Operating systems and technologies
2 likes3,838 views

The document discusses operating system viewpoints from both a user and high-level perspective. It then provides an overview of computer system components including the motherboard, CPU, memory, and input/output devices. The history of computers is reviewed in four generations from vacuum tubes to integrated circuits. Moore's Law stating that transistor density doubles every couple years is also mentioned.








































































































![Ise iv-computer organization [10 cs46]-notes new](https://cdn.slidesharecdn.com/ss_thumbnails/ise-iv-computerorganization10cs46-notesnew-140624013827-phpapp01-thumbnail.jpg?width=560&fit=bounds)










Ad
More Related Content
What's hot (19)
Viewers also liked (20)

















Ad
Similar to Operating systems and technologies (20)




















Ad
Operating systems and technologies
- 1. Operating Systems and Technologies Introduction Operating System viewpoints: >User View >High Level View (System view) >User View -‐Varies interface being used. If a personal computer -‐Easy to use -‐High performance without regard to the effectiveness of the system is low or not. If the computer connects Internet is called network system -‐Requires sharing of system resources and exchanging information between them. The operating system much is designed system resources such as CPU, I/O devices are used most effective. >High Level View (System view) -‐Resources allocate Computer system has many resources such as CPU time, memory space, file storage space, I/O devices that may required to solve the problem -‐Program controller Control devices – transmit information, manage the execution of user programs to prevent errors and improper use of the computer. Input Computer Output Computer system – overview -‐Motherboard Motherboard is the main circuit board in a computer, provides a way for hardware in a computer to communicate with each other. -‐Interconnect between computer components I/O CPU Memory 1
- 2. -‐CPU Organization The central processing unit (CPU) is the portion of a computer system that carries out the instructions of a computer program, to perform the basic arithmetical, logical, and input/output operations of the system -‐Memory Memory is an organism's ability to store, retain, and recall information and experiences -‐Input/Output Communication between an information processing system (such as a computer), and the outside world, possibly a human, or another information processing system. Inputs are the signals or data received by the system, and outputs are the signals or data sent from it. Computer System Hierarchy Electonic Signal Machine code Assembly Language Operating System High Level Language Application Software User A brief history of computers -‐The first generation – Vacuum Tubes -‐The second generation – Transistors -‐The third generation – Integrated circuit -‐The fourth generation – VLSI The first Generation -‐ Vacuum Tubes (1945 -‐1955) ENIAC (1943 -‐ 1946) • Intended for calculating range tables of aiming artillery • Consisted of 18000 tubes, 1500 relays, weight 30 tons, consumed 140 KW 2
- 3. • Decimal machine • Each digit represented by a ring of 10 vacuum tubes. • Programmed with multi-‐position switches and jumper cables. John von Neumann (1945 -‐1952) more lately … • Originally a member of the ENIAC development team. • First to use binary arithmetic • Architecture consists of: Memory, ALU, Program control, Input, Output • Stored-‐program concept -‐ main memory store both data and instructions The Second Generation -‐ Transistors (1955 -‐1965) Transistors • Transistor was invented in 1948 at Bell Labs • DEC PDP-‐1, first affordable microcomputer ($120k), performance half that of IBM 7090 (the fastest computer in the world at that time, which cost millions) • PDP-‐8, cheap ($16,000), the first to use single bus CDC 6600 (1964) • An order of magnitude faster than the mighty IBM 7094 • First highly parallelized machine (up to 10 instructions in parallel) Burroughs B5000 • First to emphasise software and high level programming languages (Algol 60) The Third Generation -‐ Integrated Circuits (1965 -‐1980) • IBM System/360 • Family of machines with same assembly language • Designed for both scientific and commercial computing • DEC PDP-‐11 • Very popular with universities, maintained DEC's lead in microcomputer market The Fourth Generation -‐ VLSI (1980 -‐ ?) • Lead to PC revolution • High performance, low cost Moore’s Law • Transistor density on a microprocessor will double every 18 to 24 months • Computer will double in power roughly every two years, but cost only half as much Technology Trends Processor – Logic Capacity increases about 30% per year 3
- 4. – Performance increases about 50% per year (2x every 1.5 years) Memory (DRAM) – Capacity increases about 60% per year (4x every 3 years) – Performance increases 3.4% per year Disk – Capacity increases 60% per year – Performance increases 3.4% per year Network Bandwidth – Bandwidth increasing more than 100% per year! The IAS (von Neumann) Machine *Key concepts of von Neumann architecture include -‐Stored program concept -‐Binary representation is the basis for storing data in computer memory -‐Memory is addressed linearly -‐Memory addressed by the location number without regard to the contents -‐Instructions executed in sequence unless an instruction or outside events cause branch Main memory storing programs and data – 1000 storage locations ALU operating on binary data Control unit interpreting instructions from memory and executing Input and output equipment operated by control unit Almost all of today’s computers have the same general structure as the IAS -‐ referred to as von Neumann machines. The structure of IAS computer Arithmetic And Logic Unit Input Main Output Memory Equipment Program Control Unit Some Observations Regarding Computer Architecture • Between 1945 and 1951, von Neumann architecture • Other experimental architectures have been developed and built • von Neumann architecture continues to be the standard architecture for computer 4
- 5. • No other architecture has had any commercial success so far • It is significant that in a field where technological changes happens almost overnight, the architecture of computers is virtually unchanged since 1951 How Does a Computer Work? Hardware needs software • Software is a program that consists of a series of instructions (and data) for performing some designated tasks. • CPU runs a program by executing the instructions one by one. • A program is stored in the main memory when it is executed. Five Classic Components of a Computer *Control gives directions to the other components – Examples: Bus controller, memory management unit *Datapath performs arithmetic and logic operations – Examples: Adders, multipliers, shifters Memory holds data and instructions – Examples: Cache, main memory, disk Input writes data to the computer (memory) – Examples: Keyboard, mouse, joystick Output reads data from the computer – Examples: Monitor, sound card The Little Man Computer (LMC): Physical Layout 5
- 6. • Computer simulator • 100 mailboxes – address 00 -‐ 99 – Each holds 3-‐digit decimal number • Calculator – Enter number – Temporarily hold number – Add and Subtraction – Display 3 digits • Hand counter – Reset button – Instruction counter • Little Man • In/Out Basket The Little Man Computer: Communication with outside World >A user outside the mailroom communicate with the little man by – Putting a 3-‐digit into the in basket – Retrieving a 3-‐digit from the out basket >Apart from the reset button, all communication between the LMC and the outside world takes place using 3-‐digit numbers The Little Man Computer: Operation • A small group of instructions, each consists of a single digit • The first digit of a 3-‐digit number is used to tell the Little Man which operation to perform. • In some cases, the Little Man is required to use a particular mailbox to store or retrieve data • The 3 digits can be used to give instructions to the Little Man according to Operation Code (Op-‐Code) 3 instruction 25 mailbox address Operation Code (Op-‐Code) The Little Man Computer: Instruction Set FORMAT MEANING 000 Stops the Computer -‐ the Little Man rests. 1xx Adds the contents of mailbox xx to the calculator display. 6
- 7. 2xx Subtracts the contents of mailbox xx from the calculator display. 3xx Stores the calculator value into mailbox xx. 4xx Stores the address portion of the calculator value (last 2 digits) into the address portion of the instruction in mailbox xx. 5xx Loads the contents of mailbox xx into the calculator. 6xx This instruction sets the instruction counter to the number xx, thus effectively branching to mailbox xx 7xx IF the calculator value is zero, THEN set the instruction counter to the number xx, thus effectively branching to mailbox xx. 8xx IF the calculator value is positive (or zero), THEN set the instruction counter to the number xx, thus effectively branching to mailbox xx. 901 Read a number from the IN basket and key it into the calculator. 902 Copy the number in the calculator onto a slip of paper and place it into the OUT basket. The Little Man Computer: Execute Program >To run an LMC program we must carry out the following steps: • Load the instructions into the mailboxes, starting with mailbox 00. • Place the data to be used by the program in the IN basket, in the order in which the program will use these data. • Press the RESET BUTTON to set the Instruction Counter to 00 and to also wakeup the Little Man. Then 1. The Little Man looks into the Instruction Counter 2. The Little Man finds the mailbox whose address has the value in the Instruction Counter and fetches the 3-‐digit number from the mailbox. 3. The Little Man goes over to increase the instruction counter by 1 4. The Little Man executes the instruction found in the mailbox 5. The Little Man repeats the by going to 1 The Little Man Computer: Program Example Write a LMC program, which adds two numbers together Mailbox Code Instruction Description 01 901 INPUT 02 399 STORE DATA to mailbox no. 99 03 INPUT ADD the 1st number to 2nd number 7
- 8. 04 902 OUTPUT RESULT 05 000 The Little man rest 99 Data The Little Man Computer (LMC) -‐ Three main aspects 1. Input/Output • These are used so the LMC can communicate with the outside world. 2. Central Processing Unit • Contains the core of the computer: calculator, reset button, instruction counter and the little man. 3. Memory • The mailboxes from 00 -‐ 99 each containing one 3-‐digit number representing instructions or data. Central Processing Unit (CPU) CPU is A hardware device (VLSI chip) that integrates millions of transistors into a silicon chip. • Lies at the heart of a computer, • Executes instructions of a program, • Controls all operations accordingly. CPU Architecture >Arithmetic Logic Unit (ALU) • Arithmetic Logic Unit (ALU): primarily constructed by logic gates (full adders) • It performs – Basic arithmetic calculations: 8
