Open stack ha design & deployment kilo
Download as PPTX, PDF17 likes4,404 views

A study and practice of OpenStack release Kilo HA deployment. The Kilo document has some errors, and it's hardly find a detailed document to describe how to deploy a HA cloud based on Kilo release. Hope this slides can provide some clues.























































![[OpenStack Days Korea 2016] Track1 - Monasca를 이용한 Cloud 모니터링](https://cdn.slidesharecdn.com/ss_thumbnails/11hpe-160226171123-thumbnail.jpg?width=560&fit=bounds)





![[OpenStack Days Korea 2016] Track1 - 카카오는 오픈스택 기반으로 어떻게 5000VM을 운영하고 있을까?](https://cdn.slidesharecdn.com/ss_thumbnails/16kakao-160226171853-thumbnail.jpg?width=560&fit=bounds)






![[오픈소스컨설팅] 쿠버네티스와 쿠버네티스 on 오픈스택 비교 및 구축 방법](https://cdn.slidesharecdn.com/ss_thumbnails/osck8svsk8sonopenstackkhoj-210310051504-thumbnail.jpg?width=560&fit=bounds)



![[OpenStack Days Korea 2016] Track3 - 오픈스택 환경에서 공유 파일 시스템 구현하기: 마닐라(Manila) 프로젝트](https://cdn.slidesharecdn.com/ss_thumbnails/31netapp-160226172856-thumbnail.jpg?width=560&fit=bounds)







Ad
More Related Content
What's hot (20)
Viewers also liked (20)


















Ad
Similar to Open stack ha design & deployment kilo (20)




















Ad
Recently uploaded (19)



















Open stack ha design & deployment kilo
- 1. - OpenStack Control Services High Availability OpenStack HA Design & Deployment - Kilo [email protected] Oct. 2015
- 2. Four types of HA in an OpenStack Cloud Compute Controller Network Controller Database Message Queue Storage .... Physical nodes Physical network Physical storage Hypervisor Host OS …. Service Resiliency QoS Cost Transparency Data Integrity ….. Virtual Machine Virtual Network Virtual Storage VM Mobility …Physical infrastructure OpenStack Control services VMs OpenStack Compute Applications
- 4. • Redundant in locations – Minimize downtime due to power or network issue • All components distributed on different labs • Controller, Network, Compute, Storage • Minimize downtime • Minimize data loss risk • Eliminate single point of failure • Extendability Physical Infrastructure
- 5. Physical Infrastructure - example Zone1 Zone 2 APIs/Orchestration/Dashboard… Compute Compute Database for control plane (MySQL) Message Queue Network Storage Storage
- 6. OpenStack Control Services High Availability Technology
- 8. Stateless / Stateful Services State Description Services Stateless • There is no dependency between requests • No need for data replication/synchronization. Failed request may need to be restarted on a different node. Nova-api, nova- conductor, glance-api, keystone-api, neutron- api, nova-scheduler, Apache web server, Cinder Scheduler, etc. Stateful • An action typically comprises multiple requests • Data needs to be replicated and synchronized between redundant services (to preserve state and consistency) MySQL, RabbitMQ, Cinder Volume, Ceilometer center agent, Neutron L3, DHCP agents, etc.
