Performance Analysis and Optimizations for Kafka Streams Applications

High-speed and low footprint data stream processing is high in demand for Kafka Streams applications. However, how to write an efficient streaming application using the Streams DSL has been asked by many users in the past since it requires some deep knowledge about Kafka Streams internals. In this talk, I will talk about how to analyze your Kafka Streams applications, target performance bottlenecks and unnecessary storage costs, and optimize your application code accordingly using the Streams DSL. In addition, I will talk about the new optimization framework that we have been developed inside Kafka Streams since the 2.1 release which replaced the in-place translation of the Streams DSL into a comprehensive process composed of streams topology compilation and rewriting phases, with a focus on reducing various storage footprints of Streams applications, such as state stores, internal topics etc.





![kubectl create -f my-kafka-streams-deployment.yaml
Deployment “my-kafka-streams-app” created
kubectl scale deployment my-kafka-streams-app --replicas=2
Deployment “my-kafka-streams-app” scaled
6
java -cp /my/app -Dlog4j.configuration=file:/my/app/conf/log4j.properties /
-Dcom.sun.management.jmxremote.authenticate=false /
-Dcom.sun.management.jmxremote.ssl=false /
-Dcom.sun.management.jmxremote.port=17072 /
-XX:+UseGCLogFileRotation -XX:GCLogFileSize=10M /
-Xloggc:/my/app/logs/GC.log /
my.streams.MyStreamsApp /my/app/conf/config.properties
The fancy way
The not-so-fancy
way
Step III: Run It!
[Kafka Summit SF 2018, Shapira & Sax]](https://image.slidesharecdn.com/kafkastreamsoptimizationkafkasummitlondon2019slides-190514151702/85/Performance-Analysis-and-Optimizations-for-Kafka-Streams-Applications-6-320.jpg)







![15
Topologies:
Sub-topology: 0
Source: KSTREAM-SOURCE-0000000000 (topics: [topic1])
--> KSTREAM-WINDOWED-0000000002
Source: KSTREAM-SOURCE-0000000001 (topics: [topic2])
--> KSTREAM-WINDOWED-0000000003
……
Processor: KSTREAM-KEY-SELECT-0000000007 (stores: [])
--> KSTREAM-FILTER-0000000011
<-- KSTREAM-MERGE-0000000006
……
Sink: KSTREAM-SINK-0000000010 (topic: MyAggStore-repartition)
<-- KSTREAM-FILTER-0000000011
Sub-topology: 1
Source: KSTREAM-SOURCE-0000000012 (topics: [MyAggStore-repartition])
--> KSTREAM-AGGREGATE-0000000009
Processor: KSTREAM-AGGREGATE-0000000009 (stores: [MyAggStore])
--> KTABLE-TOSTREAM-0000000013
<-- KSTREAM-SOURCE-0000000012
……
Sink: KSTREAM-SINK-0000000014 (topic: topic3)
<-- KTABLE-TOSTREAM-0000000013
That looks familiar..
State
[Kafka Streams Topology Visualizer. https://zz85.github.io/kafka-streams-viz/]](https://image.slidesharecdn.com/kafkastreamsoptimizationkafkasummitlondon2019slides-190514151702/85/Performance-Analysis-and-Optimizations-for-Kafka-Streams-Applications-15-320.jpg)
![16
Topologies:
Sub-topology: 0
Source: KSTREAM-SOURCE-0000000000 (topics: [topic1])
--> KSTREAM-WINDOWED-0000000002
Source: KSTREAM-SOURCE-0000000001 (topics: [topic2])
--> KSTREAM-WINDOWED-0000000003
……
Processor: KSTREAM-KEY-SELECT-0000000007 (stores: [])
--> KSTREAM-FILTER-0000000011
<-- KSTREAM-MERGE-0000000006
……
Sink: KSTREAM-SINK-0000000010 (topic: MyAggStore-repartition)
<-- KSTREAM-FILTER-0000000011
Sub-topology: 1
Source: KSTREAM-SOURCE-0000000012 (topics: [MyAggStore-repartition])
--> KSTREAM-AGGREGATE-0000000009
Processor: KSTREAM-AGGREGATE-0000000009 (stores: [MyAggStore])
--> KTABLE-TOSTREAM-0000000013
<-- KSTREAM-SOURCE-0000000012
……
Sink: KSTREAM-SINK-0000000014 (topic: topic3)
<-- KTABLE-TOSTREAM-0000000013
Hmm, that looks bizarre?
State
[Kafka Streams Topology Visualizer. https://zz85.github.io/kafka-streams-viz/]](https://image.slidesharecdn.com/kafkastreamsoptimizationkafkasummitlondon2019slides-190514151702/85/Performance-Analysis-and-Optimizations-for-Kafka-Streams-Applications-16-320.jpg)







