Optimizing your SparkML pipelines using the latest features in Spark 2.3
Download as PPTX, PDF3 likes1,076 views

The document discusses optimizing Spark machine learning pipelines. It describes using parallel model evaluation to speed up hyperparameter tuning by training multiple models simultaneously. This reduces the time spent on cross-validation for hyperparameter selection. The document also discusses optimizing tuning for pipeline models by treating the pipeline as a directed acyclic graph and parallelizing the fitting in breadth-first order to avoid duplicating work where possible.






















































Optimizing your SparkML pipelines using the latest features in Spark 2.3
- 1. Optimizing your SparkML pipelines using the latest features in Spark 2.3 IBM Center for Open-Source Data & AI Technologies (http://codait.org) DBG / June 5, 2018 / © 2018 IBM Corporation
- 2. Open Source @ IBM Center for Open Source Data & AI Technologies (CODAIT) Model Tuning in Spark PySpark Vectorized UDFs Q&A Agenda Speakers 2May 17, 2018 / © 2018 IBM Corporation BRYAN CUTLER Software Engineer, IBM CODAIT Software Engineer, IBM CODAIT Apache Spark committer Apache Arrow committer Python, Machine Learning OSS @BryanCutler on Github https://BryanCutler.github.io May 17, 2018 / © 2018 IBM Corporation VIJAY BOMMIREDDIPALLI Program Director - CODAIT: Center for Open Source Data & AI Technologies IBM Digital Business Group [email protected] @vjbytes http://codait.org
- 3. 3 IBM’s history of strong AI leadership 1997: Deep Blue • Deep Blue became the first machine to beat a world chess champion in tournament play 2011: Jeopardy! • Watson beat two top Jeopardy! champions 1968, 2001: A Space Odyssey • IBM was a technical advisor • HAL is “the latest in machine intelligence” 2018: Open Tech, AI & emerging standards • New IBM centers of gravity for AI • OS projects increasing exponentially • Emerging global standards in AI May 17, 2018 / © 2018 IBM CorporationMay 17, 2018 / © 2018 IBM Corporation
- 4. Center for Open Source Data and AI Technologies CODAIT codait.org May 17, 2018 / © 2018 IBM Corporation codait (French) = coder/coded https://m.interglot.com/fr/en/codait CODAIT aims to make AI solutions dramatically easier to create, deploy, and manage in the enterprise Relaunch of the Spark Technology Center (STC) to reflect expanded mission 4
- 5. CODAIT by the numb3rs CODAIT codait.org May 17, 2018 / © 2018 IBM Corporation codait (French) = coder/coded https://m.interglot.com/fr/en/codait The team contributes to over 10 open source projects. These projects include - Spark, Tensorflow, Keras, SystemML, Arrow, Bahir, Toree, Livy, Zeppelin, R4ML, Stocator, Jupyter Enterprise Gateway 17 committers and many contributors in Apache projects- Spark, Arrow, systemML, Bahir, Toree, Livy Over 997 JIRAs and 55,000 lines of code committed to Apache Spark itself, and Over 65,000 LoC into SystemML • Established IBM as the number 1 contributor to Spark Machine Learning in Spark 2.0 release Over 25 product lines within IBM leveraging Apache Spark in some form or another. CODAIT engineers have interacted and interlocked with many of them. Speakers at over 100 conferences, MeetUps, un-conferences etc. 5 Spark code contribution growth by week
- 6. Center for Open Source Data and AI Technologies May 17, 2018 / © 2018 IBM Corporation codait (French) = coder/coded https://m.interglot.com/fr/en/codaitCode - Build and improve practical frameworks to enable more developers to realize immediate value (e.g. FfDL, Tensorflow Jupyter, Spark) Content – Showcase solutions to complex and real world AI problems Community – Bring developers and data scientists to engage with IBM (e.g. MAX) Improving Enterprise AI lifecycle in Open Source Gather Data Analyze Data Machine Learning Deep Learning Deploy Model Maintain Model Python Data Science Stack Fabric for Deep Learning (FfDL) Mleap + PFA Scikit-LearnPandas Apache Spark Apache Spark Jupyter Model Asset eXchange Keras + Tensorflow CODAIT codait.org 6