- 9. • Active/Passive • There is a single master • Load balance stateless services using a VIP and a load balancer such as HAProxy • For Stateful services a replacement resource can be brought online. A separate application monitors these services, bringing the backup online as necessary • After a failover the system will encounter a “speed bump” since the passive node has to notice the fault in the active node and become active • Active/Active • Multiple masters • Load balance stateless services using a VIP and a load balancer such as HAProxy • Stateful Services are managed in such a way that services are redundant, and that all instances have an identical state • Updates to one instance of database would propagate to all other instances • After a failover the system will function in a “degraded” state Active/Passive or Active/Active
- 10. Do not reinvent the wheel • Leverage time-tested Linux utilities such as Keepalived, HAProxy and Virtual IP (using VRRP) • Leverage Hardware Load Balancers • Leverage replication services for RabbitMQ/MySQL such as RabbitMQ Clustering, MySQL master-master replication, Corosync, Pacemaker, DRBD, Galera and so on Overall Philosophy
- 11. • Keepalived • Based on Linux Virtual Server (IPVS) kernel module providing layer 4 Load Balancing • Implements a set of checkers to maintain health and Load Balancing • HA is implemented using VRRP Protocol, Used to load balance API services • VRRP (Virtual Router Redundancy Protocol) • Eliminates SPOF in a static default routed environment • HAProxy • Load Balancing and Proxying for HTTP and TCP Applications • Works over multiple connections • Used to load balance API services Keepalived, VRRP, HAProxy – for APIs (Active/Active – 2 nodes)
- 12. • Corosync • Totem single-ring ordering and membership protocol • UDP and InfiniBand based messaging, quorum, and cluster membership to Pacemaker • Pacemaker • High availability and load balancing stack for the Linux platform. • Interacts with applications through Resource Agents (RA) • DRDB (Distributed Replication Block Device) • Synchronizes Data at the block device • Uses a journaling system (such as ext3 or ext4) Corosync, Pacemaker and DRDB - for APIs and MySQL (Active/Passive)
- 13. • MySQL patched for wsrep (Write Set REPlication) • Active/active multi-master topology • Read and write to any cluster node • True parallel replication, in row level • No slave lag or integrity issues MySQL Galera (Active/Active) Synchronous Multi-master Cluster technology for MySQL/InnoDB
- 14. RabbitMQ HA – native
- 15. • Cinder (Block Storage) backends support • LVM Driver • Default linux iSCSI server • Vendor software plugins • Gluster, CEPH, VMware VMDK driver • Vendor storage plugins • EMC VNX, IBM Storwize, Solid Fire, etc. • Local RAID support • Swift (Object Storage) -- Done • Replication • Erasure coding: (not enabled) Data Redundancy (storage HA)
- 16. • No need to HA support for L2 networking, which is located in compute node • Problems • Routing on Linux server (max. bandwith approximately 3-4 Gbits) • Limited distribution between more network nodes • East-West and North-South communication through network node • High Availability • Pacemaker&Corosync • Keepalived VRRP • DVR + VRRP – should be in Juno release Networking – Vanilla Neutron L3 agent Reference: • Neutron/DVR • L3 High Availability • Configuring DVR in OpenStack Juno
- 17. HA methods in different vendors Vendor Cluster/Replication Technique Characteristics RackSpac e Keepalived, HAProxy, VRRP, DRBD, native clustering Automatic - Chef for 2 controller nodes installation Red Hat Pacemaker, Corosync, Galera Manual installation/Foreman Cisco Keepalived, HAProxy, Galera Manual installation, at least 3 controller tcp cloud Pacemaker, Corosync, HAProxy,Galera, Contrail Automatic Salt-Stack deployment Mirantis Pacemaker, Corosync, HAProxy,Galera Automatic - Puppet HP Microsoft Windows based installation with Hyper-V MS SQL server and other Windows based methods Ubuntu Juju-Charms, Corosync, Percona XtraDB, Juju+MAAS
- 18. Comparison Database Replication method Strengths Weakness/Limit ations Keepalived/HAPro xy/VRRP Works on MySQL master-master replication Simple to implement and understand. Works for any storage system. Master-master replication does not work beyond 2 nodes. Pacemaker/Coros ync/DRBD Mirroring on Block Devices Well tested More complex to setup. Split Brain possibility Galera Based on write- set Replication (wsrep) No Slave lag Needs at least 3 nodes. Relatively new. Others MySQL Cluster, RHCS with DAS/SAN storage Well tested More complex setup.