![24
Shuffling in Streams: RepartitionTopics
State
Repartition Topic (partition key = grouped key)
Topologies:
Sub-topology: 0
……
Sink: KSTREAM-SINK-0000000010 (topic: MyAggStore-repartition)
<-- KSTREAM-FILTER-0000000011
Sub-topology: 1
Source: KSTREAM-SOURCE-0000000012 (topics: [MyAggStore-repartition])
--> KSTREAM-AGGREGATE-0000000009
……](https://image.slidesharecdn.com/kafkastreamsoptimizationkafkasummitlondon2019slides-190514151702/85/Performance-Analysis-and-Optimizations-for-Kafka-Streams-Applications-24-320.jpg)


























![52
Logical Plan Optimization
• Currently rule based
• Repartitioning push-up and consolidation
• Sharing topics for source / changelog
• Logical views for table materialization [2.2+]
• etc..](https://image.slidesharecdn.com/kafkastreamsoptimizationkafkasummitlondon2019slides-190514151702/85/Performance-Analysis-and-Optimizations-for-Kafka-Streams-Applications-52-320.jpg)







![60
Enable Topology Optimization
config: topology.optimization = all
(default = none)
[KIP-295]
code: StreamBuilder#build(props)
upgrade: watch out for compatibility
[https://www.confluent.io/blog/data-reprocessing-with-kafka-streams-resetting-a-streams-application/]](https://image.slidesharecdn.com/kafkastreamsoptimizationkafkasummitlondon2019slides-190514151702/85/Performance-Analysis-and-Optimizations-for-Kafka-Streams-Applications-60-320.jpg)
![61
What’s next
[KIP-372, KIP-307]
• Extensible optimization framework
• More re-write rules!
• Beyond all-or-nothing config
• Compatibility support for optimized topology
[KAFKA-6034]](https://image.slidesharecdn.com/kafkastreamsoptimizationkafkasummitlondon2019slides-190514151702/85/Performance-Analysis-and-Optimizations-for-Kafka-Streams-Applications-61-320.jpg)


































More Related Content
Similar to Performance Analysis and Optimizations for Kafka Streams Applications (20)
More from Guozhang Wang (11)









Recently uploaded (20)









![[HIFLUX] High Pressure Tube Support Catalog 2025](https://cdn.slidesharecdn.com/ss_thumbnails/tubesupporten-250529073613-16c22974-thumbnail.jpg?width=560&fit=bounds)