- 7. Fabric for Deep Learning https://github.com/IBM/FfDL May 17, 2018 / © 2018 IBM Corporation FfDL provides a scalable, resilient, and fault tolerant deep-learning framework FfDL Github Page https://github.com/IBM/FfDL FfDL dwOpen Page https://developer.ibm.com/code/open/projects/fabri c-for-deep-learning-ffdl/ FfDL Announcement Blog http://developer.ibm.com/code/2018/03/20/fabric- for-deep-learning FfDL Technical Architecture Blog http://developer.ibm.com/code/2018/03/20/democr atize-ai-with-fabric-for-deep-learning Deep Learning as a Service within Watson Studio https://www.ibm.com/cloud/deep-learning Research paper: “Scalable Multi-Framework Management of Deep Learning Training Jobs” http://learningsys.org/nips17/assets/papers/paper_ 29.pdf • Fabric for Deep Learning or FfDL (pronounced as ‘fiddle’) is an open source project which aims at making Deep Learning easily accessible to the people it matters the most i.e. Data Scientists, and AI developers. • FfDL Provides a consistent way to deploy, train and visualize Deep Learning jobs across multiple frameworks like TensorFlow, Caffe, PyTorch, Keras etc. • FfDL is being developed in close collaboration with IBM Research and IBM Watson. It forms the core of Watson`s Deep Learning service in open source. FfDL 7
- 8. Jupyter Enterprise Gateway March 30 2018 / © 2018 IBM Corporation Jupyter Enterprise Gateway at IBM Code https://developer.ibm.com/code/openprojects/jupyter-enterprise-gateway/ Jupyter Enterprise Gateway source code at GitHub https://github.com/jupyter-incubator/enterprise_gateway Jupyter Enterprise Gateway Documentation http://jupyter-enterprise-gateway.readthedocs.io/en/latest/ 8 A lightweight, multi-tenant, scalable and secure gateway that enables Jupyter Notebooks to share resources across an Apache Spark or Kubernetes cluster for Enterprise/Cloud use cases Kernel Kernel Kernel Kernel Kernel KernelKernel
- 9. Fast data analysis and transformation are the prerequisite of ML/DL within the whole enterprise AI life cycle. Apache Spark answers it. 9 Apache Spark A unified analytics engine for large-scale data processing. Various IBM Cloud and Service products are dependent on or distribute Apache Spark: • IBM Analytics Engine • IBM Apache Spark service • IBM Spectrum Conductor • Apache Spark on IBM POWER • IBM Open Data Analytics for z/OS • IBM Watson Studio • IBM SQL Query • IBM Watson Machine Learning • IBM Db2 EventStore • IBM Explorys ….. many more Apache Spark Github page: https://github.com/apache/s park IBM Related blogs: https://developer.ibm.com/co de/category/spark/ May 17, 2018 / © 2018 IBM Corporation Gather Data Analyze Data Machine Learning Deep Learning Deploy Model Maintain Model Python Data Science Stack Fabric for Deep Learning (FfDL) Mleap + PFA Scikit-LearnPandas Apache Spark Apache Spark Jupyter Model Asset eXchange Keras + Tensorflow
- 10. CODAIT: Enabling End-to-End AI in the Enterprise 10May 17, 2018 / © 2018 IBM Corporation Gather Data Analyze Data Machine Learning Deep Learning Deploy Model Maintain Model Python Data Science Stack Fabric for Deep Learning (FfDL) Mleap + PFA Scikit-LearnPandas Apache Spark Apache Spark Jupyter Model Asset eXchange Keras + Tensorflow
- 11. What’s next in this talk … Take a deeper look into: • Model Tuning in Spark • Scaling Model Tuning • Optimizing Pipelines • PySpark Vectorized UDFs • Apache Arrow • Using in a Pipeline DBG / June 5, 2018 / © 2018 IBM Corporation
- 12. Model Tuning in Spark DBG / June 5, 2018 / © 2018 IBM Corporation
- 13. Model selection: workflow within a workflow Model Tuning in Spark DBG / June 5, 2018 / © 2018 IBM Corporation Ingest Data Processing Feature Engineering Model Selection Final Model Candidate models Train Evaluate Adjust
- 14. Pipeline cross-validation Model Tuning in Spark DBG / June 5, 2018 / © 2018 IBM Corporation Tokenizer CountVectorizer LogisticRegression Spark ML Pipeline # features: 10 # features: 100 regParam: 0.001 regParam: 0.1 Parameters
- 15. Pipeline cross-validation Model Tuning in Spark DBG / June 5, 2018 / © 2018 IBM Corporation # features: 10 # features: 100 regParam:0 .001 regParam: 0.1 Tokenizer CountVectorizer LogisticRegression
- 16. Pipeline cross-validation Model Tuning in Spark DBG / June 5, 2018 / © 2018 IBM Corporation Tokenizer CountVectorizer # features: 10 LogisticRegression regParam: 0.001 # features: 10 Tokenizer CountVectorizer # features: 10 LogisticRegression regParam: 0.1 Tokenizer CountVectorizer # features: 100 LogisticRegression regParam: 0.001 Tokenizer CountVectorizer # features: 100 LogisticRegression regParam: 0.1 # features: 100 regParam:0 .001 regParam: 0.1