- 9. e.g. adding(+), subtracting(-‐), multiplying(x) and dividing(/). – Logic operations: e.g. OR, AND, NOT, (Left or Right) Shift, etc. • ALU gets control signals from the Control Unit to carry out instructions one by one. >Control Unit • One of the most important parts in a CPU. • Consists of decoding, timing and control logic circuits. • Main functions: – To decode instructions, – To create control signals, which tell the ALU and the Registers how to operate, what to operate on, and what to do with the result. – To make sure everything happens in the right place at the right time, with a clock. >Registers • A mini-‐storage area built with flip-‐flops inside CPU – PC (Program Counter): Holds address of instruction being executed. – IR (Instruction Register): Holds instruction while it's decoded/executed. – ACC (Accumulator): Result of ALU operations – MBR (Memory Buffer Register): Temporarily holds the instruction/data fetched from the memory unit. – MAR (Memory Address Register): holds address. • ALU can retrieve information (instruction or data) quickly. >System BUS Structure System bus consists of 3 functional groups of lines: • Data bus lines • Control bus lines • Address bus lines Data Bus • Bi-‐directional path for transmitting data between the CPU and memory, and peripherals. • Width of data bus: number of bits can be transferred at a time – E.g. 8, 16, 32, or 64 lines, each for one bit binary data, • The width of data bus is one key factors in determining overall system performance. 9
- 10. Address Bus • A ‘road’ for conveying addresses to memory or input/ output devices. • The number of address lines, or width, determines maximum capacity of addresses a CPU can access to, i.e. N lines: 2N addressable memory (and I/O) units, e.g.8 address lines: 28 = 256 addresses from 00000000 to 11111111. Control Bus • Carries signals to control the activities of data/instruction transfers (read or write), or input/output devices. • The number of control bus lines varies, each is designed to perform a specific control task, e.g. RD: Read signal WR: Write signal CLK: system clock signal RESET: reset control signal M68000 CPU chip • 64 connection pins – 16-‐bit Data Bus (32-‐bit internal). – 24-‐bit address bus (for 16 MB). – 21 control pins, e.g. , Halt, etc. – 3 pins for power supply: Vcc, GNDx2. >Instruction execution CPU performs Fetch/Decode/Execute cycle: • Fetch instruction from primary memory • Increment Program Counter • Decode • Execute instruction • Write result to memory Fetch Time depends on access time of memory and activity on Bus Decode/Execute Time depends on type of instruction Instruction Execution Cycle 10
- 11. Summary • Most of modern computer systems are based on von Neumann architecture • Computer components: CPU, Memory and I/O devices • BUS (Control bus, data bus and address bus) links computer components together • CPU (Centre Processing Unit): the brain of a computer. Consists of: ALU (Arithmetic and Logic Unit), Registers, Control Unit, Internal bus and Bus Interface Unit. • CPU instruction cycle includes: Fetch → Decode → Execute. The Little Man Computer: Exercise Write a LMC program which subtracts the second input number from the first input number and outputs the result. (Assumption: first input number >= second input number) Mailbox Code Instruction Description 00 901 INPUT A 01 350 STORE DATA to mailbox no. 50 02 901 INPUT B 03 339 STORE DATA to mailbox no.39 04 550 LOAD the first number 05 239 SUBSTRACT 2nd from 1st 06 902 OUTPUT RESULT 07 000 The little man rest 50 Data 39 Data Exercise Computer system and number system Ex1: Find the word or phrase from the list below that best matches the description in the folloeing question. a) Binary number > III Base 2 number b) Bit > II Binary digit c) Central processor > I Active part of the computer, following the instructions of the programs it adds numbers, test number, and so on d) Complier > VII Program that translates rom a higher-‐level notation to assembly language or machine code e) Integrated circuit > IV Integrate dozens to hundreds of transistors into a single chip f) Memory > Locations of programs when they are running containing the data needed as well g) Operating system > Program that manages the sources of a computer for the benefit of the programs that run on that machine h) Semiconductor > Substance that does not conduct electricity well 11
- 12. Ex2: Convert the following binary numbers to decimal number a.) 1001 b.) 0.111 c.) 0.11011 d.) 1.001 e.) 111.1011 f.) 100.01 Ex3: Convert the following decimal number into binary number a.) 39 b.) 12 C.) 0.25 d.1/8 12
- 13. e.) 6.25 f.) 33 g.) 12.125 h.) 39.125 Ex: Discuss the main components of the little man computer and respond them to in a real computer -‐Mailbox ~= the numbering system > memory -‐Calculator > CPU/ Register -‐Little man > Bus system, CPU -‐Instruction locations (hand counter) > program computer -‐In/Put basket > Input / Output device module -‐Reset button > Reset power 13
- 14. Ex: The LMC uses a 3-‐digit mailbox and the following op-‐code, which are used to write a program. Output largest number of two input number Mailbox Code Instruction Description 00 901 INPUT A 01 399 STORE DATA to mailbox no.99 02 901 INPUT B 03 389 STORE DATA to mailbox no.89 04 299 SUBSTRACT the A to B (B-‐A) 05 820 If B-‐A > 0 (go to 20) 06 599 LOAD A (A is bigger) 07 621 JUMP to 21 07 902 OUTPUT 08 000 STOP . . . . . . . . . . . . 20 589 LOAD B (B is bigger) 21 902 OUTPUT 22 000 STOP 14
- 15. Ex: The LMC uses a 3-‐digit mailbox and the following op-‐code, which are used to write a program. Output smallest number of two input number Mailbox Code Instruction Description 00 901 INPUT A 01 399 STORE DATA to mailbox no.99 02 901 INPUT B 03 389 STORE DATA to mailbox no.89 04 299 SUBSTRACT the A to B (B-‐A) 05 820 If B-‐A > 0 (go to 20) 06 599 LOAD B (B is smallest) 07 621 JUMP to 21 . . . . . . . . . . . . 20 589 LOAD A (A is smallest) 21 902 OUTPUT 22 000 STOP 15
- 16. Operating Systems, Processes and Inter-‐Process Communication Recap…Computer System Components • Hardware – provides basic computing resources (CPU, memory, I/O devices). • Operating system – controls and coordinates the use of the hardware among the various application programs for the various users. • Applications programs – define the ways in which the system resources are used to solve the computing problems of the users (compilers, database systems, video games, business programs). • Users (people, machines, other computers). What is an Operating System (OS)? • A program that acts as an intermediary between an application program (or a user) and the computer hardware – Allocate resources (CPU, Memory, disk space, etc.) between programs and users efficiently – Allow the user to conveniently access data and programs – Protect the system from incorrect or malicious programs and users • Operating system goals: 16
- 17. – Execute user programs and make solving user problems easier. – Make the computer system convenient to use. • Use the computer hardware in an efficient manner What is an OS? • Definitions – Resource allocator – manages and allocates resources – Control program – controls the execution of user programs and operations of I/O devices – Kernel – the one program running at all times (all else being application programs) • Services typically provided by an O.S. – Program Creation (editor, compiler) – Program Execution – Access to I/O devices – Controlled access to files – System Access (logging in) – Error detection/response • O.S. will evolve over time -‐ Hardware upgrades, New services OS History • Serial Processing – Sign-‐up sheet for computer time – Each user would set up the job, run it, and collect output • Simple Batch System (mid 1950s) – Try to improve scheduling/setup time – Have a monitor that loads jobs, when a job finishes it jumps to the monitor that loads the next job. • Multiprogrammed Batch System – Several programs in memory at one time • One program can do I/O while another computes – Needs memory management, scheduling • Time-‐Sharing Systems – Allow several users to interact with the system at the same time – Single-‐user multitasking (windows 95) 17
- 18. Compatible time sharing system (CTSS) – 1962 Switched users every 0.2 second Supported up to 32 users MULTICS (1965) Intended as the computer *Desirable hardware items: service for Memory protection Boston Timer Strong Privileged instructions (I/O) influence on Interrupts later systems Good security, user interface OS Issues • Process. – Hard to define formally, but think of a running program. – O.S. needs to maintain proper synchronization between processes (mutual exclusion, avoiding deadlock). • Main causes of errors: – Improper synchronization. • Must wait for someone else to finish. – Failed mutual exclusion. • Assigning two passengers to the same seat. – Nondeterminate program execution. • Output depends on other programs. • May be a result of misused common memory. – Deadlock. • Two processors each waiting for the other to do something. • Memory management – Isolate processes from each other (shared memory may be allowed). – Automatically move data between main memory and disk. – Support long-‐term storage. • Security – Control use of the system, access to files and other resources. • Scheduling 18
- 19. – Resource allocation and scheduling – Fairness/priorities/efficiency • System structure – As systems grow larger, rely on modules, layers of abstraction • Multithreading – Allow a process to consist of one or more threads that share memory, files, etc. – Helps with structuring programs • Microkernel – Assign only essential functions to the kernel (memory, communication) – Other items run as user processes • Symmetric multiprocessing (SMP) – System may have two or more equivalent processors that share memory, I/O • Distributed operating system (clusters) – Provide illusion of a single system from several entities *Process. Hard to define formally, but think of a running program. Three main components: Executable program. Data for that program. Context (registers, files, etc.) For the program. O.S. Needs to maintain proper synchronization between processes (mutual exclusion, avoiding deadlock). Main causes of errors: Improper synchronization. Must wait for someone else to finish. Failed mutual exclusion. Assigning two passengers to the same seat. Nondeterminate program execution. Output depends on other programs. May be a result of misused common memory. Deadlock. Two processors each waiting for the other to do something. Memory management Isolate processes from each other (shared memory may be allowed). Should allow only appropriate accesses. Often implemented using virtual memory. Automatically move data between main memory and disk. Support modular programs. Support long-‐term storage. Security Control use of the system, access to files and other resources. Areas of concern by O.S. Developers: Access control. Information flow control. 19