Performance Analysis and Optimizations for Kafka Streams Applications
- 1. Performance Analysis and Optimizations for Kafka Streams Guozhang Wang Kafka Summit London, May. 14, 2019
- 2. Outline • Streams application execution: from 1000 to 400 feet • Processor topology generation: an optimization problem • Kafka Streams topology optimization framework 2
- 3. 3 So you want to write a Streams app?
- 4. 4 Step I: Read the demo streams/examples/src/main/java/o.a.k.streams/examples/wordcount/WordCountDemo.java
- 5. 5 Step II: Modify the demo code to yours
- 6. kubectl create -f my-kafka-streams-deployment.yaml Deployment “my-kafka-streams-app” created kubectl scale deployment my-kafka-streams-app --replicas=2 Deployment “my-kafka-streams-app” scaled 6 java -cp /my/app -Dlog4j.configuration=file:/my/app/conf/log4j.properties / -Dcom.sun.management.jmxremote.authenticate=false / -Dcom.sun.management.jmxremote.ssl=false / -Dcom.sun.management.jmxremote.port=17072 / -XX:+UseGCLogFileRotation -XX:GCLogFileSize=10M / -Xloggc:/my/app/logs/GC.log / my.streams.MyStreamsApp /my/app/conf/config.properties The fancy way The not-so-fancy way Step III: Run It! [Kafka Summit SF 2018, Shapira & Sax]
- 10. 10 Kafka Streams Execution Kafka Streams Kafka StreamThread JVM (from 1000 feet)
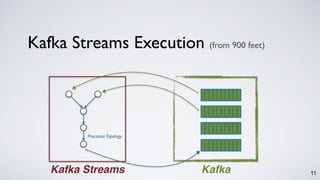
- 11. 11 Kafka Streams Execution Kafka Streams Kafka ProcessorTopology (from 900 feet)
- 12. Define your Processor Topology in DSL 12 KStream<..> stream1 = builder.stream(”topic1”); KStream<..> stream2 = builder.stream(”topic2”); KStream<..> joined = stream1.leftJoin(stream2, ...); KTable<..> aggregated = joined.groupBy(…).aggregate(…); aggregated.toStream().to(”topic3”);
- 13. Define your Processor Topology in DSL 13 KStream<..> stream1 = builder.stream(”topic1”); KStream<..> stream2 = builder.table(”topic2”); .addSource(”Source2”, ”topic2”) topology.addSource(”Source1”, ”topic1”) .addProcessor(”Join”, LeftJoin:new, ”Source1”, ”Source2”) .addProcessor(”Aggregate”, Aggregate:new, ”Join”) .addStateStore(Stores.persistent(…).build(), ”Aggregate”) .addSink(”Sink”, ”topic3”, ”Aggregate”) State
- 14. Examine your Processor Topology 14 State topology.addSource(”Source1”, ”topic1”) .addProcessor(”Join”, LeftJoin:new, ”Source1”, ”Source2”) .addProcessor(”Aggregate”, Aggregate:new, ”Join”) .addStateStore(Stores.persistent(…).build(), ”Aggregate”) .addSink(”Sink”, ”topic3”, ”Aggregate”) .addSource(”Source2”, ”topic2”) topology = builder.build(); System.out.println(topology.describe());
- 15. 15 Topologies: Sub-topology: 0 Source: KSTREAM-SOURCE-0000000000 (topics: [topic1]) --> KSTREAM-WINDOWED-0000000002 Source: KSTREAM-SOURCE-0000000001 (topics: [topic2]) --> KSTREAM-WINDOWED-0000000003 …… Processor: KSTREAM-KEY-SELECT-0000000007 (stores: []) --> KSTREAM-FILTER-0000000011 <-- KSTREAM-MERGE-0000000006 …… Sink: KSTREAM-SINK-0000000010 (topic: MyAggStore-repartition) <-- KSTREAM-FILTER-0000000011 Sub-topology: 1 Source: KSTREAM-SOURCE-0000000012 (topics: [MyAggStore-repartition]) --> KSTREAM-AGGREGATE-0000000009 Processor: KSTREAM-AGGREGATE-0000000009 (stores: [MyAggStore]) --> KTABLE-TOSTREAM-0000000013 <-- KSTREAM-SOURCE-0000000012 …… Sink: KSTREAM-SINK-0000000014 (topic: topic3) <-- KTABLE-TOSTREAM-0000000013 That looks familiar.. State [Kafka Streams Topology Visualizer. https://zz85.github.io/kafka-streams-viz/]
- 16. 16 Topologies: Sub-topology: 0 Source: KSTREAM-SOURCE-0000000000 (topics: [topic1]) --> KSTREAM-WINDOWED-0000000002 Source: KSTREAM-SOURCE-0000000001 (topics: [topic2]) --> KSTREAM-WINDOWED-0000000003 …… Processor: KSTREAM-KEY-SELECT-0000000007 (stores: []) --> KSTREAM-FILTER-0000000011 <-- KSTREAM-MERGE-0000000006 …… Sink: KSTREAM-SINK-0000000010 (topic: MyAggStore-repartition) <-- KSTREAM-FILTER-0000000011 Sub-topology: 1 Source: KSTREAM-SOURCE-0000000012 (topics: [MyAggStore-repartition]) --> KSTREAM-AGGREGATE-0000000009 Processor: KSTREAM-AGGREGATE-0000000009 (stores: [MyAggStore]) --> KTABLE-TOSTREAM-0000000013 <-- KSTREAM-SOURCE-0000000012 …… Sink: KSTREAM-SINK-0000000014 (topic: topic3) <-- KTABLE-TOSTREAM-0000000013 Hmm, that looks bizarre? State [Kafka Streams Topology Visualizer. https://zz85.github.io/kafka-streams-viz/]
