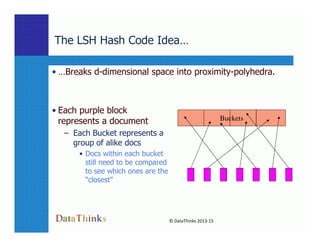
- 10. The LSH Hash Code Idea… • …Breaks d-dimensional space into proximity-polyhedra. • Each purple block represents a document Buckets 10 © DataThinks 2013-15 represents a document – Each Bucket represents a group of alike docs • Docs within each bucket still need to be compared to see which ones are the “closest”
- 11. A Brief History of LSH • Origins at Stanford (1998) • Continuing research in universities – Stanford, MIT, Rutgers, Cornell, … • Continuing research in Industry – Intel, Microsoft, Google, … 11 © DataThinks 2013-15 11 – Intel, Microsoft, Google, … • Textbook: – A. Rajaraman and J. Ullman (2010). (http://goo.gl/8AJDgI) • Our contribution: – An extensible implementation for large datasets
- 12. Choosing hash functions • Introducing minhash 1. Sample each document to get its “shingles” – small fragments • “Mary had a “ “mary”, “ary “, “ry h”, “y ha”, “ had”, … • “CTAGTATAAA” “CTAGTATA”, “TAGTATAA”, “AGTATAAA”, • “now is the time” “now is”, “is the”, “the time” 12 © DataThinks 2013-15 12 • “now is the time” “now is”, “is the”, “the time” 2. Calculate the hash value for every shingle. 3. Store the minimum hash value found in step 2. 4. Repeat steps 2 and 3 with different hash algorithms 199 more times to get a total of 200 minhash values.
- 13. Interesting thing about minhashes • The resulting minhashes are 200 integer values representing a random selection of shingles. – Property of minhashes: If the minhashes for two docs are the same, their shingles are likely to be the same – If the shingles for two docs are the same, the docs themselves are likely to be the same 13 © DataThinks 2013-15 13 themselves are likely to be the same • Beware… – Minhash is specific to a particular similarity measure – Jaccard similarity – Other hash families exist for other similarity measures
- 14. All 200 minhashes must match? • If all minhashes match, it implies a strong similarity between docs. • To catch most cases with weaker similarity – Don’t compare all minhashes at once, compare them in bands. Candidate pairs are those that hash to the same bucket for ≥ 1 band. 14 © DataThinks 2013-15 14 bucket for ≥ 1 band. – Sometimes one band will reject a pair and another band will consider it a candidate.
- 15. LSH Involves a Tradeoff • Pick the number of minhashes, the number of bands, and the number of rows per band to balance false positives/negatives. – False positives ⇒ need to examine more pairs that are not really similar. More processing resources, more time. – False negatives ⇒ failed to examine pairs that were similar, 15 © DataThinks 2013-15 15 – False negatives ⇒ failed to examine pairs that were similar, didn’t find all similar results. But got done faster!
