Parallel Computing 2007: Overview
Download as PPT, PDF6 likes3,242 views

The document discusses parallel computing over the past 25 years and challenges for using multicore chips in the next decade. It aims to provide context to scale applications effectively to 32-1024 cores. Key challenges include expressing inherent application parallelism while enabling efficient mapping to hardware through programming models and runtime systems. Future work includes developing methods to restore lost parallelism information and tradeoffs between programming effort, generality and performance.
![Parallel Computing 2007: Overview February 26-March 1 2007 Geoffrey Fox Community Grids Laboratory Indiana University 505 N Morton Suite 224 Bloomington IN [email_address] http://grids.ucs.indiana.edu/ptliupages/presentations/PC2007/](https://image.slidesharecdn.com/parallel-computing-2007-overview-250/85/Parallel-Computing-2007-Overview-1-320.jpg)














































































































































































Ad
More Related Content
What's hot (20)
Viewers also liked (14)












Ad
Similar to Parallel Computing 2007: Overview (20)




















Ad
More from Geoffrey Fox (20)




















Recently uploaded (20)




















Parallel Computing 2007: Overview
- 1. Parallel Computing 2007: Overview February 26-March 1 2007 Geoffrey Fox Community Grids Laboratory Indiana University 505 N Morton Suite 224 Bloomington IN [email_address] http://grids.ucs.indiana.edu/ptliupages/presentations/PC2007/
- 2. Introduction These 4 lectures are designed to summarize the past 25 years of parallel computing research and practice in a way that gives context to the challenges of using multicore chips over the next ten years We will not discuss hardware architectures in any depth – only giving enough detail to understand software and application parallelization issues In general we will base discussion on study of applications rather than any particular hardware or software We will assume that we are interested in “good” performance on 32-1024 cores and we will call this scalable parallelism We will learn to define what “good” and scalable means!
- 3. Books For Lectures The Sourcebook of Parallel Computing, Edited by Jack Dongarra, Ian Foster, Geoffrey Fox, William Gropp, Ken Kennedy, Linda Torczon, Andy White, October 2002, 760 pages, ISBN 1-55860-871-0, Morgan Kaufmann Publishers. http://www.mkp.com/books_catalog/catalog.asp?ISBN=1-55860-871-0 If you want to use parallel machines one of many possibilities is: Parallel Programming with MPI , Peter S. Pacheco, Morgan Kaufmann, 1996. Book web page: http://fawlty.cs.usfca.edu/mpi/
- 4. Some Remarks My discussion may seem simplistic – however I suggest that a result is only likely to be generally true (or indeed generally false) if it is simple However I understand implementations of complicated problems are very hard and that this difficulty of turning general truths into practice is the dominant issue See http://www.connotea.org/user/crmc for references -- select tag oldies for venerable links; tags like MPI Applications Compiler have obvious significance
- 5. Job Mixes (on a Chip) Any computer (chip) will certainly run several different “processes” at the same time These processes may be totally independent, loosely coupled or strongly coupled Above we have jobs A B C D E and F with A consisting of 4 tightly coupled threads and D two A could be Photoshop with 4 way strongly coupled parallel image processing threads B Word, C Outlook, D Browser with separate loosely coupled layout and media decoding E Disk access and F desktop search monitoring files We are aiming at 32-1024 useful threads using significant fraction of CPU capability without saturating memory I/O etc. and without waiting “too much” on other threads A1 A2 A3 A4 C B E D1 D2 F
- 6. Three styles of “Jobs” Totally independent or nearly so (B C E F) – This used to be called embarrassingly parallel and is now pleasingly so This is preserve of job scheduling community and one gets efficiency by statistical mechanisms with (fair) assignment of jobs to cores “ Parameter Searches” generate this class but these are often not optimal way to search for “best parameters” “ Multiple users” of a server is an important class of this type No significant synchronization and/or communication latency constraints Loosely coupled (D) is “ Metaproblem ” with several components orchestrated with pipeline, dataflow or not very tight constraints This is preserve of Grid workflow or mashups Synchronization and/or communication latencies in millisecond to second or more range Tightly coupled (A) is classic parallel computing program with components synchronizing often and with tight timing constraints Synchronization and/or communication latencies around a microsecond A1 A2 A3 A4 C B E D1 D2 F
- 7. Data Parallelism in Algorithms Data-parallel algorithms exploit the parallelism inherent in many large data structures. A problem is an (identical) update algorithm applied to multiple points in data “array” Usually iterate over such “updates” Features of Data Parallelism Scalable parallelism -- can often get million or more way parallelism Hard to express when “geometry” irregular or dynamic Note data-parallel algorithms can be expressed by ALL parallel programming models ( Message Passing, HPF like, OpenMP like )
- 8. Functional Parallelism in Algorithms Coarse Grain Functional parallelism exploits the parallelism between the parts of many systems. Many pieces to work on many independent operations Example: Coarse grain Aeroelasticity (aircraft design) CFD(fluids) and CSM(structures) and others (acoustics, electromagnetics etc.) can be evaluated in parallel Analysis: Parallelism limited in size -- tens not millions Synchronization probably good as parallelism and decomposition natural from problem and usual way of writing software Workflow exploits functional parallelism NOT data parallelism
- 9. Structure(Architecture) of Applications Applications are metaproblems with a mix of components (aka coarse grain functional) and data parallelism Modules are decomposed into parts (data parallelism) and composed hierarchically into full applications.They can be the “ 10,000” separate programs (e.g. structures,CFD ..) used in design of aircraft the various filters used in Adobe Photoshop or Matlab image processing system the ocean-atmosphere components in integrated climate simulation The data-base or file system access of a data-intensive application the objects in a distributed Forces Modeling Event Driven Simulation
- 10. Motivating Task Identify the mix of applications on future clients and servers and produce the programming environment and runtime to support effective (aka scalable) use of 32-1024 cores If applications were pleasingly parallel or loosely coupled , then this is non trivial but straightforward It appears likely that closely coupled applications will be needed and here we have to have efficient parallel algorithms, express them in some fashion and support with low overhead runtime Of course one could gain by switching algorithms e.g. from a tricky to parallelize brand and bound to a loosely coupled genetic optimization algorithm These lectures are designed to capture current knowledge from parallel computing relevant to producing 32-1024 core scalable applications and associated software