- 20. Certify above controls are correct. Scheduling Resource allocation and scheduling Fairness/priorities/efficiency System structure As systems grow larger, rely on modules, layers of abstraction Electronic circuits Instruction set Procedures Interrupts Primitive processes Local secondary storage Virtual memory Communications File system Devices Directories User process Shell Process • A process is a program in execution. A process needs certain resources, including CPU time, memory, files, and I/O devices, to accomplish its task. • Three main components: • Executable program. • Data for that program. • Context (registers, files, etc.) for the program. • The operating system is responsible for the following activities in connection with process management. – Process creation and deletion. – Process suspension and resumption. – Provision of mechanisms for: • process synchronization • process communication Hard to define formally, but think of a running program. Three main components: Executable program. Data for that program. Context (registers, files, etc.) For the program. O.S. Needs to maintain proper synchronization between processes (mutual exclusion, avoiding deadlock). An operating system executes a variety of programs: Batch system – jobs Time-‐shared systems – user programs or tasks 20
- 21. Textbook uses the terms job and process almost interchangeably. Process – a program in execution; process execution must progress in sequential fashion. A process includes: program counter stack data section Process Control Block • Identifiers – Process, Parent, User • Processor State Information associated with each process – User-‐Visible Registers – Control/Status Registers – Stack Pointers (User, System) • Process Control Information – Scheduling/state, Priority – Data structure info (links) – Interprocess Communication – Privilege Information – Memory Management • User Code • User Data • System Stack – Resource Ownership and Utilization Process States • Two-‐state model: – Running – Not Running -‐ may be held in a queue • Requirements – Some way of representing a process • Must include state and memory use – Must keep track of processes that are not currently running – Dispatcher • Moves processes to the waiting queue • Remove completed/aborted processes • Select the next process to run 21
- 22. Five-‐state Model • Processes may be waiting for I/O • Use additional states: – Running: currently being run – Ready: ready to run – Blocked: waiting for an event (I/O) – New: just created, not yet admitted to set of runnable processes – Exit: completed/error exit • May have separate waiting queues for each event May have separate waiting queues for each event Transitions: Null ® New – Process is created New ® Ready – O.S. is ready to handle another process (Memory, CPU) Ready ® Running – Select another process to run Running ® Exit – Process has terminated Running ® Ready – End of time slice or higher-‐priority process is ready Running ® Blocked – Process is waiting for an event (I/O, Synchronization) Blocked ® Ready – The event a process is waiting for has occurred, can continue Ready ® Exit – Process terminated by O.S. or parent Blocked ® Exit – Same reasons Creating a Process • Assign a unique process ID • Allocate memory for the process • Initialize the process control block – Process ID, parent ID – Set program counter and stack pointer to appropriate values 22
- 23. – State usually set to Ready • Set links so it is in the appropriate queue • Create other data structures – Memory, files, accounting • Reasons to create a process – Submit a new batch job/Start program – User logs on to the system – Device driver or Daemon – OS creates on behalf of a user Switching Processes • We will often switch between the various processes in the system – External Interrupt -‐ time slice expired, I/O interrupt – Internal trap, e. g., invalid operation – Supervisor call • Steps to take to switch processes – Save the current processor state (registers, flags, etc.) – Set the program counter to the address of the appropriate routine – Update state of current process from Running to Blocked/Ready/Exit – Move the control block to the appropriate queue – Select another process to execute – Move the control block from the appropriate queue – Update the control block of the selected process to running – Update necessary memory-‐management structures – Restore the context (registers, etc.) of the newly selected process Suspending a Process • May suspend a process by swapping part or all of it to disk – Most useful if we are waiting for an event that will not arrive soon (printer, keyboard) – If not done well, can slow system down by increasing disk I/O activity • Reasons to Suspend – Manage Resources – Timing (backup at midnight process) 23
- 24. – User request (debugging, background) – Parent process (synchronization, errors) New Transitions: Blocked ® Blocked Suspend – Swap out a blocked process to free memory Blocked Suspend ® Ready Suspend – Event occurs (O.S. must track expected event) Ready Suspend ® Ready – Activate a process (higher priority, memory available) Ready ® Ready Suspend – Need to free memory for higher-‐priority processes New ® Ready or Ready Suspend – Can choose where to put new processes Blocked Suspend ® Blocked – Reload process expecting event soon Running ® Ready Suspend – Preempt for higher-‐priority process Key States: Ready – In memory, ready to execute Blocked – In memory, waiting for an event Blocked Suspend – On disk, waiting for an event Ready Suspend – On disk, ready to execute Terminating a Process • Need some way to indicate a process is finished (system call or instruction) • Program may fail – Protection error – Address Error – Invalid data operation – Invalid or privileged instruction – I/O Failure – Parent process request – Operator intervention (control-‐C) Inter-‐process Communication (IPC) • Mechanism for processes to communicate and to synchronize their actions. • Message system – processes communicate with each other without resorting to shared variables. • IPC facility provides two operations: – send(message) – message size fixed or variable – receive(message) • If P and Q wish to communicate, they need to: – establish a communication link between them – exchange messages via send/receive • Implementation of communication link – physical (e.g., shared memory, hardware bus) – logical (e.g., logical properties) 24
- 25. Direct Communication • Processes must name each other explicitly: – send (P, message) – send a message to process P – receive(Q, message) – receive a message from process Q • Properties of communication link – Links are established automatically. – A link is associated with exactly one pair of communicating processes. – Between each pair there exists exactly one link. – The link may be unidirectional, but is usually bi-‐directional. Indirect Communication • Messages are directed and received from mailboxes (also referred to as ports). – Each mailbox has a unique id. – Processes can communicate only if they share a mailbox. • Operations – create a new mailbox – send and receive messages through mailbox – destroy a mailbox • Properties of communication link – Link established only if processes share a common mailbox – A link may be associated with many processes. – Each pair of processes may share several communication links. – Link may be unidirectional or bi-‐directional. • Mailbox sharing – P1, P2, and P3 share mailbox A. – P1, sends; P2 and P3 receive. – Who gets the message? • Solutions – Allow a link to be associated with at most two processes. – Allow only one process at a time to execute a receive operation. – Allow the system to select arbitrarily the receiver. Sender is notified who the receiver was. Primitives are defined as: Operations send(A, message) – send a message to mailbox A create a new mailbox receive(A, message) – receive a send and receive messages through mailbox destroy a mailbox message from mailbox A Client-‐Server Communication –Sockets • A socket is defined as an endpoint for communication. • Concatenation of IP address and port 25
- 26. • The socket 161.25.19.8:1625 refers to port 1625 on host 161.25.19.8 • Communication consists between a pair of sockets. Socket Socket (146.86.5.2/1625) (161.25.19.8/80) Host X (146.86.5.20) Web sever (161.25.19.8/80) Client-‐Server Communication -‐Remote Procedure Calls • Remote procedure call (RPC) abstracts procedure calls between processes on networked systems. • Stubs – client-‐side proxy for the actual procedure on the server. • The client-‐side stub locates the server and marshalls the parameters. • The server-‐side stub receives this message, unpacks the marshalled parameters, and peforms the procedure on the server. Client-‐Server Communication -‐Remote Method Invocation • Remote Method Invocation (RMI) is a Java mechanism similar to RPCs. • RMI allows a Java program on one machine to invoke a method on a remote object. Summary • OS provides an interface between a user of a computer, an application program and the computer hardware • OS have evolved over the years • Process is set of instructions and data and is usually represented by states • OS needs to maintain proper synchronization between processes • Processes use different ways of communication to synchronize their actions 26
- 27. Process and CPU Scheduling Recap … Process … Queues • Process – a program in execution; process execution must progress in sequential fashion. • As a process executes, it changes state • PCB -‐ Information associated with each process • Queues – Job queue – set of all processes in the system. – Ready queue – set of all processes residing in main memory, ready and waiting to execute. – Device queues – set of processes waiting for an I/O device. – Process migration between the various queues. – Starvation – indefinite delay of a process due queue of processes – CPU burst – processing time of a process CPU–I/O Burst Cycle CPU–I/O Burst Cycle • Process execution consists of a cycle of CPU execution and I/O wait. • Maximum CPU utilization obtained with Multiprogramming Process Types • Processes can be described as either: – I/O-‐bound process – spends more time doing I/O than computations, many short CPU bursts. – CPU-‐bound process – spends more time doing computations; few very long CPU bursts. • Process can be of two types: – Non preemptive – once CPU given to the process it cannot be released until it completes its CPU burst. – Preemptive – the process which can be released to before it completes its CPU burst. 27
- 28. Process Scheduling • Decide what processes should be executed by processor • Long-‐term scheduler (or job scheduler) – deals with creating a new process – selects which processes should be brought into the ready queue. – is invoked infrequently (seconds, minutes) ⇒ (may be slow). • Medium-‐term scheduler – deals with swapping processes in/out • Short-‐term scheduler (or CPU scheduler) – selects which process should be executed next and allocates CPU – is invoked very frequently (milliseconds) ⇒ (must be fast). – Invoked on: • clock or I/O interrupt • system call, signal Representation of Process Scheduling CPU Scheduler • Selects from among the processes in memory that are ready to execute, and allocates the CPU to one of them. • CPU scheduling decisions may take place when a process: 1. Switches from running to waiting state. 2. Switches from running to ready state. 3. Switches from waiting to ready. 4. Terminates. • Scheduling under 1 and 4 is non preemptive. • All other scheduling is preemptive. 28
