Performance Monitoring: Understanding Your Scylla Cluster
7 likes5,489 views

Learn the basics of monitoring Scylla, including monitoring infrastructure and understanding Scylla metrics.





![iostat
• iostat: useful to find disk bottlenecks
$ iostat -x -m 1
[...]
Device: rrqm/s wrqm/s r/s w/s rMB/s wMB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
xvda 0.00 0.00 0.00 0.50 0.00 0.00 2.00 0.00 0.00 0.00 0.00 0.00 0.00
xvdb 1291.00 0.00 3690.50 453.00 234.12 51.34 141.09 8.07 1.95 1.99 1.61 0.23 94.05
xvdc 1332.50 0.00 3808.00 456.00 236.65 51.31 138.31 8.38 1.96 2.01 1.56 0.22 94.70
xvdd 1308.50 0.00 3704.50 449.50 233.14 50.78 139.98 6.83 1.65 1.69 1.27 0.23 93.95
xvde 1285.50 0.00 3632.50 454.50 229.48 51.53 140.81 7.74 1.89 1.94 1.53 0.23 93.40
xvdf 1281.50 0.00 3524.00 459.50 227.91 51.95 143.88 8.08 2.04 2.06 1.86 0.23 93.25
xvdg 1306.00 0.00 3576.50 453.50 231.10 51.70 143.71 7.58 1.89 1.92 1.64 0.23 93.50
xvdh 1302.00 0.00 3566.50 451.50 231.58 51.53 144.30 6.77 1.67 1.72 1.28 0.23 92.90
xvdi 1279.00 0.00 3627.00 448.00 235.86 51.11 144.22 7.92 1.95 1.97 1.73 0.23 93.45
md0 0.00 0.00 34234.50 3570.50 1860.41 411.33 123.07 0.00 0.00 0.00 0.00 0.00 0.00](https://image.slidesharecdn.com/monitoringtracingfinal-160912210908/85/Performance-Monitoring-Understanding-Your-Scylla-Cluster-6-320.jpg)
![Linux & Client side metrics
• iostat: useful to find disk bottlenecks
$ iostat -x -m 1
[...]
Device: rrqm/s wrqm/s r/s w/s rMB/s wMB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
xvda 0.00 0.00 0.00 0.50 0.00 0.00 2.00 0.00 0.00 0.00 0.00 0.00 0.00
xvdb 1291.00 0.00 3690.50 453.00 234.12 51.34 141.09 8.07 1.95 1.99 1.61 0.23 94.05
xvdc 1332.50 0.00 3808.00 456.00 236.65 51.31 138.31 8.38 1.96 2.01 1.56 0.22 94.70
xvdd 1308.50 0.00 3704.50 449.50 233.14 50.78 139.98 6.83 1.65 1.69 1.27 0.23 93.95
xvde 1285.50 0.00 3632.50 454.50 229.48 51.53 140.81 7.74 1.89 1.94 1.53 0.23 93.40
xvdf 1281.50 0.00 3524.00 459.50 227.91 51.95 143.88 8.08 2.04 2.06 1.86 0.23 93.25
xvdg 1306.00 0.00 3576.50 453.50 231.10 51.70 143.71 7.58 1.89 1.92 1.64 0.23 93.50
xvdh 1302.00 0.00 3566.50 451.50 231.58 51.53 144.30 6.77 1.67 1.72 1.28 0.23 92.90
xvdi 1279.00 0.00 3627.00 448.00 235.86 51.11 144.22 7.92 1.95 1.97 1.73 0.23 93.45
md0 0.00 0.00 34234.50 3570.50 1860.41 411.33 123.07 0.00 0.00 0.00 0.00 0.00 0.00](https://image.slidesharecdn.com/monitoringtracingfinal-160912210908/85/Performance-Monitoring-Understanding-Your-Scylla-Cluster-7-320.jpg)
![Linux & Client side metrics
• iostat: useful to find disk bottlenecks
$ iostat -x -m 1
[...]