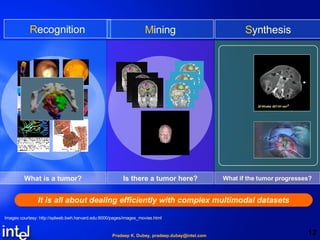
- 11. What is …? What if …? Is it …? R ecognition M ining S ynthesis Create a model instance RMS: Recognition Mining Synthesis Model-based multimodal recognition Find a model instance Model Real-time analytics on dynamic, unstructured, multimodal datasets Photo-realism and physics-based animation Model-less Real-time streaming and transactions on static – structured datasets Very limited realism Tomorrow Today
- 12. What is a tumor? Is there a tumor here? What if the tumor progresses? It is all about dealing efficiently with complex multimodal datasets R ecognition M ining S ynthesis Images courtesy: http://splweb.bwh.harvard.edu:8000/pages/images_movies.html
- 14. Why Parallel Computing is Hard Essentially all large applications can be parallelized but unfortunately The architecture of parallel computers bears modest resemblance to the architecture of applications Applications don’t tend to have hierarchical or shared memories and really don’t usually have memories in sense computers have (they have local state?) Essentially all significant conventionally coded software packages can not be parallelized Note parallel computing can be thought of as a map from an application through a model to a computer Parallel Computing Works because Mother Nature and Society (which we are simulating) are parallel Think of applications, software and computers as “ complex systems ” i.e. as collections of “time” dependent entities with connections Each is a Complex System S i where i represents “natural system”, theory, model, numerical formulation, software, runtime or computer Architecture corresponds to structure of complex system I intuitively prefer message passing as it naturally expresses connectivity
- 15. Structure of Complex Systems S natural application S theory S model S numerical S software S runtime S computer Note that the maps are typically not invertible and each stage loses information For example the C code representing many applications no longer implies the parallelism of “natural system” Parallelism implicit in natural system implied by a mix of run time and compile time information and may or may not be usable to get efficient execution One can develop some sort of theory to describe these mapping with all systems thought of as having a “space” and “time” Classic Von Neumann sequential model maps both space and time for the Application onto just time (=sequence) for the Computer map map map map map map S natural application S computer Time Space Time Space Map
- 16. Languages in Complex Systems Picture S natural application S theory S model S numerical S software S runtime S computer Parallel programming systems express S numerical S software with various tradeoffs i.e. They try to find ways of expressing application that preserves parallelism but still enables efficient map onto hardware We need most importantly correctness e.g. do not ignore data dependence in parallel loops Then we need efficiency e.g. do not incur unnecessary latency by many small messages They cay can use higher level concepts such as (data-parallel) arrays or functional representations of application They can annotate the software to add back the information lost in the mapping from natural application to software They can use run-time information to restore parallelism information These approaches trade-off ease of programming , generality, efficient execution etc. map map map map map map
- 17. Structure of Modern Java System: GridSphere Carol Song Purdue http://gridreliability.nist.gov/Workshop2/ReliabilityAssessmentSongPurdue.pdf
- 18. Another Java Code; Batik Scalable Vector Graphics SVG Browser A clean logic flow but we could find no good way to divide into its MVC (Model View Control) components due to (unnecessary) dependencies carried by links Spaghetti Java harder to parallelize than spaghetti Fortran
- 19. Are Applications Parallel? The general complex system is not parallelizable but in practice, complex systems that we want to represent in software are parallelizable (as nature and (some) systems/algorithms built by people are parallel) General graph of connections and dependencies such in GridSphere software typically has no significant parallelism (except inside a graph node) However systems to be simulated are built by replicating entities (mesh points, cores) and are naturally parallel Scalable parallelism requires a lot of “replicated entities” where we will use n (grain size) as number of entities n N proc divided by number of processors N proc Entities could be threads, particles, observations, mesh points, database records …. Important lesson from scientific applications: only requirement for efficient parallel computing is that grain size n be large and efficiency of implementation only depends on n plus hardware parameters
- 20. Seismic Simulation of Los Angeles Basin This is a (sophisticated) wave equation and you divide Los Angeles geometrically and assign roughly equal number of grid points to each processor Divide surface into 4 parts and assign calculation of waves in each part to a separate processor
- 21. Parallelizable Software Traditional software maps (in a simplistic view) everything into time and parallelizing it is hard as we don’t easily know which time (sequence) orderings are required and which are gratuitous Note parallelization is happy with lots of connections – we can simulate the long range interactions between N particles or the Internet , as these connections are complex but spatial It surprises me that there is not more interaction between parallel computing and software engineering Intuitively there ought to be some common principles as inter alia both are trying to avoid extraneous interconnections S natural application S computer Time Space Time Space Map
- 22. Potential in a Vacuum Filled Rectangular Box Consider the world’s simplest problem Find the electrostatic potential inside a box whose sides are at a given potential Set up a 16 by 16 Grid on which potential defined and which must satisfy Laplace’s Equation
- 23. Basic Sequential Algorithm Initialize the internal 14 by 14 mesh to anything you like and then apply for ever! This Complex System is just a 2D mesh with nearest neighbor connections New = ( Left + Right + Up + Down ) / 4 Up Down Left Right New
- 24. Update on the Mesh 14 by 14 Internal Mesh
- 25. Parallelism is Straightforward If one has 16 processors, then decompose geometrical area into 16 equal parts Each Processor updates 9 12 or 16 grid points independently
- 26. Communication is Needed Updating edge points in any processor requires communication of values from neighboring processor For instance, the processor holding green points requires red points
- 27. Communication Must be Reduced 4 by 4 regions in each processor 16 Green (Compute) and 16 Red (Communicate) Points 8 by 8 regions in each processor 64 Green and “just” 32 Red Points Communication is an edge effect Give each processor plenty of memory and increase region in each machine Large Problems Parallelize Best
- 28. Summary of Laplace Speed Up T P is execution time on P processors T 1 is sequential time Efficiency = Speed Up S / P (Number of Processors) Overhead f comm = (P T P - T 1 ) / T 1 = 1/ - 1 As T P linear in f comm , overhead effects tend to be additive In 2D Jacobi example f comm = t comm /( n t float ) n becomes n 1/d in d dimensions witH f comm = constant t comm /( n 1/d t float ) While efficiency takes approximate form 1 - t comm /( n t float ) valid when overhead is small As expected efficiency is < 1 corresponding to speedup being < P