- 19. • HAProxy for load balancing • MySQL Galera – active/active • RabbitMQ cluster Sample OpenStack HA architecture -1
- 20. • HAProxy for load balancing • MySQL Galera – active/active • RabbitMQ cluster • DVR + VRRP for network Sample OpenStack HA architecture - 2 HAProxy VIP HAProxy Keepalived Controller keystone glance cinder horizon rabbitmq nova Controller keystone glance cinder horizon rabbitmq nova MySQL MySQL galera Storage Storage Block Block Object Object Network / Compute Network / Compute DVR + VRRP
- 21. • OpenStack High Availability Guide • Ubuntu OpenStack HA wiki • RackSpace OpenStack Control Plane High Availability • TCP Cloud OpenStack High Availability • Configuring DVR in OpenStack Juno • OpenStack High Availability – Controller Stack by Brian Seltzer Reference
- 22. Design & Build-up - Practice
- 23. Overall Picture VIP 1 PortalHost1 PortalHost2 HAProxy1 HAProxy2 Keepalived JumpBox4 JumpBox3 ExternalNetwork Internal Network VIP2 Controller keystone glance cinder horizon rabbitmq nova MySQL Controller keystone glance cinder horizon rabbitmq nova MySQL Compute Compute Compute Compute Compute Storage JumpBox1 JumpBox2 Network L3 Network L3 Keepalived VIP rabbitmq MySQL To external Network
- 24. • OpenStack Release: Kilo • Host computers • Cisco UCS for Controller, Compute, Network nodes • SuperMicro Computer for Storage nodes • Host OS: Ubuntu 14.04 Server • Network Switches: Cisco Nexus – N7K, N5K, N2K • IP assignment: • All hosts are using Lab internal IP address to save IP addresses resource • For Management/tunnel/storage/… cloud networks • Use Jumpbox to access the all the cloud host computers from outside, 4 Jumpbox are set up for redundancy • HAProxies for internal load balancing and dashboard portal for outside. Equipment and Software
- 25. • Two portal hosts for redundancy and load balance • Same configurations on both • One node hosts 3 VMs for 2 jumpbox and 1 haproxy • Jumpbox to Cloud management • All IP addresses in Cloud are private, reachable via Jumpbox from outside • Applications: VNC, Java, Wireshark, … • Repository mirroring for Linux(Ubuntu 14.04) and OpenStack (Kilo) • Mirror required since internal network can not access Internet directly • Locate on Jumpbox • Dashboard portal (on HAProxies) • VIPs for load-balance • VIP1 for external network access • VIP2 for load balance of all Cloud APIs, Database, MessageQ, … • Important: Two VIPs should be in one VRRP group. Set up Portal Hosts VIP1 PortalHost1 PortalHost2 HAProxy1 HAProxy2 Keepalived JumpBox4 JumpBox3 External Network (Cisco) VIP2 JumpBox1 JumpBox2 Internal Network (Cloud) Step 1
- 26. Portal Hosts Index Example VIP1 PortalHost1 IPMI: 10.10.10.6 Host: 10.10.10.9 PortalHost2 IPMI: 10.10.10.7 Host: 10.10.10.8 HAProxy1 HAProxy2 Keepalived JumpBox4 JumpBox3 External Network (Cisco) VIP2 JumpBox1 JumpBox2 Internal Network (Cloud) 10.10.10.11 10.10.10.12 10.10.10.10 gw 10.10.10.1 192.168.222.240 gw 192.168.222.1 192.168.222.251 192.168.222.252 192.168.222.242 192.168.222.241 192.168.222.243 192.168.222.244 Windows 10.10.10.14 Ubuntu 10.10.10.13 Ubuntu 10.10.10.15 Windows 10.10.10.16 Assume the 10.x.x.x is the company network IPs, 192.168.*.* is for lab internal use
- 27. • HAProxy configuration for VIP1 (external network) • Keepalived configuration • VIP1 and VIP2 should be in one VRRP group • Once there is one interface fail, the whole function will be taken over by another host • HAProxy configuration for VIP2 (internal network) • http://docs.openstack.org/high-availability-guide/content/ha-aa- haproxy.html HAProxy and Keepalived set up Step 1.1
- 28. • 4 jumpbox set up • 2 Windows and 2 Linux • Software installed: • VNC • WireShark • Vmclient • Putty … • Repository Mirror for Ubuntu 14.04 and OpenStack Kilo set up in 2 Linux jumpbox • The internal network will get package from the Jumpbox directly Jumpbox and Repository Mirroring Step 1.2