Device: rrqm/s wrqm/s r/s w/s rMB/s wMB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
xvda 0.00 0.00 0.00 0.50 0.00 0.00 2.00 0.00 0.00 0.00 0.00 0.00 0.00
xvdb 1291.00 0.00 3690.50 453.00 234.12 51.34 141.09 8.07 1.95 1.99 1.61 0.23 94.05
xvdc 1332.50 0.00 3808.00 456.00 236.65 51.31 138.31 8.38 1.96 2.01 1.56 0.22 94.70
xvdd 1308.50 0.00 3704.50 449.50 233.14 50.78 139.98 6.83 1.65 1.69 1.27 0.23 93.95
xvde 1285.50 0.00 3632.50 454.50 229.48 51.53 140.81 7.74 1.89 1.94 1.53 0.23 93.40
xvdf 1281.50 0.00 3524.00 459.50 227.91 51.95 143.88 8.08 2.04 2.06 1.86 0.23 93.25
xvdg 1306.00 0.00 3576.50 453.50 231.10 51.70 143.71 7.58 1.89 1.92 1.64 0.23 93.50
xvdh 1302.00 0.00 3566.50 451.50 231.58 51.53 144.30 6.77 1.67 1.72 1.28 0.23 92.90
xvdi 1279.00 0.00 3627.00 448.00 235.86 51.11 144.22 7.92 1.95 1.97 1.73 0.23 93.45
md0 0.00 0.00 34234.50 3570.50 1860.41 411.33 123.07 0.00 0.00 0.00 0.00 0.00 0.00](https://image.slidesharecdn.com/monitoringtracingfinal-160912210908/85/Performance-Monitoring-Understanding-Your-Scylla-Cluster-8-320.jpg)























































Ad
More Related Content
What's hot (20)
Similar to Performance Monitoring: Understanding Your Scylla Cluster (20)


















Ad
More from ScyllaDB (20)




















Ad
Recently uploaded (20)




















Performance Monitoring: Understanding Your Scylla Cluster
- 1. Performance Monitoring Understanding your Scylla Cluster Glauber Costa & Tomasz Grabiec
- 2. Our Agenda for today • Basics of Monitoring Scylla • Monitoring Infrastructure • Understanding Scylla metrics
- 3. Linux tools • Linux tools are familiar, widely available, no setup needed ▪iostat, top, sar, netstat, etc. •Good for tier-1 analysis and overviews ▪but often don’t tell the whole story, ▪and are limited to a node only.
- 4. The top example • Scylla uses a polling architecture ▪Scylla running at < 100 % CPU -> definitely underloaded. ▪Scylla running at = 100 % CPU -> impossible to determine. CPU in use CPU idle request poll period
- 5. The top example • Scylla uses a polling architecture ▪Scylla running at < 100 % CPU -> definitely underloaded. ▪Scylla running at = 100 % CPU -> impossible to determine. CPU in use poll period poll period poll period
- 6. iostat • iostat: useful to find disk bottlenecks $ iostat -x -m 1 [...] Device: rrqm/s wrqm/s r/s w/s rMB/s wMB/s avgrq-sz avgqu-sz await r_await w_await svctm %util xvda 0.00 0.00 0.00 0.50 0.00 0.00 2.00 0.00 0.00 0.00 0.00 0.00 0.00 xvdb 1291.00 0.00 3690.50 453.00 234.12 51.34 141.09 8.07 1.95 1.99 1.61 0.23 94.05 xvdc 1332.50 0.00 3808.00 456.00 236.65 51.31 138.31 8.38 1.96 2.01 1.56 0.22 94.70 xvdd 1308.50 0.00 3704.50 449.50 233.14 50.78 139.98 6.83 1.65 