- 29. Dispatcher • Dispatcher module gives control of the CPU to the process selected by the short-‐term scheduler; this involves: – switching context – switching to user mode – jumping to the proper location in the user program to restart that program • Dispatch latency – time it takes for the dispatcher to stop one process and start another running. Scheduling Criteria • CPU utilization – keep the CPU as busy as possible • Throughput – number of processes that complete their execution per time unit • Turnaround time – amount of time to execute a particular process • Waiting time – amount of time a process has been waiting in the ready queue • Response time – amount of time it takes from when a request was submitted until the first response is produced Scheduling Algorithms • First-‐Come, First-‐Served (FCFS) Scheduling • Shortest-‐Job-‐First (SJR) Scheduling • Shortest-‐Remaining-‐Time-‐First (SRTF) • Round Robin (RR) • Highest Response Ratio Next • Feedback First-‐Come, First-‐Served (FCFS) Scheduling Process: P1 P2 P3 Waiting Time Burst Time: 24 3 3 =Complete time – Arrived time – Burst time Waiting time > P1=24-‐0-‐24=0 P2=27-‐0-‐3=24 • Suppose that the processes arrive in the order: P1, P 2, P3 P3=30-‐0-‐3=27 The Gantt chart for the schedule is: P1 P2 P3 P1=24 P2=3 P3=3 CPU Time 0 P1=24 24 27 30 P2=3 P2=3 P3=3 Average waiting time = P3=3 P3=3 (0+24+27)/3=17 29 =
- 30. • Suppose that the processes arrive in the order P2 , P3 , P1 . The Gantt chart for the schedule is: P2 P3 P1 P2=3 P3=3 P1=24 CPU Time 0 3 6 30 P2=3 P3=3 P1=24 P3=3 P1=24 Waiting Time =Complete time – Arrived time – Burst time P1=24 Waiting time > P1=30-‐0-‐24=6 • Processes queued in order of arrival P2=3-‐0-‐3=0 • Runs until finished or blocks on I/O P3=6-‐0-‐3=3 Average waiting time = (6+0+3)/3=3 • Tends to penalize short processes – Have to wait for earlier long processes • Convoy effect short process behind long process • Favors processor-‐bound processes – I/O processes block quickly Shortest-‐Job-‐First (SJR) Scheduling • Associate with each process the length of its next CPU burst. Use these lengths to schedule the process with the shortest time. • Two types: – Nonpreemtive version • Select process with shortest expected running time – once CPU given to the process it cannot be preempted until completes its CPU burst. • Short processes may still wait if a long process has just started – Peemtive version • Select process with shortest expected running (or remaining) time • May switch processes when a new process arrives – if a new process arrives with CPU burst length less than remaining time of current executing process, preempt • Also called Shortest-‐Remaining-‐Time-‐First (SRTF) Scheduling • Difficult to estimate required time – Can only estimate the length of Next CPU Burst – Can estimate from previous runs • Tends to be less predictable • Can starve long processes – notpreemtive SJR is better than SRTF (preemtive SRJ) in this regard • Short processes may still wait if a long process has just started – SRTF is better than nonpreemptive SRJ in this regard 30
- 31. Examples of SJF Process Arrival Time Burst Time P1 0.0 7 P2 2.0 4 P3 4.0 1 P4 5.0 4 SJF (non-‐preemptive) P3 P2 P4 P1 P1 P1 P1 P1 P3=1 P2=4 P4=4 CPU Time 0 2 4 5 7 8 12 16 P1=7 P2=4 P3=1 P4=4 P2=4 P2=4 P4=4 P3=1 P4=4 Waiting time P4=4 P1=7-‐0-‐7=0 P2=12-‐2-‐4=6 P3=8-‐4-‐1=3 P4=16-‐5-‐4=7 Average waiting time (AWT) = (0+6+3+7)/4=4 SJF (preemptive) P3 P2 P4 P1 P4=4 P1=5 P1=2 P2=2 P3=1 P2=2 0 2 4 5 7 11 16 P1=7 P1=5 P1=5 P1=5 P1=5 P1=5 P2=4 P2=2 P2=2 P4=4 Waiting time P3=1 P4=4 P1=16-‐0-‐7=9 P2=7-‐2-‐4=1 P3=5-‐4-‐1=0 P4=11-‐5-‐4=2 Average waiting time (AWT) = (9+1+0+2)/4=3 Priority Scheduling • A priority number (integer) is associated with each process • The CPU is allocated to the process with the highest priority (smallest integer ≡ highest priority). – Preemptive – nonpreemptive • SJF is a priority scheduling where priority is the predicted next CPU burst time. • Problem ≡ Starvation – low priority processes may never execute. • Solution ≡ Aging – as time progresses increase the priority of the process. 31
- 32. Round Robin (RR) • Each process gets a small unit of CPU time (time quantum), usually 10-‐100 milliseconds. After this time has elapsed, the process is preempted and added to the end of the ready queue. • If there are n processes in the ready queue and the time quantum is q, then each process gets 1/n of the CPU time in chunks of at most q time units at once. No process waits more than (n-‐1)q time units. • Performance – q large ⇒ FIFO – q small ⇒ q must be large with respect to context switch, otherwise overhead is too high. Example of RR Process P1 P2 P3 P4 Burst Time 53 17 24 68 Time Quantum = 20 • The Gantt chart is: P2 P3 P1 P4 P1=20 P2=17 P3=20 P4=20 P1=20 P3=4 P4=20 P1=13 P4=20 P4=8 0 20 37 57 77 97 101 121 134 154 162 P1=53 P2=17 P3=24 P4=68 P1=33 P3=4 P4=48 P1=13 P4=28 P4=8 P2=17 P3=24 P4=68 P1=33 P3=4 P4=48 P1=13 P4=28 P3=24 P4=68 P1=33 P3=4 P4=48 P1=13 P4=68 P1=33 Waiting time P1=134-‐0-‐53=81 P2=37-‐0-‐17=20 P3=101-‐0-‐24=77 P4=162-‐0-‐68=94 Average waiting time (AWT) = (81+20+77+94)/4=68 • Typically, higher average turnaround than SJF, but better response. • Favors processor-‐bound processes • Virtual Round Robin • Second queue for formerly blocked processes – given priority – At end of time slice, add to end of standard queue 32
- 33. Highest Response Ratio Next • Depends on Response Ratio – W = time spent waiting – S = expected CPU burst time – Response Ratio = (W + S) / S • Select process with highest Response Ratio • Nonpreemptive, tries to get best average normalized turnaround time More Algorithms • Fair Share Scheduling – Think of processes as part of a group – Each group has a specified share of the machine it is allowed to use – Priority is based on the time this processes is active, and the time the processes in the group have been active • Feedback – Starts in high-‐priority queue, moves down in priority as it executes – Lower-‐priority queues often given longer time slices – Can starve long processes • Move up processes if they wait too long Multilevel Queue • Ready queue is partitioned into separate queues • Each queue has its own scheduling algorithm, e.g. RR, FCFS • Scheduling must be done between the queues. – Fixed priority scheduling; (i.e., serve all from one queue and then from other). Possibility of starvation. – Time slice – each queue gets a certain amount of CPU time which it can schedule amongst its processes; i.e., 80% to queue in RR, 20% to queue in FCFS Summary • Scheduling decides what processes should be executed by the processor • Long-‐term, Medium-‐term and Short-‐term Scheduler – Deals with creating a new process – Deals with swapping processes in/out – What process should we run next? • A number of performance measures can be used as scheduling criteria • There are a number of CPU scheduling algorithms 33
- 34. Exercise Given the following processes with the following arrival and burst times Process(s) Arrival Burst Calculate the average waiting time when the following Time Time algorithms are used P1 0 9 -‐First come and first serve (FCFS) scheduling algorithm P2 6 22 -‐Round Robin algorithm with quantum of 7 P3 3 24 -‐Shortest job first with non pre-‐emptive version -‐Shortest remaining job first (Shortest job first with pre-‐ P4 7 3 emptive version) -‐First come and first serve (FCFS) scheduling algorithm P1 P3 P2 P4 P1=3 P1=3 P1=1 P1=2 P3=24 P2=22 P4=3 0 3 6 7 9 33 55 58 P2=22 P4=3 P1=9 P3=24 P2=22 P4=3 P3=24 P2=22 P4=3 Waiting time P4=3 P1=9-‐0-‐9=0 =2 P2=55-‐6-‐22=27 P3=33-‐3-‐24=6 P4=58-‐7-‐3=48 Average waiting time (AWT) = (0+27+6+48)/4=20.25 -‐Round Robin algorithm with quantum of 7 -‐Shortest job first with non pre-‐emptive version 34
- 35. -‐Shortest remaining job first (Shortest job first with pre-‐emptive version) Ex. Calculate the wait time for each of the following process and the overall average wait time when implementing the following algorithm. -‐FCFS -‐RR -‐SJF (non pre-‐emptive) -‐SJF (pre-‐emptive) 35
- 36. Deadlocks Bridge Crossing Example • Bridge traffic only in one direction. • Each section of a bridge can be viewed as a resource. • If a deadlock occurs, it can be resolved if one car backs up (preempt resources and rollback). • Several cars may have to be backed up if a deadlock occurs. Recap … Processes … Deadlock • Process – program in execution -‐ active element with states • Process uses resources during its operation – Process takes ownership of CPU, memory, bus …. • Processes have to compete for limited recourses • Deadlock – Permanent blocking of a set of processes that either compete for system resources or communicate with each other – Involve conflicting needs for resources by two or more processes • Starvation – Indefinite delay of a process due to queue of processes Process Deadlock Processes P and Q are competing for recourses D and T Process P Process Q Step Action Step Action P0 Request (D) Q0 Request (T) P1 Lock (D) Q1 Lock (T) P2 Request (T) Q2 Request (D) P3 Lock (T) Q3 Lock (D) P4 Perform function Q4 Perform function P5 Unlock (D) Q5 Unlock (T) P6 Unlock (T) Q6 Unlock (D) 36
- 37. Resources • Reusable Resources – Can only be used by one process at a time. After use, can be reassigned to another process – Processors, I/O channels, main and secondary memory, files, databases – Deadlock occurs if each process holds one resource and requests the other • Consumable Resources – Created (produced) and destroyed (consumed) by a process – Interrupts, signals, messages, and information – Can deadlock if both waiting for a message from each other – May take a rare combination of events to cause deadlock Examples of Deadlock • With reusable resources – Space is available for allocation of 200K bytes – Deadlock occurs if both processes progress to their second request • With consumable resources – Deadlock occurs if receive is blocked Conditions for Deadlock Deadlock can arise if four conditions hold simultaneously • Mutual Exclusion – Only one process can hold the resource at any given time • Hold and Wait – A process may hold resources while requesting other resources • No Preemption – No resource may be forcibly removed from a process • Circular Wait (event) – A closed chain of process exists, each waiting for a resource held by the next process in the chain Deadlock Prevention • Can prevent deadlock by forbidding one of the conditions • Forbid Mutual Exclusion 37
