Optimizing Delta/Parquet Data Lakes for Apache Spark
0 likes1,051 views

Matthew Powers gave a talk on optimizing data lakes for Apache Spark. He discussed community goals like standardizing method signatures. He advocated for using Spark helper libraries like spark-daria and spark-fast-tests. Powers explained how to build better data lakes using techniques like partitioning data on relevant fields to skip data and speed up queries significantly. He also covered modern Scala libraries, incremental updates, compacting small files, and using Delta Lakes to more easily update partitioned data lakes over time.




















![Filtering unpartitioned lake
== Physical Plan ==
Project [first_name#12, last_name#13, country#14]
+- Filter (((isnotnull(country#14) && isnotnull(first_name#12)) && (country#14 = Russia)) &&
StartsWith(first_name#12, M))
+- FileScan csv [first_name#12,last_name#13,country#14]
Batched: false,
Format: CSV,
Location: InMemoryFileIndex[file:/Users/powers/Documents/tmp/blog_data/people.csv],
PartitionFilters: [],
PushedFilters: [IsNotNull(country), IsNotNull(first_name), EqualTo(country,Russia),
StringStartsWith(first_name,M)],
ReadSchema: struct
!22](https://image.slidesharecdn.com/052006matthewpowers-190506223039/85/Optimizing-Delta-Parquet-Data-Lakes-for-Apache-Spark-22-320.jpg)


![Filtering Partitioned data lake
!25
== Physical Plan ==
Project [first_name#74, last_name#75, country#76]
+- Filter (isnotnull(first_name#74) && StartsWith(first_name#74, M))
+- FileScan csv [first_name#74,last_name#75,country#76]
Batched: false,
Format: CSV,
Location: InMemoryFileIndex[file:/Users/powers/Documents/tmp/blog_data/partitioned_lake],
PartitionCount: 1,
PartitionFilters: [isnotnull(country#76), (country#76 = Russia)],
PushedFilters: [IsNotNull(first_name), StringStartsWith(first_name,M)],
ReadSchema: struct](https://image.slidesharecdn.com/052006matthewpowers-190506223039/85/Optimizing-Delta-Parquet-Data-Lakes-for-Apache-Spark-25-320.jpg)
![Comparing physical plans
!26
Unpartitioned
Project [first_name#12, last_name#13, country#14]
+- Filter (((isnotnull(country#14) && isnotnull(first_name#12))
&& (country#14 = Russia)) && StartsWith(first_name#12, M))
+- FileScan csv [first_name#12,last_name#13,country#14]
Batched: false,
Format: CSV,
Location: InMemoryFileIndex[….],
PartitionFilters: [],
PushedFilters: [IsNotNull(country), IsNotNull(first_name),
EqualTo(country,Russia), StringStartsWith(first_name,M)],
ReadSchema: struct
Partitioned
Project [first_name#74, last_name#75, country#76]
+- Filter (isnotnull(first_name#74) && StartsWith(first_name#74, M))
+- FileScan csv [first_name#74, last_name#75, country#76]
Batched: false,
Format: CSV,
Location: InMemoryFileIndex[…],
PartitionCount: 1,
PartitionFilters: [isnotnull(country#76), (country#76 = Russia)],
PushedFilters: [IsNotNull(first_name),
StringStartsWith(first_name,M)],
ReadSchema: struct](https://image.slidesharecdn.com/052006matthewpowers-190506223039/85/Optimizing-Delta-Parquet-Data-Lakes-for-Apache-Spark-26-320.jpg)