- 17. 17 Data Parallelism 101 (specially tailored for Kafka) Topic 1 Partitions Producers Consumers
- 18. 18 Data Parallelism 101 (specially tailored for Kafka) groupBy(…).count(…)
- 19. 19 Data Parallelism 101 (specially tailored for Kafka) groupBy(…).count(…)
- 20. 20 Data Parallelism 101 (specially tailored for Kafka) groupBy(…).count(…)
- 21. 21 Data Parallelism 101 (specially tailored for Kafka) groupBy(…).count(…) count 3 3 3 3
- 22. 22 Shuffling in Streams: RepartitionTopics State
- 23. 23 Shuffling in Streams: RepartitionTopics State
- 24. 24 Shuffling in Streams: RepartitionTopics State Repartition Topic (partition key = grouped key) Topologies: Sub-topology: 0 …… Sink: KSTREAM-SINK-0000000010 (topic: MyAggStore-repartition) <-- KSTREAM-FILTER-0000000011 Sub-topology: 1 Source: KSTREAM-SOURCE-0000000012 (topics: [MyAggStore-repartition]) --> KSTREAM-AGGREGATE-0000000009 ……
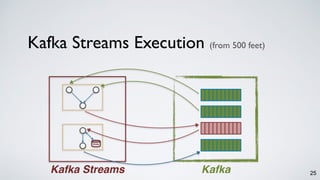
- 25. 25Kafka Streams Kafka Kafka Streams Execution (from 500 feet) State
- 26. Kafka Topic B Task2Task1 Stream Partitions and Tasks 26 Kafka Topic A
- 27. Kafka Topic B Stream Partitions and Tasks 27 Kafka Topic A Task2Task1
- 28. 28Kafka Streams Kafka Kafka Streams Execution (from 400 feet) State State instance-1 instance-2 instance-3
- 29. 29 Repartition Topics for Shuffling State State instance-1 instance-2 instance-3 … …
- 30. 30 Case #1: Duplicate Repartitioning KStream source = builder.stream(“topic1"); KStream mapped = source.map(..); KTable counts = mapped.groupByKey().aggregate(..); KStream sink = mapped.leftJoin(counts, ..);
- 31. 31 Case #1: Duplicate Repartitioning KStream source = builder.stream(“topic1"); KStream mapped = source.map(..); KTable counts = mapped.groupByKey().aggregate(..); KStream sink = mapped.leftJoin(counts, ..);
- 32. 32 Case #1: Duplicate Repartitioning KStream source = builder.stream(“topic1"); KStream mapped = source.map(..); KTable counts = mapped.groupByKey().aggregate(..); KStream sink = mapped.leftJoin(counts, ..); Map State Agg agg-repartition
- 33. 33 Case #1: Duplicate Repartitioning KStream source = builder.stream(“topic1"); KStream mapped = source.map(..); KTable counts = mapped.groupByKey().aggregate(..); KStream sink = mapped.leftJoin(counts, ..); Map State Join Agg map-join-repartition agg-repartition
- 34. 34 Case #1: Duplicate Repartitioning KStream source = builder.stream(“topic1"); KStream mapped = source.map(..); KTable counts = mapped.groupByKey().aggregate(..); KStream sink = mapped.leftJoin(counts, ..); Map State Join Agg map-join-repartition agg-repartition
- 35. 35 Case #1: Duplicate Repartitioning KStream source = builder.stream(“topic1"); KStream shuffled = source.map(..) .through(“topic2”); KTable counts = shuffled.groupByKey().count(..); KStream sink = shuffled.leftJoin(counts, ..);
- 36. 36 Case #1: Duplicate Repartitioning KStream source = builder.stream(“topic1"); KStream shuffled = source.map(..) .through(“topic2”); KTable counts = shuffled.groupByKey().count(..); KStream sink = shuffled.leftJoin(counts, ..); Map topic2
- 37. 37 Case #1: Duplicate Repartitioning KStream source = builder.stream(“topic1"); KStream shuffled = source.map(..) .through(“topic2”); KTable counts = shuffled.groupByKey().count(..); KStream sink = shuffled.leftJoin(counts, ..); Map State Agg topic2
- 38. 38 Case #1: Duplicate Repartitioning KStream source = builder.stream(“topic1"); KStream shuffled = source.map(..) .through(“topic2”); KTable counts = shuffled.groupByKey().count(..); KStream sink = shuffled.leftJoin(counts, ..); Map State Join Agg topic2
- 39. 39 Key-Changing Operations Key-Value Value Only map mapValues flatMap flatMapValues transform transformValues flatTransform flatTransformValues
- 40. 40 Case #2: Clumsy Repartitioning KStream source = builder.stream(“topic1"); KTable aggregated = source.groupBy(..).count(..);
- 41. 41 Case #2: Clumsy Repartitioning SelectKey Agg agg-repartition KStream source = builder.stream(“topic1"); KTable aggregated = source.groupBy(..).count(..); State