- 38. – Must hold for nonsharable resources – Generally not reasonable • Forbid Hold and Wait – No holding of resources when request made – Ask for all resources at one time – May block a process in waiting for resources it doesn’t yet need – May hold resources that are not needed immediately – May not know what to request • Forbid No Preemption – Take resources away from waiting processes – Only feasible if state can be saved, e.g. CPU, Memory • Forbid Circular Wait – Define a linear order on items • If it needs resources 3, 15, 6, 9, and 4 then must request in the order 3, 4, 6, 9, 15 • May not be easy to define the order ***Cannot have circular wait because a process cannot have 9 and request 5 State of the System • State of the system is the current allocation of resources to processes • Safe state – There exists at least one sequence that does not result in deadlock – We can finish all processes by some scheduling sequence • Unsafe state is a state that may lead to deadlock • When a process requests an available resource, system must decide if immediate allocation leaves the system in a safe state Current allocation: A B C P0 0 1 0 P1 2 0 0 P2 3 0 3 P3 2 1 1 P4 0 0 2 Deadlock Avoidance • A method which ensures that a system never enter an unsafe state • Makes a decision dynamically whether the current resource allocation request will potentially lead to a deadlock • Requires knowledge of future process request • Uses Resource Allocation Denial or Banker’s Algorithm for analysis 38
- 39. Deadlock Avoidance • A method which ensures that a system never enter an unsafe state • Makes a decision dynamically whether the current resource allocation request will potentially lead to a deadlock • Requires knowledge of future process request • Uses Resource Allocation Denial or Banker’s Algorithm for analysis Deadlock Avoidance A method which ensures that a system never enter an unsafe state A decision is made dynamically whether the current resource allocation request will potentially lead to a deadlock Assume we know the maximum requests for each process Process must declare it needs a max of objects Do not need to use its max claims Can make requests at any time and in any order Process Initiation Denial Track current allocations Assume all processes may make maximum requests at the same time Only start process if it can’t result in deadlock regardless of allocation Requires knowledge of future process request Resource Allocation Denial (Banker’s Algorithm) • Process makes maximum claims for recourses but no need to use its max claims • Process makes a request for resources • Reject a request if it exceeds the processes’ declared maximum claims • Grant a request if the new state would be safe • Determining if a state is safe – Find any process Pi for which we can meet it’s maximum requests – Mark Pi as “done”, add its resources to available resource pool – State is safe if we can mark all processes as “done” • Block a process if the resources are not currently available or the new state is not safe 39
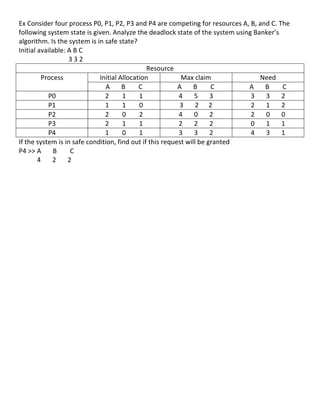
- 40. Example of Banker’s Algorithm • Assume that we have five processes: P0, P1, P2, P3 and P4. • Resource vector: A B C 10 5 7 • Initial state (snapshot at time = 0): Allocation Max claim Need A B C A B C A B C P0 0 1 0 7 5 3 7 4 3 P1 2 0 0 3 2 2 1 2 2 P2 3 0 2 9 0 2 6 0 0 P3 2 1 1 2 2 2 0 1 1 P4 0 0 2 4 3 3 4 3 1 Available vector A B C 3 3 2 Exercise: Analyze the state of the system using Bankers’ algorithm Process Initial allocation Need • S Done? No if Updated Available A B C A B C a A B C t • S 3 3 2 i a P0 0 1 0 7 4 3 s No t -‐ f i i s P1 2 0 0 1 2 2 e Yes f 5 3 2 s i e s s P2 3 0 2 6 0 0 a No -‐ f s e a P3 2 1 1 0 1 1 t Yes f 7 4 3 y e t P4 0 0 2 4 3 1 ? Yes y 7 4 5 • S ? a P0 0 1 0 7 4 3 t Yes • S 7 5 5 i a s t P2 3 0 2 6 0 0 f Yes i 10 5 7 i s e f • Satisfies safety ? the system safety condition (every process can done ) s i P1>P3>P4>P0>P2 e s s a f s e a f 40 t
- 41. • Now consider the actual resource requests • P0 Requests (0,0,0) – Check that Need ≤ Available, that is, (7,4,3) ≤ (3,3,2) ⇒ false ⇒ May lead to unsafe state ⇒ Request not granted • P1 Requests (1,0,2) – Check that Need ≤ Available, that is, (1,2,2) ≤ (3,3,2) ⇒ ? – Check that Request ≤ Max claim, that is, (1,0,2) ≤ (3,2,2) ⇒ ? – Check that Request ≤ Available, that is, (1,0,2) ≤ (3,3,2) ⇒? ⇒ System state ? • Homework: Can requests for (5,3,0) by P4 be granted? Deadlock Avoidance • Maximum resource requirement must be stated in advance • Processes under consideration must be independent; no synchronization requirements • There must be a fixed number of resources to allocate • Requires knowledge of future process request • Avoidance method tends to limit access to resources Deadlock Detection • Grant arbitrary requests and note when deadlock happens – Allow system to enter deadlock state • Detect deadlock using a detection algorithm, e.g. – Create table of process requests, current allocations – Mark any process whose requests can be met (requests £ available resources) – Reclaim resources held by the marked process – If any processes cannot be marked, they are part of a deadlock • Use a recovery strategy 41
- 42. Example of Deadlock Detection Assume that we have five processes with resource vector: A B C 7 2 6 and with initial state of allocation matrix: Exercise: A B C Analyse the following two scenarios with P0 0 1 0 request matrices: P1 2 0 0 Request1 Request2 P2 3 0 3 A B C A B C P0 0 0 0 0 0 0 P3 2 1 1 P1 2 0 2 2 0 2 P4 0 0 2 P2 0 0 0 0 0 1 => Initial available vector A B C P3 1 0 0 1 0 0 0 0 0 P4 0 0 2 0 0 2 Analysis of scenario with Request1 • State of system ? 42
- 43. Recovery Strategies once Deadlock Detected • Abort all deadlocked processes • Back up each deadlocked process to some previously defined checkpoint, and restart all process – original deadlock may occur • Successively abort deadlocked processes until deadlock no longer exists • Successively preempt resources until deadlock no longer exists Selection Criteria Deadlocked Processes • Least amount of processor time consumed so far • Least number of lines of output produced so far • Most estimated time remaining • Least total resources allocated so far • Lowest priority Summary • Deadlock is a state of permanent blocking of a set of processes due to limited system resources • Deadlock can arise if Mutual Exclusion, Hold and Wait, No Preemption and Circular Wait hold simultaneously • Banker’s Algorithm is ensures that a system never enter an unsafe state • Detection algorithm allows system to enter deadlock state and uses recovery strategy Ex: Two process P0 and P1 are competing for recourse A and B. Given the following scenario: Initial available vector A B: 4 2 Initial allocation matrix A B P0 1 2 Using the Banker’s algorithm identify if the P1 2 2 request made by P0 and P1 can be granted Maximum claim matrix A B P0 8 6 P1 4 3 Request matrix A B P0 1 2 P1 2 2 43
- 44. Cache memory Recap … The Memory Hierarchy • Problem between CPU and Memory: – CPU is very fast whereas main memory DRAM is too slow – Slow main memory constraints the ability of a fast CPU • Ways to solve the problem: – Use SRAM in all main memory but very expensive, not feasible – Small capacity of SRAM built between CPU and main memory for frequently required information Cache • Small amount of fast memory -‐ for storing recently/frequently used instructions and data • Sits between normal main memory and CPU • Cache memory is based on Locality principles • May be located on CPU chip or module 44
- 45. Cache Overview Operation • CPU requests contents of memory location • Check cache for this data • If present (hit), get from cache (fast) • If not present (miss), read required block from main memory to cache • Then deliver from Typical Cache cache to CPU Organization Cache memory performance • Hit – The information requested is found in the cache. – Hit ratio (h): the fraction of memory access found in the cache – Hit time: time to access the cache: • Miss – The data requested are not found in the cache. – Fetch the information, write into cache and send to CPU – Miss ratio = 1 -‐ h, (the smaller the better) – Miss penalty (Tmiss): (time to replace write in cache) + time to send the data to CPU – Miss penalty is much longer than hit time Cache Design • Design objective – To provide adequate fast memory at a reasonable cost • Design issues – How to store data in catch memory? – How to determine that a data requested by CPU is in the cache memory? – How to find it? • Design characteristics – Number of Caches, Size, Block Size – Mapping methods: direct, associative, set associative – Replacement Algorithm – Write Policy Direct Mapping Cache Memory • Data are transferred between cache and main memory in blocks • Main memory is divided into blocks • Cache built in lines (slots) each of which can hold one block size • Each block of main memory maps to only one cache line 45
- 46. • Address is in three parts • Least Significant w bits identify unique word – word identifier • The next higher significant r bits specify a cache line – cache line identifier • The most significant s-‐r bits specify a tag – tag identifier • Most Significant s bits specify one memory block Tag s-‐r Line or Slot r Word w Direct Mapping Cache Organization • No two blocks in the same line have the same Tag field • Check contents of cache by finding line and checking Tag 46
- 47. Direct Mapping Example • Finding a direct mapping address structure for: Main memory capacity = 16MBytes; Block size= 4 Bytes and Cache capacity 64 KBytes • Main memory capacity 16MBytes = 224 Bytes => address length = 24 bit • Block size = 4 Bytes (words) = 22 => 2 bits for word identifier • Number of cache blocks (lines) = cache capacity/block size = 64K/4 = 16K = 214 => 14 bits for line identifier • Blocks of main memory are divided into sets that are labelled as tag. number of main memory blocks 222 number of sets = = 14 = 28 number of cache blocks 2 • Or Number of bits for tag = address length – word identifier – line identifier = 24 – 2 – 14 = 8 bits So, a 24-‐bit address is divided into 3 parts: tag, slot and word. Word: 2-‐bit (block size or line size) Line or Slot: 14-‐bit (as slot address index in cache memory) Tag: 8-‐bit. Tag s-‐r = 8 Line or Slot r = 14 Word w= 2 • Cache line table (number of lines in cache m= 214) • Starting memory address of block Cache line Main Memory blocks held Starting memory address of block 0 0, m, 2m, 3m…2s-‐m 1 1, m+1, 2m+1…2s-‐m+1 m-‐1 m-‐1, 2m-‐1, 3m-‐1…2s-‐1 47
- 48. Direct Mapping Summary • Address length = (s + w) bits • Number of addressable units = 2s+w words or bytes • Block size = line size = 2w words or bytes – Size for word identifier = w bits • Number of blocks in main memory = 2s+ w/2w = 2s • Number of lines in cache (Number of blocks in cache memory) = m = Cache Capacity/Block Size = 2r – Size for cache line identifier = r bits • Size of tag = (s – r) bits Tag s-‐r Line or Slot r Word w Direct Mapping Features • Simple and not expensive • Conflict: – Fixed location in cache memory for a given main memory block – Many main memory blocks have same block number – If two blocks with same block number are requested by CPU • The later block will replace (overwrite) the former one • The blocks will be continually swapped in cache memory • The hit ratio will be low, causing miss penalty • Possible Solutions: – Bigger cache memory – Two level caches: level 1(L1) and level 2 (L2) – Associative mapping 48
