Pentaho Data Integration: Extrayendo, integrando, normalizando y preparando mis datos
Download as PPTX, PDF2 likes2,042 views

Sesión de Pentaho Data Integration impartida en Noviembre de 2015 en el marco del Programa de Big Data y Business Intelligence de la Universidad de Deusto (detalle aquí http://bit.ly/1PhIVgJ).


















































































































Ad
More Related Content
What's hot (20)
Similar to Pentaho Data Integration: Extrayendo, integrando, normalizando y preparando mis datos (20)












![[DSC DACH 24] Automatic ETL Migration - on-prem to cloud and more - Miljenko ...](https://cdn.slidesharecdn.com/ss_thumbnails/miljenkovukovic-240921155004-46bd1064-thumbnail.jpg?width=560&fit=bounds)





Ad
More from Alex Rayón Jerez (20)




















Ad
Recently uploaded (20)




















Pentaho Data Integration: Extrayendo, integrando, normalizando y preparando mis datos
- 1. TALLER Pentaho Data Integration: Extrayendo, Integrando, Normalizando y Preparando mis datos Proyectos Programa Big Data y Business Intelligence Alex Rayón [email protected] Noviembre, 2015
- 2. Before starting…. Who has used a relational database? Source: http://www.agiledata.org/essays/databaseTesting.html 2
- 3. Before starting…. (II) Who has written scripts or Java code to move data from one source and load it to another? Source: http://www.theguardian.com/teacher-network/2012/jan/10/how-to-teach-code 3
- 4. Before starting…. (III) What did you use? 1.Scripts 2.Custom Java Code 3.ETL 4
- 5. Table of Contents Pentaho at a glance In the academic field ETL Kettle Big Data Predictive Analytics 5
- 6. Table of Contents Pentaho at a glance In the academic field ETL Kettle Big Data Predictive Analytics 6
- 7. Pentaho at a glance Business Intelligence 7
- 8. Pentaho at a glance (II) 8
- 9. Pentaho at a glance (III) Business Intelligence & Analytics Open Core GPL v2 Apache 2.0 Enterprise and OEM licenses Java-based Web front-ends 9
- 10. Pentaho at a glance (IV) The Pentaho Stack Data Integration / ETL Big Data / NoSQL Data Modeling Reporting OLAP / Analysis Data Visualization Source: http://helicaltech.com/blogs/hire-pentaho-consultants-hire-pentaho-developers/ 10
- 11. Pentaho at a glance (V) Modules Pentaho Data Integration Kettle Pentaho Analysis Mondrian Pentaho Reporting Pentaho Dashboards 11
- 12. Pentaho at a glance (VI) Figures + 10.000 deployments + 185 countries + 1.200 customers Since 2012, in Gartner Magic Quadrant for BI Platforms 1 download / 30 12
- 13. Pentaho at a glance (VII) Open Source Leader 13
- 14. Pentaho at a glance (VIII) Single Platform 14
- 15. Table of Contents Pentaho at a glance In the academic field ETL Kettle Big Data Predictive Analytics 15
- 22. Table of Contents Pentaho at a glance In the academic field ETL Kettle Big Data Predictive Analytics 22
- 23. ETL Definition and characteristics An ETL tool is a tool that Extracts data from various data sources (usually legacy data) Transforms data from → being optimized for transaction to → being optimized for reporting and analysis synchronizes the data coming from different databases data cleanses to remove errors Loads data into a data warehouse 23
- 24. ETL Why do I need it? ETL tools save time and money when developing a data warehouse by removing the need for hand-coding It is very difficult for database administrators to connect between different brands of databases without using an external tool In the event that databases are altered or new databases need to be integrated, a lot of hand- coded work needs to be completely redone24
- 25. ETL Business Intelligence ETL is the heart and soul of business intelligence (BI) ETL processes bring together and combine data from multiple source systems into a data warehouse Source: http://datawarehouseujap.blogspot.com.es/2010/08/data-warehouse.html 25
- 26. ETL Business Intelligence (II) According to most practitioners, ETL design and development work consumes 60 to 80 percent of an entire BI project Source: http://www.dwuser.com/news/tag/optimization/ Source: The Data Warehousing Institute. www.dw-institute.com 26
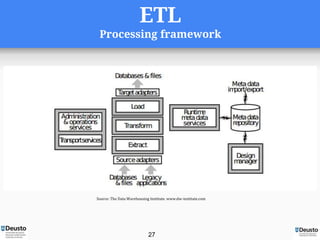
- 27. ETL Processing framework Source: The Data Warehousing Institute. www.dw-institute.com 27
- 30. ETL CloverETL Create a basic archive of functions for mapping and transformations, allowing companies to move large amounts of data as quickly and efficiently as possible Uses building blocks called components to create a transformation graph, which is a visual depiction of the intended 30
- 31. ETL CloverETL (II) The graphic presentation simplifies even complex data transformations, allowing for drag-and-drop functionality Limited to approximately 40 different components to simplify graph creation Yet you may configure each component to meet specific needs It also features extensive debugging capabilities to ensure all transformation graphs work31
- 32. ETL KETL Contains a scalable, platform-independent engine capable of supporting multiple computers and 64-bit servers The program also offers performance monitoring, extensive data source support, XML compatibility and a scheduling engine for time-based and event-driven job execution 32