- 29. • NIS servers set up for the cloud infrastructure, for • Host configuration • Authentication • … • Two NIS servers set up on the HAProxy hosts • Master and slave NIS set up on HAProxy host (option)
- 30. • 3 UCS hosts for Controller, Database, and MessageQ • Located in two racks • Better to have Network / Compute all located in UCS-B hosts • Be sure the Mac Pools are set differently in different FIs, otherwise, there will be Mac Address conflict • Complete all cabling and network configuration on UCSes and upper switches • Verify all network connectivity of IPMI ports • Write down all the configuration in a detailed document Cloud host Step 2 Similar setting when using other compute hosts
- 31. • 2 Portal Hosts • 2 HAProxy, 4 Jumpbox • 2 Portal hosts, for each: • IPMI: VLAN aaa (external network) • Eth0: (7 external IP) – VLAN eee • Eth1: (7 Internal IPs) – VLAN mmm -- VLAN access port. • All Cloud hosts • IPMI vlan/network (lab internal) • accessible via jumpbox from external network • Management vlan/network (lab internal) • Accessible via jumpbox from external network • Tunnel vlan/network (lab internal) – not accessible from external • Storage vlan/network (lab internal) – not external accessible • Other internal network (e.g. internal VLAN network) VLANs / IP design
- 32. • Network configuration for each node • Each host in one network can connect each other • Each host can reach HAProxy and JumpBox via management interface • Each host can reach HAProxy VIP2 via management interface • Hosts set up: controller-vip is used for APIs • Install the Ubuntu Cloud archive keyring and repository • Use the mirror address, instead of the standard one • Update packages for each system, via mirror on jumpbox • Verification 1. NTP: ntpq –c peers 2. Connectivity: can reach HAProxy and Jumpbox 3. Repository setup: /etc/apt/sources.list..d/ … 4. Upgraded the packages Host system preparation Check on each host
- 33. • NTP Source: • Select a stable NTP source from external network as standard time server • The VMs on portal hosts should configure to follow the standard time server listed above • Jumpboxes and HAProxy • All internal hosts in cloud should follow the HAProxy host • Using the VIP2 NTP set up Step 3
- 34. • The MySQL/Maria Galera are deployed in 3 hosts: 2 controllers and another • Make sure InnoDB is configured • Configure HAProxy to listen on galera cluster api, and load balance (Port: 3306) . • Verification • Create table on one node, can be access/manipulate from another • Mysql work well through VIP2, and verify tolerance of single node failure • Access from Jumpbox, work fine. • References: • http://docs.openstack.org/high-availability-guide/content/ha-aa-db-mysql- galera.html • Product webpage: http://www.codership.com/content/using-galera-cluster/。 • Download: http://www.codership.com/downloads/download-mysqlgalera。 • Document: http://www.codership.com/wiki。 • More information about wsrep, see https://launchpad.net/wsrep MySQL/MariaDB Galera Setup Step 4
- 35. • Deploy on 3 nodes, including two controllers • Configure them as a cluster, all nodes are disk nodes • Configure HAProxy for load balance (port: 5672) , to use multiple rabbit_hosts instead. • Verification • rabbitmqadmin tool? • rabbitmqctl status • References: • http://docs.openstack.org/high-availability-guide/content/ha-aa- rabbitmq.html • http://88250.b3log.org/rabbitmq-clustering-ha • OpenStack High Availability: RabbitMQ RabbitMQ Cluster Setup Step 5
- 36. • Services contain: • All OpenStack API services • All OpenStack Schedulers • Memcashed service (multiple instances can be configured, consider later) • API services • User VIP2 when configuring Keystone endpoints • All configuration files should refer to VIP2 • Schedulers: use RabbitMQ as the message system, hosts configured: • http://docs.openstack.org/admin-guide-cloud/content/section_telemetry-cetral- compute-agent-ha.html • Telemetry central agent set up can be load balanced: • See also: http://docs.openstack.org/high-availability-guide/content/ha-aa-controllers.html Control services set up