1.69 1.27 0.23 93.95 xvde 1285.50 0.00 3632.50 454.50 229.48 51.53 140.81 7.74 1.89 1.94 1.53 0.23 93.40 xvdf 1281.50 0.00 3524.00 459.50 227.91 51.95 143.88 8.08 2.04 2.06 1.86 0.23 93.25 xvdg 1306.00 0.00 3576.50 453.50 231.10 51.70 143.71 7.58 1.89 1.92 1.64 0.23 93.50 xvdh 1302.00 0.00 3566.50 451.50 231.58 51.53 144.30 6.77 1.67 1.72 1.28 0.23 92.90 xvdi 1279.00 0.00 3627.00 448.00 235.86 51.11 144.22 7.92 1.95 1.97 1.73 0.23 93.45 md0 0.00 0.00 34234.50 3570.50 1860.41 411.33 123.07 0.00 0.00 0.00 0.00 0.00 0.00
- 7. Linux & Client side metrics • iostat: useful to find disk bottlenecks $ iostat -x -m 1 [...] Device: rrqm/s wrqm/s r/s w/s rMB/s wMB/s avgrq-sz avgqu-sz await r_await w_await svctm %util xvda 0.00 0.00 0.00 0.50 0.00 0.00 2.00 0.00 0.00 0.00 0.00 0.00 0.00 xvdb 1291.00 0.00 3690.50 453.00 234.12 51.34 141.09 8.07 1.95 1.99 1.61 0.23 94.05 xvdc 1332.50 0.00 3808.00 456.00 236.65 51.31 138.31 8.38 1.96 2.01 1.56 0.22 94.70 xvdd 1308.50 0.00 3704.50 449.50 233.14 50.78 139.98 6.83 1.65 1.69 1.27 0.23 93.95 xvde 1285.50 0.00 3632.50 454.50 229.48 51.53 140.81 7.74 1.89 1.94 1.53 0.23 93.40 xvdf 1281.50 0.00 3524.00 459.50 227.91 51.95 143.88 8.08 2.04 2.06 1.86 0.23 93.25 xvdg 1306.00 0.00 3576.50 453.50 231.10 51.70 143.71 7.58 1.89 1.92 1.64 0.23 93.50 xvdh 1302.00 0.00 3566.50 451.50 231.58 51.53 144.30 6.77 1.67 1.72 1.28 0.23 92.90 xvdi 1279.00 0.00 3627.00 448.00 235.86 51.11 144.22 7.92 1.95 1.97 1.73 0.23 93.45 md0 0.00 0.00 34234.50 3570.50 1860.41 411.33 123.07 0.00 0.00 0.00 0.00 0.00 0.00
- 8. Linux & Client side metrics • iostat: useful to find disk bottlenecks $ iostat -x -m 1 [...] Device: rrqm/s wrqm/s r/s w/s rMB/s wMB/s avgrq-sz avgqu-sz await r_await w_await svctm %util xvda 0.00 0.00 0.00 0.50 0.00 0.00 2.00 0.00 0.00 0.00 0.00 0.00 0.00 xvdb 1291.00 0.00 3690.50 453.00 234.12 51.34 141.09 8.07 1.95 1.99 1.61 0.23 94.05 xvdc 1332.50 0.00 3808.00 456.00 236.65 51.31 138.31 8.38 1.96 2.01 1.56 0.22 94.70 xvdd 1308.50 0.00 3704.50 449.50 233.14 50.78 139.98 6.83 1.65 1.69 1.27 0.23 93.95 xvde 1285.50 0.00 3632.50 454.50 229.48 51.53 140.81 7.74 1.89 1.94 1.53 0.23 93.40 xvdf 1281.50 0.00 3524.00 459.50 227.91 51.95 143.88 8.08 2.04 2.06 1.86 0.23 93.25 xvdg 1306.00 0.00 3576.50 453.50 231.10 51.70 143.71 7.58 1.89 1.92 1.64 0.23 93.50 xvdh 1302.00 0.00 3566.50 451.50 231.58 51.53 144.30 6.77 1.67 1.72 1.28 0.23 92.90 xvdi 1279.00 0.00 3627.00 448.00 235.86 51.11 144.22 7.92 1.95 1.97 1.73 0.23 93.45 md0 0.00 0.00 34234.50 3570.50 1860.41 411.33 123.07 0.00 0.00 0.00 0.00 0.00 0.00
- 9. Not all issues are database issues • Client can introduce latencies as well ▪most notably, cassandra-stress will do. ▪JHiccup - client instrumentation for client-side hiccups.