- 16. Summary • Mine the data and place members into hash buckets • When you need to find a match, hash it and possible nearest neighbors will be in one of b buckets. 16 © DataThinks 2013-15 16 one of b buckets. • Algorithm performance O(n)
- 17. Going Beyond k-meansGoing Beyond k-means Demo J Singh and Teresa Brooks March 17, 2015
- 18. Peerbelt Results Example ##### ##### ##### ##### ##### ##### ##### ##### ##### ##### ##### ##### ##### ##### ##### ##### ##### ##### ##### ##### ##### ##### ##### ##### ##### ##### ##### ##### ##### ##### ##### ##### ##### ##### ##### ##### ##### ##### ##### ##### ##### ##### ##### ##### ##### ##### ##### ##### ##### ##### ##### ##### ##### ##### ##### ##### ##### MUhNgZKlQ5qWKlSzlQ4auA _UOkeHgLQn2HaLM5AdJBcw fjw99kNgSBSNLXDjBijKIQ 6sp57Uq1TjCCb6ozoHlcEw P2WtoTI0ROiwMu-KqcFmrg f6aRJpmmQZWshgUJY6ddiA o_CEANscQM-IC2VX-kk6Ag mzfgajvrRNyJGYcr0d7i5g Knvo0RsrRWeE-75QfeYRAQ cllezWovQay6ZA1Ubxqbzw oLXkAmQ5RIOM4svywmynbQ TTWu2oleRcuHcNKqQqL_9Q 2is32hFhRACt-qAAg15eSQ KnOpBza6TQO2lNHo45i08A PebEFSHLQmGxI4aMAP-Pmw T8TFg700R-WCACYPceCRfg 18 © DataThinks 2013-15 18 T8TFg700R-WCACYPceCRfg BnM7ETiXQAywiFYEenzGfw q6DSgUlOTVuro67PY2zpOQ YZP6Tk7ZTBKPZnLTSctZEQ yoTVRL8jSDyJHtS-Vcgkgw xhA8UNjOTBuDt-VRnMTTnw BQNIVz_5TxSlXZMJYV9lhA S6FG_NUaQU-UyIoez_k2zg _KJHmfuzQtKiCGHVT45JPg AEWdkJ3QTAiaFRwOsbTcsA MsVBW3oKT6yZNP9J8-2jKw c7bRvt-dQse7n4tmFkuQCQ K4DcDglWS3OdUXTGqTX1LA lWgrETQwQsmmTDitHstIiQ eAOq-w3pRJq1T0mdEeYBJA OfTond3JRjCmaNaHJc5pcw Wv4BFePCR0SSvotcfTbI-A 62p0zfd2SZOhH0niF90QcA AxNLgwmBS1uK-QivL3bKWw BcYtpGdbTtazQCp7ez7nCw UpOP24JMSJuP58TAHkvc4w K7fSX7v0Qcy4PAbGl7ZFFw Zwc1YB8SSeSrcALscMfDNQ mpmoIZY6S4Si89wdEyX9IA 3YhvLB30QJiFQXBA1vIqsA =-xm8tkdTRN6i18BkP-EF4Q YQ9K2Ka2TGic_7FZFb7pJg
- 19. Database Architecture Requirements • Need a very large range of bucket numbers – Bucket Numbers in our implementation are -231 to +231-1 • Most buckets are empty – Empty buckets must not take any space in the database 19 © DataThinks 2013-15 19 – Empty buckets must not take any space in the database – Some buckets have a lot of documents in them, we need to be able to locate all of them • To find documents similar to a given document, – Bucketize the document, then find other documents in the same buckets
- 20. Implementation: OpenLSH • We started OpenLSH to provide a framework for LSH • Factor out the database – Started on Google App Engine – Virtualized interface to make it work on Cassandra 20 © DataThinks 2013-15 20 – Virtualized interface to make it work on Cassandra • Factor out the calculation engine – Started on Google App Engine – Can plug in Google MapReduce – Ported to run in Batch mode on Cassandra
- 21. Using OpenLSH • We’re looking for one or two interesting use cases – Application areas: • Near de-duplicaction (covered with Peerbelt’s data) • Stocks that move independent of the herd • Filtering “unique stories” from the News 21 © DataThinks 2013-15 21 • Contact us to discuss
- 22. What you can do • For more information: http://openlsh.datathinks.org/ – Links to code and data set are included • Run on App Engine – Minimum setup required 22 © DataThinks 2013-15 22 – Minimum setup required • Adapt it to your environment and need • If you need help, send email or create a Github issue. • Send us a pull request for any improvements you make.
- 23. Thank you • J Singh – Principal, DataThinks • Algorithms for big data • @datathinks, @singh_j • j . singh @ datathinks . org 23 © DataThinks 2013-15 23 • j . singh @ datathinks . org – Adj. Prof, Computer Science, WPI • Teresa Brooks – Senior Software Engineer @ Xero • [email protected] • @VaderGirl13