- 42. 42 Case #2: Clumsy Repartitioning SelectKey Agg agg-repartition KStream source = builder.stream(“topic1"); KTable aggregated = source.groupBy(..).count(..); State
- 43. 43 Case #2: Clumsy Repartitioning KStream source = builder.stream(“topic1"); KStream projected = source.mapValues(..); KTable aggregated = projected.groupBy(..).count(..);
- 44. 44 Case #2: Clumsy Repartitioning KStream source = builder.stream(“topic1"); KStream projected = source.mapValues(..); KTable aggregated = projected.groupBy(..).count(..); mapValues
- 45. 45 Case #2: Clumsy Repartitioning KStream source = builder.stream(“topic1"); KStream projected = source.mapValues(..); KTable aggregated = projected.groupBy(..).count(..); SelectKey mapValues Agg agg-repartition State
- 46. 46 Topology Generation(an optimization problem) Define: write DSL code Examine: topology.describe Refine: modify DSL code Examine: topology.describe …
- 47. 47 Topology Generation(an optimization problem) Define: write DSL code Examine: topology.describe Refine: modify DSL code Examine: topology.describe … Root Cause: Step-by-step Translation
- 48. 48 Do I Really have to learn all this? No! (beyond Kafka 2.1)
- 49. 49 Key Idea: Replace step-by-step translation with logical plan compilation
- 50. 50 Topology Optimization Framework User DSL code Processor Topology Parsing and Generation
- 51. 51 Topology Optimization Framework User DSL code Logical Plan: Operator Graph Physical Plan: Processor Topology Parsing Compilation Logical plan optimization
- 52. 52 Logical Plan Optimization • Currently rule based • Repartitioning push-up and consolidation • Sharing topics for source / changelog • Logical views for table materialization [2.2+] • etc..
- 53. 53 Case #3: Unnecessary Materialization KTable table1 = builder.table(“topic1"); KTable table2 = builder.table(“topic2"); table1.filter().join(table2, ..); StateState
- 54. 54 Case #3: Unnecessary Materialization KTable table1 = builder.table(“topic1"); KTable table2 = builder.table(“topic2"); table1.filter().join(table2, ..); filter StateState
- 55. 55 Case #3: Unnecessary Materialization KTable table1 = builder.table(“topic1"); KTable table2 = builder.table(“topic2"); table1.filter().join(table2, ..); filter StateState join
- 56. 56 Case #3: Unnecessary Materialization KTable table1 = builder.table(“topic1"); KTable table2 = builder.table(“topic2"); table1.filter().join(table2, ..); filter State State State join
- 57. 57 Case #3: Unnecessary Materialization KTable table1 = builder.table(“topic1"); KTable table2 = builder.table(“topic2"); table1.filter().join(table2, ..); filter State State State join
- 58. 58 Case #3 with Optimization Enabled KTable table1 = builder.table(“topic1"); KTable table2 = builder.table(“topic2"); table1.filter().join(table2, ..); filter State View State join
- 59. 59 Case #3 with Optimization Enabled KTable table1 = builder.table(“topic1"); KTable table2 = builder.table(“topic2"); table1.filter().join(table2, ..); filter State View State join
- 60. 60 Enable Topology Optimization config: topology.optimization = all (default = none) [KIP-295] code: StreamBuilder#build(props) upgrade: watch out for compatibility [https://www.confluent.io/blog/data-reprocessing-with-kafka-streams-resetting-a-streams-application/]
- 61. 61 What’s next [KIP-372, KIP-307] • Extensible optimization framework • More re-write rules! • Beyond all-or-nothing config • Compatibility support for optimized topology [KAFKA-6034]
- 62. Take-aways • Optimize your topology for better performance and less footprint 62 System.out.println(topology.describe());
- 63. Take-aways • Optimize your topology for better performance and less footprint • It’s OK if you forget the first bullet point: Kafka Streams will help doing that for you! 63 System.out.println(topology.describe());
- 64. Take-aways 64 THANKS! Guozhang Wang | [email protected] | @guozhangwang • Optimize your topology for better performance and less footprint • It’s OK if you forget the first bullet point: Kafka Streams will help doing that for you! System.out.println(topology.describe());