- 10. Our Agenda for today • Basics of Monitoring Scylla • Monitoring Infrastructure • Understanding Scylla metrics
- 11. collectd metrics Prometheus Scylla / Agent Browserip:9103 Grafana ip:65534 ip:3000 ip:9103 ip:9103 HTTP Scylla / Agent Scylla / Agent
- 12. Scylla & Agent Scylla Monitoring collectd collectd_exporter ip:65534 Scylla metrics scyllatop Scylla ip:25826 Scylla + OS metrics Ip:9103 HTTP
- 13. How to use those metrics? • your own infrastructure ▪Whatever works for collectd, works for Scylla • scyllatop • prometheus + grafana
- 14. scyllatop • easy to use, top-like interface. • very high resolution • good for ad-hoc probing ▪not very good for cluster-wide view or time progression
- 15. List of metrics available • RESTful API: $ curl http://scylla-server:10000/collectd | json_reformat [ … { "enable": true, "id": { "plugin_instance": "#cpu", "type_instance": "load", "type": "gauge", "plugin": "reactor" } }, • scyllatop -l: ▪ includes host metrics # scylla running with --smp 1 $ scyllatop -l | wc -l 145
- 16. prometheus + grafana •easy cluster-wide view, with pre-configured dashboards •easy system progression view •easy metric correlation •adding composite metrics •harder to setup, -but we try to make it easier, docker images, pre-loaded dashboards. -https://github.com/scylladb/scylla-grafana-monitoring
- 17. prometheus + grafana • prometheus/grafana imgs, pre-loaded with dashboards: ▪https://github.com/scylladb/scylla-grafana-monitoring
- 19. Our Agenda for today • Basics of Monitoring Scylla • Monitoring Infrastructure • Understanding Scylla metrics
- 20. Naming of metrics Collectd naming scheme: {host}/{plugin}-{plugin instance}/{type}-{type instance} • plugin - name of the component • plugin instance - instance of the component • type - type of metric’s value • type instance - name of the metric of given component
- 21. Naming of metrics Collectd naming scheme: {host}/{plugin}-{plugin instance}/{type}-{type instance} E.g.: node1/reactor-0/gauge-load
- 22. Naming of metrics • plugin instances usually correspond to shard numbers. ▪ Example --smp 3: node1/reactor-0/gauge-load node1/reactor-1/gauge-load node1/reactor-2/gauge-load
- 23. • GAUGE - value as is ▪ collectd types: gauge, bytes, pending_operations, ... ▪ reactor-*/gauge-load, lsa-*/bytes-total_space, ... • DERIVE - change over time ▪ collectd types: total_operations, derive, ... ▪ database-*/total_operations-total_reads Data source types
- 24. Naming of metrics When exported to prometheus: collectd_{plugin}_{type} { {plugin}={plugin instance},type={type instance},instance={host} } E.g.: collectd_reactor_gauge{reactor=”0”,type=”load”,instance=”node1”}
- 25. Metric plugins coordinator replica transport (CQL server) thrift storage_proxy database memtables cachecommitlog seastar framework reactor memory io_queue lsa smp compaction_manager
- 26. • transport-*/total_operations-requests_served ▪ counts incoming CQL requests ▪ coordinator-side • database-*/total_operations-total_{reads|writes} ▪ counts incoming replica read/write requests • both are DERIVE-typed Throughput metrics
- 27. • storage_proxy-*/total_operations-{read|write} timeouts ▪ count number of timeouted read and write requests ▪ coordinator-side • check coordinator logs • check replica logs • check for overload Error metrics
- 28. Best reflected by reactor-*/gauge-load • percentage of time Scylla was executing tasks ▪ excludes busy polling, execution of on-idle tasks, sleeping ▪ Updated every second and reflects past 5 seconds. • 100 means the server is CPU-bound CPU Utilization
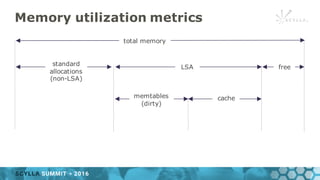
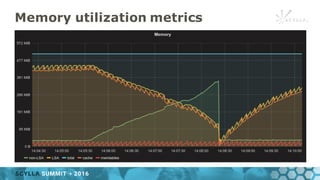
- 29. Memory utilization metrics total memory standard allocations (non-LSA) LSA free memtables (dirty) cache
- 30. Memory utilization metrics total memory standard allocations (non-LSA) LSA free memtables (dirty) cache lsa-*/bytes-non_lsa_used_space memory-*/memory-total_memory lsa-*/bytes-total_space memory-*/bytes-dirty cache-*/bytes-total
- 31. Memory utilization metrics • Useful for detecting: ▪cache getting shrunk down due to pressure from std allocations ▪requests blocking -only 50 % of memory is allowed to be dirty. -Requests will block if we can’t clean fast enough.
- 33. Cache metrics • cache-*/total_operations-*: ▪ hits, misses - entries found/not found in cache during read ▪ merges - entries updated during memtable flush ▪ insertions - entries added (on miss, memtable flush) ▪ evictions - entries removed due to memory pressure ▪ removals - entries invalidated (ring ownership change) • currently entries are per-partition
- 34. Cache metrics
- 35. I/O Queue metrics • Scylla uses the I/O Queue to provide fairness among: ▪ commitlog, memtables, query, etc io_queue-*/derive-{class name} bandwidth (bps) io_queue-*/delay-{class name} queue latency, not counting disk access (s) io_queue-*/queue_length-{class name} # requests waiting io_queue-*/total_operations-{class name} IOPS
- 36. Thank You! github.com/scylladb/scylla-grafana-monitoring Tomasz: [email protected] / @tgrabiec Glauber: [email protected] / @glcst