- 49. Associative Mapping • A main memory block can load into any line of cache • Memory address is interpreted as tag and word • Tag uniquely identifies block of memory • Every line’s tag is examined for a match • Cache searching gets expensive Compare tag field with tag entry in cache to check for hit Fully Associative Cache Organization Associative Mapping Example • Finding an associative mapping address structure for: Main memory capacity = 16MBytes; Block size= 4 Bytes and Cache capacity 64 KBytes • Main memory capacity 16MBytes = 224 Bytes => address length = 24 bit • Block size = 4 Bytes (words) = 22 => 2 bits for word identifier • Total number of blocks in main memory = 16M/4 = 222 • Each Block of main memory is a set, which is labelled as tag. • Number of bits for tag (s) = address length – word identifier = 24 – 2 = 22 bits • So, a 24-‐bit address is divided into 2 parts: tag and word. Word: 2-‐bit (block size or line size) Tag: 22-‐bit. Tag s = 22 Word w= 2 49
- 50. Tag s = 22 Word w= 2 Address Structure Associative Mapping Summary • Address length = (s + w) bits • Number of addressable units = 2s+w words or bytes • Block size = line size = 2w words or bytes • Number of blocks in main memory = 2s+ w/2w = 2s • Number of lines in cache = undetermined • Size of tag = s bits • Replacement algorithm required • Disadvantages: complex circuitry, extensive comparison of tags 50
- 51. Set Associative Mapping • Compromise of direct and associative mappings • Cache is divided into a number of sets • Each set contains a number of lines • A given block maps to any line in a given set – e.g. Block B can be in any line of set i • e.g. 2 lines per set – 2 way associative mapping – A given block can be in one of 2 lines in only one set • Extreme cases: – If 1 cache line/set (total sets= total cache lines) => direct mapping – If number of set=1 (all lines in that set)=> fully associative mapping Two Way Set Associative Cache Organizations • Use set field to determine cache set to look in • Compare tag field to see if we have a hit 51
- 52. 2-‐Way Set Associative Mapping Example • Finding an associative mapping address structure for: Main memory capacity = 16MBytes; Block size= 4 Bytes and Cache capacity 64 KBytes • Main memory capacity 16MBytes = 224 Bytes => address length = 24 bit • Block size = 4 Bytes (words) = 22 => 2 bits for word identifier • Total number of cache blocks (lines) per set = cache capacity/block size = 64K/4 = 16K = 214 • Number of cache lines per set = 2 • Number of cache sets = 214/2 = 213 => 14 bits for line for set identifier • Number of bits for tag (s) = address length – set identifier – word identifier = 24 – 13 -‐ 2 = 9 bits • So, a 24-‐bit address is divided into 3 parts: tag, set and word. Tag: 9-‐bit, Word: 2-‐bit, Set: 13-‐bit Tag 9 bit Set 13 bit Word 2 bit 52
- 53. k-‐Way Set Associative Mapping Summary • Address length = (s + w) bits • Number of addressable units = 2s+w words or bytes • Block size = line size = 2w words or bytes • Number of blocks in main memory = 2d • Number of lines in set = k • Number of sets = v = 2d • Number of lines in cache = kv = k * 2d • Size of tag = (s – d) bits • Extreme cases: – If k=1, v=number of cache lines => direct mapping – If k= number of cache lines, v=1 => fully associative mapping Replacement Algorithms • Strategy to replace existing block by new block • Direct mapping – No choice – Each block only maps to one line – Replace that line • Associative & Set associative – Hardware implemented algorithm (speed) – Least Recently used (LRU) • replace block that was least recently used – First in first out (FIFO) • replace block that has been in cache longest – Least frequently used • replace block which has had fewest hits – Random Cache coherency • The data in cache, altered by CPU, may be different from its corresponding in the main memory. • Keep consistency: To ensure the contents in cache block are consistent with its mapping memory. Write policy: • Must not overwrite a cache block unless main memory is up to date • Multiple CPUs may have individual caches • I/O may address main memory directly Write through • All writes go to main memory as well as cache • Multiple CPUs can monitor main memory traffic to keep local (to CPU) cache up to date • Lots of traffic • Slows down writes 53
- 54. • Remember bogus write through caches! Write back • Updates initially made in cache only • Update bit for cache slot is set when update occurs • If block is to be replaced, write to main memory only if update bit is set • Other caches get out of sync • I/O must access main memory through cache • N.B. 15% of memory references are writes Cache typical characteristics • Cache size: 1 -‐ 256 K • Block size: 4 -‐ 128 bytes • Hit time(h): 1 -‐ 4 cycles • Miss penalty: 8 -‐ 32 cycles – access time: 6 -‐10 cycles – transfer time: 2 -‐ 22 cycles • Miss ratio: 1% -‐ 20% Average memory access time: Tav = h x Tcache + (1-‐h) x Tmiss e.g. h = 90%, Tcache = 2 cycle, Tmiss= 20 cycle Summary • Cache memory is used to match the processor speed with the rate of information transfer • Cache memory for frequently used instructions/data • Main features of cache design space are – total size, block size – mapping (associativity) – replacement policy – write policy • Cache performance can be measured by average memory access time Exercise Ex1. How many address line are required to access 64k works of main memmory? 54
- 55. Ex2. How many words of memory can be accessed using 20 address line? Ex3. A cache memory has a hit rate of 92% and access time of 25ns. It is attached to a main memory with an access time of 90 ns. Calculate the main memory access time when cache is switched on. Ex4. Given that the hit rate to the cache memory for a particular program is 0.9. Calculate the percentage by which the program id speeded up by the use of cache memory over a similar processer with no cache memory. Suppose cache memory access time is 3 cycles and main memory access time is 5 cycles. 55
- 56. Ex5. A main memory has a capacity of 32 words and a cache memory has a capacity of 8 words, if a series of memory address occurred are 1,8,15,1,2,5,10,15,9,2,8,9,1,7,8,5 and 9. Show the final contents of cache memory and the format of main memory address for a. Direct mapped memory with 1 word block size b. Direct mapped memory with 2 word block size c. Associative memory with 2 word block size use replace LRU d. 2 way associative memory with 1 word block size use replace FIFO 56
- 57. Memory Management Recap…. Process Swapping • A process can be swapped temporarily out of memory to a backing store, and then brought back into memory for continued execution. • Backing store – fast disk large enough to accommodate copies of all memory images for all users. • Roll out, roll in – used for priority-‐ based scheduling algorithms; lower-‐ priority process is swapped out so higher-‐priority process can be loaded and executed. • Major part of swap time is transfer time; total transfer time is directly proportional to the amount of memory swapped. Logical vs. Physical Address Space • The concept of a logical address space and physical address space is central to proper memory management. – Logical address – generated by the CPU; also referred to as virtual address. – Physical address – address seen by the memory unit. • Logical (virtual) and physical addresses are the same in compile-‐time; but differ in execution time. Memory-‐Management Unit (MMU) • Hardware device that maps virtual to physical address. • In MMU scheme, the value in the relocation register is added to every address generated by a user process at the time it is sent to memory. • The user program deals with logical addresses; it never sees the real physical addresses. 57
- 58. Overlays • Large programs -‐ too big to fit in physical memory • Split along logical boundaries – Procedures, distinct functions • Needed when process is larger than amount of memory allocated to it • Keep in memory only those instructions and data that are needed at any given time • One overlay in primary memory -‐ rest on disc • When branch is made to code on disc – Store current overlay on disc, read in new overlay • Implemented by user, no special support needed from operating system Large programs can generally be decomposed into sub-‐units, which are, to an extent, self-‐contained. Whilst one sub-‐unit is active, the others will be dormant. Since this is the case, these others may as well be removed from primary memory and placed in secondary memory. Sub-‐units, which can be treated in this way, are called “overlays”. It is up to the programmer to divide her code into overlays; bearing in mind that whenever a jump is made to an overlay not currently in primary memory there will be a pause whilst the required overlay is loaded. Thus, it is important that overlays are chosen so that jumps between them are kept to a minimum. Early PC programs made extensive use of overlays and their use allowed very large programs to be run even within the original 640K RAM limit. However, performance can suffer badly as time is lost moving overlays to and from secondary memory. This performance loss is quite noticeable to users. For example, when using a spelling checker in a word processor, there may be a pause (accompanied by frenzied disc activity) whilst the overlay containing the checker is loaded. Having said that, if the overlay system is well designed, so that too frequent switching between overlays is avoided and that the size of the overlays is well-‐ matched to the memory available, then overlays can be highly efficient. The main problem is that the solution has to be re-‐invented each time a new program is written or maybe even when an old one is modified. Memory Management • Five Requirements for Memory Management to satisfy: – Relocation • Users generally don’t know where they will be placed in main memory • Generally handled by MMU – Protection • Prevent processes from interfering with the O.S. or other processes – Sharing • Allow processes to share data/programs – Logical Organization • Support modules, shared subroutines – Physical Organization • Manage mem « disk transfers 58
- 59. Fragmentation • External Fragmentation – total memory space exists to satisfy a request, but it is not contiguous. • Internal Fragmentation – allocated memory may be slightly larger than requested memory due a partition, but not being used. • Reduce external fragmentation by compaction – Shuffle memory contents to place all free memory together in one large block. – Compaction is possible only if relocation is dynamic, and is done at execution time. MM Techniques • Fixed Partitioning • Dynamic Partitioning • Buddy System • Simple Paging • Simple Segmentation • Virtual-‐Memory Paging • Virtual Memory Segmentation Fixed Partitioning Divide memory into partitions at boot time, partition sizes don’t change Simple but has internal fragmentation Dynamic Partitioning Create partitions as programs loaded Avoids internal fragmentation, but must deal with external fragmentation Simple Paging Divide memory into equal-‐size pages, load program into available pages Pages do not need to be consecutive No external fragmentation, small amount of internal fragmentation Simple Segmentation Divide program into segments Each segment is contiguous, but different segments need not be No internal fragmentation, some external fragmentation Virtual-‐Memory Paging Like simple paging, but not all pages need to be in memory at one time Allows large virtual memory space More multiprogramming, overhead Virtual Memory Segmentation Like simple segmentation, but not all segments need to be in memory at one time Easy to share modules More multiprogramming, overhead 59