- 29. All systems have various Dimensions
- 30. Parallel Processing in Society It’s all well known ……
- 32. Divide problem into parts; one part for each processor 8-person parallel processor
- 34. Amdahl’s Law of Parallel Processing Speedup S(N) is ratio Time(1 Processor)/Time(N Processors) ; we want S(N) ≥ 0.8 N Amdahl’s law said no problem could get a speedup greater than about 10 It is misleading as it was gotten by looking at small or non-parallelizable problems (such as existing software) For Hadrian’s wall S(N) satisfies our goal as long as l about 60 meters if l overlap = about 6 meters If l is roughly same size as l overlap then we have “ too many cooks spoil the broth syndrome ” One needs large problems to get good parallelism but only large problems need large scale parallelism
- 39. Typical modern application performance
- 40. Performance of Typical Science Code I FLASH Astrophysics code from DoE Center at Chicago Plotted as time as a function of number of nodes Scaled Speedup as constant grain size as number of nodes increases
- 41. Performance of Typical Science Code II FLASH Astrophysics code from DoE Center at Chicago on Blue Gene Note both communication and simulation time are independent of number of processors – again the scaled speedup scenario Communication Simulation
- 42. FLASH is a pretty serious code
- 43. Rich Dynamic Irregular Physics
- 44. FLASH Scaling at fixed total problem size Increasing Problem Size Rollover occurs at increasing number of processors as problem size increases
- 45. Back to Hadrian’s Wall
- 46. The Web is also just message passing Neural Network
- 47. 1984 Slide – today replace hypercube by cluster
- 50. Inside CPU or Inner Parallelism Between CPU’s Called Outer Parallelism
- 53. Now we discuss classes of application
- 54. “ Space-Time” Picture Data-parallel applications map spatial structure of problem on parallel structure of both CPU’s and memory However “left over” parallelism has to map into time on computer Data-parallel languages support this “ Internal” (to data chunk) application spatial dependence ( n degrees of freedom) maps into time on the computer Application Time Application Space t 0 t 1 t 2 t 3 t 4 Computer Time 4-way Parallel Computer (CPU’s) T 0 T 1 T 2 T 3 T 4
- 55. Data Parallel Time Dependence A simple form of data parallel applications are synchronous with all elements of the application space being evolved with essentially the same instructions Such applications are suitable for SIMD computers and run well on vector supercomputers (and GPUs but these are more general than just synchronous) However synchronous applications also run fine on MIMD machines SIMD CM-2 evolved to MIMD CM-5 with same data parallel language CMFortran The iterative solutions to Laplace’s equation are synchronous as are many full matrix algorithms Synchronization on MIMD machines is accomplished by messaging It is automatic on SIMD machines! Application Time Application Space Synchronous Identical evolution algorithms t 0 t 1 t 2 t 3 t 4
- 56. Local Messaging for Synchronization MPI_SENDRECV is typical primitive Processors do a send followed by a receive or a receive followed by a send In two stages (needed to avoid race conditions), one has a complete left shift Often follow by equivalent right shift, do get a complete exchange This logic guarantees correctly updated data is sent to processors that have their data at same simulation time ……… 8 Processors Application and Processor Time Application Space Communication Phase Compute Phase Communication Phase Compute Phase Communication Phase Compute Phase Communication Phase
- 57. Loosely Synchronous Applications This is most common large scale science and engineering and one has the traditional data parallelism but now each data point has in general a different update Comes from heterogeneity in problems that would be synchronous if homogeneous Time steps typically uniform but sometimes need to support variable time steps across application space – however ensure small time steps are t = (t 1 -t 0 )/Integer so subspaces with finer time steps do synchronize with full domain The time synchronization via messaging is still valid However one no longer load balances (ensure each processor does equal work in each time step) by putting equal number of points in each processor Load balancing although NP complete is in practice surprisingly easy Distinct evolution algorithms for each data point in each processor Application Time Application Space t 0 t 1 t 2 t 3 t 4
- 58. Irregular 2D Simulation -- Flow over an Airfoil The Laplace grid points become finite element mesh nodal points arranged as triangles filling space All the action (triangles) is near near wing boundary Use domain decomposition but no longer equal area as equal triangle count
- 59. Simulation of cosmological cluster (say 10 million stars ) Lots of work per star as very close together ( may need smaller time step) Little work per star as force changes slowly and can be well approximated by low order multipole expansion Heterogeneous Problems
- 60. Asynchronous Applications Here there is no natural universal ‘time’ as there is in science algorithms where an iteration number or Mother Nature’s time gives global synchronization Loose (zero) coupling or special features of application needed for successful parallelization In computer chess, the minimax scores at parent nodes provide multiple dynamic synchronization points Here there is no natural universal ‘time’ as there is in science algorithms where an iteration number or Mother Nature’s time gives global synchronization Loose (zero) coupling or special features of application needed for successful parallelization In computer chess, the minimax scores at parent nodes provide multiple dynamic synchronization points Application Time Application Space Application Space Application Time
- 61. Computer Chess Thread level parallelism unlike position evaluation parallelism used in other systems Competed with poor reliability and results in 1987 and 1988 ACM Computer Chess Championships Increasing search depth
- 62. Discrete Event Simulations These are familiar in military and circuit (system) simulations when one uses macroscopic approximations Also probably paradigm of most multiplayer Internet games/worlds Note Nature is perhaps synchronous when viewed quantum mechanically in terms of uniform fundamental elements (quarks and gluons etc.) It is loosely synchronous when considered in terms of particles and mesh points It is asynchronous when viewed in terms of tanks, people, arrows etc. Battle of Hastings
- 63. Dataflow This includes many data analysis and Image processing engines like AVS and Microsoft Robotics Studio Multidisciplinary science linkage as in Ocean Land and Atmospheric Structural, Acoustic, Aerodynamics, Engines, Control, Radar Signature, Optimization Either transmit all data (successive image processing), interface data (as in air flow – wing boundary) or trigger events (as in discrete event simulation) Use Web Service or Grid workflow in many eScience projects Often called functional parallelism with each linked function data parallel and typically these are large grain size and correspondingly low communication/calculation ratio and efficient distributed execution Fine grain dataflow has significant communication requirements Wing Airflow Radar Signature Engine Airflow Structural Analysis Noise Optimization Communication Bus Large Applications