- 17. Cross-validation is expensive! DBG / June 5, 2018 / © 2018 IBM Corporation Model Tuning in Spark • 5 x 5 x 5 hyperparameters = 125 pipelines • ... across 4 machine learning models = 500 • If training & evaluation does not fully utilize available cluster resources then that waste is compounded for each model Based on XKCD comic: https://xkcd.com/303/ & https://github.com/mislavcimpersak/xkcd-excuse-generator
- 18. Parallel model evaluation DBG / June 5, 2018 / © 2018 IBM Corporation Scaling Model Tuning • Added in SPARK-19357 and SPARK- 21911 (PySpark) • Parallelism parameter governs the maximum # models to be trained at once
- 19. Parallel model evaluation Scaling Model Tuning DBG / June 5, 2018 / © 2018 IBM Corporation Tokenizer CountVectorizer # features: 10 LogisticRegression regParam: 0.001 # features: 10 Tokenizer CountVectorizer # features: 10 LogisticRegression regParam: 0.1 Tokenizer CountVectorizer # features: 100 LogisticRegression regParam: 0.001 Tokenizer CountVectorizer # features: 100 LogisticRegression regParam: 0.1 # features: 100 regParam:0 .001 regParam: 0.1
- 20. Parallel model evaluation Scaling Model Tuning DBG / June 5, 2018 / © 2018 IBM Corporation Tokenizer CountVectorizer # features: 10 LogisticRegression regParam: 0.001 # features: 10 Tokenizer CountVectorizer # features: 10 LogisticRegression regParam: 0.1 Tokenizer CountVectorizer # features: 100 LogisticRegression regParam: 0.001 Tokenizer CountVectorizer # features: 100 LogisticRegression regParam: 0.1 # features: 100 regParam:0 .001 regParam: 0.1
- 21. Parallel model evaluation Scaling Model Tuning DBG / June 5, 2018 / © 2018 IBM Corporation Tokenizer CountVectorizer # features: 10 LogisticRegression regParam: 0.001 # features: 10 Tokenizer CountVectorizer # features: 10 LogisticRegression regParam: 0.1 Tokenizer CountVectorizer # features: 100 LogisticRegression regParam: 0.001 Tokenizer CountVectorizer # features: 100 LogisticRegression regParam: 0.1 # features: 100 regParam:0 .001 regParam: 0.1
- 22. Parallel model evaluation Scaling Model Tuning DBG / June 5, 2018 / © 2018 IBM Corporation Tokenizer CountVectorizer # features: 10 LogisticRegression regParam: 0.001 # features: 10 Tokenizer CountVectorizer # features: 10 LogisticRegression regParam: 0.1 Tokenizer CountVectorizer # features: 100 LogisticRegression regParam: 0.001 Tokenizer CountVectorizer # features: 100 LogisticRegression regParam: 0.1 # features: 100 regParam:0 .001 regParam: 0.1
- 23. Parallel model evaluation DBG / June 5, 2018 / © 2018 IBM Corporation Scaling Model Tuning
- 24. Implementation considerations DBG / June 5, 2018 / © 2018 IBM Corporation Scaling Model Tuning • Parallelism parameter sets the size of threadpool under the hood • Dedicated ExecutionContext created to avoid deadlocks with using the default threadpool • Used Futures instead of parallel collections – more flexible • Model-specific parallel fitting implementations not supported • SPARK-22126
- 25. Performance tests DBG / June 5, 2018 / © 2018 IBM Corporation Scaling Model Tuning • Compared parallel CV to serial CV with varying number of samples • Simple LogisticRegression with regParam and fitIntercept; parameter grid size 12 • Measure elapsed time for cross-validation • Data size: 100,000 -> 5,000,000 • Number features: 10 • Number partitions: 10 • Number CV folds: 5 • Parallelism: 3 • Standalone cluster with 30 cores
- 26. Results DBG / June 5, 2018 / © 2018 IBM Corporation Scaling Model Tuning • ±2.4x speedup • Stays roughly constant as # samples increases
- 27. Best practices DBG / June 5, 2018 / © 2018 IBM Corporation Scaling Model Tuning • Simple integer parameter is the only thing you can set (for now) • Too low => under-utilize resources • Too high => could lead to memory issues or overloading cluster • Rough rule: # cores / # partitions • But depends on data and model sizes • Mid-sized cluster probably <= 10
- 28. Optimizing Tuning for Pipeline Models DBG / June 5, 2018 / © 2018 IBM Corporation
- 29. Challenges DBG / June 5, 2018 / © 2018 IBM Corporation Optimizing Tuning for Pipeline Models • Multi-stage, complex pipelines • Parameter grid with hyperparameters from different stages • Easy to have huge number of candidate parameter combinations • Model parallelism helps, but can we do better?