- 33. ETL Kettle The Pentaho company produced Kettle as an OS alternative to commercial ETL software No relation to Kinetic Networks' KETL Kettle features a drop-and-drag, graphical environment with progress feedback for all data transactions, including automatic documentation of executed jobs XML Input Stream to handle huge XML files without suffering a loss in performance or a spike in memory usage Users can also upgrade the free Kettle version for 33
- 34. ETL Talend Provides a graphical environment for data integration, migration and synchronization Drag and drop graphic components to create the java code required to execute the desired task, saving time and effort Pre-built connectors to enable compatibility with a wide range of business systems and databases Users gain real-time access to corporate data, allowing for the monitoring and debugging of transactions to ensure smooth data integration 34
- 35. ETL Comparison The set of criteria that were used for the ETL tools comparison were divided into seven categories: TCO Risk Ease of use Support Deployment Speed 35
- 37. ETL Comparison (III) Total Cost of Ownership The overall cost for a certain product. This can mean initial ordering, licensing servicing, support, training, consulting, and any other additional payments that need to be made before the product is in full use Commercial Open Source products are typically free to use, but the support, training and consulting are what companies need to pay37
- 38. ETL Comparison (IV) Risk There are always risks with projects, especially big projects. The risks for projects failing are: Going over budget Going over schedule Not completing the requirements or expectations of the customers Open Source products have much lower risk then Commercial ones since they do not restrict the use of their products by pricey licenses 38
- 39. ETL Comparison (V) Ease of use All of the ETL tools, apart from Inaport, have GUI to simplify the development process Having a good GUI also reduces the time to train and use the tools Pentaho Kettle has an easy to use GUI out of all the tools Training can also be found online or within the community 39
- 40. ETL Comparison (VI) Support Nowadays, all software products have support and all of the ETL tool providers offer support Pentaho Kettle – Offers support from US, UK and has a partner consultant in Hong Kong Deployment Pentaho Kettle is a stand-alone java engine that can run on any machine that can run java. Needs an external scheduler to run automatically. It can be deployed on many different machines and used as40
- 41. ETL Comparison (VII) Speed The speed of ETL tools depends largely on the data that needs to be transferred over the network and the processing power involved in transforming the data. Pentaho Kettle is faster than Talend, but the Java-connector slows it down somewhat. Also requires manual tweaking like Talend. Can be clustered by placed on many machines to reduce network traffic 41
- 42. ETL Comparison (VIII) Data Quality Data Quality is fast becoming the most important feature in any data integration tool. Pentaho – has DQ features in its GUI, allows for customized SQL statements, by using JavaScript and Regular Expressions. It also has some additional modules after subscribing. Monitoring Pentaho Kettle – has practical monitoring tools and logging 42
- 43. ETL Comparison (IX) Connectivity In most cases, ETL tools transfer data from legacy systems Their connectivity is very important to the usefulness of the ETL tools. Kettle can connect to a very wide variety of databases, flat files, xml files, excel files and web services. 43
- 44. Table of Contents Pentaho at a glance In the academic field ETL Kettle Big Data Predictive Analytics 44
- 45. Kettle Introduction Project Kettle Powerful Extraction, Transformation and Loading (ETL) capabilities using an innovative, metadata-driven approach 45
- 46. Kettle Introduction (II) What is Kettle? Batch data integration and processing tool written in Java Exists to retrieve, process and load data PDI is a synonymous term Source: http://www.dreamstime.com/stock-photo-very-old-kettle-isolated-image16622230 46
- 47. Kettle Introduction (III) It uses an innovative meta-driven approach It has a very easy-to-use GUI Strong community of 13,500 registered users It uses a stand-alone Java engine that process the tasks for moving data between many different databases and files 47
- 49. Kettle Data Integration Platform Source: http://download.101com.com/tdwi/research_report/2003ETLReport.pdf 49
- 51. Kettle Most common uses Datawarehouse and datamart loads Data Integration Data cleansing Data migration Data export etc. 51
- 52. Kettle Data Integration Changing input to desired output Jobs Synchronous workflow of job entries (tasks) Transformations Stepwise parallel & asynchronous processing of a recordstream52
- 53. Kettle Data Integration challenges Data is everywhere Data is inconsistent Records are different in each system Performance issues Running queries to summarize data for stipulated long period takes operating system for task Brings the OS on max load53
- 54. Kettle Transformations String and Date Manipulation Data Validation / Business Rules Lookup / Join Calculation, Statistics Cryptography Decisions, Flow control 54