- 64. Grid Workflow Datamining in Earth Science Indiana university work with Scripps Institute Web services controlled by workflow process real time data from ~70 GPS Sensors in Southern California NASA GPS Earthquake Streaming Data Support Transformations Data Checking Hidden Markov Datamining (JPL) Display (GIS) Real Time Archival
- 65. Grid Workflow Data Assimilation in Earth Science Grid services triggered by abnormal events and controlled by workflow process real time data from radar and high resolution simulations for tornado forecasts
- 66. Web 2.0 has Services of varied pedigree linked by Mashups – expect interesting developments as some of services run on multicore clients
- 67. Mashups are Workflow? http:// www.programmableweb.com/apis has currently (Feb 18 2007) 380 Web 2.0 APIs with GoogleMaps the most used in Mashups Many Academic and Commercial tools exist for both workflow and mashups. Can expect rapid progress from competition Must tolerate large latencies (10-1000 ms) in inter service links
- 68. Work/Dataflow and Parallel Computing I Decomposition is fundamental (and most difficult) issue in (generalized) data parallelism (including computer chess for example) One breaks a single application into multiple parts and carefully synchronize them so they reproduce original application Number and nature of parts typically reflects hardware on which application will run As parts are in some sense “artificial”, role of concepts like objects and services not so clear and also suggests different software models Reflecting microsecond (parallel computing) versus millisecond (distributed computing) latency difference
- 69. Work/Dataflow and Parallel Computing II Composition is one fundamental issue expressed as coarse grain dataflow or functional parallelism and addressed by workflow and mashups Now the parts are natural from the application and are often naturally distributed Task is to integrate existing parts into a new application Encapsulation, interoperability and other features of object and service oriented architectures are clearly important Presumably software environments tradeoff performance versus usability, functionality etc. and software with highest performance (lowest latency) will be hardest to use and maintain – correct? So one should match software environment used to integration performance requirements e.g. use services and workflow not language integration for loosely coupled applications
- 70. Google MapReduce Simplified Data Processing on Large Clusters http://labs.google.com/papers/mapreduce.html This is a dataflow model between services where services can do useful document oriented data parallel applications including reductions The decomposition of services onto cluster engines is automated The large I/O requirements of datasets changes efficiency analysis in favor of dataflow Services (count words in example) can obviously be extended to general parallel applications There are many alternatives to language expressing either dataflow and/or parallel operations and indeed one should support multiple languages in spirit of services
- 71. Other Application Classes Pipelining is a particular Dataflow topology Pleasingly parallel applications such as analyze the several billion independent events per year from the Large Hadron Collider LHC at CERN are staple Grid/workflow applications as is the associated master-worker or farming processing paradigm High latency unimportant as hidden by event processing time while as in all observational science the data is naturally distributed away from users and computing Note full data needs to be flowed between event filters Independent job scheduling is a Tetris style packing problem and can be handled by workflow technology
- 72. Event-based “Dataflow” This encompasses standard O/S event handling through enterprise publish-subscribe message bus handling for example e-commerce transactions The “ deltaflow ” of distributed data-parallel applications includes abstract events as in discrete event simulations Collaboration systems achieve consistency by exchanging change events of various styles Pixel changes for shared display and audio-video conferencing DOM changes for event-based document changes Event Broker
- 73. A small discussion of hardware
- 74. Blue Gene/L Complex System with replicated chips and a 3D toroidal interconnect
- 75. 1024 processors in full system with ten dimensional hypercube Interconnect 1987 MPP
- 76. Discussion of Memory Structure and Applications
- 77. Parallel Architecture I The entities of “computer” complex system are cores and memory Caches can be shared or private They can be buffers (memory) or cache They can be coherent or incoherent There can be different names : chip, modules, boards, racks for different levels of packaging The connection is by dataflow “vertically” from shared to private cores/caches Shared memory is a horizontal connection Dataflow Performance Bandwidth Latency Size Cache L3 Cache Main Memory L2 Cache Core Cache Cache L3 Cache Main Memory L2 Cache Core Cache Cache L3 Cache Main Memory L2 Cache Core Cache Cache L3 Cache Main Memory L2 Cache Core Cache Main Memory L2 Cache
- 78. Communication on Shared Memory Architecture On a shared Memory Machine a CPU is responsible for processing a decomposed chunk of data but not for storing it Nature of parallelism is identical to that for distributed memory machines but communication implicit as “just” access memory
- 79. GPU Coprocessor Architecture AMD adds a “data-parallel” engine to general CPU; this gives good performance as long as one can afford general purpose CPU to GPU transfer cost and GPU RAM to GPU compute core cost
- 80. IBM Cell Processor This supports pipelined (through 8 cores) or data parallel operations distributed on 8 SPE’s Applications running well on Cell or AMD GPU should run scalablyon future mainline multicore chips Focus on memory bandwidth key (dataflow not deltaflow)
- 81. Parallel Architecture II Multicore chips are of course a shared memory architecture and there are many sophisticated instances of this such as the 512 Itanium 2 chips in SGI Altix shared memory cluster Distributed memory systems have shared memory nodes linked by a messaging network Cache L3 Cache Main Memory L2 Cache Core Cache Cache L3 Cache Main Memory L2 Cache Core Cache Cache L3 Cache Main Memory L2 Cache Core Cache Cache L3 Cache Main Memory L2 Cache Core Cache Interconnection Network Dataflow Dataflow “ Deltaflow” or Events
- 82. Memory to CPU Information Flow Information is passed by dataflow from main memory (or cache ) to CPU i.e. all needed bits must be passed Information can be passed at essentially no cost by reference between different CPU’s (threads) of a shared memory machine One usually uses an owner computes rule in distributed memory machines so that one considers data “fixed” in each distributed node One passes only change events or “edge” data between nodes of a distributed memory machine Typically orders of magnitude less bandwidth required than for full dataflow Transported elements are red and edge/full grain size 0 as grain size increases