- 37. • Installation • Add Database into MySQL, and grant privileges (once) • Install Keystone components on each node (one each node) • Configure the keystone.conf • Configure the backend to sql database • Disable caching if needed (need to try) • Configure the HAProxy for the API • Configure the keystone token backend to sql (the default is memcached) • Services/Endpoints/Users/Roles/Projects & Verification • Create admin, demo, service projects and corresponding user/role, … • Create on one node and verify it on another node • Work with VIP2 • See also: • http://docs.openstack.org/high-availability-guide/content/s-keystone.html • http://docs.openstack.org/kilo/config-reference/content/section_keystone.conf.html Identity Service - Keystone Step 6
- 38. • Shared storage is required for Glance HA • In the pilot cloud, the controller local file system is used as image storage, for HA, it will not work • Use the swift as Glance backend. • Swift itself needs to be HA • At least two storage nodes • At least two swift proxy nodes • Installed on controllers with glance • Use keystone for authentication, instead of Swauth Image Service - Glance Step 7 VIP2 … Controller keystone glance MySQL Swift Proxy… Controller keystone glance MySQL Swift Proxy HAProxy1 HAProxy2 Swift
- 39. • Installation • Install two swift proxy • Proxies can be located on the controller nodes; Configure VIP2 for them for load- balance • Install two storage nodes in B-series nodes, two disks for each, total 4 • Configure 3 replicators for HA • No account error fix – upgrade swift-client to 2.3.2. • There is a bug, fixed in 2.3.2 (not in Kilo release) • Verification • File can be put into the storage via one of proxies, and get from another • Object write/get via VIP2 • Failure cases • See also: http://docs.openstack.org/kilo/install- guide/install/apt/content/ch_swift.html • https://bugs.launchpad.net/python-swiftclient/+bug/1372465 Object Storage Installation Step 7.1
- 40. • Install Glance on each controller • Use the file system as the backend first, verify it works with local file system • Configure the HAProxy for Glance API and Glance Registry service • There would be warning about Unknown version in Glance API log • Need to change HAProxy setting about httpchk to fix it • option httpchk Get /versions • See also: • http://docs.openstack.org/juno/config-reference/content/section_glance- api.conf.html • https://bugzilla.redhat.com/show_bug.cgi?id=1245572 • http://docs.openstack.org/high-availability-guide/content/s-glance- api.html Image Service - Glance Step 7.2
- 41. • Prerequisites: • Swift object store had been installed and verified • Glance installed on controllers and verified with local file system as the backend • Integration: • Configure the swift store as the glance backend • Configure the keystone token backend to sql (important) • Or configure multiple memcached hosts in the configuration file • Verification • Upload image and list images successfully in each controller node • See also: • http://behindtheracks.com/2014/05/openstack-high-availability-glance- and-swift/ • http://thornelabs.net/2014/08/03/use-openstack-swift-as-a-backend- store-for-glance.html Integration of Glance and Swift Step 7.3
- 42. • Install Nova related packages • In two controller nodes and in one compute node • Compute nodes need to be set up as “Virturelization Host” • Otherwise, the installation later will fail due to dependency issue. • Configure HAProxy for Nova services • List the Nova services • Verify if RabbitMQ works in the HA environment • There should be redundant Nova APIs, Schedulers, Conductors, … listed • Further verification needs network nodes set up Install Compute Services Step 8