- 30. End up Duplicating Work DBG / June 5, 2018 / © 2018 IBM Corporation Optimizing Tuning for Pipeline Models • Each Pipeline treated independently • Depending on parameter grid and pipeline stages • Fit the same model multiple times • Perform same transformations multiple times
- 31. Optimize with a DAG DBG / June 5, 2018 / © 2018 IBM Corporation Optimizing Tuning for Pipeline Models • A node is an estimator/transformer with a set of hyperparameters • A path in the graph is a single pipeline model Tokenizer Count Vectorizer nfeat=10 Count Vectorizer nfeat=100 LR reg=0.1 LR reg=0.01 LR reg=0.1 LR reg=0.01
- 32. Parallelize in breadth-first order DBG / June 5, 2018 / © 2018 IBM Corporation Optimizing Tuning for Pipeline Models • Example with parallelism parameter set to 2 • Tokenizer is only a transform, proceed to fit CountVectorizer nodes Tokenizer Count Vectorizer nfeat=10 Count Vectorizer nfeat=100 LR reg=0.1 LR reg=0.01 LR reg=0.1 LR reg=0.01
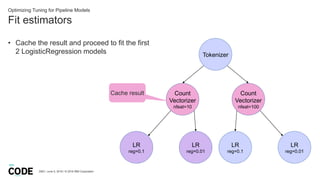
- 33. Fit estimators DBG / June 5, 2018 / © 2018 IBM Corporation Optimizing Tuning for Pipeline Models • Cache the result and proceed to fit the first 2 LogisticRegression models Tokenizer Count Vectorizer nfeat=10 Count Vectorizer nfeat=100 LR reg=0.1 LR reg=0.01 LR reg=0.1 LR reg=0.01 Cache result
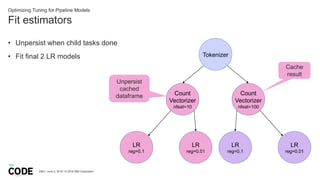
- 34. Fit estimators DBG / June 5, 2018 / © 2018 IBM Corporation Optimizing Tuning for Pipeline Models • Unpersist when child tasks done • Fit final 2 LR models Tokenizer Count Vectorizer nfeat=10 Count Vectorizer nfeat=100 LR reg=0.1 LR reg=0.01 LR reg=0.1 LR reg=0.01 Unpersist cached dataframe Cache result
- 35. Fit estimators DBG / June 5, 2018 / © 2018 IBM Corporation Optimizing Tuning for Pipeline Models • All 4 LR models fitted Tokenizer Count Vectorizer nfeat=10 Count Vectorizer nfeat=100 LR reg=0.1 LR reg=0.01 LR reg=0.1 LR reg=0.01 Unpersist cached dataframe
- 36. Evaluate models DBG / June 5, 2018 / © 2018 IBM Corporation Optimizing Tuning for Pipeline Models • Evaluate models using similar method • CountVectorizerModel is now a transformer • Cache transform result Tokenizer CVModel nfeat=10 CVModel nfeat=100 LRModel reg=0.1 LRModel reg=0.01 LRModel reg=0.1 LRModel reg=0.01 Cache, Unpersist when done
- 37. Evaluate models DBG / June 5, 2018 / © 2018 IBM Corporation Optimizing Tuning for Pipeline Models • All models evaluated for this fold Tokenizer CVModel nfeat=10 CVModel nfeat=100 LRModel reg=0.1 LRModel reg=0.01 LRModel reg=0.1 LRModel reg=0.01 Cache, unpersist when done Metrics: 0.62 0.62 0.72 0.66
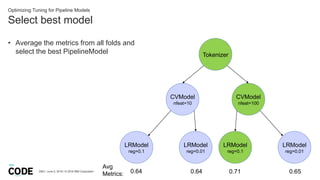
- 38. Select best model DBG / June 5, 2018 / © 2018 IBM Corporation Optimizing Tuning for Pipeline Models • Average the metrics from all folds and select the best PipelineModel Tokenizer CVModel nfeat=10 CVModel nfeat=100 LRModel reg=0.1 LRModel reg=0.01 LRModel reg=0.1 LRModel reg=0.01 Avg Metrics: 0.64 0.64 0.71 0.65
- 39. Performance tests DBG / June 5, 2018 / © 2018 IBM Corporation Optimizing Tuning for Pipeline Models • Compared to Standard Spark CV with parallelism enabled • Pipeline: MinMaxScaler → PCA → LinearRegression • Measure elapsed time for cross-validation varying size of parameter grid from 36 to 80 models to evaluate • Data size: 1,000,000 • Number features: 50 • Number partitions: 16 • Number CV folds: 4 • Parallelism: 3 • Standalone cluster with 30 cores
- 40. Results DBG / June 5, 2018 / © 2018 IBM Corporation Optimizing Tuning for Pipeline Models • Up to 3.25x speedup • Increases with more models … • … and more complex pipelines • Check out: https://github.com/BryanCutler/PipelineTuning Experimental! • Watch SPARK-19071 0 200 400 600 800 1000 1200 36 48 60 80 # models Elapsed time for DAG CV vs Simple Parallel CV Parallel DAG Parallel