- 83. Cache and Distributed Memory Analogues Dataflow performance sensitive to CPU operation per data point – often maximized by preserving locality Good use of cache often achieved by blocking data of problem and cycling through blocks At any one time one (out of 105 in diagram) block being “updated” Deltaflow performance depends on CPU operations per edge compared to CPU operations per grain One puts one block on each of 105 CPU’s of parallel computer and updates simultaneously This works “more often” than cache optimization as works in case with low CPU update count per data point but these algorithms also have low edge/grain size ratios Cache L3 Cache L2 Cache Core Cache Main Memory
- 84. Space Time Structure of a Hierarchical Multicomputer
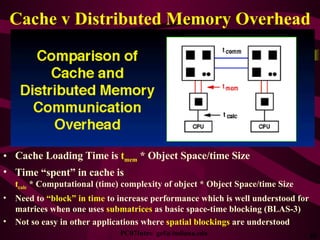
- 85. Cache v Distributed Memory Overhead Cache Loading Time is t mem * Object Space/time Size Time “spent” in cache is t calc * Computational (time) complexity of object * Object Space/time Size Need to “block” in time to increase performance which is well understood for matrices when one uses submatrices as basic space-time blocking (BLAS-3) Not so easy in other applications where spatial blockings are understood
- 86. Space-Time Decompositions for the parallel one dimensional wave equation Standard Parallel Computing Choice
- 87. Amdahl’s misleading law I Amdahl’s law notes that if the sequential portion of a program is x%, then the maximum achievable speedup is 100/x, however many parallel CPU’s one uses. This is realistic as many software implementations have fixed sequential parts; however large (science and engineering) problems do not have large sequential components and so Amdahl’s law really says “ Proper Parallel Programming is too hard ”
- 88. Amdahl’s misleading law II Let N = n N proc be number of points in some problem Consider trivial exemplar code X= 0; Sequential for( i = 0 to N) { X= X+A( i ) } Parallel Where parallel sum distributes n of the A(i) on each processor and takes time O( n ) without overhead to find partial sums Sums would be combined at end taking a time O( logN proc ) So we find “sequential” O( 1 ) + O( logN proc ) While parallel component is O( n ) So as problem size increases ( n increases) the sequential component does not keep a fixed percentage but declines Almost by definition intrinsic sequential component cannot depend on problem size So Amdahl’s law is in principle unimportant
- 89. Hierarchical Algorithms meet Amdahl Consider a typical multigrid algorithm where one successively halves the resolution at each step Assume there are n mesh points per process at finest resolution and problem two dimensional so communication time complexity is c n At finest mesh fractional communication overhead c / n Total parallel complexity is n (1 + 1/2 + 1/4 ….) .. +1 = 2 n and total serial complexity is 2 n N proc The total communication time is c n (1+1/ 2 + 1/2 + 1/2 2 + ..) = 3.4 c n So the communication overhead is increased by 70% but in scalable fashion as it still only depends on grain size and tends to zero at large grain size 0 1 2 3 Processors Level 4 Mesh Level 3 Mesh Level 2 Mesh Level 1 Mesh Level 0 Mesh
- 90. A Discussion of Software Models
- 91. Programming Paradigms At a very high level, there are three broad classes of parallelism Coarse grain functional parallelism typified by workflow and often used to build composite “metaproblems” whose parts are also parallel This area has several good solutions getting better Large Scale loosely synchronous data parallelism where dynamic irregular work has clear synchronization points Fine grain functional parallelism as used in search algorithms which are often data parallel (over choices) but don’t have universal synchronization points Pleasingly parallel applications can be considered special cases of functional parallelism I strongly recommend “ unbundling ” support of these models! Each is complicated enough on its own
- 92. Parallel Software Paradigms I: Workflow Workflow supports the integration (orchestration) of existing separate services (programs) with a runtime supporting inter-service messaging, fault handling etc. Subtleties such as distributed messaging and control needed for performance In general, a given paradigm can be realized with several different ways of expressing it and supported by different runtimes One needs to discuss in general Expression, Application structure and Runtime Grid or Web Service workflow can be expressed as: Graphical User Interface allowing user to choose from a library of services, specify properties and service linkage XML specification as in BPEL Python (Grid), PHP (Mashup) or JavaScript scripting
- 93. The Marine Corps Lack of Programming Paradigm Library Model One could assume that parallel computing is “just too hard for real people” and assume that we use a Marine Corps of programmers to build as libraries excellent parallel implementations of “all” core capabilities e.g. the primitives identified in the Intel application analysis e.g. the primitives supported in Google MapReduce , HPF , PeakStream , Microsoft Data Parallel .NET etc. These primitives are orchestrated (linked together) by overall frameworks such as workflow or mashups The Marine Corps probably is content with efficient rather than easy to use programming models
- 94. Parallel Software Paradigms II: Component Parallel and Program Parallel We generalize workflow model to the component parallel paradigm where one explicitly programs the different parts of a parallel application with the linkage either specified externally as in workflow or in components themselves as in most other component parallel approaches In the two-level Grid/Web Service programming model , one programs each individual service and then separately programs their interaction; this is an example of a component parallel paradigm In the program parallel paradigm, one writes a single program to describe the whole application and some combination of compiler and runtime breaks up the program into the multiple parts that execute in parallel
- 95. Parallel Software Paradigms III: Component Parallel and Program Parallel continued In a single virtual machine as in single shared memory machine with possible multi-core chips, standard languages are both program parallel and component parallel as a single multi-threaded program explicitly defines the code and synchronization for parallel threads We will consider programming of threads as component parallel Note that a program parallel approach will often call a built in runtime library written in component parallel fashion A parallelizing compiler could call an MPI library routine Could perhaps better call “ Program Parallel ” as “ Implicitly Parallel ” and “ Component Parallel ” as “ Explicitly Parallel ”
- 96. Parallel Software Paradigms IV: Component Parallel and Program Parallel continued Program Parallel approaches include Data structure parallel as in Google MapReduce , HPF (High Performance Fortran), HPCS (High-Productivity Computing Systems) or “SIMD” co-processor languages Parallelizing compilers including OpenMP annotation Component Parallel approaches include MPI (and related systems like PVM ) parallel message passing PGAS (Partitioned Global Address Space) C++ futures and active objects Microsoft CCR and DSS Workflow and Mashups (already discussed) Discrete Event Simulation