- 60. Fixed Partitioning • Memory is divided into a set of partitions, each holds one program • May have same or different sizes • • Equal-‐sized partitions – Program may be too large for one partition • Programmer must handle overlays – Program may not be big enough to need a full partition • Results in internal fragmentation • Variable-‐sized partitions – Can fit partition size to program size – Placement • Want to use smallest possible partition • Can have a queue for each partition size, or one queue for all partitions • Easy to implement • Tends to use memory poorly, especially for small programs (internal fragmentation) – Will work if the job sizes can be predicted in advance Dynamic Partitioning • Create a new partition for each program • Only allocate space required • Tends to create “holes” as processes are swapped in and out (external fragmentation) • Tends to generate small holes in memory (external fragmentation) • Compaction -‐Shifting processes so all of the available memory is in one block -‐ Requires processor time to move items around in memory -‐ Requires relocation hardware that can handle the change in addresses >Cannot easily find all possible addresses in the program 60
- 61. >Need to move program without changing user addresses • Placement Algorithms – Best-‐Fit: Find the smallest available block that will hold the program • Tends to produce a lot of small blocks, e.g. use 30K block for 28K program, leaves 2K – First-‐Fit: Find the first block that is large enough (regardless of size) • May leave small blocks at the beginning, larger blocks at the end of memory • Generally best, fastest – Next-‐Fit: Like First-‐Fit, but start from the last allocation instead of the start • Tends to break up large blocks at the end of memory that First-‐Fit leaves alone – Worst-‐Fit – Allocate the largest hole Buddy System • Tries to allow a variety of block sizes while avoiding excess fragmentation • Blocks generally are of size 2k, for a suitable range of k • Initially, all memory is one block • All sizes are rounded up to 2s • If a block of size 2s is available, allocate it • Else find a block of size 2s+1 and split it in half to create two buddies • If two buddies are both free, combine them into a larger block • Largely Replaced by paging Buddy System Example 61
- 62. Paging • Divides memory into small (4K or less) pieces of memory (frames) • Logically divide program into same-‐size pieces (pages) • Page size typically a power of 2 to simplify the paging hardware • Use a page table to map the pages of the current process to the corresponding frames in memory Example Page Table A B C D Free 0 - 7 4 13 1 - 8 5 14 2 - 9 6 3 10 11 12 Logical address space of a process can be noncontiguous; process is allocated physical memory whenever the latter is available. Divide physical memory into fixed-‐sized blocks called frames (size is power of 2, between 512 bytes and 8192 bytes). Divide logical memory into blocks of same size called pages. Keep track of all free frames. To run a program of size n pages, need to find n free frames and load program. Set up a page table to translate logical to physical addresses. Internal fragmentation. Page size typically a power of 2 to simplify the paging hardware Example (16-‐bit address, 1K pages) 010101 011011010 Top 6 bits (010101)= page # Bottom 10 bits (011011010) = offset within page Common sizes: 512 bytes, 1K, 4K 62
- 63. Page Table and Free Frames • Set up a page table to translate logical to physical addresses • Keep track of all free frames • To load a program of size n pages, need to find n free frames Implementation of Page Table Before After • Page table is kept in main memory. • Page-‐table base register (PTBR) points to the page table. • Page-‐table length register (PRLR) indicates size of the page table • Use of valid (v) or invalid (i) bit in a page table 63
- 64. Segmentation • Memory-‐management scheme that supports user view of memory. • A program is a collection of segments. A segment is a logical unit such as: Main program, procedure, function, method, object, local variables, global variables, Common block, stack, symbol table, arrays • Program views memory as a set of segments of varying sizes – Easy to handle growing data structures – Easy to share libraries, memory – Privileges can be applied to a segment – Programs may use multiple segments • Have a segment table – Beginning address – Size – Present, Modified, Accessed bits – Permission/Protection bits Summary • Process can be swapped out of and back into memory • MMU is a hardware device that maps virtual to physical address • Overlays needed when process is larger than amount of memory allocated to it • There a number of partitioning algorithms • Paging divides memory into small pieces called frames and program into pages 64
- 65. Exercise Ex1.) Assume a computer with a memory size of 128 MB initially empty. Requests and freeing are received for blocks of memory of P1= 5 M, P2 = 30 M, P3= 25 M, P2 completed, P4=27 M, P3 completed, P5= 3 M, P1 completed, P6= 10 M. Show hoe the dynamic partitioning would deal with each request, showing the memory layout at each stage. Use the following strategies for the dynamic partitioning A-‐ Best fit B-‐ Frist fit C-‐ Next fit Ex2.) Same problem show how the buddy system would deal with each request, showing the memory layout at each stage for each of the system 65
- 66. Virtual Memory Recap … Real to Virtual Memory • Program addresses only logical addresses, Hardware maps to physical addresses • Possible to load only part of a process into memory • Logical address space can be much larger than physical address space • Real Memory – The physical memory occupied by a program • Virtual memory – The larger memory space perceived by the program • Principle of Locality – A program tends to reference the same items – Even if same item not used, nearby items will often be referenced Virtual Memory Virtual Memory >> Physical Memory • Logical address space can be much larger than physical address space • Virtual memory – separation of user logical memory from physical memory. – Possible for a process to be larger than main memory – Allows additional processes since only part of each process needs to occupy main memory – Allows for more efficient process creation • Virtual memory can be implemented via: – Paging – Segmentation Paging • Divides memory into small pieces of memory (frames) • Logically divide program into same-‐size pieces (pages) • Use a page table to map the pages of the current process to the corresponding frames in memory Example A B C D Free Page Table 0 - 7 4 13 1 - 8 5 14 2 - 9 6 3 10 11 12 Segmentation 66
- 67. • Programmer sees memory as a set of multiple segments, each with a separate address space • Growing data structures easier to handle – OS can expand or shrink segment • Can alter the one segment without modifying other segments • Easy to share a library – Share one segment among processes • Easy memory protection – Can set values for the entire segment OS Policies • Implementation decisions: – Paging, Segmentation, or both? • Decisions about virtual memory: – Fetch Policy – When to bring a page in – Placement – Where to put it – Replacement – What to remove to make room for a new page – Resident Set Management – How many pages to keep in memory – Cleaning Policy – When to write a page to disk – Load Control – How many processes to keep in memory Paging Operation • Page Hit -‐ Page is present in memory • Page Fault – Page not in memory (Page marked as not present) • Handling a Page Fault – CPU determines page isn’t in memory – Interrupts the program, starts OS page fault handler – OS verifies the reference is valid but not in memory – Swap out a page if needed – Read referenced page from disk – Update page table entry – Resume interrupted process (or possible switch to another process) Page Table Bits 67
- 68. • Valid-‐invalid bit – Indicates if the page is a valid part of the process – Prevents a process accessing an erroneous page • Referenced bit – Indicates that the page has been read – Useful for implementing page replacement policies • Modified bit – Indicates that the page has been written – Must be written back on disc before replacing. Policies • Fetch Policy – When to bring a page into memory – Demand Paging – Load the page when a process tries to reference it • Less I/O needed • Less memory needed • Faster response required – Prepaging – Bring in pages that are likely to be used in the near future • Try to take advantage of disk characteristics • Hard to correctly guess which pages will be referenced • Placement Policy – Where to put the page – Best-‐fit, First-‐Fit, or Next-‐Fit can be used in with segmentation Basic Page Replacement • Which page to replace when a new page needs to be loaded • Steps: 1. Find the location of the desired page on disk. 2. Find a free frame: -‐ If there is a free frame, use it. -‐ If there is no free frame, use a page replacement algorithm to select a victim frame. 3. Read the desired page into the (newly) free frame. Update the page and frame tables. 4. Restart the process. 68
- 69. Replacement Policy • Frame Locking – Require a page to stay in memory, e.g. OS Kernel, Interrupt Handlers, Real-‐Time processes – Implemented by bit in data structures • Basic Algorithms – Optimal – First in, First out – Least recently used – Clock • Evaluate algorithm by running it on a memory references (reference string) and computing the number of page hits or faults on that string • Page hit rate – ratio of number of pages found in memory to the number of page references • Page fault rate – ratio of number of pages not found in memory to the number of page references • Want to maximise page hit rate (minimise page-‐fault rate) First-‐In-‐First-‐Out (FIFO) Algorithm • Replace the page in order of entering into the memory frame • Example FIFO example 69
- 70. • Reference string (sequence of virtual page number in the course of execution) : 1, 2, 3, 4, 1, 2, 5, 1, 2, 3, 4, 5 • Main memory initially empty • Calculate page faults (misses) for number of main memory frames (page capacity) = 1,2,3 and 4 70
- 71. Optimal Algorithm • Replace page that will not be used for longest period of time. • How do you know this? • Used for measuring how well your algorithm performs – Gives a standard for other algorithms • Example Optimal example • Reference string (sequence of virtual page number in the course of execution) : 1, 2, 3, 4, 1, 2, 5, 1, 2, 3, 4, 5 • Main memory initially empty • Calculate page faults (misses) for number of main memory frames (page capacity) = 4 71