- 41. PySpark Vectorized UDFs with Apache Arrow DBG / June 5, 2018 / © 2018 IBM Corporation
- 42. Python in Big Data DBG / June 5, 2018 / © 2018 IBM Corporation Vectorized UDFs • Spark successful, partly because integration of tools that traditionally require separate systems • e.g. in the same system you can do SQL and ML • Most big data tools work on the JVM, but many people use Python for analytics and ML – how do we connect them? • Pickling, JSON, XML, Strings, etc. • Lots of serialization and data copying!!!
- 43. PySpark – Python Interface to Spark DBG / June 5, 2018 / © 2018 IBM Corporation Vectorized UDFs • Provides a wrapper around Spark App JVMs • Driver uses Py4J to run JVM commands • Workers start a Python process and pipe data to/from • Data is transferred in Pickle format, leads to double serialization costs • Spark DataFrames can avoid serialization by staying in the JVM • Achieve performance almost as good as pure Scala/Java • Running any custom Python code leads back to costly serialization
- 44. Worker 1 Worker N Driver Python App Worker Interaction DBG / June 5, 2018 / © 2018 IBM Corporation Vectorized UDFs socket Py4J pipe pipe
- 45. Wordcount with DataFrames (in JVM) DBG / June 5, 2018 / © 2018 IBM Corporation Vectorized UDFs df = sqlCtx.read.load(src) split_words = df.select(split(df.text, ’ ‘).alias("word_list")) words = split_words.select(explode(split_words.word_list).alias("word")) word_count = words.groupBy("word").count() word_count.write.format("parquet").save("wc.parquet") Fast as long as using built-in functions
- 46. Apache Arrow introduced in Spark 2.3 DBG / June 5, 2018 / © 2018 IBM Corporation Vectorized UDFs • Standard format to transfer data between systems • Impl: Java, C/C++, Python, Rust, JS • Optimized for fast data processing • Avoid costly serialization • Efficiently uses chunked array data • Helps Spark when transferring data between the JVM and a Python process • Particularly useful for Python UDFs, @pandas_udf
- 47. Arrow in Big Data DBG / June 5, 2018 / © 2018 IBM Corporation Vectorized UDFs Common data layer between systems * Logos trademarks of their respective projects
- 48. Apache Arrow Adoption DBG / June 5, 2018 / © 2018 IBM Corporation Vectorized UDFs @kstirman
- 49. Scalar Pandas UDF Example DBG / June 5, 2018 / © 2018 IBM Corporation Vectorized UDFs @pandas_udf("integer", PandasUDFType.SCALAR) def add_one(x): return x + 1
- 50. How a Python Worker Looks with Arrow DBG / June 5, 2018 / © 2018 IBM Corporation Vectorized UDFs
- 51. Pandas UDF vs. Standard UDF Performance DBG / June 5, 2018 / © 2018 IBM Corporation Vectorized UDFs *Source: https://databricks.com/blog/2017/10/30/introducing-vectorized-udfs-for-pyspark.html
- 52. Improved Tokenization with Spacy NLP python package https://spacy.io/ DBG / June 5, 2018 / © 2018 IBM Corporation Vectorized UDFs @pandas_udf(returnType=ArrayType(StringType())) def spacy_tokenize(input_series): import spacy # Just set `input_lang` to support non-English language tokenization!! nlp = spacy.load(input_lang) def tokenize_elem(elem): return map(lambda token: token.text, nlp(unicode(elem))) return input_series.apply(tokenize_elem)
- 53. Pandas UDF --> Pipeline Stage DBG / June 5, 2018 / © 2018 IBM Corporation Vectorized UDFs • With some boilerplate code, can wrap your UDF into a Spark ML pipeline stage • Then can use it in the with the rest of Spark ML framework • Kind of a pain! • Sparkling ML is an open-source project that extends Spark ML • Makes it easy to plugin your Pandas UDF to create a Python estimator/transformer, or • Plays nice with the rest of Spark ML • Repo at: https://github.com/sparklingpandas/sparklingml
- 54. Text Classification Pipeline Mixed Language ML Pipeline DBG / June 5, 2018 / © 2018 IBM Corporation Vectorized UDFs Spark ML Cross- Validation Spark SQL Spacy Tokenizer (Python) Count Vectorizer (JVM) Logistic Regression (JVM)