- 97. Data Structure Parallel I Reserving data parallel to describe the application property that parallelism achieved from simultaneous evolution of different degrees of freedom in Application Space Data Structure Parallelism is a Program Parallel paradigm that expresses operations on data structures and provides libraries implementing basic parallel operations such as those needed in linear algebra and traditional language intrinsics Typical High Performance Fortran built on array expression in Foretran90 and supports full array statements such as B = A1 + A2 B = EOSHIFT(A,-1) C = MATMUL(A,X ) HPF also allows parallel forall loops Such support is also seen in co-processor support of GPU ( PeakStream ), ClearSpeed and Microsoft Data Parallel .NET support
- 98. Data Structure Parallel II HPF had several problems including mediocre early implementations (My group at Syracuse produced the first!) but on a longer term, they exhibited Unpredictable performance Inability to express complicated parallel algorithms in a natural way Greatest success was on Earth Simulator as Japanese produced an excellent compiler while IBM had cancelled theirs years before Note we understood limited application scope but negative reception of early compilers prevented issues being addressed; probably we raised expectations too much! HPF now being replaced by HPCS Languages X10, Chapel and Fortress but these are still under development
- 99. Data Structure Parallel III HPCS Languages Fortress (Sun), X10 (IBM) and Chapel (Cray) are designed to address HPF problems but they are a long way from being proven in practice in either design or implementation Will HPCS languages extend outside scientific applications Will people adopt a totally new language as opposed to an extension of an existing language Will HPF difficulties remain to any extent? How hard will compilers be to write? HPCS Languages include a wealth of capabilities including parallel arrays, multi-threading and workflow. They have support for 3 key paradigms identified earlier and so should address broad problem class HPCS approach seems ambitious to me and more conservative would be to focus on unique language-level data structure parallel support and build on existing language(s) There are less “disruptive” ways to support coarse and fine grain functional parallelism
- 100. Parallelizing Compilers I The simplest Program parallel approach is a parallelizing compiler In syntax like for( i=1; i<n; i++) { k=something; A(i)= function(A(i+k)); } It is not clear what parallelism is possible k =1 all if careful; k= -1 none On a distributed memory machine, it is often unclear what instructions involve remote memory access and expensive communication In general parallelization information (such as value of k above) is “ lost ” when one codes a parallel algorithm in a sequential language Whole program compiler analysis more likely to be able to find needed information and so identify parallelism.
- 101. Parallelizing Compilers II Data Parallelism corresponds to multiple for loops over the degrees of freedom for( iouter1=1; i<n; i++) { for( iouter2=1; i<n; i++) { …………………. for( iinner2=1; i<n; i++) { for( iinner1=1; i<n; i++) { ….. }}…}} The outer loops tend to be the scalable (large) “ global ” data parallelism and the inner loops “ local ” loops over for example degrees of freedom at a mesh point (5 for CFD Navier Stokes) or over multiple (x,y,z) properties of a particle Inner loops are most attractive for parallelizing compilers as minimizes number of undecipherable data dependencies Overlaps with very successful loop reorganization, vectorization and instruction level parallelization Parallelizing Compilers are likely to be very useful for small number of cores but of decreasing success as core count increases
- 102. OpenMP and Parallelizing Compilers Compiler parallelization success can clearly be optimized by careful writing of sequential code to allow data dependencies to be removed or at least amenable to analysis. Further OpenMP (Open Specifications for Multi Processing) is a sophisticated set of annotations for traditional C C++ or Fortran codes to aid compilers producing parallel codes It provides parallel loops and collective operations such as summation over loop indices Parallel Sections provide traditional multi-threaded capability
- 103. OpenMP Parallel Constructs In distributed memory MPI style programs, the “master thread” is typically replicated and global operations like sums deliver results to all components Master Thread Master Thread Master Thread Master Thread again with an implicit barrier synchronization SECTIONS Fork Join Heterogeneous Team SINGLE Fork Join DO/for loop Fork Join Homogeneous Team
- 104. Performance of OpenMP, MPI, CAF, UPC NAS Benchmarks Oak Ridge SGI Altix and other machines http://www.csm.ornl.gov/~dunigan/sgi/ MPI OpenMP MPI OpenMP UPC CAF MPI MPI Multigrid OpenMP MPI MPI OpenMP MPI MPI OpenMP Conjugate Gradient
- 105. Component Parallel I: MPI Always the final parallel execution will involve multiple threads and/or processes In Program parallel model, a high level description as a single program is broken up into components by the compiler. In Component parallel programming, the user explicitly specifies the code for each component This is certainly hard work but has advantage that always works and has a clearer performance model MPI is the dominant scalable parallel computing paradigm and uses a component parallel model There are a fixed number of processes that are long running They have explicit message send and receive using a rendezvous model
- 106. MPI Execution Model Rendezvous for set of “local” communications but as in this case with a global “structure” Gives a global synchronization with local communication SPMD (Single Program Multiple Data) with each thread identical code including “computing” and explicit MPI sends and receives 8 fixed executing threads (processes)
- 107. MPI Features I MPI aimed at high performance communication and original 1995 version had 128 functions but 6 are key: MPI_INIT Initialize MPI_Comm_rank Find Thread number in pool allowing one to work out what part of data you are responsible for MPI_Comm_Size Find total number of threads MPI_Send Send data to processor MPI_Recv Receive data from processor MPI_Finalize Clean up – get rid of threads etc. Key concepts include Ability to define data structures for messages (relevant for C, Fortran) Ability to address general sets of processes (multicast with reduction) Ability to label messages using common tags allowing different message sets to coexist and not intefere
- 108. MPI Features II Both simple MPI_SEND and MPI_RECV and a slew of collective communications Barrier, Broadcast , Gather, Scatter, All-to-all, Exchange General reduction operation (sum, minimum, scan) e.g. All threads send out a vector and at end of operation, all have the vector that sums over those sent by each thread Need different implementations on each interconnect Blocking , non-blocking, buffered , synchronous, asynchronous messaging Topologies to decompose set of threads onto a mesh I/O in MPI-2 that doubles number of functions! MPICH most famous implementation and OpenMPI is a fresh rewrite including fault-tolerance
- 109. 300 MPI2 routines from Argonne MPICH2
- 110. MPICH2 Performance