- 43. • DVR + 3 network nodes (distributed SNAT / DHCP redundency) • Multiple options, but no one is perfect • Pacemaker&Corosync • Keepalived VRRP • DVR + VRRP – should be in Juno/Kilo releases • References: • http://docs.openstack.org/networking-guide/scenario_dvr_ovs.html • https://blogs.oracle.com/ronen/entry/diving_into_openstack_network_ar chitecture • http://assafmuller.com/2014/08/16/layer-3-high-availability/ Network Redundancy Step 9
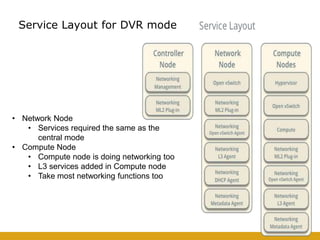
- 44. Service Layout for DVR mode • Network Node • Services required the same as the central mode • Compute Node • Compute node is doing networking too • L3 services added in Compute node • Take most networking functions too
- 45. • Support GRE/VXLAN/VLAN/FLAT network • In our system, GRE is used for tunneling between instances and SNAT • VLAN network is not required if we do not use it. • Network Node is mainly for network central services like DHCP, Metadata, and SNAT • Just north/south traffic with fixed IP need network node forwarding • Compute nodes handle DNAT • East/West traffic and North/South traffic with a floating IP will not go through network node DVR General Architecture
- 46. • This is just for load balance of networking, not HA really • Install all services listed in the service layout picture • On Network node and Compute node respectively • Configuration • router_distrbuted = True • …… • Create routers, networks and instances • Verification • North/south for instances with a fixed IP address (SNAT, via Network node) • North/south for instances with a floating IP address (DNAT, via Compute node only) • East/west for instances using different networks on the same router (via Compute node only) Install one Network and two Compute node Step 9.1
- 47. • Add one more network Node • DHCPD redundancy • Networking L3 Agent redundancy • Networking Metadata Agent • Kilo does not support DVR & L3HA mechanism combination • This is not implemented in our practice, but it should be feasible to implement • The key is to keep all configuration (static/dynamic) sync-up • Two ways to go: • PaceMaker + CoroSync … • VRRP + Keepalived (need to reboot network node when one is down) L3 network redundancy - TBD Step 9.2
- 48. • Cinder Services installation • Install Cinder services in each controller • Configure HAProxy for the API • Storage Nodes set up • SuperMicro equipment as storage • Linux soft-raid for disk redundancy • GlusterFS for node redundancy • Verification • Create and access volume through client on Jumpbox – try both controllers • Do failover cases on disk level • Do failover cases on node level Volume redundancy Step 10 VIP2 … Controller keystone MySQL Cinder … Controller keystone MySQL Cinder HAProxy1 HAProxy2 It’s the same to use any other storage node, e.g. normal computer, we use SuperMicro since it provides >100T storage on one node RaidRaid SuperMicro Storage Node Gluster FS
- 49. • Horizon Services installation • Install Horizon services in each controller • Configure Horizon services • Use the external url name for console setting (instead of controller) • Configure the memcached • /etc/openstack-dashboard/local_settings.py – CACHES LOCATION changes to VIP2 • /etc/memcached.conf change 127.0.0.1 to the controller IP. • Configure HAProxy for the API • Configure the VIP1 to the internal controllers proxy • Make sure the Dashboard is accessible from external network • Verification • From Jumpbox to access the dashboard • From external network to access the dashboard Dashboard redundancy Step 11
- 50. • HEAT Services installation • Install HEAT services in each controller • Configure HEAT services • Configure HAProxy for the HEAT API • Verification Orchestration redundancy Step 12
- 51. • Ceilometer Services installation • Install Ceilometer services in each controller • Configure Ceilometer services • Configure HAProxy for the Ceilometer API • Verification Telemetry redundancy - TBD Step 13