- 72. Least Recently Used (LRU) Algorithm • Locate the page that hasn’t been referenced for the longest time • Nearly as good at optimal policy in many cases • Difficult to implement fully • Must keep a ordered list of pages or last accessed time for all pages • Counter implementation • Every page entry has a counter; every time page is referenced through this entry, copy the clock into the counter. • When a page needs to be changed, look at the counters to determine which are to change. • Example 1 Example 2 Reference string: 1, 2, 3, 4, 1, 2, 5, 1, 2, 3, 4, 5 Page hit ratio:??? 72
- 73. Thrashing • If a process does not have “enough” pages, the page-‐fault rate is very high. This leads to: – Low CPU utilization. – OS thinks that it needs to increase the degree of multiprogramming – Another process added to the system. – A process is busy swapping pages in and out ≡ Thrashing • Thrashing – Constantly needing to get pages off secondary storage – Happens if the OS throws out a piece of memory that is about to be used – Can happen if the program scans a long array – continuously referencing pages not used recently Resident Set Management • Resident Set – Those parts of the program being actively used – Remaining parts of program on disk • Size – How many pages to bring in – Smaller sets allow more processes in memory at one time – Larger sets reduce # of page faults for each process – Fixed Allocation • Each process is assigned a fixed number of pages – Variable Allocation • Allow the number of pages for a given process to vary over time Cleaning Policy • Use modify (dirty) bit to reduce overhead of page transfers – only modified pages are written to disk • Demand Cleaning – Write out when selected for replacement – Process may have to wait for two I/O operations before being able to proceed • Pre cleaning – Write out in bunches – Do it too soon, and the page may be modified again before being replaced – Works well with page buffering Load Control • Managing how many processes we keep in main memory • If too few, all processes may be blocked, may have a lot of swapping • Too many can lead to thrashing Summary • Virtual memory – larger memory space perceived by the program • OS should adapt a number of policy for virtual memory management • Page replacement completes separation between logical memory and physical memory 73
- 74. Virtual memory problem Ex. The following sequence of visual page number with virtual memory 2, 4, 3, 6, 7, 1, 3, 2, 6, 3, 5, 1, 2, 3. Assume the main memory is initially empty. Calculate the number of page fault and show the final contents for the following scenarios: a.) 3 frames (number of page capacity) with page replacement policy – optimal algorithm b.) 4 frames (number of page capacity) with page replacement policy – optimal algorithm c.) 3 frames (number of page capacity) with page replacement policy – Fist in first out algorithm d.) 4 frames (number of page capacity) with page replacement policy – Fist in first out algorithm e.) 3 frames (number of page capacity) with page replacement policy – Least recently used algorithm f.) 4 frames (number of page capacity) with page replacement policy – Least recently used algorithm 74
- 75. File Management File Management • One of the important services of OS • Objectives – Meet the data requirements of the user – Guarantee valid data – Optimize performance -‐ Both throughput and response time – Support a wide variety of devices – Minimize lost or destroyed data – Provide a standard set of I/O routines – Provide support for multiple users OS and File Operations • System calls to (for example) create files, delete files, move files, rename files, copy files, open files, close file, read files, write files. • Open (Fi) – search the directory structure on disk for entry Fi, and move the content of entry to memory. • Close (Fi) – move the content of entry Fi in memory to directory structure on disk. • Control other’s access to files • Able to move data between files • Back up and recover files Access Methods • Sequential Access read next write next reset no read after last write (rewrite) • Direct Access read n write n position to n read next write next rewrite n n = relative block number 75
- 76. Directory Structure • A collection of nodes containing information about all files. Both the directory structure and the files reside on disk. Backups of these two structures are kept on tapes. Directory Implementation • Linear list of file names with pointer to the data blocks. – simple to program – time-‐consuming to execute • Hash Table – linear list with hash data structure. – decreases directory search time – collisions – situations where two file names hash to the same location – fixed size File Sharing • Sharing of files on multi-‐user systems is desirable. • Sharing may be done through a protection scheme. • On distributed systems, files may be shared across a network. • Network File System (NFS) is a common distributed file-‐sharing method. Protection • File owner/creator should be able to control: – what can be done – by whom • Types of access – Read – Write – Execute – Append – Delete 76
- 77. – List Allocation Methods • An allocation method refers to how disk blocks are allocated for files • Three main methods: – Contiguous allocation – Linked allocation – Indexed allocation Contiguous Allocation • Each file occupies a set of contiguous blocks on the disk. • Simple – only starting location (block #) and length (number of blocks) are required. • Random access. • Wasteful of space (dynamic storage-‐ allocation problem). • Files cannot grow. Linked Allocation • Each file is a linked list of disk blocks: blocks may be scattered anywhere on the disk. • Simple – need only starting address • Free-‐space management system – no waste of space • No random access • Two file system implementation methods (mapping) that uses linked lists: – Linked chain of blocks – File-‐allocation table (FAT) File implementation -‐ Linked chain – Block to be accessed is the Qth block in the linked chain of blocks representing the file. – Displacement into block = R + File B 77
- 78. Linked chain -‐ advantages • Every block can be used, unlike a scheme that insists that every file is contiguous. • No space is lost due to external fragmentation (although there is fragmentation within the file, which can lead to performance issues). • The directory entry only has to store the first block. The rest of the file can be found from there. • The size of the file does not have to be known beforehand (unlike a contiguous file allocation scheme). • When more space is required for a file any block can be allocated (e.g. the first block on the free block list). • Random access is very slow (as it needs many disc reads to access a random point in the file). • The implementation is really only useful for sequential access. • Space is lost within each block due to the pointer. • The number of bytes is not a power of two. • This is not fatal, but does have an impact on performance. • Reliability could be a problem. • one corrupt block pointer and the whole system might become corrupted (e.g. writing over a block that belongs to another file). File implementation – FAT File-‐Allocation Table (FAT) This method removes the pointers from the data block and places them in a table, which is stored in memory. FAT -‐ advantages and disadvantages • Advantages – The entire block is available for data. – Random access can be implemented a lot more efficiently. – Although the pointers still have to be followed these are now in main memory and are thus much faster. • Disadvantages – The entire table must be in memory all the time. • For a large disc (with a large number of blocks) this can lead to a large table having to be kept in memory. 78
- 79. Indexed Allocation • Brings all pointers together into the index block. • Logical view. • Need index table • Random access • Dynamic access without external fragmentation, but have overhead of index block. • Indexed Allocation – Mapping – Mapping from logical to physical in a file of unbounded length (block size of 512 words). We need only 1 block for index table. – Linked scheme – Link blocks of index table (no limit on size). – Two-‐level index (maximum file size is 5123) Indexed Allocation – Mapping Efficiency and Performance • Efficiency dependent on: – disk allocation and directory algorithms – types of data kept in file’s directory entry • Performance – disk cache – separate section of main memory for frequently used blocks – free-‐behind and read-‐ ahead – techniques to optimize sequential access – improve PC performance by dedicating section of memory as virtual disk, or RAM disk. 79
- 80. Summary • File management is one of the important services of OS • Three main methods to allocate disk blocks to a file – Contiguous allocation – Linked allocation – Indexed allocation • Two common file system implementation methods that use linked lists are: – Linked chain of blocks – File-‐allocation table (FAT) 80
- 81. Exercise: Write algorithm and LMC program that accepts three values as input and output the largest number. Assume that all three input values are not equal. (For example if A, B, and C are three inputs numbers, then if output largest of these three number) 81
- 82. Ex2 Given the following processes with the following arrival and burst time Process Arrived Time Burst Time Calculate the AWT when RR scheduling P1 0 9 algorithm with quantum time = 10 is used P2 12 31 P3 20 24 P4 17 3 P5 35 22 P6 26 30 P7 27 2 82
- 83. Ex A main memory has a capacity of 128 words. Its cache uses a direct mapping. The cache memory has a capacity of 16 word organized into 4 word blocks store the address structure. Starting with on empty cache the following series of main memory address occurs: 25, 3, 26, 24, 88, 91, 17, 15, 1, 127, 9, 15, 8, 7, 9, 2, 5, 6 , 7, 99, 98, 1 Label each address references in the list as a hit or a miss and show the final contents of the cache. State the address structure. 83
- 84. Ex The following sequence of virtual page number is encountered in the course of execution on a computer with virtual memory: 6, 3, 1, 2, 3, 4, 3, 1, 7, 1, 3, 2, 7, 8 Calculate page faults when the number of main memory frames is 4. Assume that main memory is initially empty for the following replacements policies . -‐FIFO -‐LRU 84
- 85. Ex Consider four process P0, P1, P2, P3 and P4 are competing for resources A, B, and C. The following system state is given. Analyze the deadlock state of the system using Banker’s algorithm. Is the system is in safe state? Initial available: A B C 3 3 2 Resource Process Initial Allocation Max claim Need A B C A B C A B C P0 2 1 1 4 5 3 3 3 2 P1 1 1 0 3 2 2 2 1 2 P2 2 0 2 4 0 2 2 0 0 P3 2 1 1 2 2 2 0 1 1 P4 1 0 1 3 3 2 4 3 1 If the system is in safe condition, find out if this request will be granted P4 >> A B C 4 2 2 85
- 86. Ex Consider four process P0, P1, P2, P3 and P4 are competing for resources A, B, and C. Assume that we have the following initial availability of the resources and the initial state of allocations foe the processes. Initial availability: A B C 2 3 2 Process Initial state of allocate Request A B C A B C P0 1 1 0 0 0 0 P1 1 0 0 2 0 3 P2 3 0 2 1 1 0 P3 2 1 1 0 1 1 P4 0 0 2 5 3 1 Analyze the above request scenario with the deadlock detection technique as indicated in the 86