- 112. Why people like MPI! Jason J Beech-Brandt, and Andrew A. Johnson, at AHPCRC Minneapolis BenchC is unstructured finite element CFD Solver Looked at OpenMP on shared memory Altix with some effort to optimize Optimized UPC on several machines cluster After Optimization of UPC cluster
- 113. Component Parallel: PGAS Languages I PGAS (Partitioned Global Address Space) Languages have been explored for 30 years (perhaps more) but have never been very popular Probably because it was difficult to write efficient compilers for the complicated problems for which the had most possible advantage However there is a growing interest confined to small communities probably spurred by better implementations HPCS Languages offer PGAS capabilities In MPI, one writes program for each thread addressing its local variables with local indices. There are clever tricks like ghost points to make the code cleaner and more similar to sequential version One uses MPI_Comm_rank or equivalent to find out which part of Application you are addressing There is still quite a bit of bookkeeping to get MPI calls correct and transfer data to and from correct locations
- 114. Ghost Cells Suppose you are writing code to solve Laplace’s equation for 8 by 8 set of Green mesh points One would communicate values on neighboring red mesh points and be able to update Easiest code corresponds to dimensioning array to 10 by 10 and preloading effective boundary values in red cells This is termed use of Halo or Ghost points
- 115. PGAS Languages II In the PGAS approach, one still writes the code for the component but use some form of global index In contrast with MPI and other “pure” messaging systems one uses “local” indices with the “global” value implicit from the particular processors that messages were gotten from and user is responsible for calculating global implications of local indices Global references in component code (external to component) are translated into appropriate MPI (on distributed memory) calls to transfer information using the usual “owner computes” rule i.e. component where variable stored updates it Non trivial performance issue for compiler to generate suitable large messages to avois too much overhead from message latency Co-array Fortran CAF extensions will be adopted by Fortran standards committee (X3J3) UPC is a C-based PGAS language developed at NSA Titanium from Berkeley and the obscure HPJava (Indiana University) are extensions of Java
- 116. Other Component Parallel Models Shared memory (as in multicore) allows more choices as one no longer needs to send messages One may choose to use messages as less likelihood of race conditions However even MPI on a shared memory need not actually transfer data as one can simply transfer a reference to information However loosely synchronous problems have a clear efficient synchronization mechanism whereas other applications may not or Appropriate Mechanisms depends on application structure Is structure?
- 117. Component Synchronization Patterns There are (at least) 3 important “ synchronization patterns ” which must get implemented by messaging on distributed Reductions (such as global sums over subsets of threads) are present in all applications; this a well known hot spot example Here one can use libraries which is default in MPI/PGAS as the structure is quite simple and easy to optimize for each architecture Structured Synchronization is characteristic of loosely synchronous problems and is application specific but can be arranged to happen at natural barriers; note all threads are communicating and synchronizing together and often involve multicast Explicit messaging seems attractive as hard otherwise to avoid race conditions as need data values to be well defined and not updated on the fly Erratic Synchronization as in updating shared databases as in Computer Chess hash table; here often particular synchronization points are not likely to have interference between multiple threads and so one can use locks or similar approaches that are not good for more intense but structured synchronization Locks or queues of updates seem to fit this
- 118. Microsoft CCR Supports exchange of messages between threads using named ports FromHandler: Spawn threads without reading ports Receive: Each handler reads one item from a single port MultipleItemReceive: Each handler reads a prescribed number of items of a given type from a given port. Note items in a port can be general structures but all must have same type. MultiplePortReceive: Each handler reads a one item of a given type from multiple ports. JoinedReceive: Each handler reads one item from each of two ports. The items can be of different type. Choice: Execute a choice of two or more port-handler pairings Interleave: Consists of a set of arbiters (port -- handler pairs) of 3 types that are Concurrent, Exclusive or Teardown (called at end for clean up). Concurrent arbiters are run concurrently but exclusive handlers are not.
- 119. Pipeline which is Simplest loosely synchronous execution in CCR Note CCR supports thread spawning model MPI usually uses fixed threads with message rendezvous Message Message Message Message Message Message Next Stage Message Thread3 Port3 Message Message Message Thread3 Port3 Message Message Message Thread2 Port2 Message Message Message Thread2 Port2 Message Message Message Thread0 Port0 Message Message Message Thread0 Port0 Message Message Message Thread0 Port0 Message Message Message Thread3 Port3 Message Message Message Thread2 Port2 Message Message Message Thread1 Port1 Message Message Message Thread1 Port1 Message Message Message Thread1 Port1 Message Message One Stage Message Thread0 Port0 Message Message Message Thread0 Port0 Message Message Message Thread0 Port0 Message Message Message Thread1 Port1 Message Message Message Thread1 Port1 Message Message Message Thread1 Port1 Message Message
- 120. Thread0 Message Thread3 EndPort Message Thread2 Message Thread1 Message Idealized loosely synchronous endpoint (broadcast) in CCR An example of MPI Collective in CCR Message Thread0 Port0 Message Message Message Thread3 Port3 Message Message Message Thread2 Port2 Message Message Message Thread1 Port1 Message Message
- 121. Write Exchanged Messages Port3 Port2 Thread0 Thread3 Thread2 Thread1 Port1 Port0 Thread0 Write Exchanged Messages Port3 Thread2 Port2 Exchanging Messages with 1D Torus Exchange topology for loosely synchronous execution in CCR Thread0 Read Messages Thread3 Thread2 Thread1 Port1 Port0 Thread3 Thread1
- 122. Thread0 Port3 Thread2 Port2 Port1 Port0 Thread3 Thread1 Thread2 Port2 Thread0 Port0 Port3 Thread3 Port1 Thread1 Thread3 Port3 Thread2 Port2 Thread0 Port0 Thread1 Port1 (a) Pipeline (b) Shift (d) Exchange Thread0 Port3 Thread2 Port2 Port1 Port0 Thread3 Thread1 (c) Two Shifts Four Communication Patterns used in CCR Tests. (a) and (b) use CCR Receive while (c) and (d) use CCR Multiple Item Receive
- 123. Stages (millions) Fixed amount of computation (4.10 7 units) divided into 4 cores and from 1 to 10 7 stages on HP Opteron Multicore . Each stage separated by reading and writing CCR ports in Pipeline mode Time Seconds 8.04 microseconds per stage averaged from 1 to 10 million stages Overhead = Computation Computation Component if no Overhead 4-way Pipeline Pattern 4 Dispatcher Threads HP Opteron
- 124. Stages (millions) Fixed amount of computation (4.10 7 units) divided into 4 cores and from 1 to 10 7 stages on Dell Xeon Multicore . Each stage separated by reading and writing CCR ports in Pipeline mode Time Seconds 12.40 microseconds per stage averaged from 1 to 10 million stages 4-way Pipeline Pattern 4 Dispatcher Threads Dell Xeon Overhead = Computation Computation Component if no Overhead