- 55. Call for Code inspires developers to solve pressing global problems with sustainable software solutions, delivering on their vast potential to do good. Bringing together NGOs, academic institutions, enterprises, and startup developers to compete build effective disaster mitigation solutions, with a focus on health and well-being. International Federation of Red Cross/Red Crescent, The American Red Cross, and the United Nations Office of Human Rights combine for the Call for Code Award to elevate the profile of developers. Award winners will receive long-term support through open source foundations, financial prizes, the opportunity to present their solution to leading VCs, and will deploy their solution through IBM’s Corporate Service Corps. Developers will jump-start their project with dedicated IBM Code Patterns, combined with optional enterprise technology to build projects over the course of three months. Judged by the world’s most renowned technologists, the grand prize will be presented in October at an Award Event. developer.ibm.com/callforcode
- 56. Thank you! codait.org github.com/BryanCutler developer.ibm.com/code http://github.com/codait DBG / June 5, 2018 / © 2018 IBM Corporation FfDL Try out DSX Local with Hortonworks Data Platform http://www.ibmbigdatahub.com/blog/exciting-data- science-experience-hortonworks-data-platform Sign up for IBM Cloud and try Watson Studio! https://datascience.ibm.com/ MAX
- 57. DBG / June 5, 2018 / © 2018 IBM Corporation
Editor's Notes
- #47: Arrow is an in memory columnar data format Format definition is language agnostic Have libraries implemented in several key languages with more coming
- #48: Looking at arrow from a high-level point of view, it’s not just for transferring data from java to python. Arrow can be a common way to bring together many different systems into the big data world, that might otherwise require a lot of specialized code to talk to the JVM. Also, an important feature of Arrow for non-Java applications is that it can read/write parquet, which is a standard big data file format.
- #51: Let’s look in detail of how a python worker processes a UDF with and without Arrow
- #53: Now that we have an efficient way to transfer data to/from python, it becomes more practical to start integrating some of the great packages available in python. Going back to the wordcount example, now we can create a pandas_udf that uses the python package spacy for NLP to do the tokenization, which will give us better tokenization with configurable languages. Here, the input is a pandas series of text documents. We use Pandas to apply the spacy tokenizer to each document, and return a pandas series of string arrays.
- #54: Taking this a step further, we will probably want to connect it into a ML pipeline. Currently all of the existing Spark MLlib stages are Java based, so this creates a multi-language pipeline. To make this less painful, it would be really great to have a simple way to plugin our Python code. Trying to hack up your own solution is difficult because it can be a lot of boilerplate code and it’s not always easy to work with the Spark ML framework. Fortunately, there is an os project called Sparkling ML. This is a library extension to Spark that adds additional estimators/transformers and allows you to easily write your own that will fit in nicely with rest of Spark ML. It also makes it easy to integrate a pure python stage into a standard Scala-based pipeline.
- #55: Once we have defined our spacy tokenization stage, we can use it to build a mixed language pipeline that fits right in with the rest of Spark. So we are then able to use Spark SQL to feed our pipeline and tune it with the existing CrossValidator.