Optimizing Delta/Parquet Data Lakes for Apache Spark
- 1. WIFI SSID:SparkAISummit | Password: UnifiedAnalytics
- 2. Matthew Powers, Prognos Optimizing data lakes for Apache Spark #UnifiedAnalytics #SparkAISummit
- 3. About !3 But what about those poor data scientists that work with gzipped CSV lakes 😱
- 4. What you will get from this talk… • Motivation to write Spark open source code • Practical knowledge to build better data lakes !4
- 5. Agenda • Community goals • Spark open source • Modern Scala libs • Parquet lakes • Incremental updates & small files • Partitioned lakes • Delta lakes !5
- 6. Loved by most !6 Dreaded by some Source: 2019 Stackoverflow survey
- 7. Community goals • Passionate about community unification (standardization of method signatures) • Need to find optimal scalafmt settings • Strongly dislike UDFs • Spark tooling? !7
- 8. Spark helper libraries !8 spark-daria (Scala) quinn (PySpark)
- 11. Modern Scala libs !11 uTest Mill Build Tool
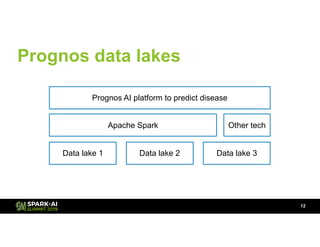
- 12. Prognos data lakes !12 Data lake 2Data lake 1 Data lake 3 Apache Spark Prognos AI platform to predict disease Other tech
- 13. TL;DR • 1 GB files • No nested directories !13
- 14. Small file problem • Incrementally updating a lake will create a lot of small files • We can store data like this so it’s easy to compact !14
- 15. Suppose we have a CSV data lake • CSV data lake is constantly being updated • Want to convert it to a Parquet data lake • Want incremental updates every hour !15
- 17. Compacting small files !17 10,000 incremental files and 166GB of data
- 19. !19
- 20. Why partition data lakes? • Data skipping • Massively improve query performance • I’ve seen queries run 50-100 times faster on partitioned lakes !20
- 21. Sample data !21
- 22. Filtering unpartitioned lake == Physical Plan == Project [first_name#12, last_name#13, country#14] +- Filter (((isnotnull(country#14) && isnotnull(first_name#12)) && (country#14 = Russia)) && StartsWith(first_name#12, M)) +- FileScan csv [first_name#12,last_name#13,country#14] Batched: false, Format: CSV, Location: InMemoryFileIndex[file:/Users/powers/Documents/tmp/blog_data/people.csv], PartitionFilters: [], PushedFilters: [IsNotNull(country), IsNotNull(first_name), EqualTo(country,Russia), StringStartsWith(first_name,M)], ReadSchema: struct !22
- 23. Partitioning the data lake !23
- 24. Partitioned lake on disk !24
- 25. Filtering Partitioned data lake !25 == Physical Plan == Project [first_name#74, last_name#75, country#76] +- Filter (isnotnull(first_name#74) && StartsWith(first_name#74, M)) +- FileScan csv [first_name#74,last_name#75,country#76] Batched: false, Format: CSV, Location: InMemoryFileIndex[file:/Users/powers/Documents/tmp/blog_data/partitioned_lake], PartitionCount: 1, PartitionFilters: [isnotnull(country#76), (country#76 = Russia)], PushedFilters: [IsNotNull(first_name), StringStartsWith(first_name,M)], ReadSchema: struct
- 26. Comparing physical plans !26 Unpartitioned Project [first_name#12, last_name#13, country#14] +- Filter (((isnotnull(country#14) && isnotnull(first_name#12)) && (country#14 = Russia)) && StartsWith(first_name#12, M)) +- FileScan csv [first_name#12,last_name#13,country#14] Batched: false, Format: CSV, Location: InMemoryFileIndex[….], PartitionFilters: [], PushedFilters: [IsNotNull(country), IsNotNull(first_name), EqualTo(country,Russia), StringStartsWith(first_name,M)], ReadSchema: struct Partitioned Project [first_name#74, last_name#75, country#76] +- Filter (isnotnull(first_name#74) && StartsWith(first_name#74, M)) +- FileScan csv [first_name#74, last_name#75, country#76] Batched: false, Format: CSV, Location: InMemoryFileIndex[…], PartitionCount: 1, PartitionFilters: [isnotnull(country#76), (country#76 = Russia)], PushedFilters: [IsNotNull(first_name), StringStartsWith(first_name,M)], ReadSchema: struct
- 27. Directly grabbing the partitions is faster !27
- 28. Real partitioned data lake • Updates every 3 hours • Has 5 million files • 15,000 files are being added every day • Still great for a lot of queries !28
- 29. Creating partitioned lakes (1/3) !29
- 30. Creating partitioned lakes (2/3) !30
- 31. Creating partitioned lakes (3/3) !31
- 33. Incrementally updating partitioned lakes • Small file problem grows quickly • Compaction is hard • Not sure of any automated Parquet compaction algos !33
- 34. What talk should I give next? • Best practices for the Spark community • Ditching SBT for the Mill build tool • Testing Spark code • Running Spark Scala code in PySpark !34
- 35. DON’T FORGET TO RATE AND REVIEW THE SESSIONS SEARCH SPARK + AI SUMMIT