- 125. Summary of Stage Overheads for AMD 2-core 2-processor Machine These are stage switching overheads for a set of runs with different levels of parallelism and different message patterns –each stage takes about 28 microseconds (500,000 stages)
- 126. Summary of Stage Overheads for Intel 2-core 2-processor Machine These are stage switching overheads for a set of runs with different levels of parallelism and different message patterns –each stage takes about 30 microseconds. AMD overheads in parentheses These measurements are equivalent to MPI latencies
- 127. Summary of Stage Overheads for Intel 4-core 2-processor Machine These are stage switching overheads for a set of runs with different levels of parallelism and different message patterns –each stage takes about 30 microseconds. 2-core 2-processor Xeon overheads in parentheses These measurements are equivalent to MPI latencies
- 128. AMD 2-core 2-processor Bandwidth Measurements Previously we measured latency as measurements corresponded to small messages. We did a further set of measurements of bandwidth by exchanging larger messages of different size between threads We used three types of data structures for receiving data Array in thread equal to message size Array outside thread equal to message size Data stored sequentially in a large array (“stepped” array) For AMD and Intel, total bandwidth 1 to 2 Gigabytes/second
- 129. Intel 2-core 2-processor Bandwidth Measurements For bandwidth, the Intel did better than AMD especially when one exploited cache on chip with small transfers For both AMD and Intel, each stage executed a computational task after copying data arrays of size 10 5 (labeled small), 10 6 (labeled large) or 10 7 double words. The last column is an approximate value in microseconds of the compute time for each stage. Note that copying 100,000 double precision words per core at a gigabyte/second bandwidth takes 3200 µs. The data to be copied (message payload in CCR) is fixed and its creation time is outside timed process
- 130. Typical Bandwidth measurements showing effect of cache with slope change 5,000 stages with run time plotted against size of double array copied in each stage from thread to stepped locations in a large array on Dell Xeon Multicore Time Seconds 4-way Pipeline Pattern 4 Dispatcher Threads Dell Xeon Total Bandwidth 1.0 Gigabytes/Sec up to one million double words and 1.75 Gigabytes/Sec up to 100,000 double words Array Size: Millions of Double Words Slope Change (Cache Effect)
- 131. Timing of HP Opteron Multicore as a function of number of simultaneous two-way service messages processed (November 2006 DSS Release) CGL Measurements of Axis 2 shows about 500 microseconds – DSS is 10 times better DSS Service Measurements
- 132. Parallel Runtime Locks and Barriers Software Transactional Memory MPI RTI (Run Time Infrastructure) which is runtime for DoD HLA (High Level Architecture) Discrete Event Simulation CCR multi-input multi-output messaging There is also Message oriented Middleware and that used to support Web Services and Peer to peer networks
- 133. Horror of Hybrid Computing Many parallel systems have distributed shared memory nodes and indeed all multicore clusters are of this type This could be supported by say OpenMP on the shared memory nodes and MPI between the distributed nodes. Such hybrid computing models are common but it is not clear if they are better than “ pure MPI ” on both distributed and shared memory MPI is typically more efficient than OpenMP and many applications have enough data (outer loop) parallelism (i.e. they are large enough ) that it can be used for both shared and distributed parallelism If one uses OpenMP , natural to exploit inner loop not the outer loop data parallelism Funny to use two software models for the same parallelism
- 134. A general discussion of Some miscellaneous issues
- 135. Load Balancing Particle Dynamics Particle dynamics of this type (irregular with sophisticated force calculations) always need complicated decompositions Equal area decompositions as shown here to load imbalance Equal Volume Decomposition Universe Simulation Galaxy or Star or ... 16 Processors If use simpler algorithms (full O(N 2 ) forces) or FFT, then equal area best
- 136. Reduce Communication Consider a geometric problem with 4 processors In top decomposition, we divide domain into 4 blocks with all points in a given block contiguous In bottom decomposition we give each processor the same amount of work but divided into 4 separate domains edge/area(bottom) = 2* edge/area(top) So minimizing communication implies we keep points in a given processor together Block Decomposition Cyclic Decomposition
- 137. Minimize Load Imbalance But this has a flip side. Suppose we are decomposing Seismic wave problem and all the action is near a particular earthquake fault denoted by . In Top decomposition only the white processor does any work while the other 3 sit idle. Ffficiency 25% due to Load Imbalance In Bottom decomposition all the processors do roughly the same work and so we get good load balance …... Block Decomposition Cyclic Decomposition
- 138. Parallel Irregular Finite Elements Here is a cracked plate and calculating stresses with an equal area decomposition leads to terrible results All the work is near crack Processor
- 139. Irregular Decomposition for Crack Concentrating processors near crack leads to good workload balance equal nodal point -- not equal area -- but to minimize communication nodal points assigned to a particular processor are contiguous This is NP complete (exponenially hard) optimization problem but in practice many ways of getting good but not exact good decompositions Region assigned to 1 processor Work Load Not Perfect ! Processor
- 140. Further Decomposition Strategies Not all decompositions are quite the same In defending against missile attacks , you track each missile on a separate node -- geometric again In playing chess, you decompose chess tree -- an abstract not geometric space Computer Chess Tree Current Position (node in Tree) First Set Moves Opponents Counter Moves California gets its independence
- 141. Physics Analogy for Load Balancing We define S software as a Physical system
- 142. Physics Analogy to discuss Load Balancing The existence of simple geometric physics analogy makes it less surprising that Load Balancing has proven to be easier than its formal NP Complete complexity might suggest C i is compute time of i’th process V i,j is communication needed between i and j and attractive as minimized when i and j nearby Processes are particles in analogy
- 143. Forces are generated by constraints of minimizing H and they can be thought of as springs Processes (particles in analogy) that communicate with each other have attractive forces between them One can discuss static and dynamic problems
- 144. Suppose we load balance by Annealing the physical analog system
- 145. Optimal v. stable scattered Decompositions Consider a set of locally interacting particles simulated on a 4 processor system Optimal overall
- 146. Time Dependent domain (optimal) Decomposition compared to stable Scattered Decomposition
- 147. Use of Time averaged Energy for Adaptive Particle Dynamics