- 55. Kettle What is good for? Mirroring data from master to slave Syncing two data sources Processing data retrieved from multiple sources and pushed to multiple destinations Loading data to RDBMS Datamart / Datawarehouse 55
- 56. Kettle Alternatives 56 Code Custom java Spring batch Scripts perl, python, shell, etc Possibly + db loader tool and Commercial ETL tools Datastage Informatica Oracle Warehouse Builder SQL Server Integration services
- 59. Kettle Extraction (III) RDBMS (SQL Server, DB2, Oracle, MySQL, PostgreSQL, Sybase IQ, etc.) NoSQL Data: HBase, Cassandra, MongoDB OLAP (Mondrian, Palo, XML/A) Web (REST, SOAP, XML, JSON) Files (CSV, Fixed, Excel, etc.) ERP (SAP, Salesforce, OpenERP) Hadoop Data: HDFS, Hive 59
- 64. Kettle Comparison of Data Integration tools 64
- 65. Table of Contents Pentaho at a glance In the academic field ETL Kettle Big Data Predictive Analytics 65
- 66. Big Data Business Intelligente Source: http://es.wikipedia.org/wiki/Weka_(aprendizaje_autom%C3%A1tico) A brief (BI) history…. 66
- 67. Big Data WEKA Project Weka A comprehensive set of tools for Machine Learning and Data Mining Source: http://es.wikipedia.org/wiki/Weka_(aprendizaje_autom%C3%A1tico) 67
- 68. Big Data Among Pentaho’s products Mondrian OLAP server written in Java Kettle ETL tool Weka Machine learning and Data Mining tool 68
- 69. Big Data WEKA platform WEKA (Waikato Environment for Knowledge Analysis) Funded by the New Zealand’s Government (for more than 10 years) Develop an open-source state-of-the-art workbench of data mining tools Explore fielded applications Develop new fundamental methods Became part of Pentaho platform in 2006 (PDM - Pentaho Data Mining) 69
- 70. Big Data Data Mining with WEKA (One-of-the-many) Definition: Extraction of implicit, previously unknown, and potentially useful information from data Goal: improve marketing, sales, and customer support operations, risk assessment etc. Who is likely to remain a loyal customer? What products should be marketed to which prospects? What determines whether a person will respond to a certain offer? 70
- 71. Big Data Data Mining with WEKA (II) Central idea: historical data contains information that will be useful in the future (patterns → generalizations) Data Mining employs a set of algorithms that automatically detect patterns and regularities in data 71
- 72. Big Data Data Mining with WEKA (III) A bank’s case as an example Problem: Prediction (Probability Score) of a Corporate Customer Delinquency (or default) in the next year Customer historical data used include: Customer footings behavior (assets & liabilities) Customer delinquencies (rates and time data) Business Sector behavioral data 72
- 73. Big Data Data Mining with WEKA (IV) Variable selection using the Information Value (IV) criterion Automatic Binning of continuous data variables was used (Chi-merge). Manual corrections were made to address particularities in the data distribution of some variables (using again IV) 73
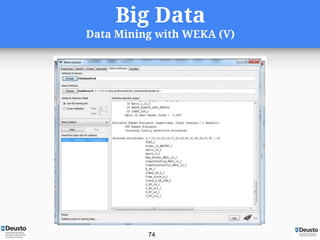
- 74. Big Data Data Mining with WEKA (V) 74
- 75. Big Data Data Mining with WEKA (VI) 75
- 76. Big Data Data Mining with WEKA (VII) Limitations Traditional algorithms need to have all data in (main) memory big datasets are an issue Solution Incremental schemes Stream algorithms MOA (Massive Online Analysis) 76
- 77. Big Data Be careful with Data Mining 77
- 78. Table of Contents Pentaho at a glance In the academic field ETL Kettle Big Data Predictive Analytics 78
- 79. Predictive analytics Unified solution for Big Data Analytics 79
- 80. Predictive analytics Unified solution for Big Data Analytics (II) Curren release: Pentaho Business Analytics Suite 4.8 Instant and interactive data discovery for iPad ● Full analytical power on the go – unique to Pentaho ● Mobile-optimized user interface 80
- 81. Predictive analytics Unified solution for Big Data Analytics (III) Curren release: Pentaho Business Analytics Suite 4.8 Instant and interactive data discovery and development for big data ● Broadens big data access to data analysts ● Removes the need for separate big data visualization tools ● Further improves productivity for big data developers 81
- 82. Predictive analytics Unified solution for Big Data Analytics (IV) Pentaho Instaview ● Instaview is simple ○ Created for data analysts ○ Dramatically simplifies ways to access Hadoop and NoSQL data stores ● Instaview is instant & interactive ○ Time accelerator – 3 quick steps from data to analytics ○ Interact with big data sources – group, sort, aggregate & visualize ● Instaview is big data analytics ○ Marketing analysis for weblog data in Hadoop ○ Application log analysis for data in MongoDB 82
- 85. Copyright (c) 2015 University of Deusto This work (but the quoted images, whose rights are reserved to their owners*) is licensed under the Creative Commons “Attribution-ShareAlike” License. To view a copy of this license, visit http://creativecommons.org/licenses/by-sa/3.0/ Alex Rayón Noviembre 2015
- 86. TALLER Pentaho Data Integration: Extrayendo, Integrando, Normalizando y Preparando mis datos Proyectos Programa Big Data y Business Intelligence Alex Rayón [email protected] Noviembre, 2015